Keras
1. 序列式API
序列式API简单直接,适合每层都是单输入单输出的网络,直线型,每个层的输出直接作为下一层的输入,且是唯一输入。keras.Sequential()
不适合:
- 模型或任意一层有多输入或多输出
- 需要层共享
- 需要非线性网络结构
模型可以视为一个序列,可以使用.add,.pop增删层,缺点也是序列属性,结构单一。model和layer都可以传入参数name绑定一个标识名。可通过标识名来访问指定层:model.get_layer(name)
1.1 权重初始化
推断:
通常模型第一层没指定输入规模,模型各层无法确定权重,是不会创建参数的,此时weights, trainable_weights,variables, trainable_variables都为空,除非先通过输入数据处理一下,就会根据输入数据确定权重。(注:keras里weights等同于variables)
一旦模型处理过输入数据后,输入数据的维度就固定了,后面即使增加其它层之后,增加的层也会自动推断纬度初始化权重。
提前设置:
另外就是提前设置输入数据的维度信息,才模型最开始传入keras.Input(shape),相当于是一个网络层。然后再加入其它层,此时就会直接初始化权重。
另外一种方式是在模型第一层加入参数input_shape也可以起到同样的效果。
当有参数后,可以通过model.summary查看模型的结构和基本参数。
冻结某层或某个模型的参数
layer.trainable=False model.trainable=False
可用于模型输入推测或是预测环节。
绘制层计算图
keras.utils.plot_model(model)
2. 函数式API
相对于序列式API,函数式API能处理非线性拓扑、具有共享层,多个输入或输出的模型。
步骤:
- 先创建
keras.Input输入 - 创建多个层,通过函数式调用产生输出
- 将输入和输出组合成模型
keras.Model(inpus=inputs, outputs=outputs)
模型也可以像层一样使用,所以也可以组合起多个模型。
Conv2D 层的反面是 Conv2DTranspose 层,MaxPooling2D 层的反面是 UpSampling2D 层。
tf.keras 包含了各种内置层,例如:
- 卷积层:Conv1D、Conv2D、Conv3D、Conv2DTranspose
- 池化层:MaxPooling1D、MaxPooling2D、MaxPooling3D、AveragePooling1D
- RNN 层:GRU、LSTM、ConvLSTM2D BatchNormalization、Dropout、Embedding 等
函数式 与子类式:
相比于子类时,函数式和Sequencetial都会更加简洁,不用自定义几个内部方法;函数式API中,输入的类型(形状和dtype)可以预先进行定义(Input),可以静态进行检查;函数式API可以安全的序列化和克隆,子类式API模型重写模型层的get_config和from_config。
函数式不支持动态架构,将模型视为层的DAG(有向无环图),导致某些不符合该结构的模型无法实现。
什么时候应该使用 Keras 函数式 API 来创建新的模型,或者什么时候应该直接对
Model类进行子类化呢?通常来说,函数式 API 更高级、更易用且更安全,并且具有许多子类化模型所不支持的功能。
但是,当构建不容易表示为有向无环的层计算图的模型时,模型子类化会提供更大的灵活性。
3. 子类式在其它式API中的使用
只要子类式层或模型实现了一下函数,即可在函数式或Sequential中使用:
call(self, inputs, **kwargs)- 其中inputs是张量或张量的嵌套结构(例如张量列表),**kwargs是非张量参数(非输入)。call(self, inputs, training=None, **kwargs)- 其中training是指示该层是否应在训练模式和推断模式下运行的布尔值。call(self, inputs, mask=None, **kwargs)- 其中mask是一个布尔掩码张量(对 RNN 等十分有用)。call(self, inputs, training=None, mask=None, **kwargs)- 当然,您可以同时具有掩码和训练特有的行为。
如果在自定义层或模型上实现了 get_config 方法,则创建的函数式模型将仍可序列化和克隆。
4. 使用内置函数配置训练
model.compile(optimizer=keras.optimizers.RMSprop(), # Optimizer# Loss function to minimizeloss=keras.losses.SparseCategoricalCrossentropy(),# List of metrics to monitormetrics=[keras.metrics.SparseCategoricalAccuracy()],)
history = model.fit(x_train,y_train,batch_size=64,epochs=2,# We pass some validation for# monitoring validation loss and metrics# at the end of each epochvalidation_data=(x_val, y_val),)
results = model.evaluate(x_test, y_test, batch_size=128)
其中history.history为一个字典,保存了训练过程中的loss, metrics值,model.evaluate输出在测试集上的loss, metrics值
在comile模型指定设置的时候,可以使用字符串来简便输入。
model.compile(optimizer="rmsprop",loss="sparse_categorical_crossentropy",metrics=["sparse_categorical_accuracy"],)
对于多个输出结构,也可以为每个输出指定单独的optimizer, loss, metrics,传入值用列表即可(按输出的次序),如果对层进行了命名,可以通过传入字典的方式。
同时可以对不同输出赋予不同的权重,通过参数loss_weight,其值同样使用列表或字典。
对于训练集、测试集,同样可采用该方式。
5. 自定义loss
最简单的方式就是写一个简单的函数:
def custom_mean_squared_error(y_true, y_pred):return tf.math.reduce_mean(tf.square(y_true - y_pred))model.compile(optimizer=keras.optimizers.Adam(), loss=custom_mean_squared_error)
满足参数具有y_true, y_pred,就可以在compile中使用,如果要需要其它参数,则需要子类化keras.losses.Loss,子类化时只需要实现**__init__(self)**和**call(self, y_true, y_pred)**即可
class CustomLoss(keras.losses.Loss)def __init__(self, params)...def call(y_true, y_pred):return ...
同样,想要能被序列化和保存(JSON, HDF5等格式存储)也需要实现get_config
对于非标准参数表的loss,可以写在自定义层或自定义模型的call中,通过使用self.add_loss(...),会自动添加(加法)到模型的主loss中。也可以在模型定义好之后,使用model.add_loss(可以自定义一个层,只为添加该功能,不执行任何计算功能):
class ActivityRegularizationLayer(layers.Layer):def call(self, inputs):self.add_loss(tf.reduce_sum(inputs) * 0.1)return inputs # Pass-through layer.
6. 自定义metrics
子类化keras.metrics.Metric,必须需要实现以下3个方法(updata_state, result为抽象方法):
__init__(self),在其中为指标创建状态变量。update_state(self, y_true, y_pred, sample_weight=None),使用目标 y_true 和模型预测 y_pred 更新状态变量。result(self),使用状态变量来计算最终结果。
通常也实现以下方法用于状态重置
reset_states(self),用于重新初始化指标的状态。
不实现也可以,源码中的默认实现是:
def reset_states(self):"""Resets all of the metric state variables.This function is called between epochs/steps,when a metric is evaluated during training."""K.batch_set_value([(v, 0) for v in self.variables])
同样,对于非标准参数签名的也可以通过单独自定义层,或放在自定义层和自定义模型之中,通过self.add_metric(...),此时compile中可不指定metrics,也可以在模型定义好之后,使用model.add_metric
7. 验证集
对于model.fit()训练方式,使用验证集有两种方式
validation_data以元组传入验证集validation_split,不用传验证集,设置比例,从训练集中抽出指定对应比例的数据作为验证集。注:只适用于numpy数据。
8.回调函数
回调指是训练期间(某个周期开始时、某个批次结束时、某个周期结束时等)在不同时间点调用的对象。
用途:
- 在训练期间的不同时间点进行验证(除了内置的按周期验证外)
- 定期或在超过一定准确率阈值时为模型设置检查点
- 当训练似乎停滞不前时,更改模型的学习率
- 当训练似乎停滞不前时,对顶层进行微调
- 在训练结束或超出特定性能阈值时发送信息通知
- …
比如使用Early Stopping:
model = get_compiled_model()callbacks = [keras.callbacks.EarlyStopping(# Stop training when `val_loss` is no longer improvingmonitor="val_loss",# "no longer improving" being defined as "no better than 1e-2 less"min_delta=1e-2,# "no longer improving" being further defined as "for at least 2 epochs"patience=2,verbose=1,)]model.fit(x_train,y_train,epochs=20,batch_size=64,callbacks=callbacks,validation_split=0.2,)
自定义
class LossHistory(keras.callbacks.Callback):def on_train_begin(self, logs):self.per_batch_losses = []def on_batch_end(self, batch, logs):self.per_batch_losses.append(logs.get("loss"))
常用回调函数:
- Early Stopping,提前结束训练
- ExponentialDecay,学习率衰减,还有多个不同衰减曲线的回调,
ExponentialDecay、PiecewiseConstantDecay、PolynomialDecay和InverseTimeDecay,这些都是按训练步长进行学习率更改 - ReduceLROnPlateau,根据指标修改学习率
- Tensorboard,可视化训练过程中的指标
9. 自定义层
call函数的执行流程:在执行完build后调用__call__
参数创建
参数创建有两种方式:
- 通过
tf.Variable(initial_value=...) - 通过
self.add_weights()
可设置trainable=False是参数变为不可训练权重,
两种方式的区别:第一种需要先知道输入数据形状,直接创建数据,第二种是不需要知道形状,也没有创建数据,当第一次调用数据时根据数据形状确定参数。
参数创建时间
当显式传入输入维度后,可以在模型定义时就同时创建好参数,参数可创建在__init__中,自定义类签名为:
class CustomLayer(keras.layers.Layer):def __init__(self, units, input_dim, **kwargs):passdef call(self, inputs):pass
如果事先不知道参数维度,可以采用运行时推断的方式,延迟创建参数,此时参数最好创建在build中,自定义类签名为:
class CustomLayer(keras.layers.Layer):def __init__(self, units, **kwargs):passdef build(self, input_shape):passdef call(self, inputs):pass
总结:如果要直接给定了输入类型形状,直接在__init__中创建层的参数,如果要动态推断,在build中创建参数。
权重正则化
创建层时,传入参数kernel_regularizer即可,可以在自定义层加入add_loss进行构建
自定义loss, metrics
自定义后,可以通过layer.losses和layer.metrics进行获取,metrcs的计算结果通过layer.metrics[0].result()进行获取,这些指标可以通过fit进行跟踪
序列化
通过get_config,
class CustomLayer(keras.layers.Layer):def __init__(self, units):passdef build(self, input_shape):passdef call(self, inputs):passdef get_config(self):base_configs = super().get_config()return {**base_configs, ...}
保留参数
call函数具有两个保留字参数:
- training。通过设置traing控制是否进行参数更新,用以适应训练和推断两种场景。
- mask。布尔型掩码,用以只选中输入中的部分数据。
activity regularizer的处理
在使用自带的模型层时,activity regularizer是一个初始化参数,是对模型整体输出的正则化,如果要在自定义层中使用这个参数,有两种策略:
- 传到父类中处理,也分两种。一种是定义时不写,在对自定义层使用时,
activity_regularizer参数会自动被传到keras.layers.Layer中处理;另一种是在定义时写,但是和kwargs一同 自行处理。通过阅读源码可知,处理方式如下:
for output in output_list:activity_loss = self._activity_regularizer(output)batch_size = math_ops.cast(array_ops.shape(output)[0], activity_loss.dtype)# Make activity regularization strength batch-agnostic.mean_activity_loss = activity_loss / batch_sizeself.add_loss(mean_activity_loss)# 自定义时进行如下处理即可:class CustomLayer(keras.layers.Layer):def __init__(self, activity_regularizer,...):...self.activity_redgularizer = keras.regularizers.get(activity_regularizer)...def __call__(self, ):...activity_loss = self.activity_regularizer(output)self.add_loss(activity_loss / batch_size)...
10. 自定义模型
Model 类具有与 Layer 相同的 API,但有如下区别:
- 它会公开内置训练、评估和预测循环(
model.fit()、model.evaluate()、model.predict())。定义时如果重写这些方法会覆盖掉原方法,确定能正确写好这些方法后再进行重写 - 它会通过
model.layers属性公开其内部层的列表。 - 它会公开保存和序列化 API(
save()、save_weights()…)
例子:
from tensorflow.keras import layersclass Sampling(layers.Layer):"""Uses (z_mean, z_log_var) to sample z, the vector encoding a digit."""def call(self, inputs):z_mean, z_log_var = inputsbatch = tf.shape(z_mean)[0]dim = tf.shape(z_mean)[1]epsilon = tf.keras.backend.random_normal(shape=(batch, dim))return z_mean + tf.exp(0.5 * z_log_var) * epsilonclass Encoder(layers.Layer):"""Maps MNIST digits to a triplet (z_mean, z_log_var, z)."""def __init__(self, latent_dim=32, intermediate_dim=64, name="encoder", **kwargs):super(Encoder, self).__init__(name=name, **kwargs)self.dense_proj = layers.Dense(intermediate_dim, activation="relu")self.dense_mean = layers.Dense(latent_dim)self.dense_log_var = layers.Dense(latent_dim)self.sampling = Sampling()def call(self, inputs):x = self.dense_proj(inputs)z_mean = self.dense_mean(x)z_log_var = self.dense_log_var(x)z = self.sampling((z_mean, z_log_var))return z_mean, z_log_var, zclass Decoder(layers.Layer):"""Converts z, the encoded digit vector, back into a readable digit."""def __init__(self, original_dim, intermediate_dim=64, name="decoder", **kwargs):super(Decoder, self).__init__(name=name, **kwargs)self.dense_proj = layers.Dense(intermediate_dim, activation="relu")self.dense_output = layers.Dense(original_dim, activation="sigmoid")def call(self, inputs):x = self.dense_proj(inputs)return self.dense_output(x)class VariationalAutoEncoder(keras.Model):"""Combines the encoder and decoder into an end-to-end model for training."""def __init__(self,original_dim,intermediate_dim=64,latent_dim=32,name="autoencoder",**kwargs):super(VariationalAutoEncoder, self).__init__(name=name, **kwargs)self.original_dim = original_dimself.encoder = Encoder(latent_dim=latent_dim, intermediate_dim=intermediate_dim)self.decoder = Decoder(original_dim, intermediate_dim=intermediate_dim)def call(self, inputs):z_mean, z_log_var, z = self.encoder(inputs)reconstructed = self.decoder(z)# Add KL divergence regularization loss.kl_loss = -0.5 * tf.reduce_mean(z_log_var - tf.square(z_mean) - tf.exp(z_log_var) + 1)self.add_loss(kl_loss)return reconstructed
original_dim = 784vae = VariationalAutoEncoder(original_dim, 64, 32)optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)mse_loss_fn = tf.keras.losses.MeanSquaredError()loss_metric = tf.keras.metrics.Mean()(x_train, _), _ = tf.keras.datasets.mnist.load_data()x_train = x_train.reshape(60000, 784).astype("float32") / 255train_dataset = tf.data.Dataset.from_tensor_slices(x_train)train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)epochs = 2# Iterate over epochs.for epoch in range(epochs):print("Start of epoch %d" % (epoch,))# Iterate over the batches of the dataset.for step, x_batch_train in enumerate(train_dataset):with tf.GradientTape() as tape:reconstructed = vae(x_batch_train)# Compute reconstruction lossloss = mse_loss_fn(x_batch_train, reconstructed)loss += sum(vae.losses) # Add KLD regularization lossgrads = tape.gradient(loss, vae.trainable_weights)optimizer.apply_gradients(zip(grads, vae.trainable_weights))loss_metric(loss)if step % 100 == 0:print("step %d: mean loss = %.4f" % (step, loss_metric.result()))
11.自定义训练流程
模型的训练,通常有两种:
- 通过模型的
fit方法 - 自己从头开始写,通过
GradientTape并控制每个细节
这里的自定义训练流程是自定义模型的**model.fit**过程。实际上要重写的是**train_step**()方法。在模型内部,通过self.compiled_loss和self.comiled_metrics可以获取已经定义好的loss, metrics函数。以下是一个模版:
class CustomModel(keras.Model):
def train_step(self, data):
x, y = data
with tf.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y, y_pred, regularization_losses=self.losses)
# Compute gradients
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Update metrics
self.compiled_metrics.update_state(y, y_pred)
# Return a dict mapping metric names to current value
return {m.name: m.result() for m in self.metrics}
注:self.compiled_metrics经过了特殊处理,因为metrics可以是多个,处理后的self.compiled_metrics在.update_state(y, y_pred)后其实是同时对所有的metrics进行了update_state(y, y_pred),而self.metrics则是存的模型各个metrics构成的列表。
如果要对模型的model.evaluate进行更改,需要重载的方法是**test_step()**。参考模版如下:
class CustomModel(keras.Model):
def test_step(self, data):
# Unpack the data
x, y = data
# Compute predictions
y_pred = self(x, training=False)
# Updates the metrics tracking the loss
self.compiled_loss(y, y_pred, regularization_losses=self.losses)
# Update the metrics
self.compiled_metrics.update_state(y, y_pred)
# Return a dict mapping metric names to current value.
return {m.name: m.result() for m in self.metrics}
12. 模型保存的加载
保存所有内容
操作比较简单:
model.save('my_model')
loaded_model = keras.models.load_model('my_model')
模型保存有两种方式,一种是Tensorflow2格式,另一种是HDF5文件
model.save('my_model.h5')
loaded_model = keras.models.load_model('my_model.h5')
当使用HDF5保存时,外部(为写进model中的)loss和metrics不会被保存,保存文件不包括自定义模型、层的计算图
仅保存网络架构
config = model.get_config Sequential.from_config(config) # or Model.from_config(config)json_config = model.to_json() new_model = keras.model.model_from_json(json_config)
仅保存权重
获取权重:layer.get_weights
设置权重:layer.set_weights
复制权重:layer1.set_weights(layer2.get_weights())
对于model同样可以使用上述操作。
保存至硬盘:
# save_format='tf' or save_format='h5'
model.save_weights(path)
model.load_weights(path)
Tensorflow
通常,没有必要用[tf.function](https://tensorflow.google.cn/api_docs/python/tf/function)装饰每个较小的功能;仅使用[tf.function](https://tensorflow.google.cn/api_docs/python/tf/function)装饰高级计算-例如,训练的一个步骤或模型的向前传递
变量保存,keras的层和模型具有variables和trainable_variables属性,能收集和保存所有的模型参数
layer.trainable_variables
layer.variables
model.trainable_variables
model.variables
数据类型
张量
一般来说,[tf.reshape](https://tensorflow.google.cn/api_docs/python/tf/reshape) 唯一合理的用途是用于合并或拆分相邻轴(或添加/移除 1)。利用 [tf.reshape](https://tensorflow.google.cn/api_docs/python/tf/reshape) 无法实现轴的交换,要交换轴,您需要使用 [tf.transpose](https://tensorflow.google.cn/api_docs/python/tf/transpose)。
张量类型:
- Tensor
- RaggedTensor
- SparseTensor
将非张量数据变为张量:tf.convert_to_tensor()
变量
tf.Variable,同样具有tf.constant的各种属。可更改元素值,但是无视更改元素形状,除非x.assign(),回收内存并重新分配。
重要属性:
- trainable。控制变量是否需要微分,为False可以关闭对该变量的梯度
自定义数据位置
tf.device()可以控制将变量、张量放在哪个位置,CPU、GPU或哪个GPU上。通过上下文语法,或者设为全局模式。
求梯度
with tf.GradientTape() as tape:
tape.watch(x)
z = f(x)
tape.gradient(z, x)
其中GradientTape.watch控制监听的张量,可以传list同时接受多个张量。
通常情况下,一次梯度只能使用一次tape.gradient,因为默认设置是当调用GradientTape().gradient的时候,就释放掉GradientTape占用的资源。如果需要多次调用,加入参数persistent=True:
with tf.GradientTape(persistent=True) as t:
t.watch(x)
y = f(x)
z = z(y)
dz_dx = t.gradient(z, x)
dy_dx = t.gradient(y, x)
计算图
In short, graphs are extremely useful and let your TensorFlow run fast, run in parallel, and run efficiently on multiple devices.
加速代码执行可以使用tf.function将python代码进行封装。
全局设置为eager excution:
tf.config.run_functions_eagerly(True)
关闭:
tf.config.experimental_run_functions_eagerly(False)
模型操作
虽然主要靠使用tf.keras,但掌握一些其它知识可以极大方便模型调整,增大自由度。
TensorFlow是一个强大的科学计算库,并针对大规模机器学习而进行了诸多优化。其核心部分同样依赖于Numpy且有非常相似的操作,但是增加了自动微分、各类优化器、GPU支持、分布式计算、JIT编译器(通过计算图),另外计算图可以打包起来在其它平台使用(如通过Java在Android设备上)
TensorFlow最重要的部分当属tf.keras,另外也有用于数据加载和预处理操作的tf.data,tf.io,负责图像处理操作的tf.image,信号处理的tf.signal…
底层上,大多TensorFlow操作都有高效的C++代码进行实现,许多操作还有不同的内核实现(kernels)
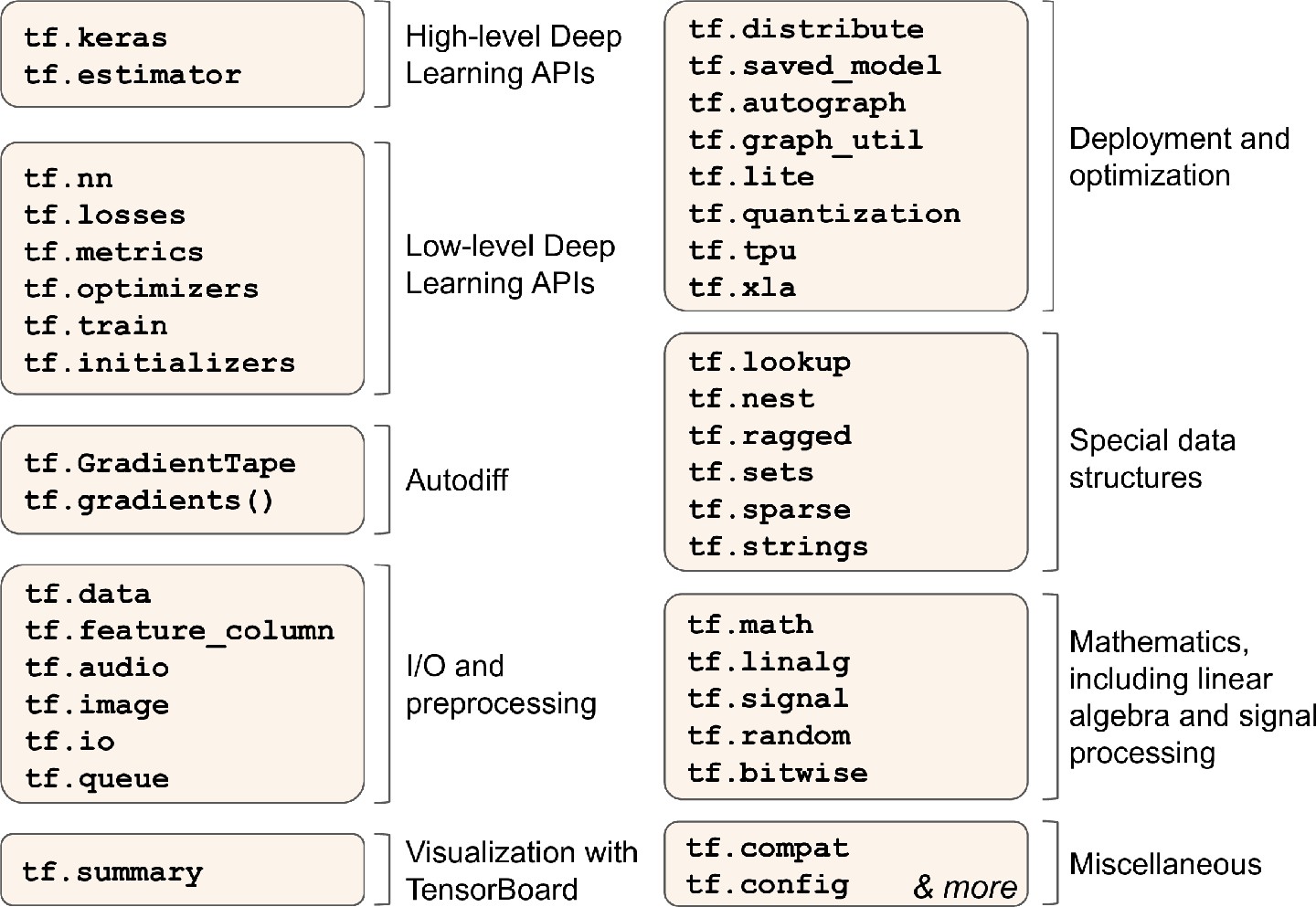
数据类型
常量(tf.constant)和变量(tf.Variable)
值得注意的一点是,TensorFlow中,为了性能考虑,不会自动进行数据类型转换,只能靠手动数据转换tf.cast,不然会引发异常InvalidArgumentError
自动微分
通常采用两点函数值除以横坐标值差距这种方式来进行近似(通常为),TensorFlow具有自动微分功能
def f(w1, w2):
return 3 * w1 ** 2 + 2 * w2 * w1
w1, w2 = tf.Variable(5.), tf.Variable(3.)
with tf.GradientTape() as tape: # 记录每次涉及到 变量 的操作
z = f(w1, w2)
# 可以使用with tape.stop_recording()来暂停tf.GradientTape()内部的记录操作
gradients = tape.gradient(z, [w1, w2])
# 当调用完gradient()后,tape会被自动擦除,再次调用会报错
对于非变量数据,默认不会进行跟踪记录,调用gradient()后会返回None的结果,如果需要在tf.GradientTape()内进行跟踪,可以进行设置(tape.watch())
c1, c2 = tf.constant(5.), tf.constant(3.)
with tf.GradientTape() as tape:
tape.watch(c1)
tape.watch(c2)
z = f(c1, c2)
gradients = tape.gradient(z, [z1, z2]) # 不加tape.watch()的话,返回的结果是[None, None]
对于矢量,如果想计算单独的梯度,要使用tape.jabobian(),另外还可以计算二阶偏导数(Hessian矩阵)
如果要阻止某部分的梯度的反向传播,可以使用tf.stop_gradient(),如下
def f(w1, w2):
return 3 * w1 ** 2 + tf.stop_gradient(2 * w1 * w2)
# 只会在前向传播时计算梯度,反向传播时不会计算后面的部分
with tf . GradientTape() as tape:
z = f(w1, w2) # same result as without stop_gradient()
gradients = tape.gradient(z, [w1, w2])
计算精度问题(自定义求导)
由于浮点数精度错误原因,自动微分可能会计算出NaN的结果,可以自定义链式求导的部分求导(不通过自动微分),然后通过链式求导乘起来
@tf.custom_gradient
def my_better_softplus(z):
exp = tf.exp(z)
def my_softplus_gradients(grad):
return grad / (1 + 1 / exp)
return tf.math.log(exp + 1), my_softplus_gradients
TensorFlow函数
可以将普通函数变为TensorFlow函数,通过tf.function,有两种方式,例如对于某函数alpha(),有两种方式:
tf_alpha = tf.function(alpha)
@tf.function
def alpha()
pass
对于自定义损失函数、评估矩阵、网络层…中的函数,Keras会自动将其转换为TensorFlow函数
TensorFlow图
TensorFlow具有自动生成图功能,首先(AutoGraph),分析Python函数源代码,捕获所有控制流语句;然后(Tracing)调用upgraded函数,传递一个符号张量(不具有任何实际值得张量,只具有名字、数据类型和形状)而不是参数,这个函数将运行在图模式graph mode(与之相对的是常规模式,也叫eager mode,eager execution),即每个TensorFlow操作将在图形中添加一个节点来表示自身及其输出张量。
可以通过tf.autograph.to_code(sum_squares.python_function)查看生成函数的源代码,有时候可能对于调式有帮助。
模型自定义
自定义损失函数
对于自定义模型的保存(比如模型的损失函数是自己定义的),重新导入时,要传递一个字典对象custom_object,指明模型中自定义函数名和对应的函数声明。
model = keras.models.load_model("my_model_with_a_custom_loss.h5", custom_objects={'huber_fn': huber_fn})
def huber_fn:
pass
但是上述方式不会保存自定义损失函数的超参数,要想保存超参数,需要子类化Keras的Loss类,按照以下的定义方式之后再结合上面的模型保存方式,可以让自定义模型加载后就能具有正确的损失函数和超参数。
class HuberLoss(keras.losses.Loss):
def __init__(self, threshold=1.0, **kwargs):
self.threshold = threshold
super().__init__(**kwargs)
def call(self, y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs( error ) < self.threshold
squared_loss = tf.square( error ) / 2
linear_loss = self.threshold * tf.abs( error ) - self.threshold ** 2 / 2
return tf.where(is_small_error , squared_loss , linear_loss )
def get_config(self):
base_config = super().get_config()
return {**base_config, "threshold": self.threshold}
当模型保存时,Keras会调用损失函数实例的get_config方法来将配置以JSON, HDF5的形式保存,当加载模型时,Keras会调用HuberLoss的from_fonfig(Loss函数已经实现,无需自行实现),然后创建该类(HuberLoss)实例并传递**config到构造器之中。
激活函数、初始化、正则化、约束的自定义
同损失函数的定义,如果没有超参数,直接在加载模型时加上custom_objects这一字典对象即可,不然需要同上所述利用子类化手段处理(keras.regularizers.Regularizer, keras.constraints.Constraint, keras.initializers.Initializer, keras.layers.Layer等),例如正则化:
class MyL1Regularizer(keras.regularizers.Regularizer):
def __init__(self, factor):
self.factor = factor
def __call__(self, weights):
return tf.reduce_sum(tf.abs(self.factor*weights))
def get_config(self):
return {"factor": self.factor}
注:对于损失函数和模型层(包括激活函数),子类化需要使用call函数,而其他的则使用__call__函数
自定义评估矩阵
评估矩阵不同于损失函数,损失函数需要保证可微分、有梯度,而评估矩阵不用,当然损失函数也可以作为评估矩阵用来使用
class HuberMetric(keras.metrics.Metric):
def __init__(self, threshold=1.0, **kwargs):
super().__init__(**kwargs)
self.threshold = threshold
self.huber_fn = create_huber(threshold) # 另外定义的一个huber损失函数
self.total = self.add_weight("total", initializer="zeros") # 创建多次迭代中跟踪矩阵状态的变量,此处为Huber Loss之和
self.count = self.add_weight("count", initializer="zeros") # 为一直到当前迭代为止, 的实例数
def update_state(self, y_true, y_pred, sample_weight=None): # 更新变量值
metric = self.huber_fn(y_true, y_pred)
self.total.assign_add(tf.reduce_sum(metric))
self.count.assign_add(tf.cast(tf.size(y_true), tf.float32))
def result(self): # 返回最终的计算值
return self.total / self.count
def get_config(self): # 确保threshold会跟随模型一起保存
base_config = super().get_config()
return {**base_config, "threshold": self.threshold}
自定义网络层
满足自定义特殊网络层的需求,首先是没有权重的网络层(如keras.layers.Flatten,keras.layers.ReLU),自定义无权重网络层最简单的是采用keras.layers.Lambda,如下:
exponential_layer = keras.layers.Lambda(lambda x:tf.exp(x))
创建具有权重的网络层,则需要使用子类化keras.layers.Layer,创建简化版Dense层如下:
class MyDense(keras.layers.Layer):
def __init__(self, units, activation=None, **kwargs):
super().__init__(**kwargs)
self.units = units
self.activation = keras.activations.get(activation) # 可接受函数、标准的激活函数字符串名或者None
def build(self, batch_input_shape):
self.kernel = self.add_weight(name="kernel", shape=[batch_input_shape[-1], self.units], initializer="glorot_normal")
self.bias = self.add_weight(name="bias", shape=[self.units], initialize="zeros")
super().build(batch_input_shape) # 必须放在最后
def call(self, X):
return self.activation(X @ self.kernel + self.bias)
def compute_output_shape(self, batch_input_shape):
return tf.TensorShape(batch_input_shape.as_list()[:-1] + [self.units])
# TensorFlow中shape是TensorShape类型,可以通过as_list()转为Python列表
def get_config(self):
base_config = super().get_config()
return {**base_config, "units":self.units, "activation":keras.activations.serialize(self.activation)}
创建具有多输入的网络层,call方法需要接受一个元组数据,包含所有的输入,但是这类网络层只能用于函数式、子类式API,无法用于序列式API(只能处理单输入单输出情况)
class MyMultiLayer(keras.layers.Layer):
def call(self, X):
X1, X2 = X
return [X1 + X2, X1 * X2, X1/X2]
def compute_output_shape(self, batch_input_shape):
b1, b2 = batch_input_shape
return [b1, b1, b1] # 应该可以处理广播规则
要使网络层在训练时和测试时具有不同的表现(例如Dropout、BatchNormalization),需要在call中传递training参数,以下是在网络层训练中加入高斯噪音(基本同keras.layers.GaussianNoise)
class MyGaussianNoise(keras.layers.Layer):
def __init__(self, stddev, **kwargs):
super().__init__(**kwargs)
self.stddev = stddev
def call(self, X, training=None):
if training:
noise = tf.random.normal(tf.shape(X), stddev=self.stddev)
return X + noise
else:
return X
def compute_output_shape(self, batch_input_shape):
return batch_input_shape
自定义模型

对于图示模型(并无实际意义),可以自定义ResidualBlock模块
class ResidualBlock(keras.layers.Layer):
def __init__(self, n_layers, n_neurons, **kwargs):
super().__init__(**kwargs)
self.hidden = [keras.layers.Dense(n_neurons, activation="elu", kernel_initializer="he_normal") for _ in range(n_layers)]
def call(self, inputs):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
return inputs + Z
接下来定义整个网络模块
class ResidualRegressor(keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(30, activation="elu", kernel_initializer="he_normal")
self.block1 = ResidualBlock(2, 30)
self.block2 = ResidualBlock(2, 30)
self.out = keras.layers.Dense(output_dim)
def call(self, inputs):
Z = self.hidden(inputs)
for _ in range(1 + 3):
Z = self.block1(Z)
Z = self.block2(Z)
return self.out(Z)
如果要使网络能被保存和被keras.models.load_model()加载,就需要向前面一样,定义get_config函数(在ResidualBlock和ResidualRegressor中都定义)
基于模型内部的损失函数和评估矩阵
class ReconstructingRegressor(keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden = [keras.layers.Dense(30, activation="selu", kernel_initializer="lecun_normal") for _ in range(5)]
self.out = keras.layers.Dense(output_dim)
# 5个Dense隐层和一个输出隐层
# TODO: check https://github.com/tensorflow/tensorflow/issues/26260
#self.reconstruction_mean = keras.metrics.Mean(name="reconstruction_error")
def build(self, batch_input_shape):
n_inputs = batch_input_shape[-1]
self.reconstruct = keras.layers.Dense(n_inputs)
super().build(batch_input_shape)
# 另外建一个隐层用于模型输入的重建,用于辅助任务
def call(self, inputs, training=None):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
reconstruction = self.reconstruct(Z) # reconstruction loss,reconstruction和输入之间的均方差
recon_loss = tf.reduce_mean(tf.square(reconstruction - inputs))
self.add_loss(0.05 * recon_loss)
#if training:
# result = self.reconstruction_mean(recon_loss)
# self.add_metric(result)
return self.out(Z)
自定义训练循环
自定义训练循环,即使对模型的fit()进行调整,提高灵活性,以满足某些特殊的需求。
此时,需要自己选取、自定义各类操作(损失函数、优化器、评估矩阵…),然后创建运行时、运行结束后的打印函数,然后手动实现fit()过程。
训练结构
自定义:
for x,y in dataset:
with tf.GradientTape() as tape:
prediction = model(x)
loss = loss_func(prediction, y)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradient(zip(gradients, model.trainable_variables))
使用fit(),无需考虑数据迭代
model.compile(optimizer=optimizer, loss=loss_func, ...)
model.fit(dataset)
调整数据维度顺序:
tf.transpose(data, perm=order),第二个参数是一个向量,指定调整后的次序
tf.TensorArray(dtype, data_shape),创建一个动态数组,可以运行中写入数据
加载和处理数据
通过使用Data API,基础的from_tensor_slices可以将数据参数转变为TensorFlow的数据集对象
X = tf.range(10)
tf.data.Dataset.from_tensor_slices(X) # 针对可切片数据,将X转为数据集,可遍历
tf.data.Dataset.range(10) # 和上面一样等价
对于数据集对象,有一些内置的预处理函数。注:处理后仍是数据集对象,故可以循环叠加使用
dataset.repeat(3) # 重复所有元素三次
dataset.batch(4) # 变为以4为一个batch的数据集
dataset.unbatch() # 字面意思
dataset.map(lambda x: x * 2) # 对于dataset的每个元素,进行函数处理
dataset.apply(transformation_function) # 对dataset整体实施一个操作
dataset.filter(lambda x: x > 2) # 过滤操作
dataset.shuffle(buffer_size=x) # 以x为缓冲单位来重排数据,buffer_size一般要比数据数大,如果数据集过大,可以采用系统级操作先进行重排(如Linux的shuf)
加载多项数据
dataset_paths = tf.data.Dataset.list_files(file_paths, seed=42) # 同时加载多个数据文件路径,并默认对顺序进行重排,不想打乱顺序可以设定参数shuffle=False
dataset = dataset_paths.interleave(function, cycle_length) # 对于多个数据的路径对象,将function作用到每个路径对象上,一遍遍循环从中取元素,cycle_length控制每轮循环取元素的数量
data = dataset.take(5) # 从dataset数据集中取5个元素
TFReconds类型
对于其它类型数据,如图片、语音等非CSV文本文件,可以使用TensorFlow的自建格式进行处理(TFReconds),包含四部分:长度、长度CRC验证、真实数据、数据CRC验证,通过tf.io.TFRecordWriter可快速创建该类型数据
常用api为三个:tf.io.TFRecordWriter, tf.io.TFRecordDataset, tf.io.TFRecordOptions
TFRecordWriter负责写数据,接收参数为文件路径(单个),通过方法write进行数据写入
TFRecordDataset负责导入数据,接收的是列表数据,包括单个或多个文件路径,可指定参数num_parallel_reads来设置并行访问数量
TFRecordOptions是设置文件压缩类型(参数为compression_type)的,可以放在TFRecordWriter和TFRecordDataset中作为options参数传递。如:
options = tf.io.TFRecordOptions(compression_type='GZIP')
with tf.io.TFRecordWriter("my_compressed.tfrecord", options) as f:
f.write(b"This is the first record")
f.write(b"And this is the second record")
dataset = tf.data.TFRecordDataset(["my_compressed.tfrecord"],
compression_type="GZIP")
for item in dataset:
print(item)
数据预处理
数据标准化
对于数据标准化处理,有多种方法,常用的是调用sklearn.preprocessing.StandardScaler,然后再传入网络中,当然也可以在神经网络中加上一层标准化层,以下为在keras中的实现。
means = np.mean(X_train, axis=0, keepdims=True)
stds = np.std(X_train, axis=0, keepdims=True)
eps = keras.backend.epsilon()
model = keras.models.Sequential([
keras.layers.Lambda(lambda inputs:(inputs - means) / (stds + eps))
...
])
或者进行API化:
class Standardization(keras.layers.Layer):
def adapt(self, data_sample):
self.means_ = np.mean(data_sample, axis=0, keepdims=True)
self.stds_ = np.std(data_sample, axis=0, keepdims=True)
def call(self, inputs):
return (inputs - self.means_) / (self.stds_ + keras.backend.epsilon())
# 使用
std_layer = Standardization()
std_layer.adapt()
model = keras.Sequential()
model.add(std_layer)
...
model.compile(...)
model.fit(...)
分类特征one-hot化
数据的one-hot化有多种方式:
- DataFrame数据通过
pd.get_dummies() - 通过
sklearn.preprocessing.OneHotEncoder()
用tensorflow进行实现:
在tensorflow中,one-hot化的数据必须是整型,通常做法是先将类型化数据的值整型化(1, 2, 3…),对应sklearn.preprocessing.LabelEncoder
vocabu = [...]
indices = tf.range(len(vocabu))
table_init = tf.lookup.KeyValueTensorInitializer(vocab, indices)
num_oov_buckets = 2 # 不在vocabu中的类别数量
table = tf.lookup.StaticVocabularyTable(table_init, num_oov_buckets)
categories = tf.constant(...) # 测试编码
# 整型分类化
cat_indices = table.lookup(categories)
# one-hot化
cat_one_hot = tf.one_hot(cat_indices, depth=len(vocabu) + num_oov_buckets)
embedding向量处理
随着类别增多,one-hot的向量可能具有很高的维度,带来计算上的困难,通常做法是进行embedding操作,将其映射到低纬度的隐空间内,用低纬度的向量进行表示。
# 已有embedding的矩阵:embedding_matrix
categories = tf.constant([...]) # 给定某个one-hot之前的数据
cat_indices = table.lookup(categories)
tf.nn.embedding_loopup(embedidng_matrix, cat_indices) # 从embedding矩阵中读取该数据对应的embedding
keras自带有embedding层,一个处理类别化数据的模型如下:
# 两个输入:regular_inputs是8个数值型特征,categories是类别特性,one-hot化为6维,embedding为2维
regular_inputs = keras.layers.Input(shape=[8])
categories = keras.layers.Input(shape=[], dtype=tf.string)
cat_indices = keras.layers.Lambda(lambda cats: table.lookup(cats))(categories)
cat_embed = keras.layers.Embedding(input_dim=6, output_dim=2)(cat_indices)
encoded_inputs = keras.layers.concatenate([regular_inputs, cat_embed])
outputs = keras.layers.Dense(1)(encoded_inputs)
model = keras.models.Model(inputs=[regular_inputs, categories],
outputs=[outputs])

若有收获,就点个赞吧
0 人点赞
