图解 BERT 模型:从零开始构建 BERT – 闪念基因 – 个人技术分享
# 图解 BERT 模型:从零开始构建 BERT
2019年1月26日本文首先介绍 BERT 模型要做什幺,即:模型的 输入 、 输出 分别是什幺,以及模型的 预训练任务 是什幺;然后,分析模型的 内部结构 ,图解如何将模型的输入一步步地转化为模型输出;最后,我们在多个中 / 英文、不同规模的数据集上比较了 BERT 模型与现有方法的 文本分类效果 。
1. 模型的输入 / 输出
BERT 模型的全称是: BidirectionalEncoder Representations from Transformer 。从名字中可以看出, BERT 模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的 Representation ,即:文本的语义表示,然后将文本的语义表示在特定 NLP 任务中作微调,最终应用于该 NLP 任务。煮个栗子, BERT 模型训练文本语义表示的过程就好比我们在高中阶段学习语数英、物化生等各门基础学科,夯实基础知识;而模型在特定 NLP 任务中的参数微调就相当于我们在大学期间基于已有基础知识、针对所选专业作进一步强化,从而获得能够应用于实际场景的专业技能。
在基于深度神经网络的 NLP 方法中,文本中的字 / 词通常都用一维向量来表示(一般称之为 “ 词向量 ” );在此基础上,神经网络会将文本中各个字或词的一维词向量作为输入,经过一系列复杂的转换后,输出一个一维词向量作为文本的语义表示。特别地,我们通常希望语义相近的字 / 词在特征向量空间上的距离也比较接近,如此一来,由字 / 词向量转换而来的文本向量也能够包含更为准确的语义信息。因此, BERT 模型的主要输入是文本中各个字 / 词的原始词向量,该向量既可以随机初始化,也可以利用 Word2Vector 等算法进行预训练以作为初始值;输出是文本中各个字 / 词融合了全文语义信息后的向量表示,如下图所示(为方便描述且与 BERT 模型的当前中文版本保持一致,本文统一以 字向量 作为输入):
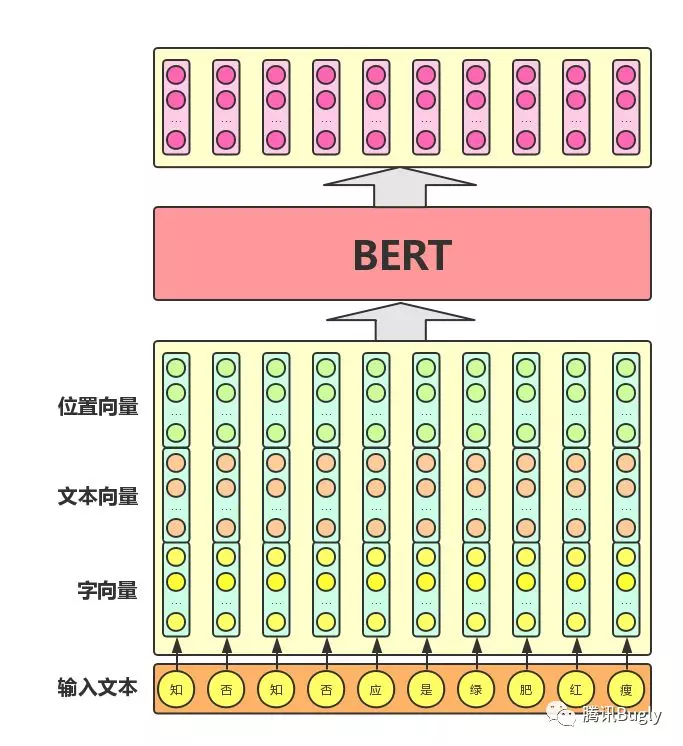 从上图中可以看出, BERT 模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。此外,模型输入除了字向量,还包含另外两个部分:
从上图中可以看出, BERT 模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。此外,模型输入除了字向量,还包含另外两个部分:
1. 文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字 / 词的语义信息相融合
2. 位置向量:由于出现在文本不同位置的字 / 词所携带的语义信息存在差异(比如: “ 我爱你 ” 和 “ 你爱我 ” ),因此, BERT 模型对不同位置的字 / 词分别附加一个不同的向量以作区分
最后, BERT 模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的 BERT 模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位( WordPiece ),例如:将 playing 分割为 play 和 ##ing ;此外,对于中文,目前作者尚未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
对于不同的 NLP 任务,模型输入会有微调,对模型输出的利用也有差异,例如:
单文本分类任务:对于文本分类任务, BERT 模型在文本前插入一个 [CLS] 符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字 / 词相比,这个无明显语义信息的符号会更 “ 公平 ” 地融合文本中各个字 / 词的语义信息。
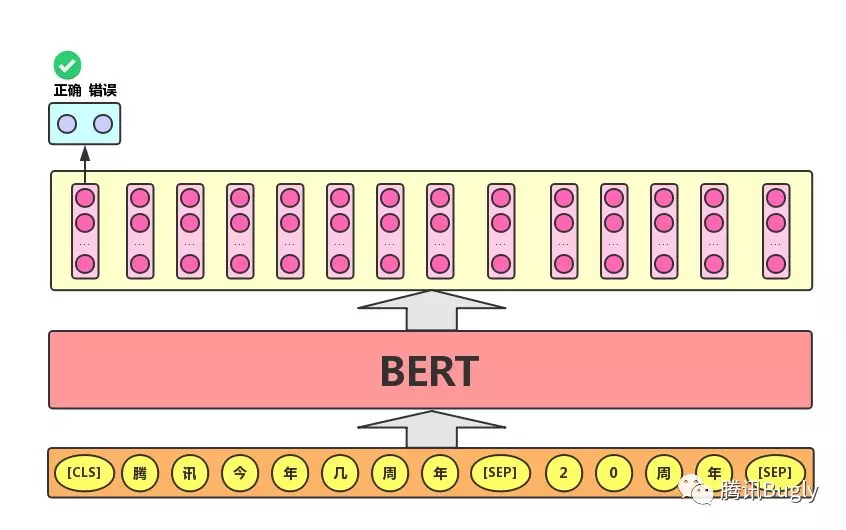
 语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务, BERT 模型除了添加 [CLS] 符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个 [SEP] 符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示。
语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务, BERT 模型除了添加 [CLS] 符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个 [SEP] 符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示。
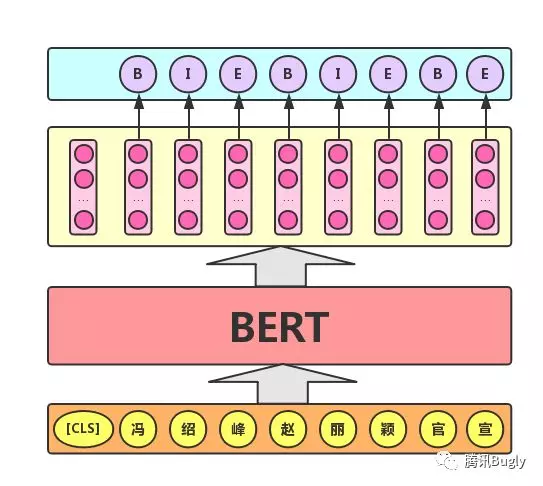
 序列标注任务:该任务的实际应用场景包括:中文分词 & 新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务, BERT 模型利用文本中每个字对应的输出向量对该字进行标注(分类),如下图所示 (B 、 I 、 E 分别表示一个词的第一个字、中间字和最后一个字 ) 。
序列标注任务:该任务的实际应用场景包括:中文分词 & 新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务, BERT 模型利用文本中每个字对应的输出向量对该字进行标注(分类),如下图所示 (B 、 I 、 E 分别表示一个词的第一个字、中间字和最后一个字 ) 。
 ……
……
根据具体任务的不同,在实际应用中我们可以脑洞大开,通过调整模型的输入、输出将模型适配到真实业务场景中。
2. 模型的预训练任务
BERT 实际上是一个语言模型。语言模型通常采用大规模、与特定 NLP 任务无关的文本语料进行训练,其目标是学习语言本身应该是什幺样的,这就好比我们学习语文、英语等语言课程时,都需要学习如何选择并组合我们已经掌握的词汇来生成一篇通顺的文本。回到 BERT 模型上,其预训练过程就是逐渐调整模型参数,使得模型输出的文本语义表示能够刻画语言的本质,便于后续针对具体 NLP 任务作微调。为了达到这个目的, BERT 文章作者提出了两个预训练任务: Masked LM 和 Next Sentence Prediction 。
2.1 Masked LM
Masked LM 的任务描述为:给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词汇预测被抹去的几个词分别是什幺,如下图所示。
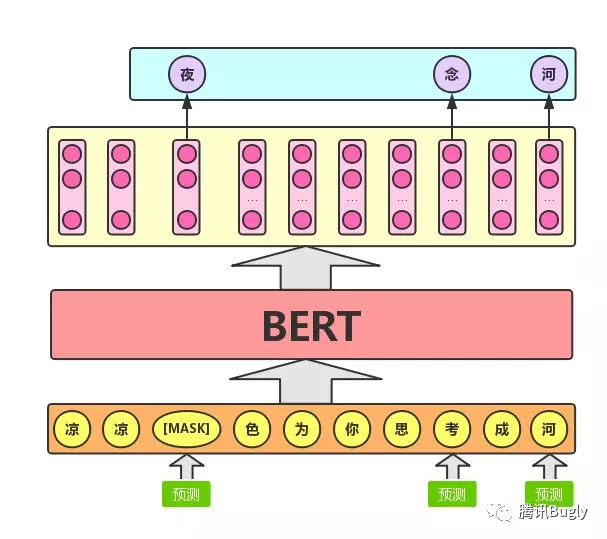 这不就是我们高中英语常做的 完形填空 幺!所以说, BERT 模型的预训练过程其实就是在模仿我们学语言的过程。具体来说,文章作者在一句话中随机选择 15% 的词汇用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。这幺做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这幺做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
这不就是我们高中英语常做的 完形填空 幺!所以说, BERT 模型的预训练过程其实就是在模仿我们学语言的过程。具体来说,文章作者在一句话中随机选择 15% 的词汇用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。这幺做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这幺做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
2.2 NextSentence Prediction
Next Sentence Prediction 的任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示。
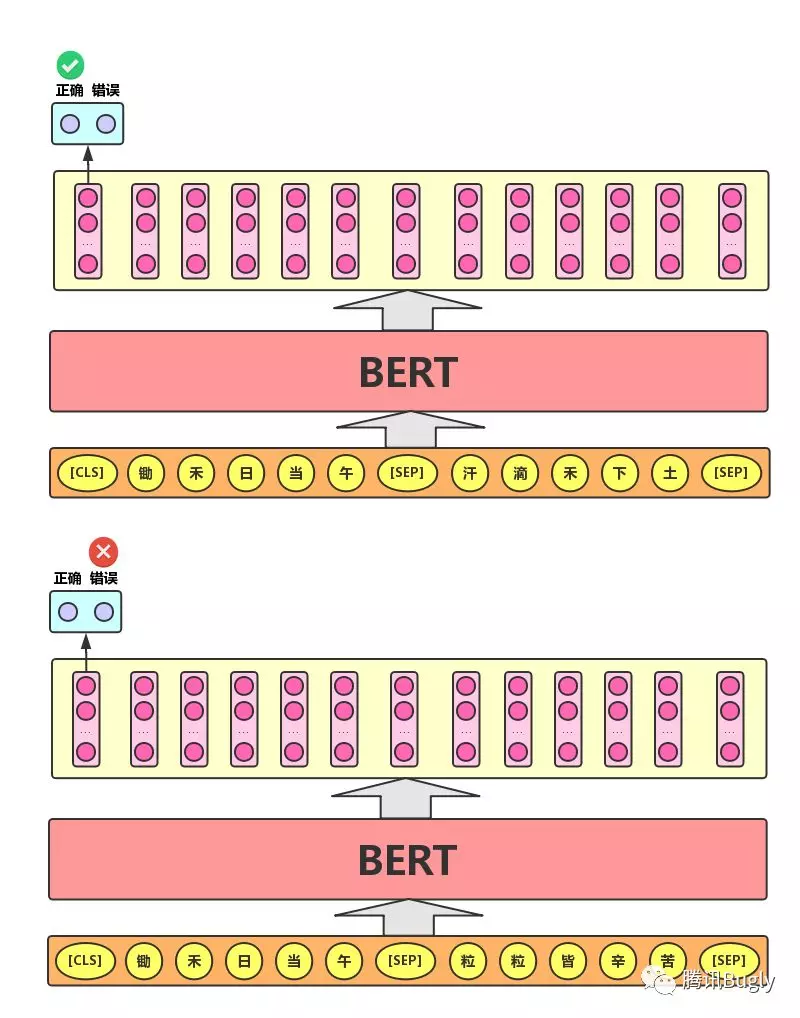 当年大学考英语四六级的时候,大家应该都做过 段落重排序 ,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。 Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
当年大学考英语四六级的时候,大家应该都做过 段落重排序 ,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。 Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
BERT 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
3. 模型结构
了解了 BERT 模型的输入 / 输出和预训练过程之后,我们来看一下 BERT 模型的内部结构。前面提到过, BERT 模型的全称是: BidirectionalEncoder Representations from Transformer ,也就是说, Transformer 是组成 BERT 的核心模块,而 Attention 机制又是 Transformer 中最关键的部分,因此,下面我们从 Attention 机制开始,介绍如何利用 Attention 机制构建 Transformer 模块,在此基础上,用多层 Transformer 组装 BERT 模型。
3.1 Attention 机制
Attention: Attention 机制的中文名叫 “ 注意力机制 ” ,顾名思义,它的主要作用是让神经网络把 “ 注意力 ” 放在一部分输入上,即:区分输入的不同部分对输出的影响。这里,我们从增强字 / 词的语义表示这一角度来理解一下 Attention 机制。
我们知道,一个字 / 词在一篇文本中表达的意思通常与它的上下文有关。比如:光看 “ 鹄 ” 字,我们可能会觉得很陌生(甚至连读音是什幺都不记得吧),而看到它的上下文 “ 鸿鹄之志 ” 后,就对它立马熟悉了起来。因此,字 / 词的上下文信息有助于增强其语义表示。同时,上下文中的不同字 / 词对增强语义表示所起的作用往往不同。比如在上面这个例子中, “ 鸿 ” 字对理解 “ 鹄 ” 字的作用最大,而 “ 之 ” 字的作用则相对较小。为了有区分地利用上下文字信息增强目标字的语义表示,就可以用到 Attention 机制。
Attention 机制主要涉及到三个概念: Query 、 Key 和 Value 。在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始 Value , Attention 机制将目标字作为 Query 、其上下文的各个字作为 Key , 并将 Query 与各个 Key 的相似性作为权重,把上下文各个字的 Value 融入目标字的原始 Value 中。如下图所示, Attention 机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的 Query 向量表示、上下文各个字的 Key 向量表示以及目标字与上下文各个字的原始 Value 表示,然后计算 Query 向量与各个 Key 向量的相似度作为权重,加权融合目标字的 Value 向量和各个上下文字的 Value 向量,作为 Attention 的输出,即:目标字的增强语义向量表示。
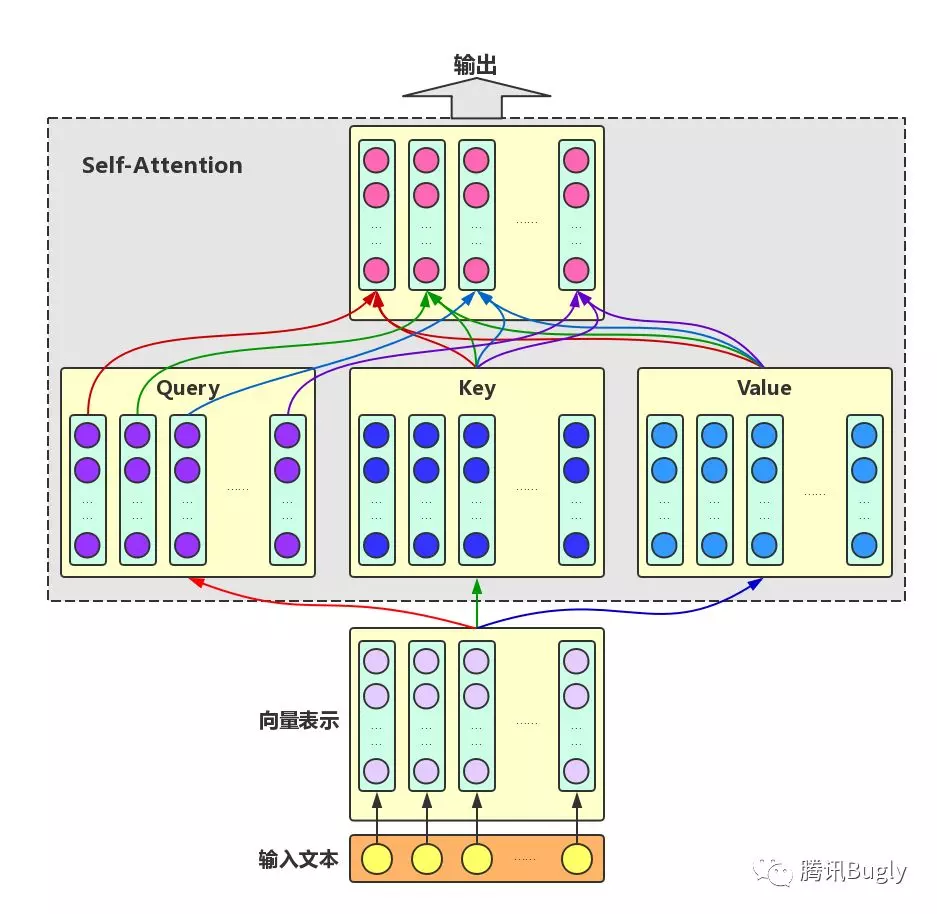
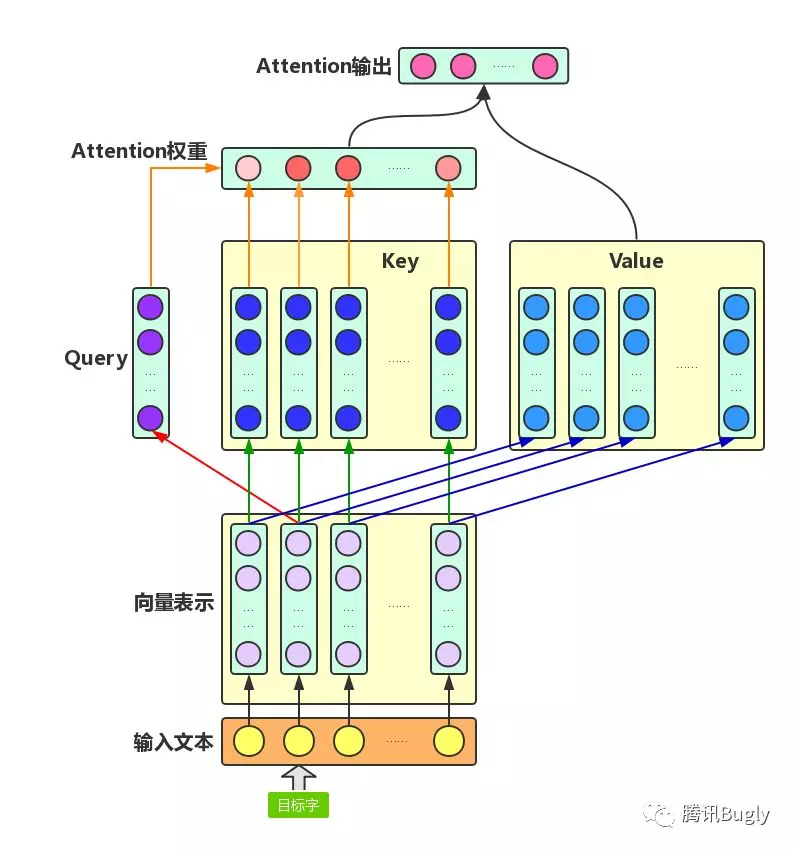 Self-Attention: 对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为 Query ,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下, Query 、 Key 和 Value 的向量表示均来自于同一输入文本,因此,该 Attention 机制也叫 Self-Attention 。
Self-Attention: 对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为 Query ,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下, Query 、 Key 和 Value 的向量表示均来自于同一输入文本,因此,该 Attention 机制也叫 Self-Attention 。
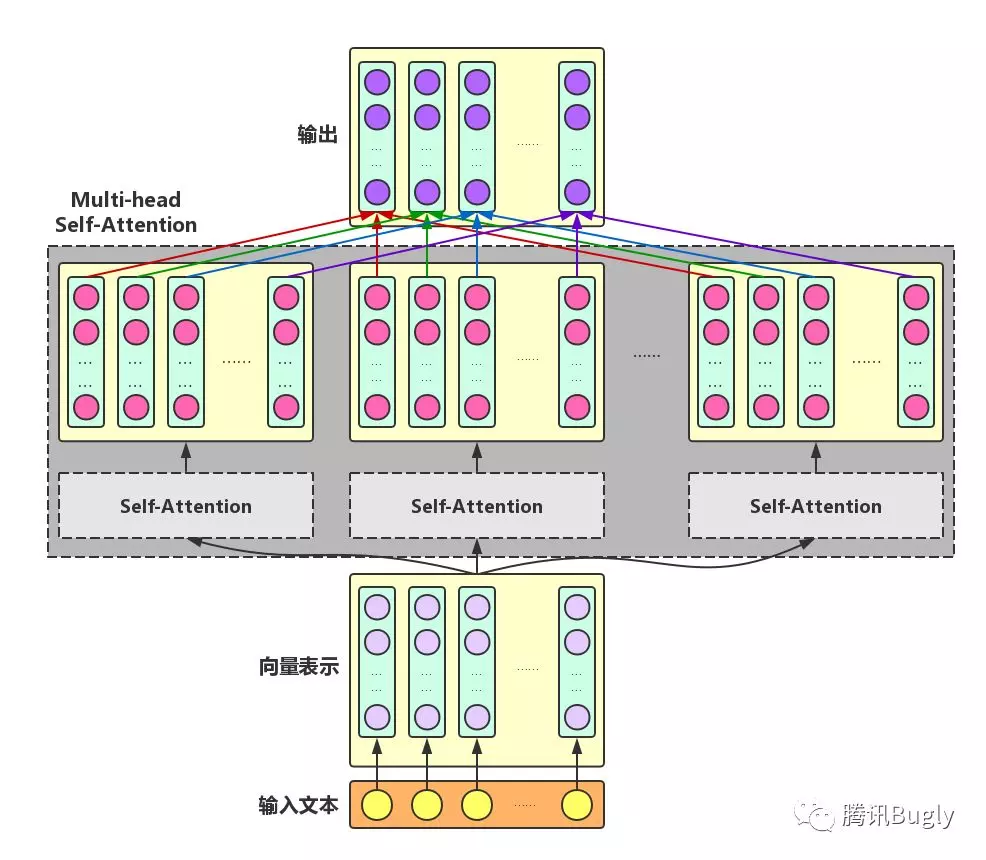
 Multi-head Self-Attention: 为了增强 Attention 的多样性,文章作者进一步利用不同的 Self-Attention 模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量,如下图所示。
Multi-head Self-Attention: 为了增强 Attention 的多样性,文章作者进一步利用不同的 Self-Attention 模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量,如下图所示。
 这里,我们再给出一个例子来帮助理解 Multi-head Self-Attention (注:这个例子仅用于帮助理解,并非严格正确)。看下面这句话: “ 南京市长江大桥 ” ,在不同语义场景下对这句话可以有不同的理解: “ 南京市 / 长江大桥 ” ,或 “ 南京市长 / 江大桥 ” 。对于这句话中的 “ 长 ” 字,在前一种语义场景下需要和 “ 江 ” 字组合才能形成一个正确的语义单元;而在后一种语义场景下,它则需要和 “ 市 ” 字组合才能形成一个正确的语义单元。我们前面提到, Self-Attention 旨在用文本中的其它字来增强目标字的语义表示。在不同的语义场景下, Attention 所重点关注的字应有所不同。因此, Multi-head Self-Attention 可以理解为考虑多种语义场景下目标字与文本中其它字的语义向量的不同融合方式。可以看到, Multi-head Self-Attention 的输入和输出在形式上完全相同,输入为文本中各个字的原始向量表示,输出为各个字融合了全文语义信息后的增强向量表示。因此, Multi-head Self-Attention 可以看作是对文本中每个字分别增强其语义向量表示的黑盒。
这里,我们再给出一个例子来帮助理解 Multi-head Self-Attention (注:这个例子仅用于帮助理解,并非严格正确)。看下面这句话: “ 南京市长江大桥 ” ,在不同语义场景下对这句话可以有不同的理解: “ 南京市 / 长江大桥 ” ,或 “ 南京市长 / 江大桥 ” 。对于这句话中的 “ 长 ” 字,在前一种语义场景下需要和 “ 江 ” 字组合才能形成一个正确的语义单元;而在后一种语义场景下,它则需要和 “ 市 ” 字组合才能形成一个正确的语义单元。我们前面提到, Self-Attention 旨在用文本中的其它字来增强目标字的语义表示。在不同的语义场景下, Attention 所重点关注的字应有所不同。因此, Multi-head Self-Attention 可以理解为考虑多种语义场景下目标字与文本中其它字的语义向量的不同融合方式。可以看到, Multi-head Self-Attention 的输入和输出在形式上完全相同,输入为文本中各个字的原始向量表示,输出为各个字融合了全文语义信息后的增强向量表示。因此, Multi-head Self-Attention 可以看作是对文本中每个字分别增强其语义向量表示的黑盒。
3.2 Transformer Encoder
在 Multi-headSelf-Attention 的基础上再添加一些 “ 佐料 ” ,就构成了大名鼎鼎的 Transformer Encoder 。实际上, Transformer 模型还包含一个 Decoder 模块用于生成文本,但由于 BERT 模型中并未使用到 Decoder 模块,因此这里对其不作详述。下图展示了 Transformer Encoder 的内部结构,可以看到, Transformer Encoder 在 Multi-head Self-Attention 之上又添加了三种关键操作:
残差连接( ResidualConnection ):将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本考虑是:修改输入比重构整个输出更容易( “ 锦上添花 ” 比 “ 雪中送炭 ” 容易多了!)。这样一来,可以使网络更容易训练。
Layer Normalization :对某一层神经网络节点作 0 均值 1 方差的标准化。
线性转换:对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度相同。
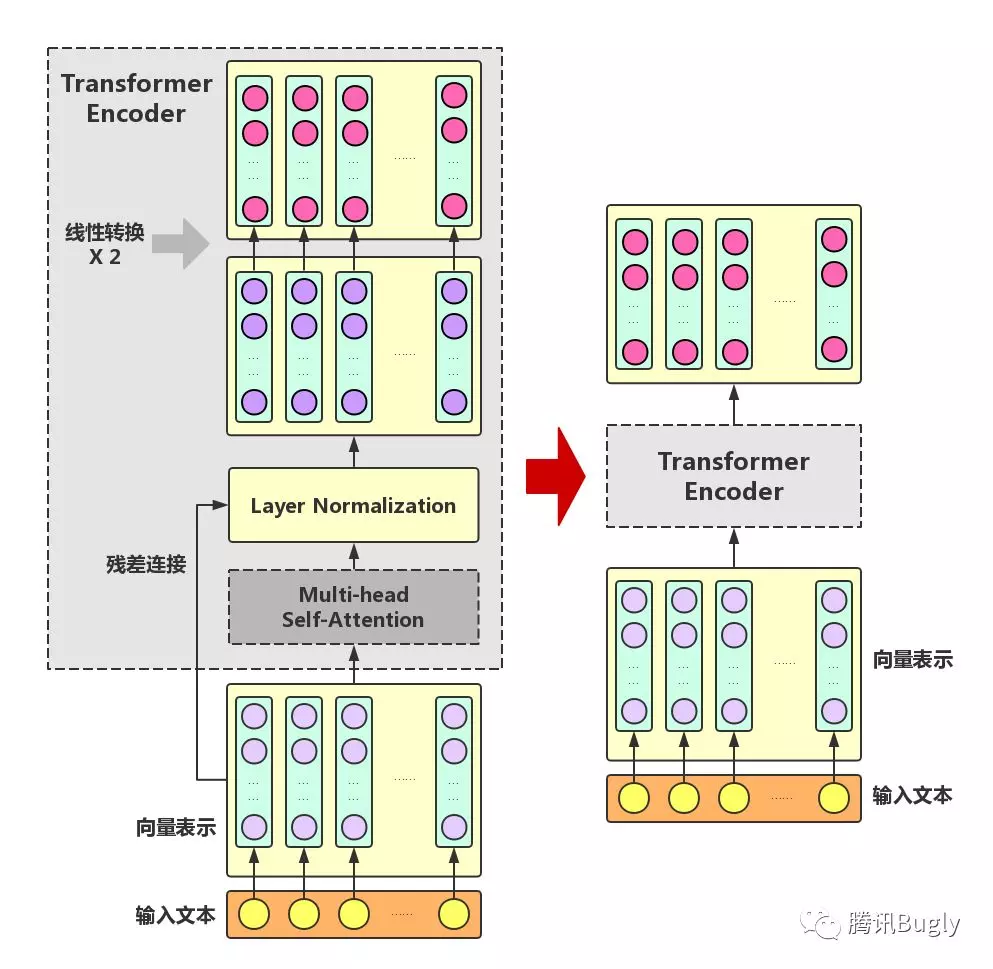 可以看到, Transformer Encoder 的输入和输出在形式上还是完全相同,因此, Transformer Encoder 同样可以表示为将输入文本中各个字的语义向量转换为相同长度的增强语义向量的一个黑盒。
可以看到, Transformer Encoder 的输入和输出在形式上还是完全相同,因此, Transformer Encoder 同样可以表示为将输入文本中各个字的语义向量转换为相同长度的增强语义向量的一个黑盒。
3.3 BERT model
组装好 TransformerEncoder 之后,再把多个 Transformer Encoder 一层一层地堆叠起来, BERT 模型就大功告成了!
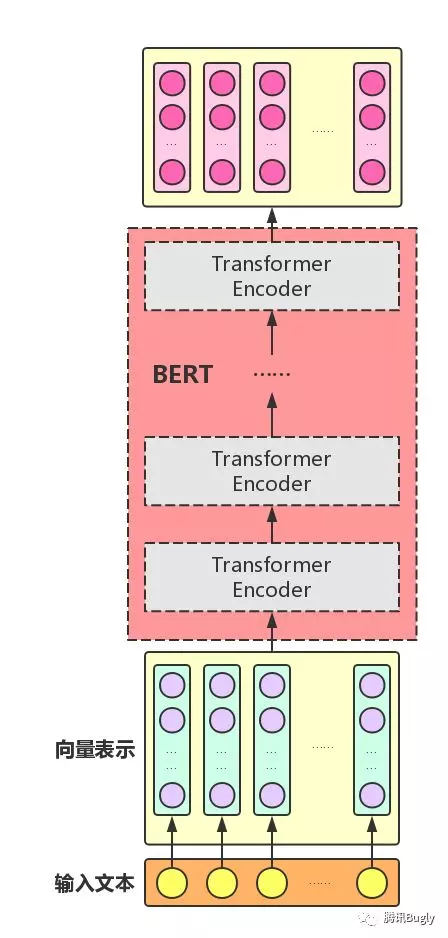 在论文中,作者分别用 12 层和 24 层 Transformer Encoder 组装了两套 BERT 模型,两套模型的参数总数分别为 110M 和 340M 。
在论文中,作者分别用 12 层和 24 层 Transformer Encoder 组装了两套 BERT 模型,两套模型的参数总数分别为 110M 和 340M 。
4. BERT 模型的文本分类效果
在本文中,我们聚焦文本分类任务,对比分析 BERT 模型在中 / 英文、不同规模数据集上的文本分类效果。我们基于 Google 预训练好的 BERT 模型( 中文采用chinese_L-12_H-768_A-12模型,下载链接: https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip; 英文采用uncased_L-12_H-768_A-12模型,下载链接: https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip)。 我们一共选择了 6 个数据集进行实验,各数据集的训练集 / 测试集大小、分类任务、类别数和语言类型如下表所示。
| 数据集 | 训练集大小 | 测试集大小 | 分类任务 | 类别数 | 语言类型 | | —- | —- | —- | —- | —- | —- |
| 商品评论情感分析 | 9653 | 1145 | 情感极性分类 | 3 | 中文 |
| Sentiment_XS | 29613 | 11562 | 情感极性分类 | 2 | 中文 |
| 立场分析 | 2914 | 1249 | 立场分类 | 3 | 英文 |
| AG’s News | 120000 | 7600 | 新闻分类 | 4 | 英文 |
| Yelp Review Full | 650000 | 50000 | 情感分类 | 5 | 英文 |
| Yahoo! Answers | 1400000 | 60000 | 问答系统 | 10 | 英文 |
4.1 商品评论情感分析
该数据集旨在分析微博中表达的对特定商品的情感倾向:正面、负面或中立。我们选择了三种方法与 BERT 模型进行对比:
XGBoost : NGram 特征 +XGBoost 分类器
Char-level CNN :将未分词的文本直接输入卷积神经网络(已对比发现 Word-level CNN 效果略差)
Attention-based RNN :将分词后的文本输入循环神经网络(已对比发现 Char-level RNN 效果略差),并且在最终分类前采用 Attention 机制融合输入各个词对应的 hidden states
BERT 模型与三种对比方法的正面、负面、中立情感分类 F1 值如下:
| 方法 | 正面 F1 值 | 负面 F1 值 | 中立 F1 值 | | —- | —- | —- | —- |
| XGBoost | 67% | 60% | 91% |
| Char-level CNN | 69% | 74% | 92% |
| Attention-based RNN | 66% | 71% | 91% |
| BERT | 71% | 76% | 92% |
从上表中可以看到, BERT 模型在正、负、中立 F1 值上均碾压了 所有 对比方法!
4.2 Sentiment_XS
该数据集来自于论文 “SentimentClassification with Convolutional Neural Networks: an Experimental Study on aLarge-scale Chinese Conversation Corpus” ( DOI:10.1109/CIS.2016.0046 ),旨在对短文本进行正 / 负面情感极性分类。我们选择论文中的部分代表性对比方法与 BERT 模型进行对比,包括:支持向量机分类器( SVC )、逻辑回归( LR )、 Naive Bayes SVM ( NBSVM )和卷积神经网络( CNN ),分类准确率如下表所示(对比方法的实验数据来自于论文)。
| 方法 | 分类准确率 | | —- | —- |
| SVC | 81.89% |
| LR | 81.84% |
| NBSVM | 81.18% |
| CNN | 87.12% |
| BERT | 90.01% |
可以看到, BERT 模型在 Sentiment_XS 数据集上的分类准确率再次碾压了 所有 对比方法!
4.3 立场分析
该数据集来自于国外文本分析评测比赛 SemEval-2016 的任务 6A :有监督立场分类,旨在分析文本中对 5 个话题的支持、反对或中立态度,包括:有神论、气候变化、女权运动、 Hillary Clinton 和堕胎合法化。因此,该数据集实际上对应 5 个话题子集。分类效果的官方评估指标为支持类别 F1 值和反对类别 F1 值的宏平均。我们选择了当前立场分析领域的四个最优方法与 BERT 模型进行对比,包括:
SVM : NGram 特征 + 支持向量机分类器,该方法取得了当时参加评测的所有方法的最优分类效果
MITRE :基于循环神经网络( LSTM )的方法,在参加评测的神经网络方法中取得最优效果
pkudblab :基于卷积神经网络的方法,在参加评测的神经网络方法中效果仅次于 MITRE
TGMN-CR :结合动态记忆模块与循环神经网络的方法,近期提出的最新方法
上述方法与 BERT 模型在 5 个数据子集上的分类效果如下表所示(对比方法的数据来自于论文: A Target-GuidedNeural Memory Model for Stance Detection in Twitter , DOI : 10.1109/IJCNN.2018.8489665 )。
| 方法 | 有神论 | 气候变化 | 女权运动 | Hillary Clinton | 堕胎合法化 | | —- | —- | —- | —- | —- | —- |
| SVM | 65.19% | 42.35% | 57.46% | 58.63% | 66.42% |
| MITRE | 61.47% | 41.63% | 62.09% | 57.67% | 57.28% |
| pkudblab | 63.34% | 52.69% | 51.33% | 64.41% | 61.09% |
| TGMN-CR | 64.6% | 43.02% | 59.35% | 66.21% | 66.21% |
| BERT | 75.51% | 46.04% | 55.35% | 67.54% | 62.5% |
从上表中可以看到, BERT 模型在 2 个数据子集中都取得了最优效果,尤其是 “ 有神论 ” 数据集, F1 值超过当前最优算法约 10% !不过,在其余三个数据子集中, BERT 模型的表现比较一般。
4.4 AG’s News& Yelp Review Full & Yahoo! Answers
这三个数据集算是文本分类领域的经典数据集了,分别对应新闻分类、情感分类和问答系统任务。这里,我们选择了 4 种在这三个数据集上进行过实验验证的方法与 BERT 模型进行对比,包括:
char-CNN :将未分词的文本直接输入卷积神经网络
FastText :一种用于文本分类的快速神经网络方法
VDCNN : Very Deep CNN ,顾名思义,非常非常深的卷积神经网络 Region embedding :利用局部文本语义信息增强文本中每个词的语义向量表示,输入到一个简单神经网络中进行分类
DPCNN : Deep Pyramid CNN ,同样是非常深的神经网络,通过池化操作使网络的每层神经元个数不断减半,因此,整个神经网络看起来像是一个金字塔结构
上述对比方法与 BERT 模型在三个数据集上的分类准确率如下表所示(对比方法的数据来自于论文: A New method ofRegion Embedding for Text Classification 和 Deep PyramidConvolutional Neural Networks for Text Categorization )。
| 方法 | AG’s News | Yelp Review Full | Yahoo! Answers | | —- | —- | —- | —- |
| char-CNN | 87.2% | 62% | 71.2% |
| FastText | 92.5% | 63.9% | 72.3% |
| VDCNN | 91.3% | 64.7% | 73.4% |
| Region embedding | 92.8% | 64.9% | 73.7% |
| DPCNN | 93.1% | 69.4% | 76.1% |
| BERT | 94.6% | 66.0% | 74.2% |
上表表明, BERT 模型在 AG’s News 数据集上取得了最高的分类准确率,在 Yelp Review Full 和 Yahoo! Answers 数据集上也都取得了次高的分类准确率。需要注意的是,我们目前仅使用 12 层 Transformer Encoder 结构的 BERT 模型进行实验,后续会进一步检验 24 层 TransformerEncoder 结构的 BERT 模型的分类效果,可以期待, BERT 模型的分类效果应该会随着网络结构的加深而进一步有所提高。
5. 结语
本文分析了 BERT 模型的内部结构与原理,并在文本分类任务上检验了模型效果。从实验结果中可以看出, BERT 模型 的文本分类 效果在许多中 / 英文数据集上都超过了现有方法,体现出了很强的泛用性。后续我们将继续检验 BERT 模型在其它 NLP 任务中的效果,并研究提升模型训练效率的方法,欢迎大家批评与指正!
Citations
Devlin J, Chang M W, Lee K, et al. Bert:Pre-training of deep bidirectional transformers for language understanding[J].arXiv preprint arXiv:1810.04805, 2018.
Vaswani A, Shazeer N, Parmar N, et al.Attention is all you need[C]//Advances in Neural Information ProcessingSystems. 2017: 5998-6008.
Zhang L, Chen C. Sentimentclassification with convolutional neural networks: an experimental study on alarge-scale Chinese conversation corpus[C]//Computational Intelligence andSecurity (CIS), 2016 12th International Conference on. IEEE, 2016: 165-169.
Mohammad S, Kiritchenko S, Sobhani P, etal. Semeval-2016 task 6: Detecting stance in tweets[C]//Proceedings of the 10thInternational Workshop on Semantic Evaluation (SemEval-2016). 2016: 31-41.
Zarrella G, Marsh A. MITRE atsemeval-2016 task 6: Transfer learning for stance detection[J]. arXiv preprintarXiv:1606.03784, 2016.
Wei W, Zhang X, Liu X, et al. pkudblabat semeval-2016 task 6: A specific convolutional neural network system foreffective stance detection[C]//Proceedings of the 10th International Workshopon Semantic Evaluation (SemEval-2016). 2016: 384-388.
Wei P, Mao W, Zeng D. A Target-GuidedNeural Memory Model for Stance Detection in Twitter[C]//2018 InternationalJoint Conference on Neural Networks (IJCNN). IEEE, 2018: 1-8.
Joulin A, Grave E, Bojanowski P, et al.Bag of tricks for efficient text classification[J]. arXiv preprintarXiv:1607.01759, 2016.
Conneau A, Schwenk H, Barrault L, et al.Very deep convolutional networks for natural language processing[J]. arXivpreprint, 2016.
Johnson R, Zhang T. Deep pyramidconvolutional neural networks for text categorization[C]//Proceedings of the55th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers). 2017, 1: 562-570.
如果您觉得我们的内容还不错,就请转发到朋友圈,和小伙伴一起分享吧~

若有收获,就点个赞吧
0 人点赞
