激活函数
神经网络,特别是深度神经网络,神经网络的叠加起到效果,并实现其强大的拟合能力,很重要的就是其各层输出的非线性变换,也即是各层的激活函数。
激活函数最主要的作用就是进行非线性变换,各种激活函数的不断变化在于其它特性,例如有的激活函数反向传播容易梯度消失或爆炸,实践上不同激活函数网络有着不同的适应场景,在此,对常用的一些激活函数作总结。
实际使用中隐层基本都使用ReLU系激活函数(ReLU, LeakyReLU, PReLU, ELU, SELU等),Sigmoid、Softmax通常出现在二分类、多分类的输出层,而其它激活函数就很少出现了。
keras中,激活函数的应用用两种方式:通过构建激活函数层;初始化层时传递激活函数作为参数。
model.add(layers.Dense(64))model.add(layers.Activation(activations.relu))# ormodel.add(layers.Dense(64, activation='relu'))
ReLU
基本是最长使用的激活函数,兼顾计算速度、导数性质、非线性变换、稀疏性等方面,计算很简单,公式如下:
%20%3D%20max(0%2C%20x)%0A#card=math&code=ReLU%28x%29%20%3D%20max%280%2C%20x%29%0A)
def relu(x):return np.maximum(x, 0)# tftf.nn.relu(x)tf.keras.activations.relu(x)

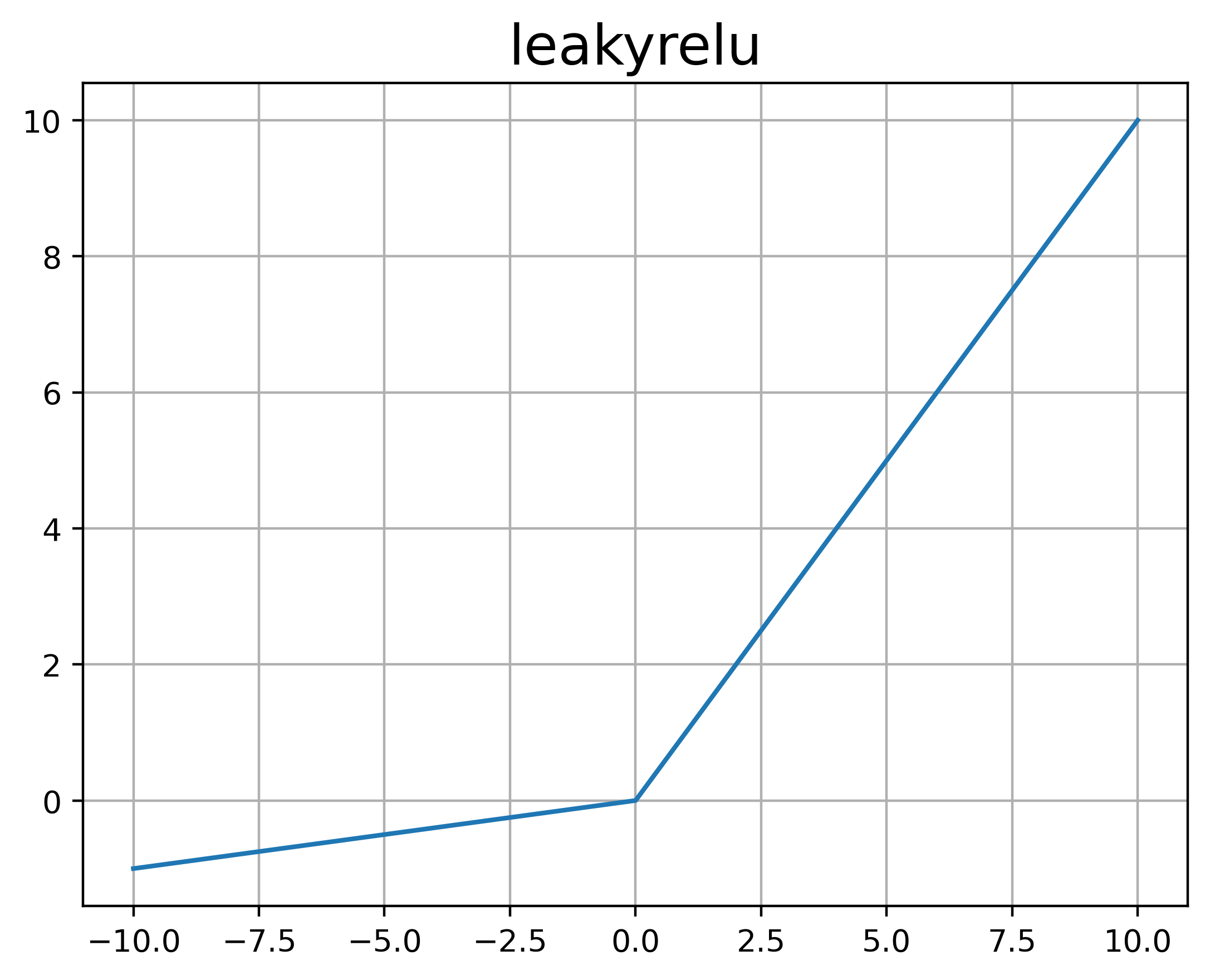
LeakyReLU
属于ReLU的改进版本,在左侧引入了一个梯度(斜率)值。
注:LeakyReLU中,该梯度值为给定值(超参数),如果是训练参数(模型参数),则称之为Parametric ReLU, PReLU。
%20%3D%20%5Ccases%20%7B%0Ax%20%26%20x%3E0%5C%5C%5C%5C%0A%5Cgamma%20x%20%26%20x%3C%3D0%0A%7D%0A#card=math&code=LeakyReLU%28x%29%20%3D%20%5Ccases%20%7B%0Ax%20%26%20x%3E0%5C%5C%5C%5C%0A%5Cgamma%20x%20%26%20x%3C%3D0%0A%7D%0A)
def leakyrelu(x, gamma):return np.maximum(x, 0) + np.minimum(0, gamma * x)# tftf.nn.leaky_relu(x, alpha=0.2)tf.keras.activations.relu(x, alpha=0.2)
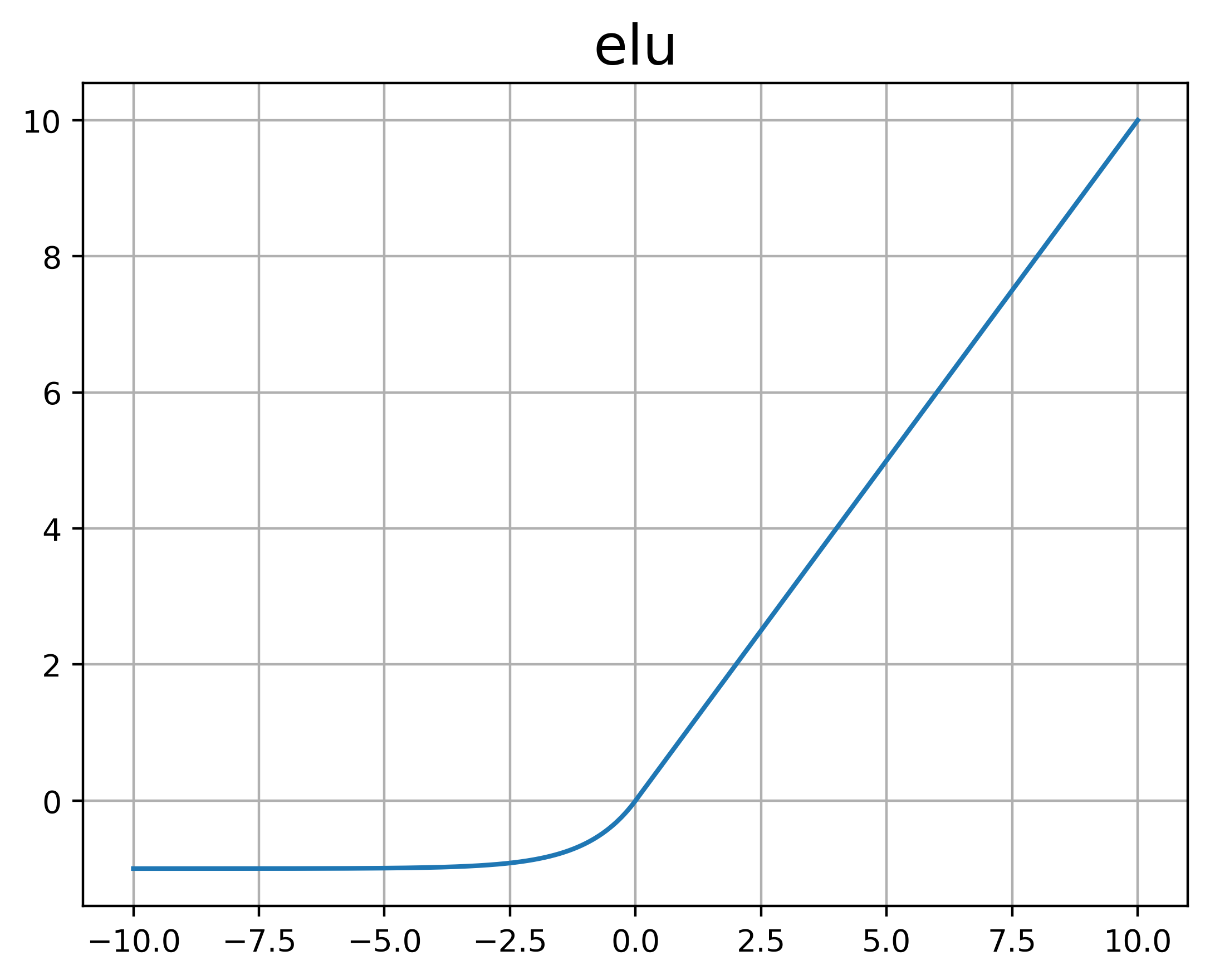
ELU
全称Exponential Linear Unit,也是ReLU的改进版本,处理的是ReLU不零中心化的问题,由于ReLU是非零中心化的,会给后一层神经网络引入偏置偏移。但是ELU相对ReLU的问题主要就是计算慢
%20%26x%3C%3D0%0A%7D%0A#card=math&code=ELU%20%3D%20%5Ccases%7B%0Ax%20%26x%3E0%5C%5C%5C%5C%0A%5Cgamma%28e%5Ex-1%29%20%26x%3C%3D0%0A%7D%0A)
def elu(x):return np.maximum# tftf.keras.activations.elu(x, alpha=1.0)
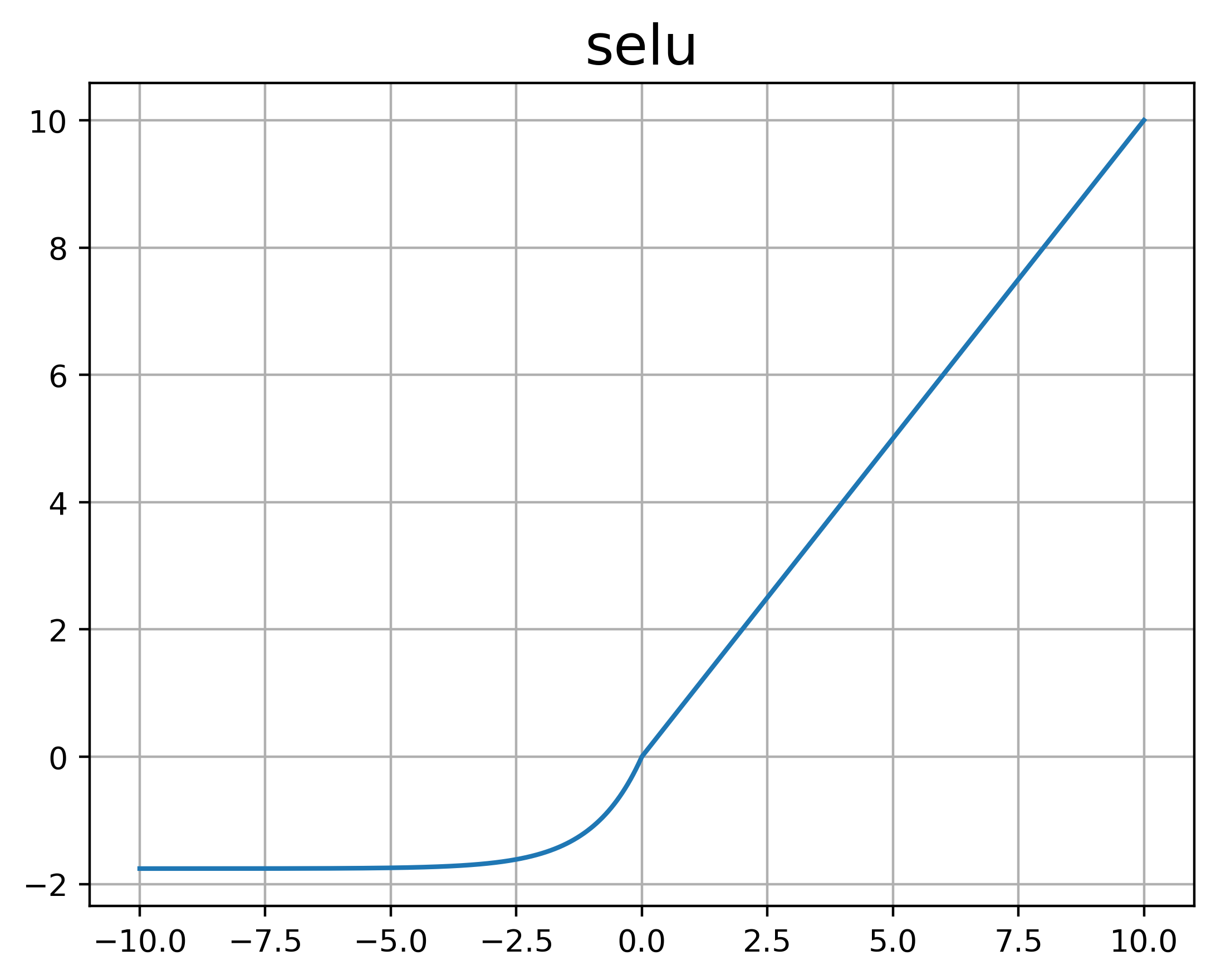
SELU
全称Scaled Exponential Linear Unit,也就是Scaled ELU,直译就是缩放的指数线性函数,提出自2017年,SELU可以使网络自正则化,即输出均值为0,标准差为1的数据,效果效果相较于其它网络会好很多,但是需要满足一定条件:
- 输入特征需要标准化
- 隐藏层权重必须采用LeCun Initialization
- 网络架构必须是序列型,在非序列性网络(如RNN)中使用的话不能确保自正则化,也不会一定优于其它激活函数的训练效果
- 原论文只证明了所有隐藏层都是密集层(Dense)时,能够自正则化,其它类型的网络不确定
隐藏层激活函数选择建议:SELU>ELU>leaky ReLU>ReLU>tanh>logistic,如果网络架构导致SELU无法自正则化,ELU会优于SELU,如果比较在意运行延迟,可以选择leaky ReLU,如果不想调整另外的超参数,可以使用Keras默认的(比如leaky ReLU的
为0.3)。 而如果时间和计算资源稍微充裕,可以交叉验证其它的几个激活函数效果:RReLU(如果网络过拟合)、PReLUde(如果训练样本集非常大),而速度第一位的话,ReLU是最佳选择(许多库对ReLU有特别的硬件优化)
%2C%20%26%20x%20%3C%3D0%0A%7D%0A#card=math&code=SELU%20%3D%20%5Ccases%7B%0Ascale%20%2A%20x%20%26%20x%3E0%5C%5C%5C%5C%0Ascale%20%2A%20alpha%20%2A%20%28e%5Ex%20-%201%29%2C%20%26%20x%20%3C%3D0%0A%7D%0A)
虽然公式如上,实际上scale, alpha是给定的值,分别为alpha=1.67326324和scale=1.05070098。当使用Lecun initialization时,会保留相邻层的标准差和方差。
def selu(x):return np.maximum(x, 0) + np.minimum(0, scale * alpha * (np.exp(x)-1))# tftf.nn.selu(x)tf.keras.activations.selu(x)# 层中tf.keras.layers.Dense(64, kernel_initializer='lecun_normal', activation='selu')
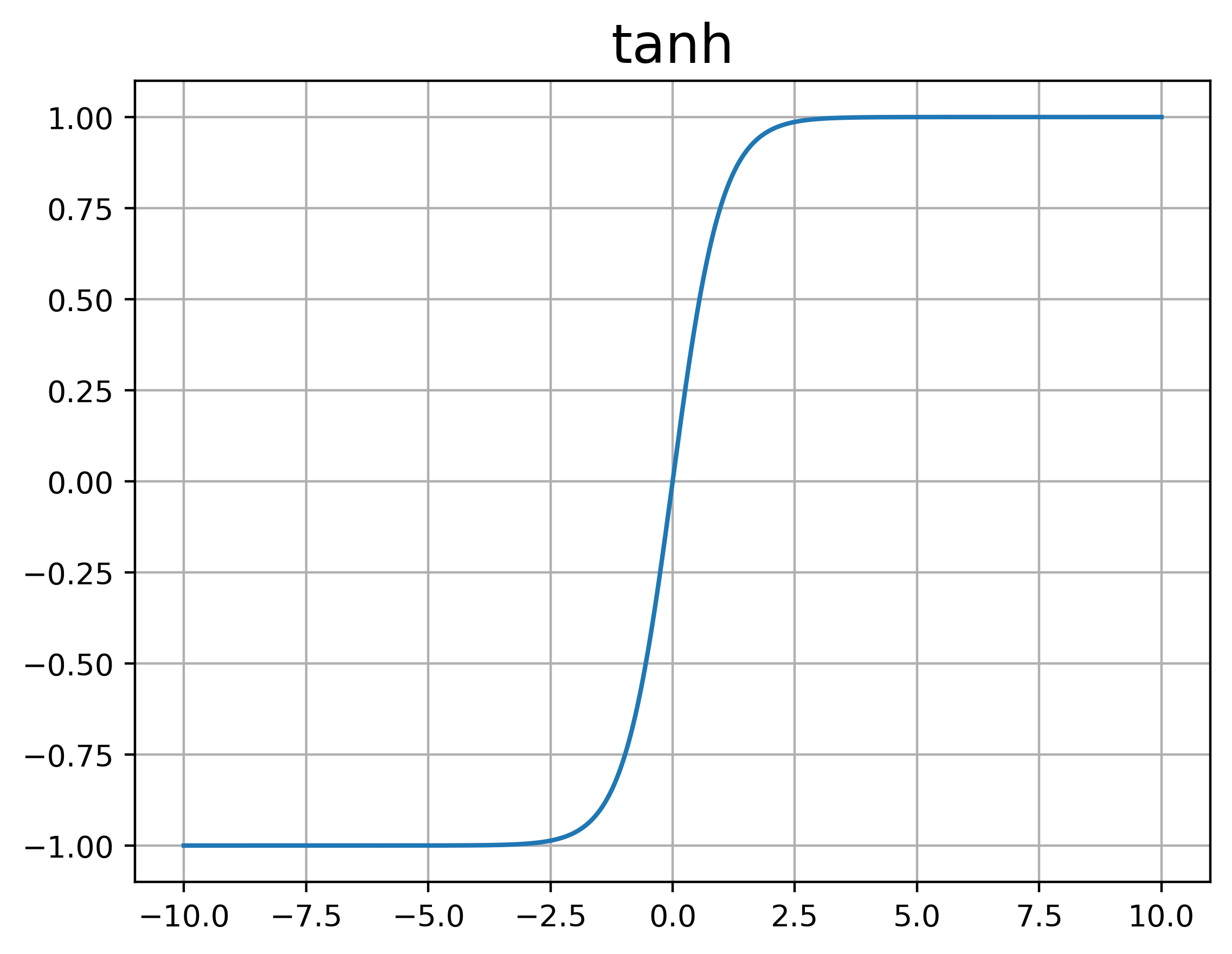
tanh
双曲正切函数,使用比较少
%20%3D%20%5Cfrac%7Be%5Ex%20-%20e%5E%7B-x%7D%7D%7Be%5Ex%20%2B%20e%5E%7B-x%7D%7D%0A#card=math&code=tanh%28x%29%20%3D%20%5Cfrac%7Be%5Ex%20-%20e%5E%7B-x%7D%7D%7Be%5Ex%20%2B%20e%5E%7B-x%7D%7D%0A)
def tanh(x):return np.tanh(x)# tftf.nn.tanh(x)tf.keras.activations.tanh(x)
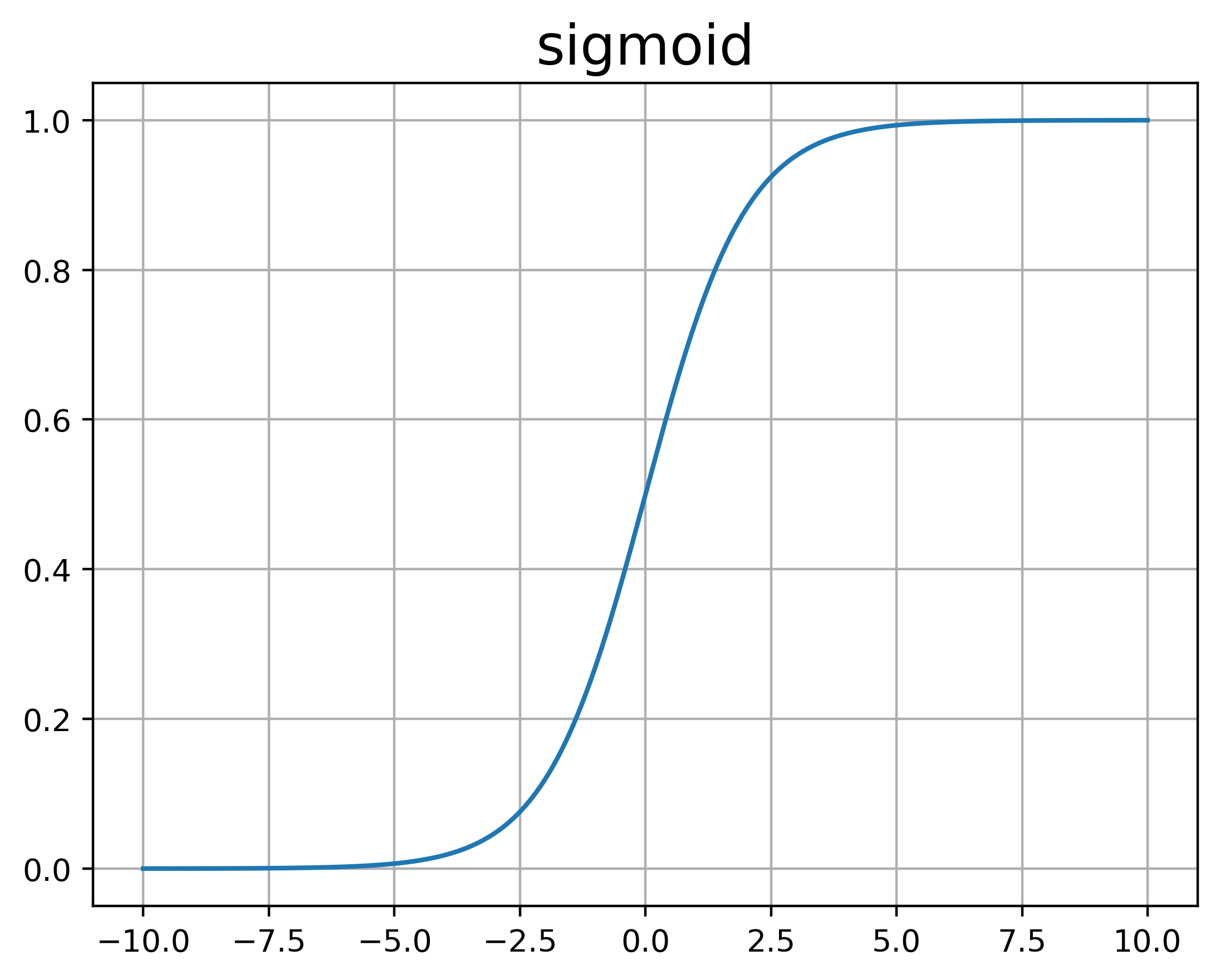
Sigmoid
信号处理中常会用到的函数,Logistic Regress中使用的也是sigmoid函数,Sigmoid函数也叫Logistic函数,以前作为所有网络层的激活函数,但发现有问题,后来就基本都开始用ReLU了,问题主要是两点:
- 导数易饱和,当输入过大或者过小时,导数都向0饱和,导致层数增加后,开始层的参数变化非常微小
- 平均值为0.5,而不是0
%20%3D%20%5Cfrac%7B1%7D%7B1%2Be%5E%7B-x%7D%7D%0A#card=math&code=Sigmoid%28x%29%20%3D%20%5Cfrac%7B1%7D%7B1%2Be%5E%7B-x%7D%7D%0A)
def sigmoid(x):return 1 / (1 + np.exp(-x))# tftf.nn.sigmoid(x)tf.keras.activations.sigmiod(x)
另外还有Hard-sigmoid,其实就是为了简化计算,采用近似的方式,近似方式是通过一阶泰勒展开,在值在-1和1之间的区域,公式可见:
%20%3D%20%5Ccases%7B%0A1%20%26%20x%3E2.5%5C%5C%5C%5C%0A0.2%20x%20%2B%200.5%20%26-2.5%20%3C%3D%20x%3C%3D2.5%5C%5C%5C%5C%0A0%20%26x%3C-2.5%0A%7D%0A#card=math&code=HardSigmoid%28x%29%20%3D%20%5Ccases%7B%0A1%20%26%20x%3E2.5%5C%5C%5C%5C%0A0.2%20x%20%2B%200.5%20%26-2.5%20%3C%3D%20x%3C%3D2.5%5C%5C%5C%5C%0A0%20%26x%3C-2.5%0A%7D%0A)
Softmax
可当作多元的sigmiod,将标量值转变为概率值,通常用在最后一层,计算多分类的概率值。
%20%3D%20%5Cfrac%7Be%5E%7Bxi%7D%7D%7B%5Csum_i%20e%5E%7Bxi%7D%7D%0A#card=math&code=sigmoid%28xi%29%20%3D%20%5Cfrac%7Be%5E%7Bxi%7D%7D%7B%5Csum_i%20e%5E%7Bxi%7D%7D%0A)
# 输入为2阶张量def sigmoid(x):fra = np.exp(x)div = np.sum(fra, axis=1)return fra / div# tftf.nn.softmax(x)tf.keras.activations.softmax(x)
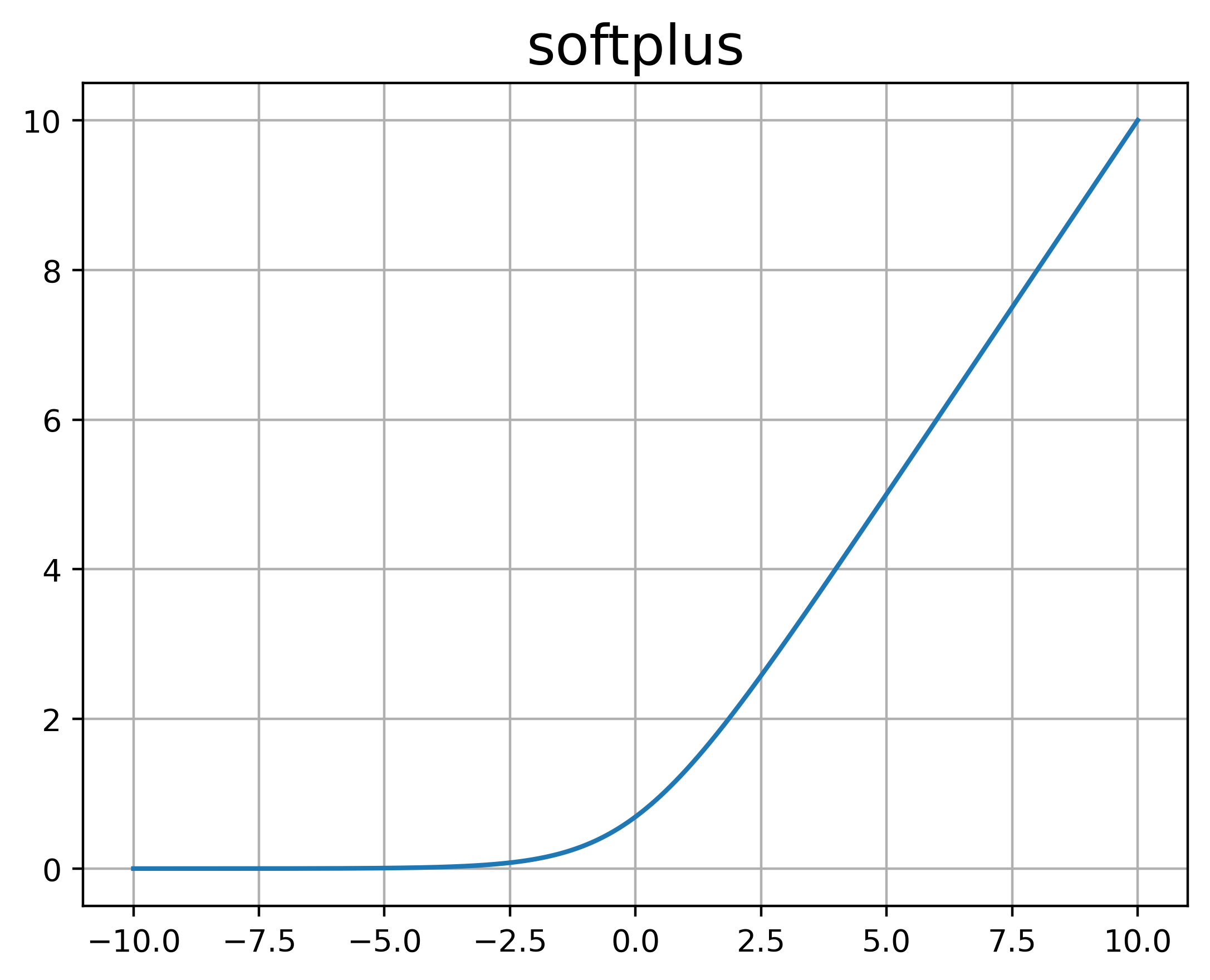
Softplus
可以看作是ReLU函数的平滑版本,定义为:
%20%3D%20%5Clog(1%2Be%5Ex)%0A#card=math&code=Softplus%28x%29%20%3D%20%5Clog%281%2Be%5Ex%29%0A)
其倒数恰好为Logistic函数,具有单侧一直、宽兴奋边界的特性,但是没有稀疏激活性。
def softplus(x):
return np.log(1+np.exp(x))
# tf
tf.nn.softmax(x)
tf.keras.activations.softmax(x)
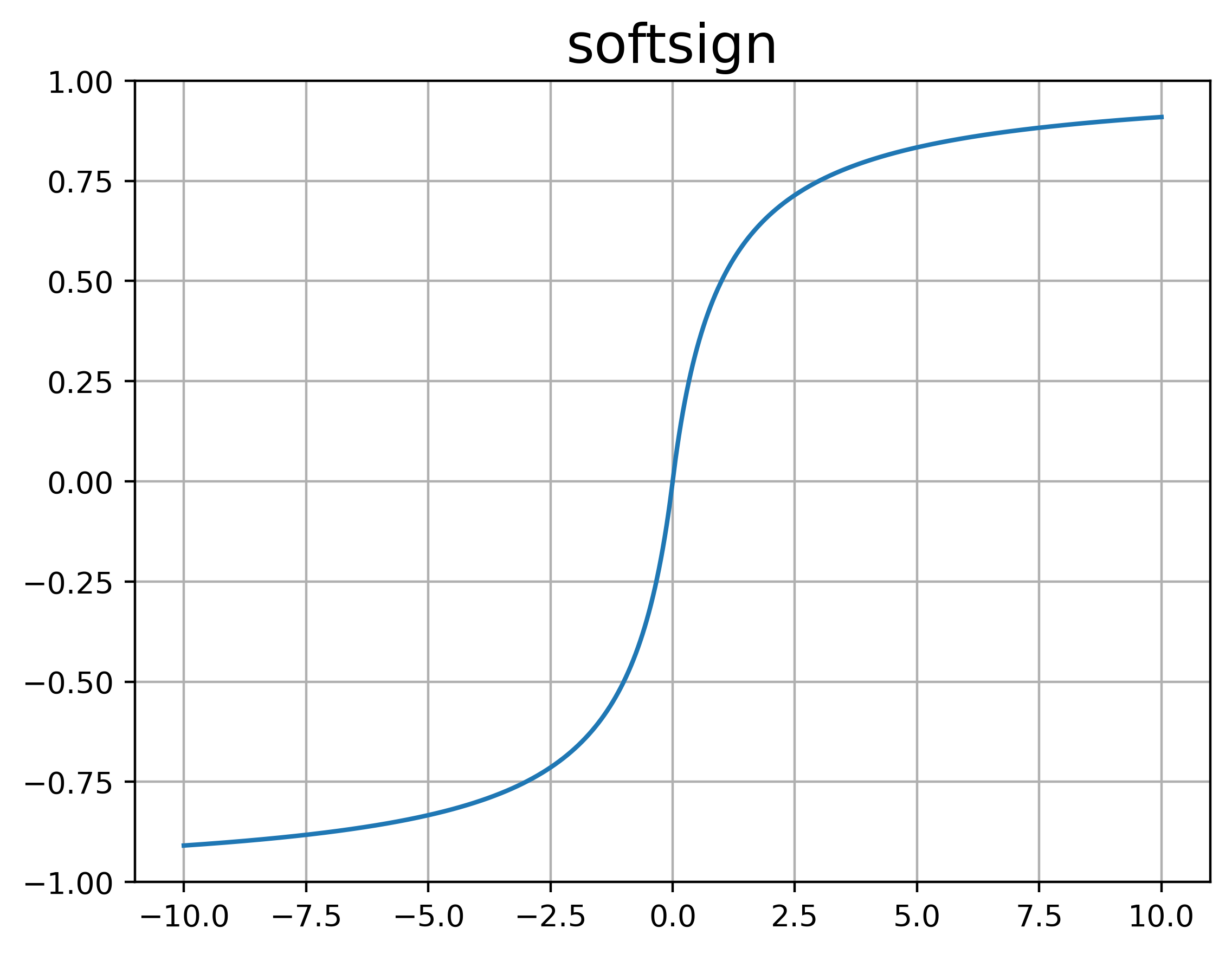
Softsign
类似于Softplus,也是对某一函数的近似,Softsign是对Sign(就是阶跃函数)的平滑版本,从起名就可以看出来,公式如下:
%20%3D%20%5Cfrac%7Bx%7D%7B%5Cvert%20x%5Cvert%20%2B1%7D%0A#card=math&code=Softsign%28x%29%20%3D%20%5Cfrac%7Bx%7D%7B%5Cvert%20x%5Cvert%20%2B1%7D%0A)
def softsign(x):
return x / (np.abs(x) + 1)
# tf
tf.nn.softsign(x)
tf.keras.activations.softsign(x)
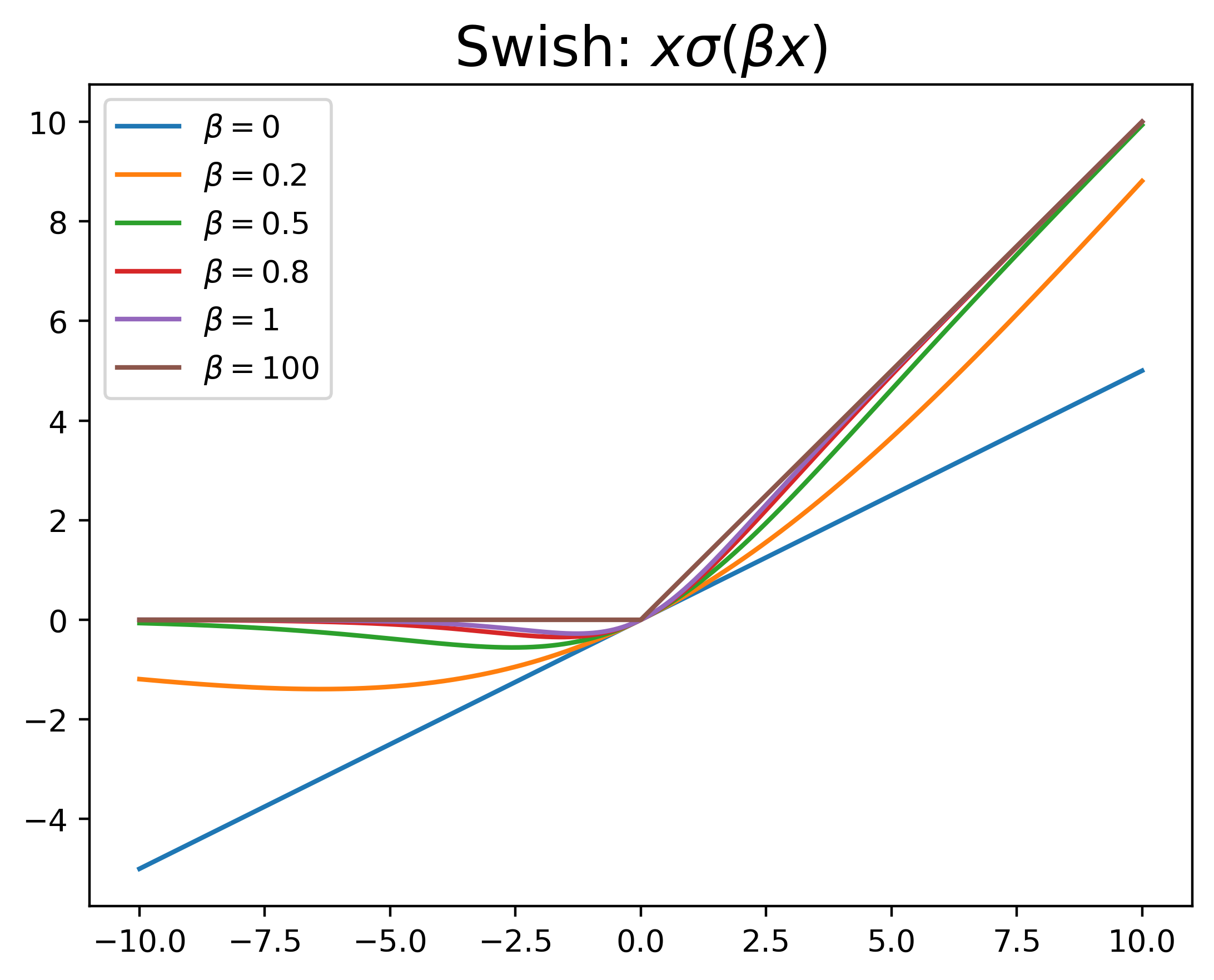
Swish
由于是2017年才提出,使用不多,是一种self-gated激活函数,具有一个可学习的参数,公式如下:
%20%3D%20x%5Csigma(%5Cbeta%20x)%0A#card=math&code=Swish%28x%29%20%3D%20x%5Csigma%28%5Cbeta%20x%29%0A)
其中#card=math&code=%5Csigma%28%5Ccdot%29)是可看作一种软性额门控机制,当
接近1时,门处于“开”状态,激活函数输出近似与
,而当
#card=math&code=%5Csigma%28%5Cbeta%20x%29)接近0时,门处于“关”状态,激活函数输出近似于0。
def swish(x, beta):
sig = 1 / (1 + np.exp(-beta * x))
return x * sig
# tf
# 都是默认beta=1,且不提供beta的参数调节
tf.nn.swish(x)
tf.keras.activations.swish(x)

若有收获,就点个赞吧
0 人点赞
