深度学习轻量级推理及加速
深度学习轻量级推理及加速
李景峰
算法小白
轻量级模块化的高性能神经网络推理引擎
Mace
No.4:Mace:专为移动端异构计算平台优化的深度学习推理框架[Github 2118颗星]。 来自小米>
Mobile AI Compute Engine (MACE) 是小米开源的移动端深度学习框架,它针对移动芯片特性进行了大量优化,目前在小米手机上已广泛应用,如人像模式、场景识别等。>
Mace主要从以下的角度做了专门的优化:>
性能:代码经过NEON指令,OpenCL以及Hexagon HVX专门优化,并且采用 Winograd算法来进行卷积操作的加速。 此外,还对启动速度进行了专门的优化。功耗:支持芯片的功耗管理,例如ARM的big.LITTLE调度,以及高通Adreno GPU功耗选项。系统响应:支持自动拆解长时间的OpenCL计算任务,来保证UI渲染任务能够做到较好的抢占调度, 从而保证系统UI的相应和用户体验。内存占用:通过运用内存依赖分析技术,以及内存复用,减少内存的占用。另外,保持尽量少的外部 依赖,保证代码尺寸精简。模型加密与保护:模型保护是重要设计目标之一。支持将模型转换成C++代码,以及关键常量字符混淆,增加逆向的难度。硬件支持范围:支持高通,联发科,以及松果等系列芯片的CPU,GPU与DSP(目前仅支持Hexagon)计算加速。 同时支持在具有POSIX接口的系统的CPU上运行。项目地址:> https://github.com/XiaoMi/mace> Ubuntu16.04—-腾讯NCNN框架入门到应用
TEngine性能全面超越ncnn
TensorRT 的运行需要CUDA,而且只能在 NVIDIA的 GPU中才能使用。
CaffePresso,可以将 Caffe中prototxt类型的文件定制成适用于各种不同硬件平台的低规格版本, CaffePresso 也需要某种硬件加速器(DSP、FPGA 或 NoC)。
CaffePresso: An Optimized Library for Deep Learning on Embedded Accelerator-based platforms
http://github.com/gplhegde/caffepressogithub.com
Mini-caffe :Minimal runtime core of Caffe, Forward only, GPU support and Memory efficiency.
ZQCNN, 一款比mini-caffe更快的Forward库,
Anakin
High performance Cross-platform Inference-engine, you could run Anakin on x86-cpu,arm, nv-gpu, amd-gpu,bitmain and cambricon devices. https://anakin.baidu.com/
paddle-mobile
This research aims at simply deploying deeplearning on mobile and embedded devices, with low complexity and high speed. old name mobile deep learning.
高通snpe
SNPE的使用 - Slow down - CSDN博客blog.csdn.net
TensorFlow Lite
苹果的Core ML
后端加速库
ARM Computer Library
The ARM Computer Vision and Machine Learning library is a set of functions optimised for both ARM CPUs and GPUs using SIMD technologies.
NNPACK后端库
Ristretto是一种自动CNN近似工具,可压缩32位浮点网络。Ristretto是Caffe的扩展, 允许以有限的数值精度测试,训练和微调网络。
Ristretto | CNN Approximation - LEPSlepsucd.com
优化矩阵乘法运算。谷歌开源小型独立低精度通用矩阵乘法(General Matrix to Matrix Multiplication,GEMM)库 gemmlowp。
优化矩阵乘法运算。谷歌开源小型独立低精度通用矩阵乘法(General Matrix to Matrix Multiplication,GEMM)库 gemmlowp。GEMMLOWP的一二apllo新浪博客blog.sina.com.cn
优化矩阵乘法运算。谷歌开源小型独立低精度通用矩阵乘法(General Matrix to Matrix Multiplication,GEMM)库 gemmlowp。
GEMMLOWP的一二apllo新浪博客blog.sina.com.cn
FeatherCNN, developed by Tencent TEG AI Platform, is a high-performance lightweight CNN inference library. FeatherCNN is currently targeting at ARM CPUs, and is capable to extend to other devices in the future.
Hexagon DSP SDK
Hexagon DSP 发布SDK 3.3.2,打造全新神经网络库cloud.tencent.com
高通qsml库
阿里 BNN
模型压缩框架
腾讯AI Lab自动模型压缩框架PocketFlow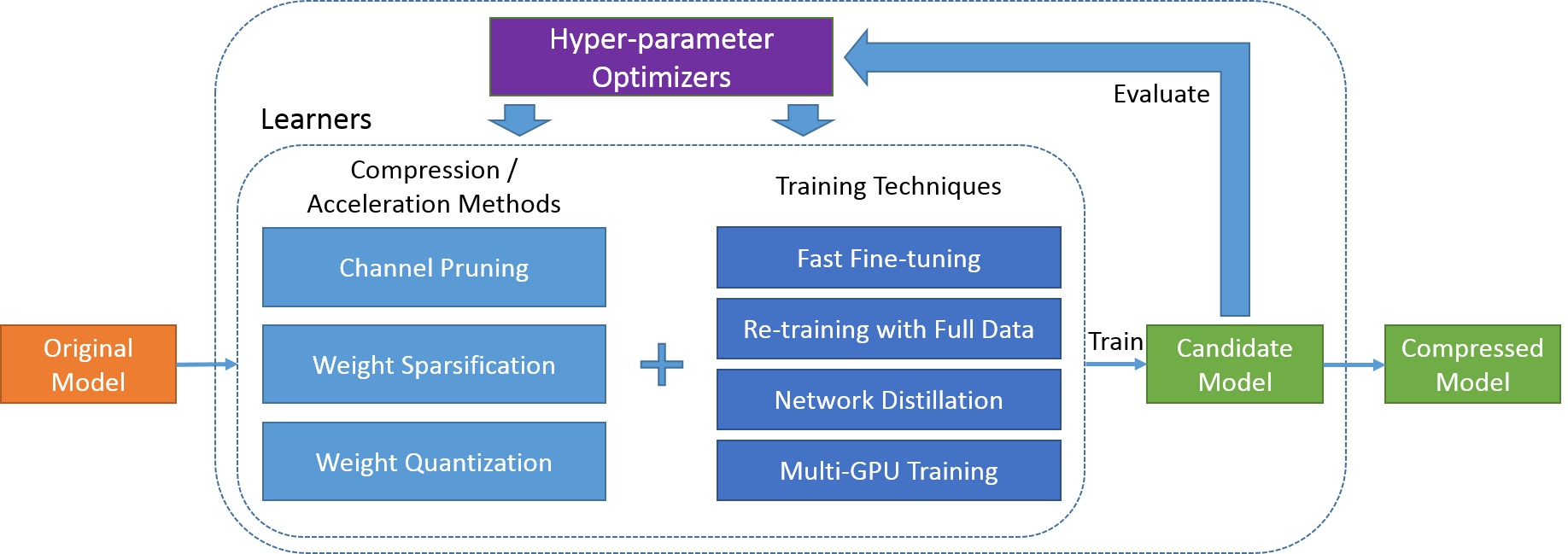
TVM
Open deep learning compiler stack for cpu, gpu and specialized accelerators
The Benchmark of caffe-android-lib, mini-caffe, and ncnn

若有收获,就点个赞吧
0 人点赞
