1. 决策树的介绍和分类
通过树结构进行回归和分类任务,通过选择特征作为树的节点,按照特征的取值将数据进行分堆,树逐步向下生长,最终使用完所有的特征,并达到预测标准,这类算法统称决策树。
1.1 决策树学习步骤
- 特征选取
- 树的生成
- 树的剪枝
1.2 决策树的分类:
- ID3
- C4.5
- CART
2. ID3
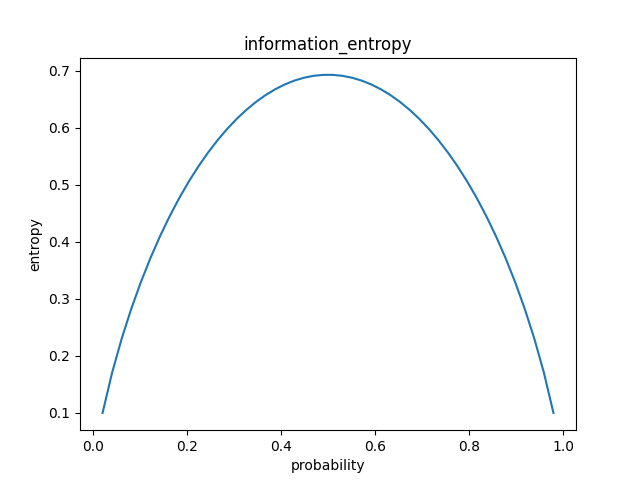
信息熵的概念:信息熵越大,表示的是时间的不确定性增加,如下图,二分类事件,当两者概率相同时,事件不确定最高,对应的信息熵值也越高:
ID3决策树算法利用的是信息增益作为选择特征的标准,信息增益指的是信息熵
的减少量,定义为信息熵-条件熵:
%20%3D%20H(D)%20-%20H(D%7CA)%20%5C%5C%5C%5C%0AH(D)%20%3D%20-%5Csum%7Bk%3D1%7D%5EK%20%5Cfrac%7B%7CC_k%7C%7D%7B%7CD%7C%7Dlog(%5Cfrac%7B%7CC_k%7C%7D%7B%7CD%7C%7D)%20%5C%5C%5C%5C%0AH(D%7CA)%20%3D%20%5Csum%7Bi%3D1%7D%5En%20%5Cfrac%7B%7CDi%7C%7D%7B%7CD%7C%7DH(D_i)%0A#card=math&code=g%28D%2C%20A%29%20%3D%20H%28D%29%20-%20H%28D%7CA%29%20%5C%5C%5C%5C%0AH%28D%29%20%3D%20-%5Csum%7Bk%3D1%7D%5EK%20%5Cfrac%7B%7CCk%7C%7D%7B%7CD%7C%7Dlog%28%5Cfrac%7B%7CC_k%7C%7D%7B%7CD%7C%7D%29%20%5C%5C%5C%5C%0AH%28D%7CA%29%20%3D%20%5Csum%7Bi%3D1%7D%5En%20%5Cfrac%7B%7CD_i%7C%7D%7B%7CD%7C%7DH%28D_i%29%0A)
其中表示的是集合
中属于第
类(目标类)的样本子集,
是属于特征
的第
的取值的样本子集。
2.1缺点
ID3算法通过应用信息增益来选择特征作为节点生成决策树,但是有以下不足:
- 没有剪枝策略,容易过拟合;
- 只能处理离散型特征;
- 没有考虑缺失值;
- 在特征选择时可能偏向取值较多的特征。
对于第四点进行解释,根据信息增益的公式,之所以会有#card=math&code=H%28D%29)与
#card=math&code=H%28D%7CA%29)的差值,是因为根据特征将数据分堆后,分堆后的数据不平衡性增加、方差更大,导致不确定性降低,即熵较少。即:
%20%3D%20%5Csum%7Bi%3D1%7D%5En%5Cfrac%7B%7CD_i%7C%7D%7B%7CD%7C%7D%5BH(D)-H(D_i)%5D%0A#card=math&code=g%28D%2CA%29%20%3D%20%5Csum%7Bi%3D1%7D%5En%5Cfrac%7B%7CD_i%7C%7D%7B%7CD%7C%7D%5BH%28D%29-H%28D_i%29%5D%0A)
而将数据分堆越多,这种数据不平衡性越会增加。
3. C4.5
主要考虑了ID3缺点中的第四点,使用信息增益比作为特征选择标准。除以了关于特征(原来时关于样本类别)的熵,对其进行修正:
%20%3D%20%5Cfrac%7Bg(D%2C%20A)%7D%7BH_A(D)%7D%0A#card=math&code=g_R%28D%EF%BC%8C%20A%29%20%3D%20%5Cfrac%7Bg%28D%2C%20A%29%7D%7BH_A%28D%29%7D%0A)
4. CART
相较前面两者,CART是二叉树,采用基尼系数作为衡量标准进行节点分裂,可针对连续值和离散值。
分为回归树和分类树

若有收获,就点个赞吧
0 人点赞
