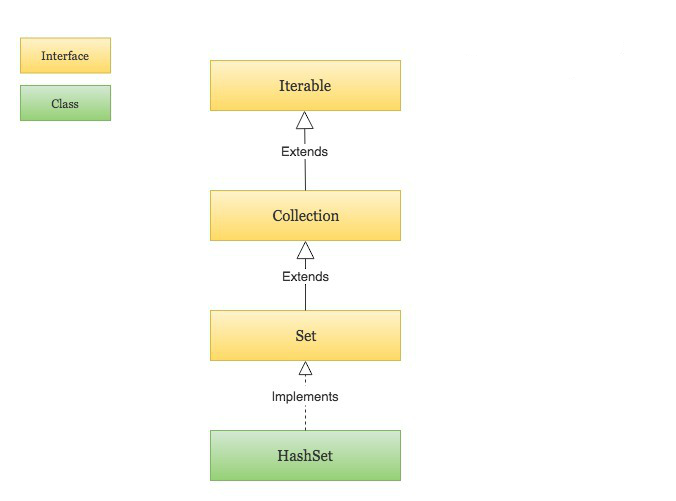
HashSet 基于 HashMap 来实现的,是一个所存储元素不可重复的集合 HashSet 是无序的,即不会记录插入的顺序 HashSet 是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法 HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问 HashSet 允许有 null 值 HashSet 实现了 Set 接口
HashSet 中的元素实际上是对象,一些常见的基本类型可以使用它的包装类。
基本类型对应的包装类表如下:
| 基本类型 | 引用类型 |
|---|---|
| boolean | Boolean |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
import java.util.HashSet; // HashSet 类位于 java.util 包中,使用前需要引入它HashSet<String> sites = new HashSet<String>(); //以下实例我们创建一个 HashSet 对象 sites,用于保存字符串元素:
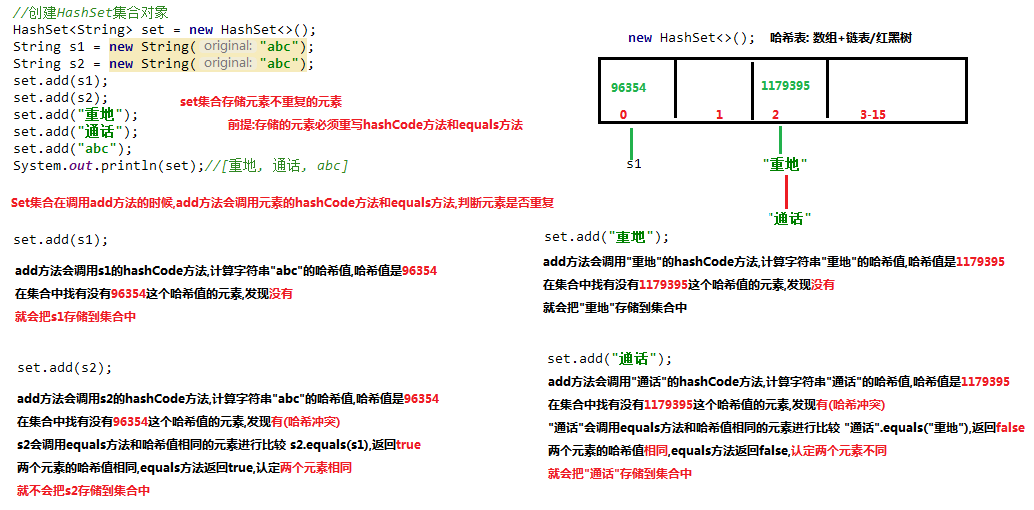
hasCode()的特殊
System.out.println("重地".hashCode()); //1179395
System.out.println("通话".hashCode()); //1179395
什么是哈希表呢?
在JDK1.8之前,哈希表底层采用 数组+链表 实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用 数组+链表+红黑树 实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间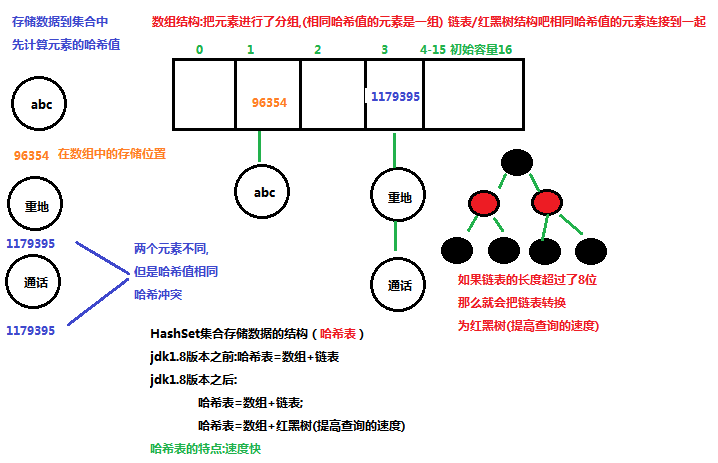
HashSet存储自定义类型元素
import java.util.*;
class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public String toString() {
return "person{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}
public class Test {
public static void main(String[] args) {
//创建集合对象 该集合中存储 Student类型对象
HashSet<Student> stuSet = new HashSet<Student>();
//存储
stuSet.add(new Student("于谦", 1));
stuSet.add(new Student("郭德纲", 44));
stuSet.add(new Student("郭德纲", 44));
stuSet.add(new Student("于谦", 43));
stuSet.add(new Student("郭麒麟", 23));
for (Student stu2 : stuSet) {
System.out.println(stu2);
}
}
}
/*
执行结果:
person{name='郭德纲', age=44}
person{name='于谦', age=43}
person{name='郭麒麟', age=23}
person{name='于谦', age=1}
*/
添加元素
HashSet 类提供类很多有用的方法,添加元素可以使用 add() 方法:
import java.util.HashSet;
public class Test {
public static void main(final String[] args) {
final HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Apple");
sites.add("MicroSoft");
sites.add("Apple"); // 重复的元素不会被添加
System.out.println(sites); // [Google, Apple, MicroSoft]
}
}
在上面的实例中,Apple 被添加了两次,它在集合中也只会出现一次,因为集合中的每个元素都必须是唯一的
判断元素是否存在
我们可以使用 contains() 方法来判断元素是否存在于集合当中:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Apple");
sites.add("MicroSoft");
sites.add("Apple"); // 重复的元素不会被添加
System.out.println(sites.contains("Google")); // true
}
}
删除元素
我们可以使用 remove() 方法来删除集合中的元素:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Apple");
sites.add("MicroSoft");
sites.add("Apple"); // 重复的元素不会被添加
sites.remove("MicroSoft"); // 删除元素,删除成功返回 true,否则为 false
System.out.println(sites); // [Google, Apple]
}
}
删除集合中所有元素可以使用 clear 方法:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Apple");
sites.add("MicroSoft");
sites.add("Apple"); // 重复的元素不会被添加
sites.clear();
System.out.println(sites); // []
}
}
计算大小
如果要计算 HashSet 中的元素数量可以使用 size() 方法:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Apple");
sites.add("MicroSoft");
sites.add("Apple"); // 重复的元素不会被添加
System.out.println(sites.size()); // 3
}
}
迭代 HashSet
可以使用 for-each 来迭代 HashSet 中的元素
import java.util.HashSet;
import java.util.Iterator;
public class Test {
public static void main(String[] args) {
HashSet<String> sites = new HashSet<String>();
sites.add("Google");
sites.add("Apple");
sites.add("MicroSoft");
sites.add("Apple"); // 重复的元素不会被添加
for (String i : sites) {
System.out.println(i);
}
Iterator<String> sitesIterator = sites.iterator();
while (sitesIterator.hasNext()) {
System.out.println(sitesIterator.next());
}
}
}
/*
* Google Apple MicroSoft
* Google Apple MicroSoft
*/

若有收获,就点个赞吧
0 人点赞
