常用垃圾回收算法
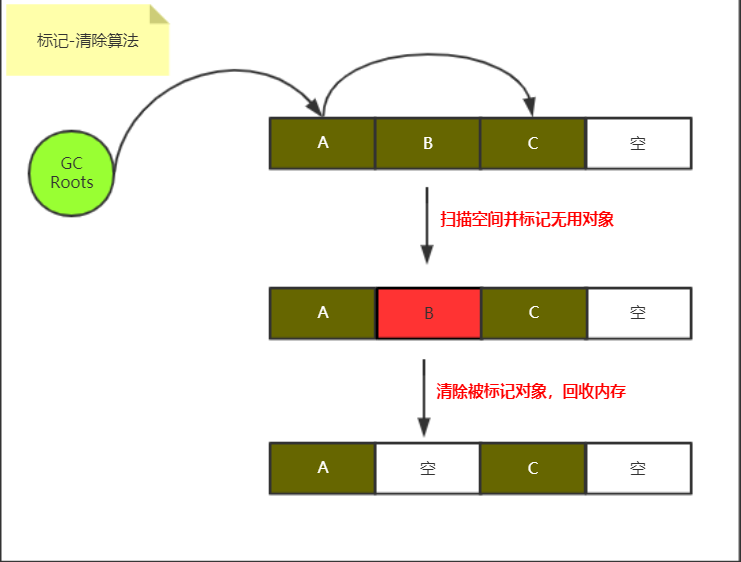
一、标记-清除算法
算法执行步骤:
1、标记:遍历内存区域,标记所有需要回收的对象(结合可达性分析算法对无用对象进行标记)
2、清除:遍历内存区域,统一回收所有被标记的对象内存
缺点:
1、两次遍历,效率过低
2、容易产生大量内存碎片,当再需要一块较大的内存时,无法找到一块满足要求的,因而不得不再次触发GC
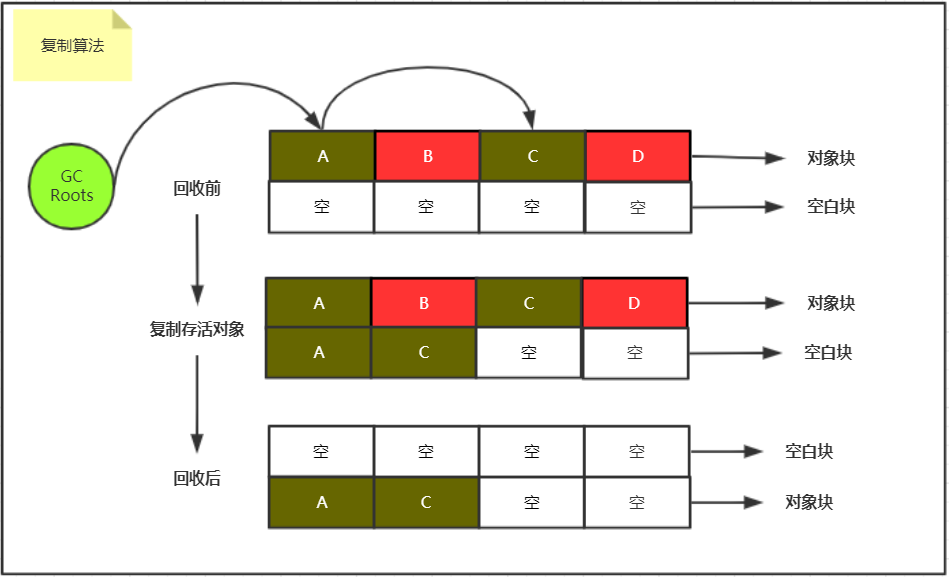
二、复制算法
算法描述:将内存空间分为等大的两块(对象块&空白块),每次只使用其中一块,当一块用完之后,触发GC时,将该块中尚且存活的对象复制到另一块区域,然后一次性清理掉这块没用的内存,下次则对调过来执行,如此往复。
优点:解决了标记清除算法的内存碎片问题,且清除对象效率更高(一波带走)
缺点:
1、内存利用率不高,每次都只能使用一半的内存
2、当内存中对象存活率较高时,重复执行复制操作就会显得耗时且无意义
三、标记-整理算法
算法步骤:
1、标记:遍历内存区域,标记所有需要回收的对象(结合可达性分析算法对无用对象进行标记)
2、整理:清除所有标记对象,同时让存活对象往内存一端移动
优点:解决了内存碎片问题,也提高了内存利用率
缺点**:既有标记清除,又有移动过程,效率更低
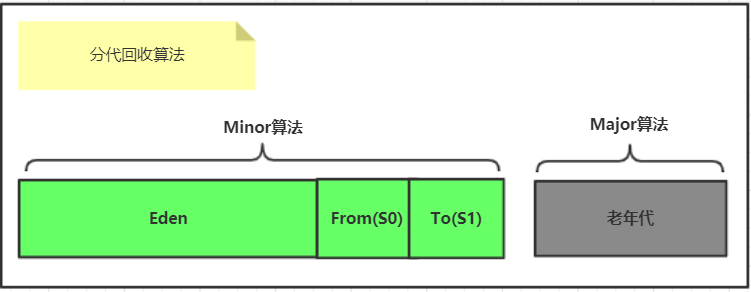
四、分代回收算法(主角)
算法描述:是目前大部分JVM的垃圾收集器采用的算法。并不是一种全新的算法,而是根据对象存活时间长短按需整合了前述三种算法。
**
如前面文章所述,目前堆内结构分为年轻代和老年代(比例默认:1:2),而年轻代中又分为两个区:生成区(Eden)和幸存区(Survivor),幸存区也分为两个区:From Space(S0)和To Space(S1),所以年轻代中内存分布是Eden:S0:S1=8:1:1
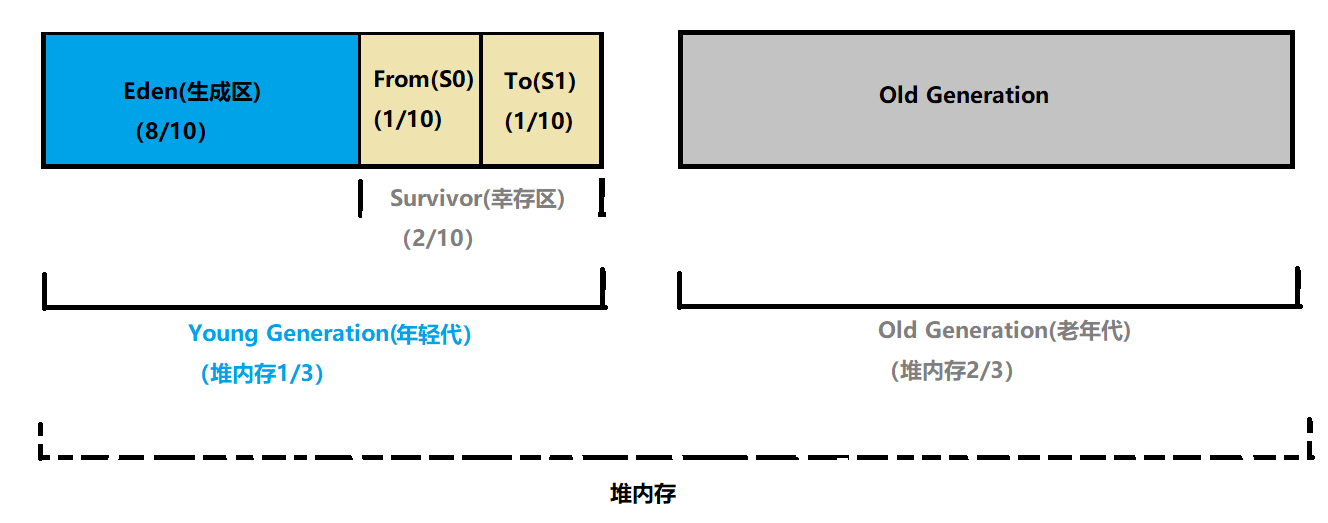
年轻代垃圾回收(Minor GC)
**
1、大部分新生成的对象都会先放在Eden区,回收时先将Eden区存活对象复制到Survivor其中一个区From区,然后清空Eden区
2、后续回收时,将From区和Eden区的存活对象复制到另一个Survivor区To区,然后清空Eden区和From区。
3、部分对象会在From区域和To区域中复制来复制去,如此交换15次(由JVM参数MaxTenuringThreshold决定,这个参数默认是15),最终如果还存活,就存入老年代
特点**:
年轻代的GC别称为Minor GC,实际上,更像是改良版的复制算法
Minor GC 的执行频率较高,并不一定等到Eden区满才执行,速度极快
基本每次都会有对象死亡,回收量很大
老年代垃圾回收(Major GC/Full GC)
**
如上所述,对象在年轻代经过N轮垃圾回收后仍存活的对象,就会被存放到老年代,可以认为,老年代中存放的都是一些生命周期较长的对象
当老年区内存满了之后,就会触发Major GC也称Full GC,回收整个内存空间的死亡对象内存
特点**:**
执行速度较慢,相较于Minor GC速度慢了10倍左右
执行频率
实例
好了,上面讲了一大堆的概念,我们最后用实例来看一下实时垃圾回收的表现:
现有类Test和HeapTest,代码如下:
public class Test {public static void main(String[] args) throws InterruptedException {List<HeapTest> heapTests = new ArrayList<>();while (true){heapTests.add(new HeapTest());Thread.sleep(5);}}}class HeapTest {private HeapTest heapTest;public void setHeapTest(HeapTest heapTest){this.heapTest = heapTest;}}
运行程序,打开docs窗口,执行jvisualvm命令调用jvm监控工具

自动调用Java VisualVM视图窗口(VisualVM是到目前为止随JDK发布的功能最强大的运行监视和故障处理程序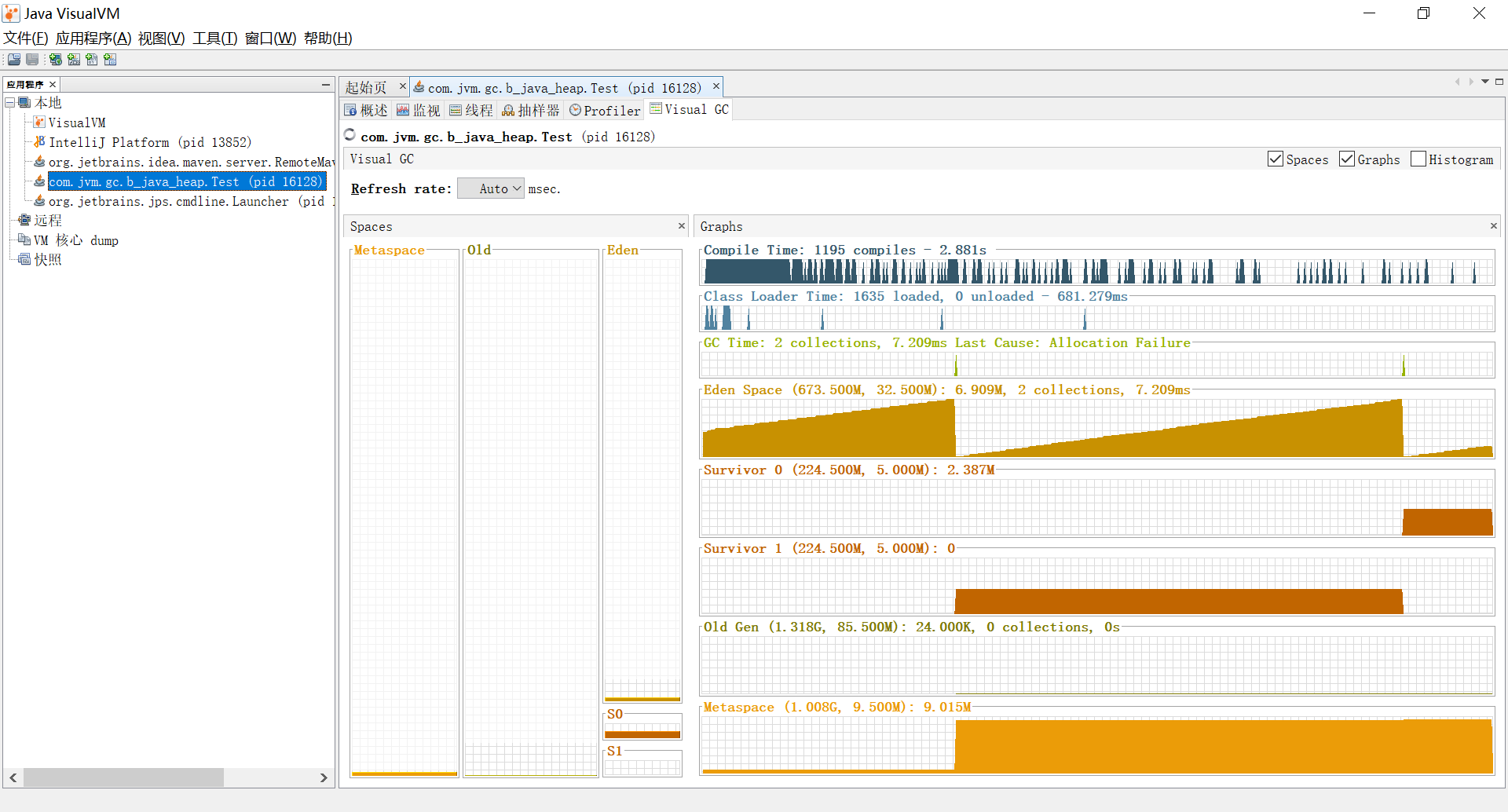
其视图窗口包含本地及远程的程序监控,可以查看每个线程的概述,监视CPU、类、线程、内存等信息,而我们需要关注的重点是Visual GC面板,该面板展示的是程序运行中的堆内存及元空间变化,进而观察程序运行期间的回收动作
从Graphs面板可以看到各个空间分区和GC的实时变化,Spaces面板可以看到各个空间分区的内存状况。
从面板可以看到熟悉的Eden(生成区),Survivor 0(幸存0区) 和Survivor 1(幸存1区)以及Old(老年区)
现有一个测试类如下:
public class Test {
public static void main(String[] args) throws InterruptedException {
List<HeapTest> heapTests = new ArrayList<>();
while (true){
heapTests.add(new HeapTest());
Thread.sleep(5);
}
}
}
①当线程运行起来后,可以看到Eden区的内存逐渐增大,达到内存巅峰的时候进行了一次内存GC,将所有Eden区中尚且存活的对象复制到S1区,同时将大对象直接放入Old区,然后将Eden区清空
②第二次Eden区内存满了的时候,将Eden区和S1区所有存活的对象复制到S0区,同时清空Eden区和S1区内存。
③第三次Eden区内存满了的时候,将Eden区和S0区所有存活的对象复制到S1区,同时清空Eden区和S0区内存
④每次GC都会对存活对象进行标识,如果标识次数即经历回收达到一定次数,则认为该对象是生命周期较长的对象,选择将该对象存入Old区
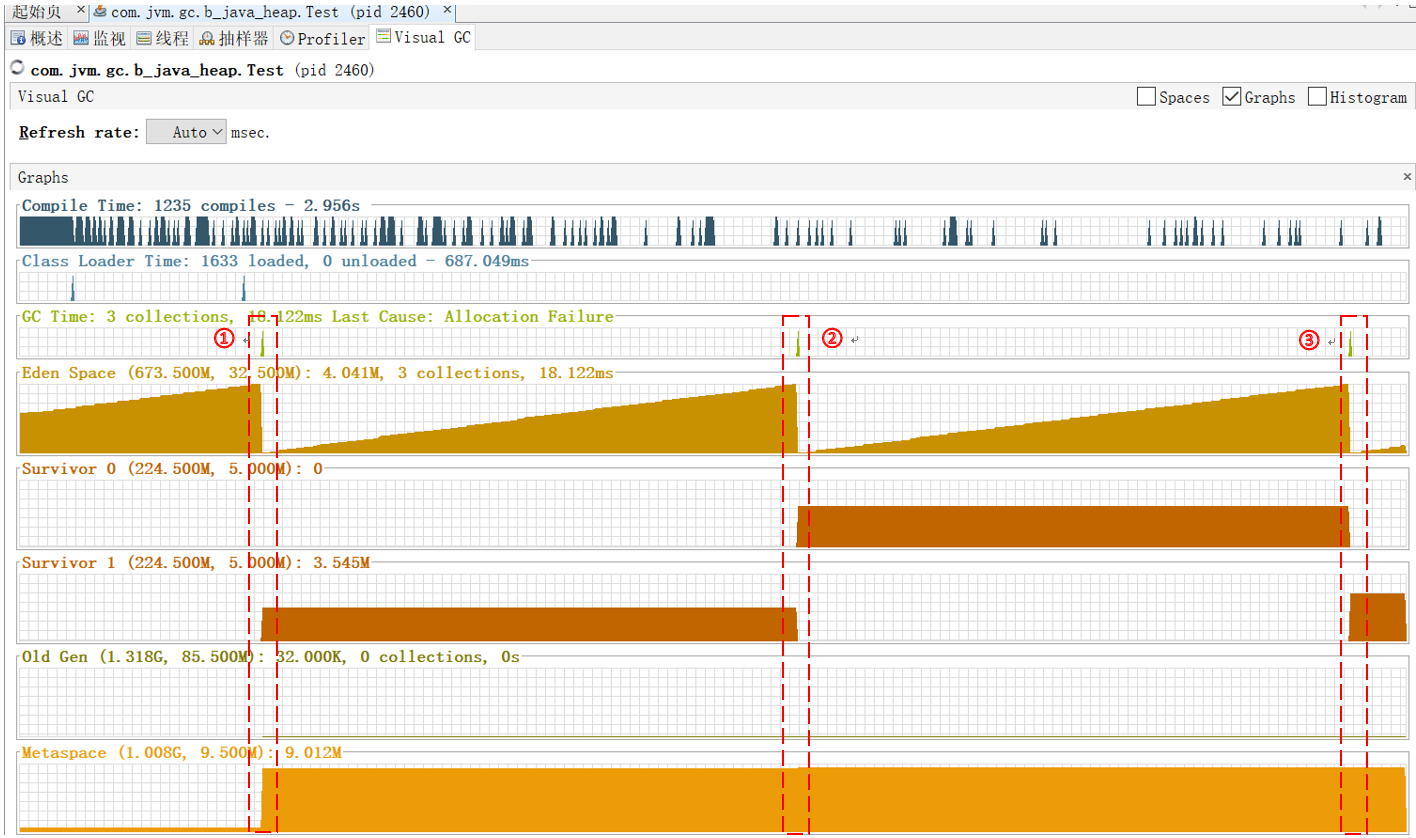
如此往复,直到Old区再也装不下对象时会执行一次Full GC,如果执行完Full GC 后仍旧没有足够内存满足需求,那么就会抛出异常OutOfMemoryError(OOM),程序停止运行

注**:
1、什么时候会执行GC?**
年轻代GC发生在新创建的对象在Eden区无法申请到空间(即Eden区满)的时候
老年代GC发生在Old区空间已满或调用System.gc()方法时
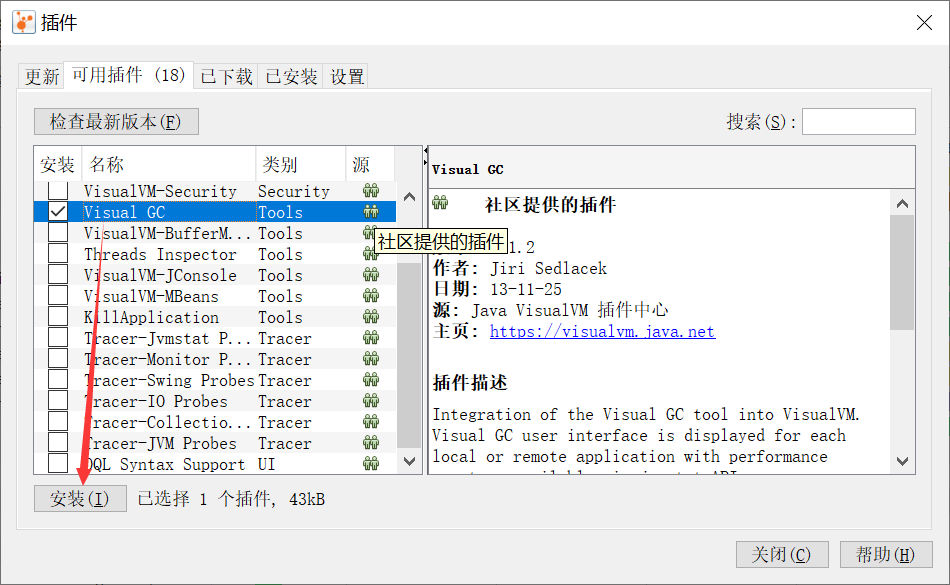
2、没有Visual GC面板?
工具->插件->可用插件->Visual GC->安装
常见的垃圾收集器
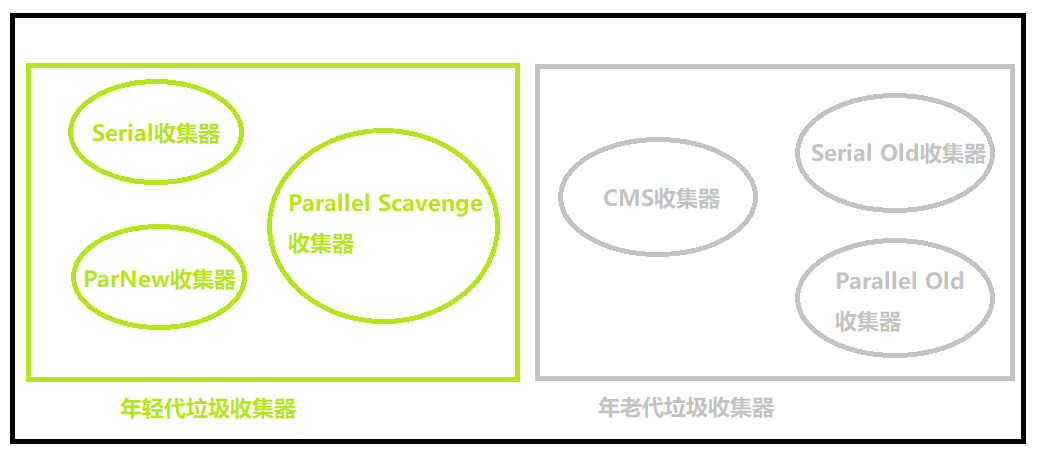
年轻代垃圾收集器
Serial收集器(串行收集器)
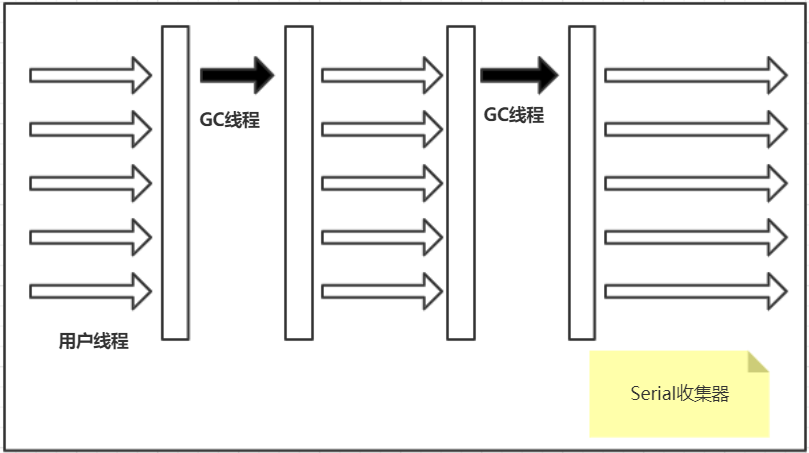
线程:单线程收集器(单线程仅有一条垃圾回收线程,而且在垃圾回收的线程执行时,会暂停用户线程,直至回收结束,Stop The World)
算法**:复制算法
显式配置:-XX:+UseSerialGC
应用场景:Client模式
优点**:简单高效(单CPU环境下,无需与其他线程交互,专心GC)
缺点**:造成应用停顿时间
ParNew收集器
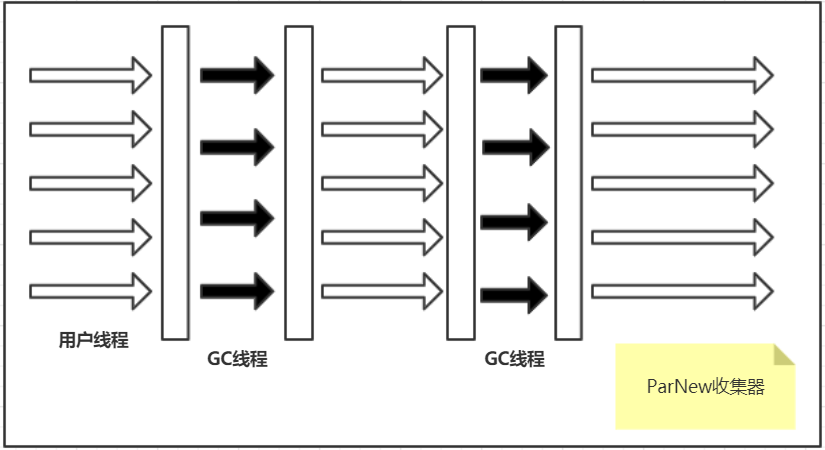
特点**:多线程并行(用户线程等待)
线程:多线程收集器(是Serial收集器的多线程版本,除了线程数,其余特征一致,和Serial收集器共用了不少代码,Stop The World)
算法**:复制算法
显式配置:-XX:+UseParNewGC**(指定使用ParNew收集器)
**-XX:+UseConcMarkSweepGC**(指定使用CMS收集器,会默认使用ParNew收集器作为年轻代收集器)
**-XX:ParallelGCThreads**(指定垃圾收集线程数量)
应用场景:Server模式
优点**:回收速度更快
缺点**:**在单CPU环境下,增加了线程交互开销
Parallel Scavenge收集器(吞吐量优先收集器)
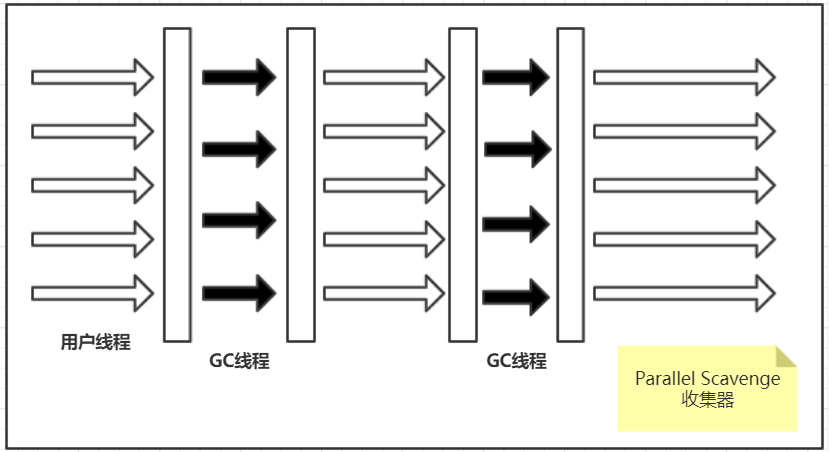
特点**:器如其名,专注于吞吐量优化,吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
线程:多线程并发
算法**:复制算法
显式配置:-XX:+UseParallelGC **(显示指定使用Parallel Scavenge收集器)
**-XX:GCTimeRatio**(控制吞吐量大小)
**-XX:MaxGCPauseMills** (最大垃圾收集时间)
应用场景:不过分关注暂停时间的应用(如后台定时任务,科学计算器等)
优点**:**吞吐量得到保证
老年代垃圾收集器
Serial Old收集器(串行收集器)
特点:Serial收集器的老年代版本
线程:单线程收集器
算法**:标记-整理算法
显式配置**:**-XX:+UseSerialGC
应用场景:Client模式
优点**:简单高效(单CPU环境下,无需与其他线程交互,专心GC)
缺点**:**造成应用停顿时间
Parallel Old收集器(吞吐量优先收集器)
特点**:Parallel Scavenge收集器的老年代版本,JDK1.6后才有
线程:多线程收集器
算法**:标记-整理算法
显式配置:-XX:+UseParallelOldGC **(显示指定使用Parallel Old收集器)
应用场景:Server模式
优点**:**吞吐量得到保证
CMS(Concurrent Mark Sweep)收集器
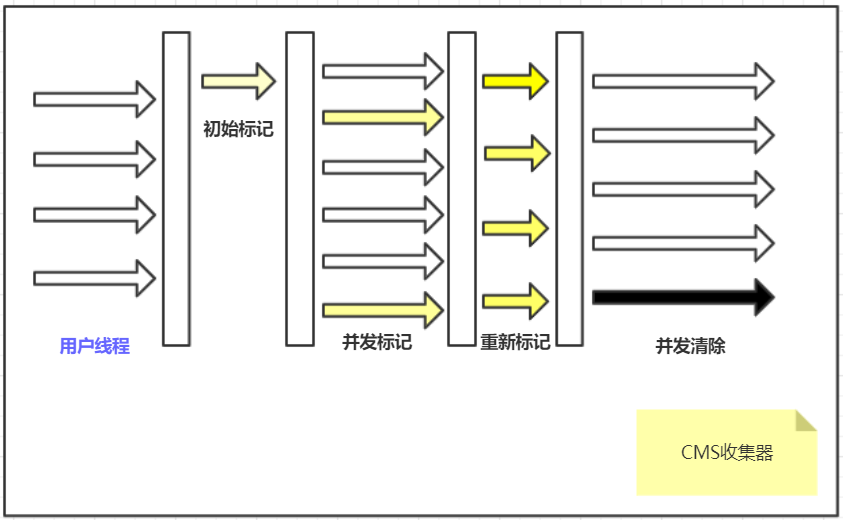
特点**:专注于获取最短回收停顿时间,非常适合用于注重用户体验的应用,第一次实现了让垃圾收集线程与用户线程同时工作
线程:多线程收集器(此处的多线程是并发的,造成的用户停顿非常短暂,甚至存在与用户线程同步进行的情况)
算法**:标记-清除算法
执行步骤**:
1、初始标记:标记GC Roots直接关联的对象(仅运行收集线程,Stop The World),速度较快
2、**并发标记**:进行GC Roots Tracing的过程,标记出”所有上一步骤被标记的对象”所能到达的对象(时长较长,此进程与用户线程并发进行,不会造成停顿)
3、重新标记:更改在并发标记的过程中,用户线程并发运行时产生变动的标记对象的标记(仅运行收集线程,Stop The World)
4、**并发清除**:清除之前未被标记的所有垃圾(与用户进程并发进行,不会造成停顿)
显式配置**:-XX:+UseConcMarkSweepGC (显示指定使用CMS收集器)
应用场景:与用户交互较多的应用场景,如Web网站等
优点**:用户体验较好,系统停顿极短
缺点**:
必然存在大量内存碎片,需要更多的内存
无法解决最后并发清除阶段用户线程产生新垃圾且没清除的问题
独立回收
Garbage-First收集器(G1收集器)
特点**:一个并行、并发和增量式压缩低停顿**的垃圾收集器,为了替代CMS收集器,解决了CMS收集器的内存碎片和内存空间需求等问题
传统的垃圾收集器将堆内存分为年轻代(Eden区和Survivor区)和老年代,而G1将堆内存分为多个大小相同的区域(**Region**),每个Region拥有自己的分代属性,但是分代不需要连续
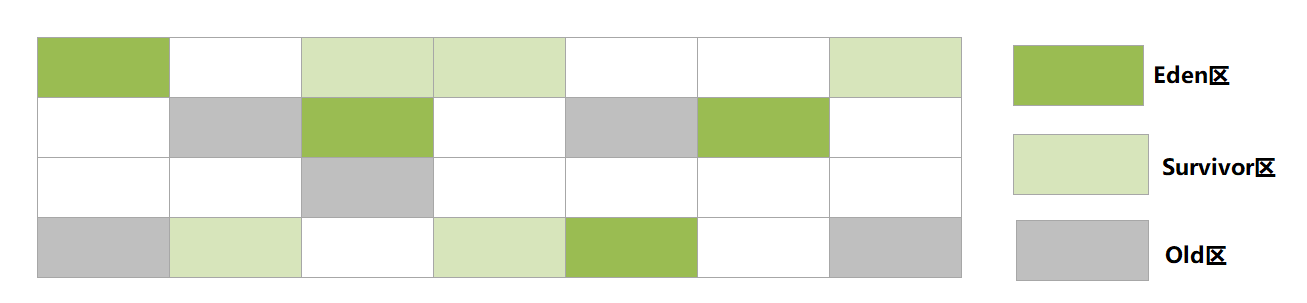
由于分代不连续,可以有效解决内存碎片化的问题,但是也会导致每次GC的时候都需要全盘扫描找出引用内存,所以G1收集器为每个Region都维护了一个Remenbered Set,用于记录对象引用的情况(是不是很像索引?),当发生GC的时候,从Remenbered Set出发搜索,有效降低耗时
GC模式**:G1收集器仅有两种GC模式,Full GC交给Serial Old收集器执行
YoungGC(年轻代收集)
**
当所有Eden Region使用达到阈值,且无法申请足够内存时,会触发一次YoungGC
每次YoungGC会回收所有Eden区和Survivor区(From),且将存活对象复制到Old区和另一个Survivor区(复制算法)
MixedGC(混合收集)
MixedGC是G1收集器独有的GC模式
我们知道,每次YoungGC都会将Eden区和Survivor区(From)的存活对象都复制到另一个Survivor区(To),然后回收Eden区和From区内存;
那么,MixedGC就是将一部分老年区(Old区)加到将被清理的Eden区和Survivor区(From)的后面,合称collection set,就是即将被回收的集合,等下次MixedGC将该集合的区域一并清理。选择Old区域优先选择E垃圾较多即存活对象较少的区域(所以称为Garbage-First)
线程:多线程收集器(此处的多线程是并发的,造成的用户停顿非常短暂,甚至存在与用户线程同步进行的情况)
算法**:整体使用“标记-整理”算法,局部使用“复制算法”
执行步骤**:
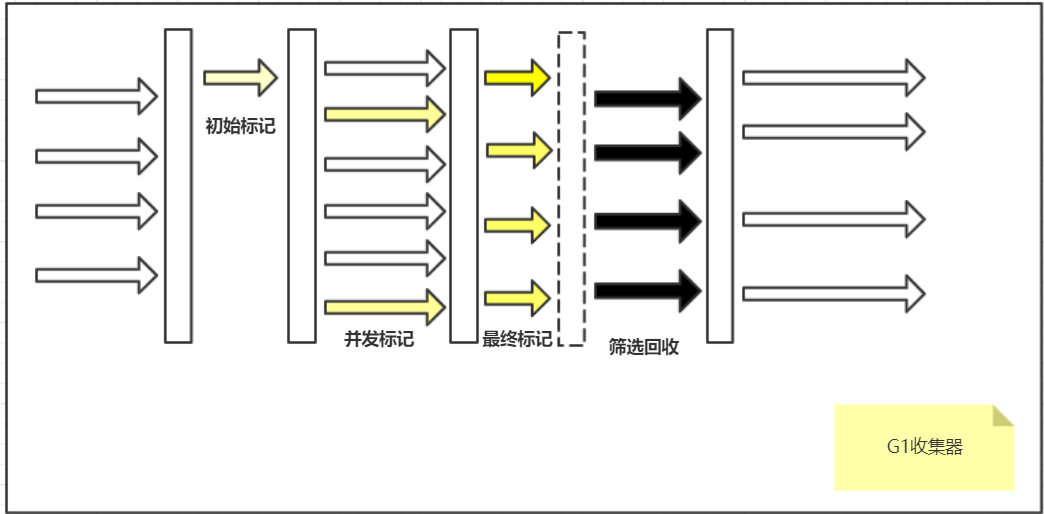
1、初始标记:标记GC Roots直接关联的对象(仅运行收集线程,Stop The World),速度较快
2、并发标记:进行GC Roots Tracing的过程,标记出”所有上一步骤被标记的对象”所能到达的对象(时长较长,此进程与用户线程并发进行,不会造成停顿)
3、最终标记:更改在并发标记的过程中,用户线程并发运行时产生变动的标记对象的标记(仅运行收集线程,Stop The World)
4、筛选回收:统计及清除Remenbered Set,同时识别完全空白的区域以及可供混合垃圾回收的区域,选择GC模式进行垃圾回收(仅运行收集线程,Stop The World)
显式配置**:-XX:+UseG1GC(显示指定使用G1收集器)
应用场景:与用户交互较多的应用场景,如Web网站等
优点**:用户体验较好,系统停顿极短
垃圾收集器回顾
| Serial | ParNew | Parallel Scavenge | Serial Old | Parallel Old | CMS | G1 | |
|---|---|---|---|---|---|---|---|
| 是否并行 | 串行 | 并行 | 并行 | 串行 | 并行 | 并行 | 并行 |
| 是否并发 | 否 | 否 | 并发 | 否 | 否 | 并发 | 并发 |
| 作用代 | 年轻代 | 年轻代 | 年轻代 | 老年代 | 老年代 | 老年代 | 年轻代和老年代 |
总结
1、常用垃圾回收算法包括:标记-清除算法、复制算法、标记-整理算法、分代回收算法等,每个算法都在不断的完善上一算法的缺陷,提高回收效率
2、常见的垃圾收集器包括Serial收集器、ParNew收集器、Parallel Scavenge收集器、Serial Old收集器、Parallel Old收集器、CMS收集器、G1收集器等,每个收集器的线程并行并发和作用代都不尽相同。
如有贻误,还请评论指正

若有收获,就点个赞吧
0 人点赞
