简介
在卷积网络中,大部分的计算耗费在计算卷积的过程中,尤其是在端上设备中,对于性能的要求更为苛刻。程序的性能优化是一个复杂而庞大的话题。高性能计算就像系统设计一样,虽然有一些指导原则,但是,对于不同的场景需要有不同的设计方案,因此,对于同一个优化问题,不同的人可能会给出完全不同的优化方案。本文不是探讨硬件和代码级的优化,仅针对计算卷积的一个特定方法 —— Winograd 方法做一个简单的记述。
卷积计算方法
首先明确一点,这里说的卷积计算是指深度学习卷积网络(ConvNet)的计算方式,而不是高数中的卷积计算。目前常见的计算卷积的方式主要有以下集中方法:
- 滑动窗口:这种方法就是基本的计算方式,但是计算比较慢,因此一般不采用这种方法。
- im2col:目前几乎所有的主流计算框架包括 Caffe, MXNet 等都实现了该方法。该方法把整个卷积过程转化成了 GEMM 过程,而 GEMM 在各种 BLAS 库中都是被极致优化的,一般来说,速度较快。可以参考这篇文章:Caffe中的底层数学计算函数
- FFT: 傅里叶变换和快速傅里叶变化是在经典图像处理里面经常使用的计算方法,但是,在 ConvNet 中通常不采用,主要是因为在 ConvNet 中的卷积模板通常都比较小,例如 3×3 等,这种情况下,FFT 的时间开销反而更大。
- Winograd:Winograd 是存在已久,但是最近被重新发现的方法,在大部分场景中,Winograd 方法都显示和较大的优势,目前 CUDNN 中计算卷积就使用了该方法。
Winograd 方法
Winograd 方法简单来讲,就是用更多的加法计算来减少乘法计算。因此,一个前提就是,在处理器中,乘法计算的时钟周期数要大于加法计算的时钟周期数。
Winograd 计算卷积需要完成的乘法的次数为:
𝜇(𝐹(𝑚×𝑛,𝑟×𝑠))=(𝑚+𝑛−1)×(𝑛+𝑠−1)μ(F(m×n,r×s))=(m+n−1)×(n+s−1)
𝑟×𝑠r×s 表示卷积核的大小,𝑚×𝑛m×n 表示输出大小,根据这两个参数一般可以推算输入大小。
做一个简单的对比计算:假设卷积核大小为 3×33×3,输出大小为 2×22×2,那么,窗或者 im2col 需要的乘法计算次数为:3×3×2×2=363×3×2×2=36,Winograd 需要的乘法计算次数为:(3+2−1)×(3+2−1)=16(3+2−1)×(3+2−1)=16。可以看出,Winograd 的乘法次数大大减少,相应的加法次数增加了,但是绝大部门平台上,乘法的耗费大于加法,因此可以加速。
Winograd 的证明方法较为复杂,要用到数论中的一些知识,但是,使用起来很简单。只需要按照如下公式计算:
𝑌=𝐴𝑇[[𝐺𝑔𝐺𝑇]⊙[𝐵𝑇𝑑𝐵]]𝐴Y=AT[[GgGT]⊙[BTdB]]A
其中,⊙⊙ 表示按元素乘,𝐴,𝐺,𝐵A,G,B 表示根据输出大小和卷积核大小不同有不同的定义,并且是提前确定了的。每种输出大小和卷积核的 𝐴,𝐺,𝐵A,G,B 具体是多少可以通过这种方法计算,𝑔g 表示卷积核,𝑑d 表示要进行卷积计算的数据,𝑔g 的大小为 𝑟×𝑟r×r,𝑑d 的大小为 (𝑚+𝑟−1)×(𝑚+𝑟−1)(m+r−1)×(m+r−1)。
以上描述的 Winograd 算法只展示了在二维的图像 (更确切的说是 tile) 上的过程,具体在 ConvNet 的多个 channel 的情况,直接逐个 channel 按照上述方法计算完然后相加即可。实践经验
但是 Winograd 应用也有一些局限:
- 在目前使用越来越多的 depthwise conv 中其优势不明显了。
- 在 tile 较大的时候,Winograd 方法不适用,因为,在做 inverse transform 的时候的计算开销抵消了 Winograd 带来的计算节省。
- Winograd 会产生误差,这个一定要注意,要做好相应的精度损失测试。
1. 为什么会引入 WinoGrad?
做过 ACM/OI 的朋友大家应该对 FFT 并不陌生,我们知道对于两个序列的乘法通过 FFT 可以从原始 O(n^2) 复杂度变成 O(nlogn),所以我们就会想着 FFT 这个算法是否可以应用到我们计算卷积中来呢?当然是可以的,但是 FFT 的计算有个问题哦,会引入复数。而移动端是不好处理复数的,对于小卷积核可能减少的计算量和复数运算带来的降速效果是不好说谁会主导的。所以在这种情况下,针对卷积的 WinoGrad 算法出现了,它不仅可以类似 FFT 一样降低计算量,它还不会引入复数,使得卷积的运算加速成为了可能。因此,本文尝试从工程实现的角度来看一下 WinoGrad,希望对从事算法加速的小伙伴有一些帮助。
2. 为什么会有这篇文章?
最近尝试给 MsnhNet 做
卷积的 WinoGrad 实现,然后开始了解这个算法,并尝试参考着 NCNN 来理解和动手写一下。参考了多篇优秀的讲解文章和 NCNN 源码,感觉算是对这个算法有了较为清楚的认识,这篇文章就记录一下我在实现
并且步长为
的 WinoGrad 卷积时的一些理解。这篇文章的重点是 WinoGrad 卷积的实现,关于 WinoGrad 卷积里面的变化矩阵如何推导可以看梁德澎作者的文章:详解 Winograd 变换矩阵生成原理 (听说后续他会做个视频来仔细讲讲 QAQ),现在就假设我们知道了 WinoGrad 的几个变换矩阵。如果你不知道也没关系,因为有一个 Python 工具包可以直接帮我们计算,地址为:https://github.com/andravin/wincnn 。然后现在我们就要用拿到的这几个矩阵来实现 WinoGrad 算法,听起来比较简单,但我们还是得一步步理清楚是不。
3. WinoGrad 算法原理
WinoGrad 算法起源于 1980 年,是 Shmuel Winograd 提出用来减少 FIR 滤波器计算量的一个算法。它指出对于输出个数为 ,参数个数为
,参数个数为 的 FIR 滤波器,不需要
的 FIR 滤波器,不需要 次乘法计算,而只需要
次乘法计算,而只需要
次乘法计算即可。
3.1 一维Winograd算法
以 1 维卷积为例,输入信号 ,卷积核
,卷积核 ,则卷积可写成如下矩阵乘法形式:
,则卷积可写成如下矩阵乘法形式: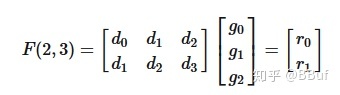
如果这个计算过程使用普通的矩阵乘法,则一共需要「6 次乘法和 4 次加法」 。
但是卷积运算中输入信号转换得到的矩阵不是任意矩阵,其有规律的分布着大量的重复元素,例如第一行的 和
和 ,卷积转换成的矩阵乘法比一般乘法的问题域更小,所以这就让优化存为了可能。
,卷积转换成的矩阵乘法比一般乘法的问题域更小,所以这就让优化存为了可能。
然后 WinoGrad 的做法就是: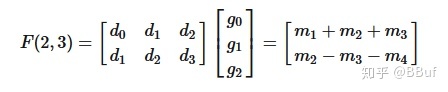
其中,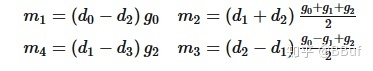
我们知道,在 CNN 的推理阶段,卷积核上的元素是固定的,所以上式中和g 相关的式子可以提前算好,在预测阶段只用计算一次,可以忽略。所以这里一共需要「4 次乘法加 4 次加法」。相比于普通的矩阵乘法,使用 WinoGrad 算法之后乘法次数减少了,这样就可以达到加速的目的了。
这个例子实际上是「1D 的 WinoGrad 算法」,我们将上面的计算过程写成矩阵的形式如下: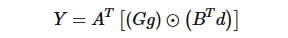
其中, 表示 element-wise multiplication(Hadamard product)对应位置相乘。
表示 element-wise multiplication(Hadamard product)对应位置相乘。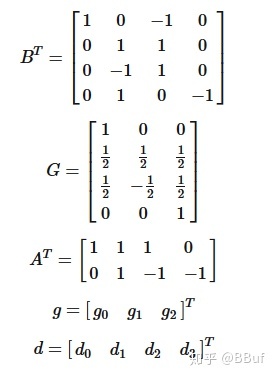
相关矩阵解释
所以整个计算过程可以分为 4 步:
 卷积的加速了,公式如下:
卷积的加速了,公式如下: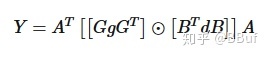
 为
为 的卷积核,
的卷积核, 为
为 的图像块。
的图像块。4. 从工程角度来看 WinoGrad
下面我们就从一个实际例子来说,如何利用 WinoGrad 来实现 并且步长为 1 的卷积运算。基于上面介绍的 2D WinoGrad 的原理,我们现在只需要分 4 步即可实现 WnoGrad 算法:
并且步长为 1 的卷积运算。基于上面介绍的 2D WinoGrad 的原理,我们现在只需要分 4 步即可实现 WnoGrad 算法:
接下来我们就以 WinoGrad 实现
并且步长为 1 的卷积计算为例子,来理解一下 WinoGrad 的工程实现。
4.1 对输入卷积核进行变换
这一步就是对卷积核进行变化,公式为: ,
,
其中 表示输出通道标号,
表示输出通道标号, 表示输入通道标号,一个
表示输入通道标号,一个 对应卷积核的一个
对应卷积核的一个 。由于我们要实现的是
。由于我们要实现的是 ,因此
,因此 是一个
是一个 的矩阵
的矩阵
4.2 对输入数据进行变换
对卷积核进行变换之后,接下来就轮到对输入矩阵进行变换了,即对 V 矩阵进行计算,
对于卷积核获得的每一个 ,我们都需要一个对应的
,我们都需要一个对应的 的图像块 (tile) 和它做卷积运算(eltwise_multiply)。所以这里我们首先需要确定输入数据可以被拆成多少个图像块,并且我们需要为变换矩阵 V 申请空间,从第三节可知:输入变换矩阵,尺寸为
的图像块 (tile) 和它做卷积运算(eltwise_multiply)。所以这里我们首先需要确定输入数据可以被拆成多少个图像块,并且我们需要为变换矩阵 V 申请空间,从第三节可知:输入变换矩阵,尺寸为 ,即每个小块的变换矩阵都为
,即每个小块的变换矩阵都为 ,但是输入特征图长宽不一定会被 8 整除,这个时候就需要对输入特征图进行扩展 (padding)
,但是输入特征图长宽不一定会被 8 整除,这个时候就需要对输入特征图进行扩展 (padding)
4.3 计算 M 矩阵
M 矩阵的计算公式为:
4.4 计算结果 Y 矩阵
现在就到了最后一步了,我们需要计算结果矩阵 Y,公式为:

5. WinoGrad 算法进一步加速
上面无论是针对 U,V,M 还是 Y 矩阵的计算我们使用的都是暴力计算,所以接下来可以使用 Neon Instrics 和 Neon Assembly 技术进行优化。介于篇幅原因,这里就不贴代码了,有需要学习的可以关注后续 MsnhNet 的 WinoGrad 代码部分https://github.com/msnh2012/Msnhnet/blob/master/src/layers/arm/MsnhConvolution3x3s1Winograd.cpp。这个代码实现的思路取自开源框架 NCNN,在此表示感谢 NCNN 这一优秀工作 (github:https://github.com/Tencent/ncnn)。
6. 何时开启 WinoGrad 卷积
和 Sgemm 用于 卷积一样,我们也需要思考 WinoGrad 在何种情况下是适用的,或者说是有明显加速的。这篇文章介绍的 WinoGrad 卷积是针对 NCHW 这种内存排布的,然后我们来看一下 NCNN 在基于 NCHW 这种内存排布下,是在何种情况下启用 WinoGrad(
卷积一样,我们也需要思考 WinoGrad 在何种情况下是适用的,或者说是有明显加速的。这篇文章介绍的 WinoGrad 卷积是针对 NCHW 这种内存排布的,然后我们来看一下 NCNN 在基于 NCHW 这种内存排布下,是在何种情况下启用 WinoGrad( )?
)?
通过查看 NCNN 的源码 (https://github.com/Tencent/ncnn/blob/master/src/layer/arm/convolution_arm.cpp) 可以发现,只有在输入输出通道均 >=16,并且特征图长宽均小于等于 120 的条件下才会启用 WinoGrad 卷积。
那么这个条件是如何得出的,除了和手工优化的conv3x3s1(https://github.com/msnh2012/Msnhnet/blob/master/src/layers/arm/MsnhConvolution3x3s1.cpp) 在不同条件下做速度对比测试之外,我们也可以感性的分析一下。
第一,WinoGrad 算法设计到几个矩阵变换,如果计算量不大,这几个矩阵变换的成本占计算总成本的比例就越大,所以 WinoGrad 应当是在计算量比较大时才能有效,如 VGG16。
第二,当计算量比较大的时候,又要考虑到 Cache 命中率的问题,这个时候 WinoGrad 访存可能会比直接手动优化更差,导致速度上不去。

若有收获,就点个赞吧
0 人点赞
