 更新策略
更新策略1 广告的基本知识
1.1 广告的目的与效果
什么是广告(Advertising)?
- 广告的定义:广告是由已确定的出资人通过各种媒介进行的有关产品(商品、服务和观点)的,通常是有偿的、有组织的、综合的、劝服性的非人员的信息传播活动。
- 广告的主体:出资人(sponsor)即广告主,媒介(medium),受众(audience)
广告的本质功能:是借助某种有广泛受众的媒介的力量,完成较低成本的用户接触(reach)
品牌广告(Brand Awareness)
创造独特良好的品牌或产品形象,目的在于提升较长时期内的离线转化率
效果广告(Direct Response)
有短期内明确用户转化行为诉求的广告。用户转化行为例如:购买、注册、投票、捐款等
1.2 广告有效性模型
| 序号 | 方向 | 阶段 | 主要原则 |
|---|---|---|---|
| 1 | 选择 | 曝光(exposure) | 1.1 主要取决于广告位的天然属性 |
| 2 | 关注(attention) | 2.1 不要干扰或打断用户的任务 2.2 明确揭示推荐的原因 2.3 符合用户兴趣或需求 |
|
| 3 | 解释 | 理解(comprehension) | 3.1 广告在用户能理解的兴趣范畴 3.2 与关注程度相匹配的理解门槛 |
| 4 | 信息接受(message acceptance) | 4.1 广告商/广告认可度(+/-) 4.2 广告位认可度(+/-) |
|
| 5 | 态度 | 保持(retention) | 5.1 艺术性带来的记忆效果 |
| 6 | 购买(purchase) | 6.1 在用户的价格敏感接受范围内 |
一些广告策略的效果
| 传统广告策略分析 | 阶段 | 在线广告创意原则 |
|---|---|---|
| 幽默 (2+,3-) |
利于关注,不利于理解 | 仿背景(2.1+) 1. 仿网页文字链 1. 尽量靠近网页色调 大标识(2+) 1. 显著大于背景字体 1. logo尽量显著 简单(2,3.2+) 1. 留白吸引用户关注 1. 减少同时表达的诉求 |
| 性感 (2+,4?) |
利于关注,对部分用户信息接受不友好 | |
| 艺术 (3-,5+) |
不利于理解,有利于保持 | |
| 折扣 (2+,6+) |
有利于关注和购买 |
1.3 广告与营销的区别
| 类比 | 目的和效果对比 | 对象 |
|---|---|---|
| 广告 Advertising |
- 目的:通过媒介传播某种企业形象或产品信息 - 效果:某特定人群的有效到达(reach),多渠道综合的ROI |
潜在用户 |
| 销售 sales |
- 目的:提升产品销量,从而提高企业收益 - 效果:收入和利润 |
有较明确需求者 |
- 探讨一下渠道的广告/销售特质
- 硬广,SEM,导航网站,淘宝直通车,返利网
精准广告不等于营销或CRM,也不应该仅仅是“把你的客户卖给你”或“把竞争对手的客户卖给你”
1.4 在线广告的特点和问题
在线广告的独特性
技术和计算导向
- 数字媒体的特点使在线广告可以进行精细的受众定向
- 技术使得广告决策和交易朝着计算驱动的方向发展
- 可衡量性
- 广告的调户是效果的直接收集途径
- 从98年到今天,Banner广告的点击率从10%降至0.1%,是广告的效果下降了两个数量级么?
- 标准化
- 技术投放和精准定向促进了在线广告的标准化
-
美国广告行业协会
iab:interactive Advertising Bureau
在线广告供给方的行业协会,推动数字化市场营销行业的发展
- 制定市场效果衡量标准和在线广告创意的标准
- 会员:Google,Yahoo,Microsoft,Facebook等
4s:American Association of Advertising Agencies
- 主要的协议是关于广告代理费用的收取约定(17.65%),以避免恶意竞争
- 主要集中在创意和客户服务,在线业务是一部分
- 会员:Ogilvy & Mather,JWT,McCann等,Dentsu等非4A会员的大公司但也别列为4A公司
ANA:Association of National Advertisers
- 主要代表广告需求方的利益(也有媒体和代理会员)
- 会员:AT&T,P&G,NBA等
1.5 在线广告市场
在线广告市场结构示意

1.6 计算广告核心问题和挑战
在线广告的核心计算问题
- 广告中的计算问题
- Find the best match between a given user u. in a given context c, and a suitable ad a.

从优化角度来看
- 特征提取:受众定向
- 微观优化:CTR预测
- 宏观优化:竞价市场机制
- 受限优化:在线分配
- 强化学习:探索与利用
-
从系统角度来看
候选查询:实时索引
- 特征存储:No-sql技术
- 离线学习:Hadoop
- 在线学习:流计算
-
在线广告计算的主要挑战1
大规模(Scale)
百万量级的页面,十亿量级的用户,需要被分析处理
- 高并发在线投放系统(例:Rightmedia每天处理百亿次广告交易)
Latency的严格要求(例:ad exchange要求竞价在100ms内返回)
动态性(Dynamics)
-
丰富的查询信息(Rich query)
-
探索与发现(Explore & exploit)
用户反馈数据局限于在以往投放中出现过的(a,u,c)组合,需要主动探索未观察到的领域,以提高模型正确性
1.7 广告、搜索与推荐的比较
| | 搜索 | 搜索广告 | 显示广告 | 推荐 | | —- | —- | —- | —- | —- | | 首要准则 | 相关性
(relevence) | 投资回报率(ROI) | | 用户兴趣 | | 其他需求 | 各垂直领域独立定义 | 质量,安全性(Safety) | | 多样性(diversity),
新鲜度(freshness) | | 索引规模 | ~十亿级 | ~百万级—千万级 | ~百万级 | ~百万级—亿级 | | 个性化 | 较少的个性化需求 | | ~亿级用户规模上的个性化 | | | 检索信号 | 较为集中 | | 较为丰富 | | | Downstream
优化 | 不适用 | | | 适用 |
1.8 投资回报(ROI)分析
ROI的分解
在线广告系统的ROI
CPM市场:固定eCPM
- CPC市场:动态CTR,固定click value
CPA/CPS/ROI市场:动态CTR与click value
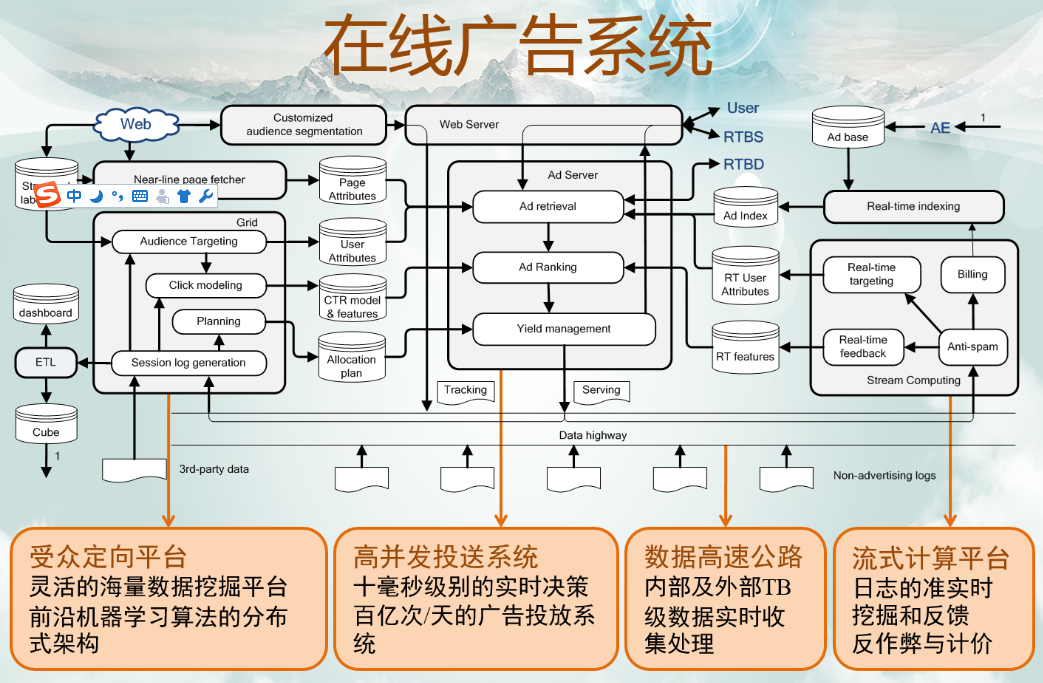
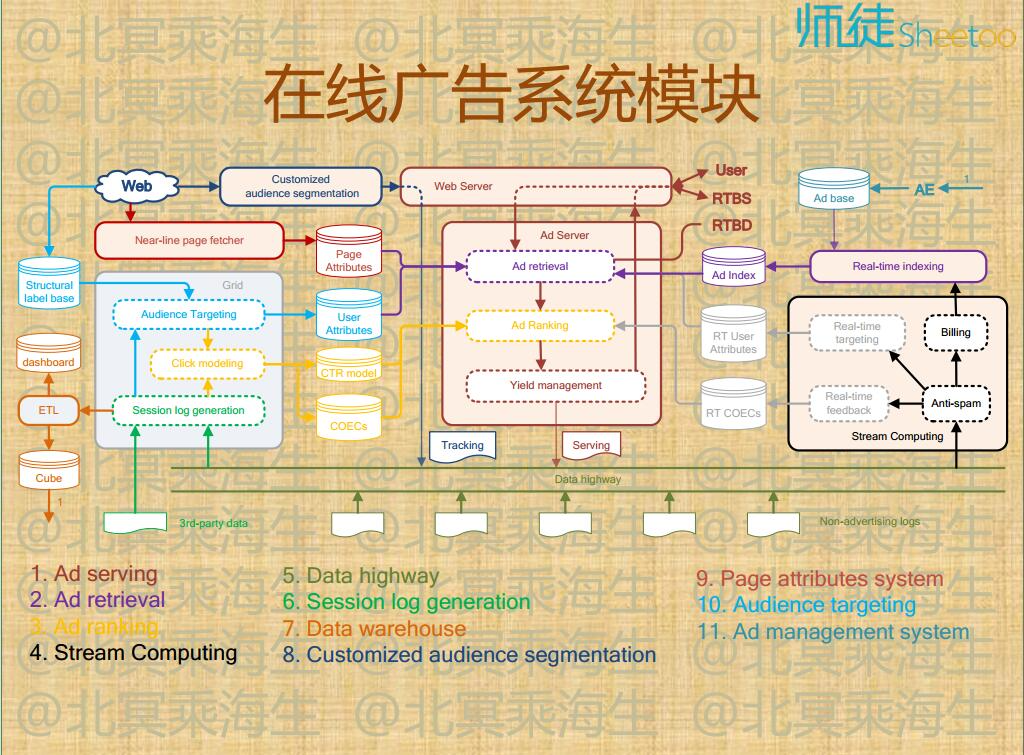
1.9 在线广告系统结构
2 合约广告系统
2.1 常用广告系统开源工具
跨语言服务搭建工具
跨语言服务快速搭建(C++,java,python,ruby,C#…)
- 用struct定义语言无关的通信数据结构
- struct KV {1:optional i32 key = 10; :optional string value=”X”}
- 用service定义RPC服务接口
- service KVCache{void set(1:i32 key, 2:string value}; string get(1:32 key);void delete(1:32 key);
- 将上述声明放在IDL文件(比如service.thrift)中,用thrift -r -gen cpp service.thrift生成服务框架代码
- 能实现结构体和接口的Backward compatible
类似工具:Hadoop子项目Avro,Google开发的ProtoBuf
2.2 合约广告简介
直接媒体购买
供给方:广告排期系统
- 帮助媒体自动执行多个合同的排期
- 不提供受众定向,可以将广告素材直接插入页面
- 需求方:代理商
- 帮助广告上策划和执行排期
- 用经验和人工满足广告商质和量的需求
代表
担保式投放(Guaranteed Delivery,GD)
- 基于合约的广告机制,约定的量未完成需要向广告商补偿
- 量(Quantity)优于质(Quality)的销售方式
- 多采用千次展示付费(Cost per Mille,CPM)方式结算
广告投放机(Ad Server)
Apache 开源项目
- 源于Lucene项目一部分,2006.1成为子项目,现为Apache顶级项目
- Yahoo!是最重要源代码贡献者,其他:: Powerset,Facebook等
- 已知为接近150家的大型组织实际使用:Yahoo!, Amazon, EBay, AOL, Google, IBM, Facebook, Twitter, Baidu, Alibaba, Tencent, …
- http://wiki.apache.org/hadoop/PowerBy
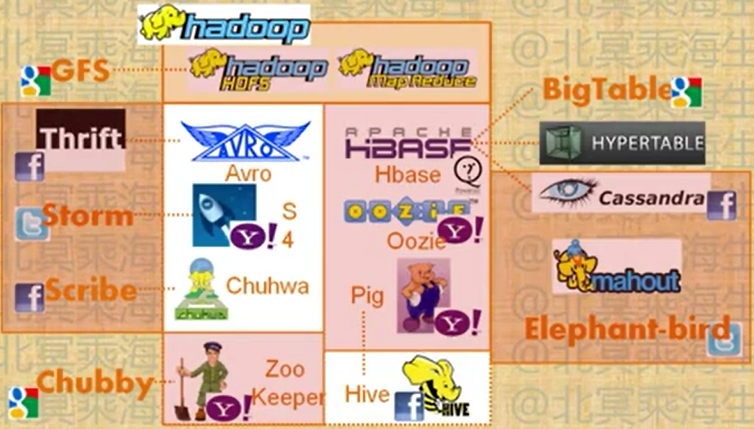
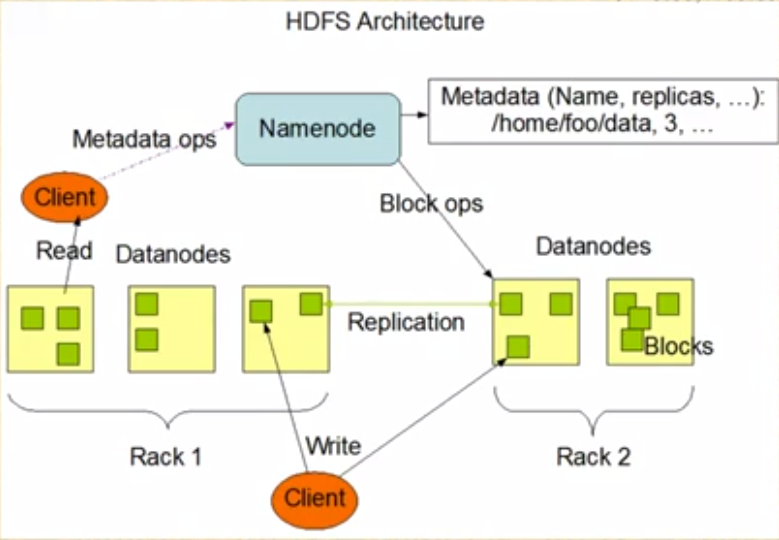
- Hadoop核心功能
- 高可靠性,高效率的分布式文件系统
- 一个海量数据处理的编程框架
Hadoop目标
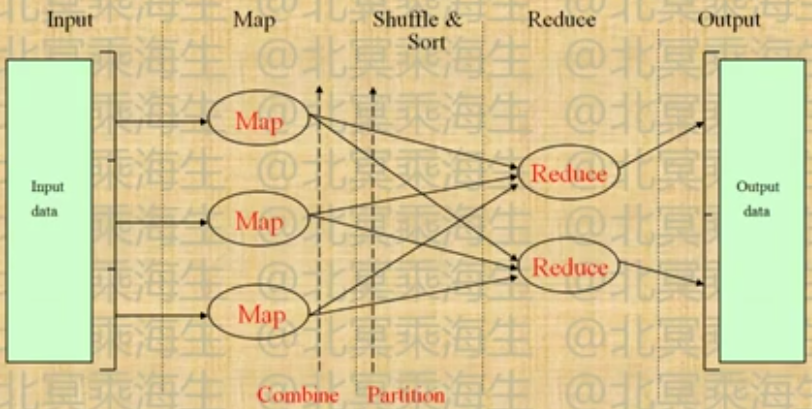
什么是Map/Reduce
- 一种高效,海量的分布式计算编程模型
- 海量:相比于MAP. Map处理之间的独立性使得整个系统的可靠性大为提高
- 高效:用调度计算代替调度数据!
- 分布式操作和容错机制由系统实现,应用级编程非常简单
- 计算流程非常类似于简单的Unix pipe:
- -Pipe:cat input | grep | sort | uniq -c > output
- M/R: INPUT | map | shuffle & sort | reduce | output
多样的编程接口:
模拟Pipe方式执行Map/Reduce Job,并利用标准输入/输出调度数据:
- INPUT | map | shuffle & sort | reduce | output
- 开发者可以使用任何编程实现map和reduce过程,只需要从标准输入读入数据,并将处理结果打印到标准输出
- 只支持文本格式数据,数据缺省配置为每行为一个Record,Key和value之间用\t分隔
例,生成大量文本上的字典:
指数族分布
- Canonical form:

- 举例:Gaussian,multinomial,maximum entroy
- 最大似然(Maximum likelihood,ML)估计可以通过充分统计量(sufficient statistics)链接到数据
- Canonical form:
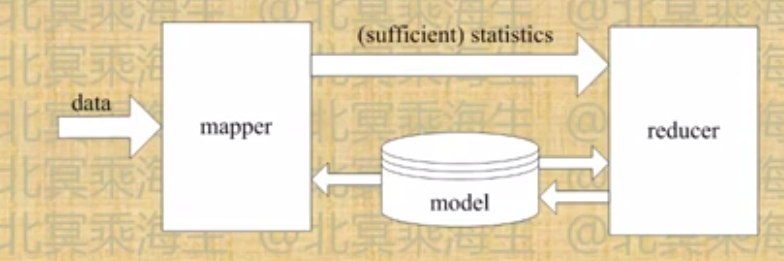
指数族混合分布
在mapper中仅仅生成比较紧凑的统计量,其大小正比于模型参数量,与数据量无关
这样的流程可以处想出来,而具体的模型算法只需要关注统计量计算和更新两个函数
Hadoop上的工作引擎 -Oozie
连接多个Map/Reduce Job,完成复杂的数据处理
- 处理各Job以及数据之间的依赖关系(可以依赖的条件:数据,时间,其他Job)
- 使用hPDL(一种XML流程语言)来定义DAG工作流









-
3 受众定向(Audience targeting)
概述
A(d)U(ser)C(txt)上的标签体系
常见受众定向方式
Audience Science
核心业务
主要提供面向publisher的数据加工服务
- 直接运营ad network,并帮忙广告主进行campaign管理和优化


其他点评
- 较早提出受众定向(audience targeting)的概念
- 数据标签不像bluekai那样在市场上公开出售,仅供委托他们优化campaign的广告商使用
使用标签impression创造的营收按照一定比例跟publisher分成
3.1 行为定向(Behavioral Targetting)
九种重要原始行为(按信息强度顺序)
- Transaction
- Pre-transaction(如商品浏览)
- Paid search click
- Ad click
- Search Click
- Search
- Share
- Page View
- Ad View
- 行为定向计算(t(i)(u)表示用户u在标签i上的强度)
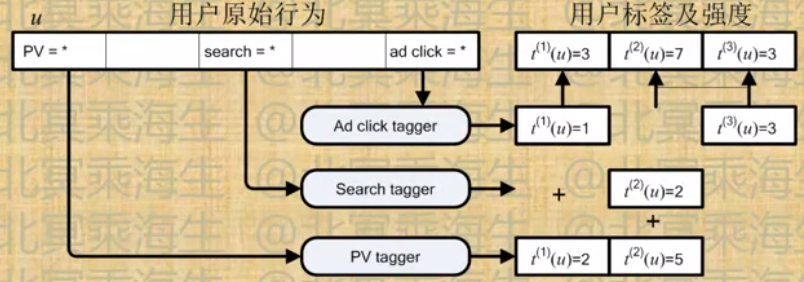
行为定向其他问题
- Session Log
- 将各种行为日志整理成以用户ID为key的形式,完成作弊和无效行为标注,作为个数据处理模块的输入源
- 可以将targeting变成局部计算,大大方便整个流程
- Long-term行为定向两种多日累计方式
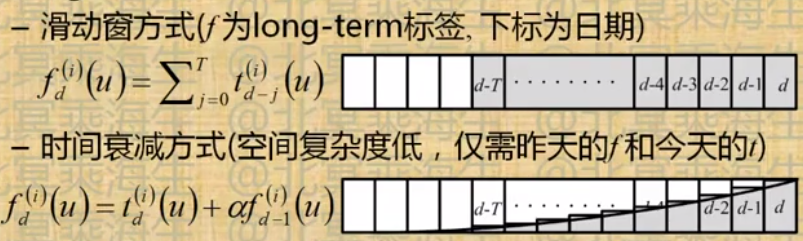
受众定向评测-Reach/CTR曲线
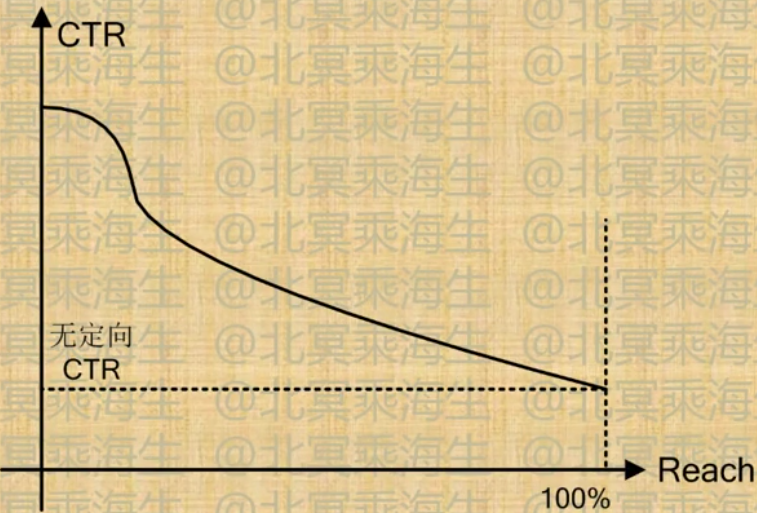
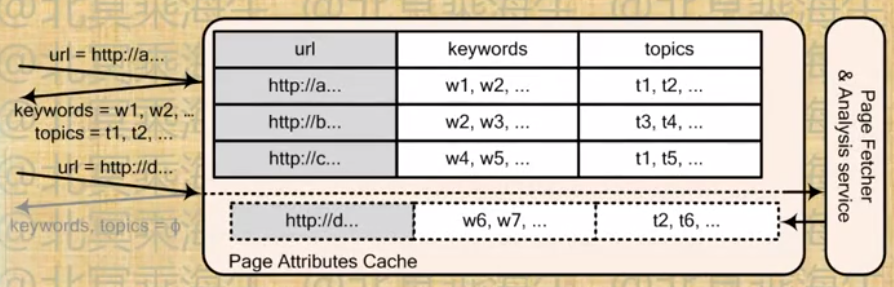
3.2 上下文定向
- Near-line上下文定向系统
- 涌在线cache系统存储url->特征表以提供实时访问
- 不预先加载任何cache内容,对cache中不存在的url,立刻返回空特征,同时出发相应的页面爬虫和特征提取
- 设置cache系统合适的实效时间以完成特征自动更新
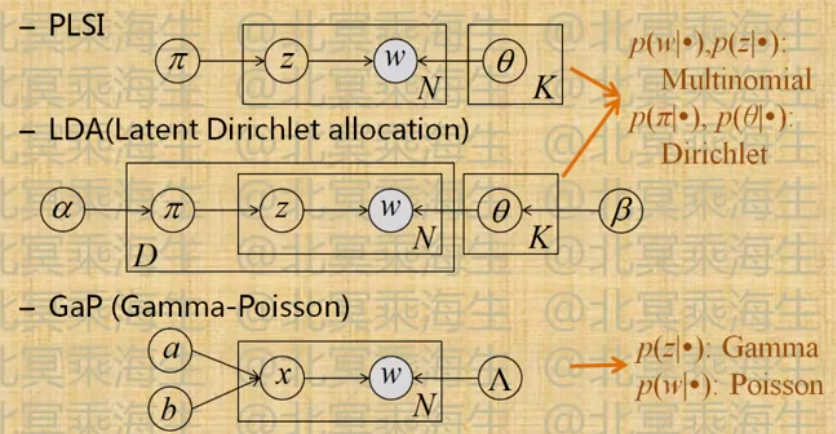
3.3 页面主题分析-Topic Model
- 问题:发现一组文档中抽象的主题(topics)
- 常用模型图表示
经验贝叶斯-Empirical Bayes
- 如下图模型,如何确定hyperparameter

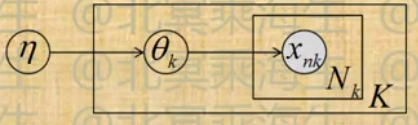
- EB解
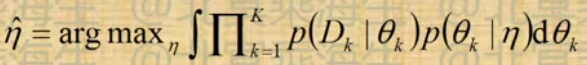
- 当
 为指数族分布,
为指数族分布, 为其共轭鲜艳时,可用EM求解,其中E-step为Bayesian inference过程
为其共轭鲜艳时,可用EM求解,其中E-step为Bayesian inference过程
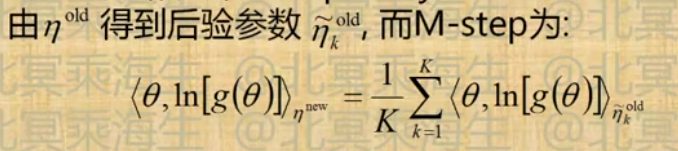
从经验贝叶斯看LDA
- LDA可以视为PLSI的经验贝叶斯版本
- 由于PLSI不是指数族分布,而是其混合分布,因此其贝叶斯版本不能使用全面的EM算法
- Deterministic inference:
- 可用变分近似,假设z和
 的后延分布独立迭代求解过程与EM非常相似,成为VBEM
的后延分布独立迭代求解过程与EM非常相似,成为VBEM - 在大多数问题上无法保证收敛到局部最优
- 可用变分近似,假设z和
- Probabilistic inference:
- 可用Gibbs-sampling(Markov-chain Monte-Carlo,MCMC,的一种),以概率1收敛到局部最优解
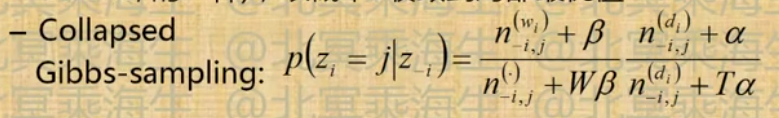
Topic model的并行化
- EM及VBEM的并行化
- E-step(mapper):可以方便地并行计算
- M-step(reducer):累加E-step各部分统计量后更新模型
- 将更新后的模型分发到新的E-step各个计算服务器上
- AD-LDA:Gibbs Sampling的并行化
- Mapper:在部分data上分别进行Gibbs sampling
- Reducer:全局Update
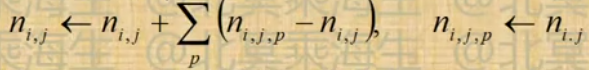
文档的Topic model抽取可以认为是一个大量(而非海量)数据计算,采用类MPI架构的分布式计算架构(例如spark)会比map/reduce效率更高
3.4 数据加工和交易
精准广告业务是什么?
精准广告业务若干错误观念
越精准的广告,给市场带来的价值越大
- 媒体利益与广告主利益是相博弈的关系
- 精准投放加上大数据可以显著提高营收
- 人群覆盖率较低的数据来源是不需要的
-
有价值的数据
用户标识
- 除上下文和地域外各种定向的基础,需要长期积累和不断建设
- 可以通过多家第三方ID绑定不断优化
- 用户行为
- 业界公认有效行为数据(按有效性排序)
- 交易,预交易,搜索广告点击,广告点击,搜索,搜索点击,网页浏览,分享,广告浏览
- 需去除网络热点话题带来的偏差
- 越靠近demand的行为对转化越有贡献
- 越主动的行为越有效
- 业界公认有效行为数据(按有效性排序)
- 广告商(Demand)数据
- 简单的cookie植入可以用户retargeting
- 对接广告商种子人群可以做look-alike,提高覆盖率
- 用户属性和精准地理位置
- 非媒体广告网络很难获取,需通过第三方数据对接。
- 移动互联和HTML5为获得地理位置提供了便利性
社交网络
目的:
- 为网站提供数据加工的对外交易能力
- 加工跨媒体用户标签,在交易市场中售卖
- 是否应直接从事广告交易存在争议
- 关键特征:
- 定制化用户划分
- 统一的对外数据接口
代表:
核心业务:
- 为中小网站主提供数据加工和变现的方式
- 通过汇聚众多中小网站用户资料和行为数据,加工成受众定向标签,通过Data exchange对外售卖
- 其他点评:
- 提供大量戏份标签、开发体系上的标签,如“对保洁洗发水感兴趣的人”,“想去日本旅游的人”
- 靠数据出售变现,并与提供数据的网站主成分,并不直接运营广告业务
- 用户可以看到自己的资料被谁使用,也可以选择“捐给慈善机构”



4 竞价广告系统
4.1 位置拍卖理论
竞价系统理论
- 位置拍卖(Position auctions)
- 将对象a={1,2,…A}排放到位置s={1,2,…,S}
- 经对象a的出价(bid)为
 ,而其对位置s的计价为
,而其对位置s的计价为
- 将
 视为点击价值,
视为点击价值, 视为点击率,该模型可近似描述广告系统竞价问题(对显示广告,S=1)
视为点击率,该模型可近似描述广告系统竞价问题(对显示广告,S=1)
对称纳什平衡(Symmetric Nash equilibruim)
VCG(Vickrey-Clarke-Groves)机制
- 某对象的收费应等于给他人带来的价值损害

- 整体市场是truth-telling的
- 某对象的收费应等于给他人带来的价值损害
广义第二高价(Generalized second pricing)机制

广告网络
- Connects advertisers to web sites that want to host advertisements(见Wikipedia)
- 自行估计给定(a,u,c)组合的CTR
- 主要特征
- 竞价系统(Auction system)
- 淡化广告位概念
- 最合适的计价方式为CPC
- 不足:不易支持定制化用户划分

Ad Network系统架构示意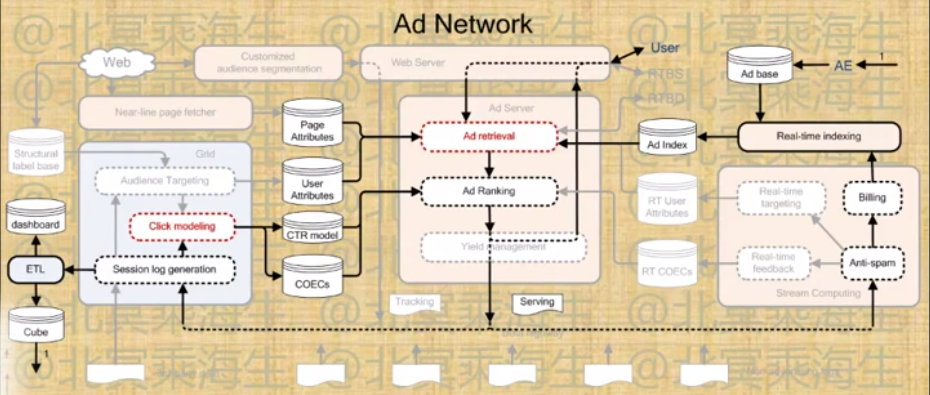
4.3 广告检索
布尔表达式检索
布尔表达式检索-index算法
布尔表达式检索-index示例
长Query情况下的相关性检索
Weight-And(WAND)检索算法
基于WAND的上下文定向检索
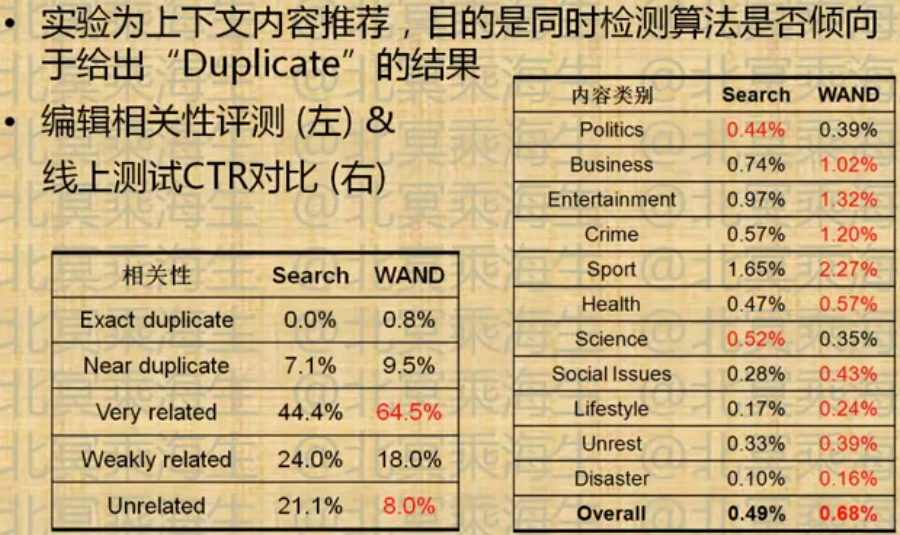
4.4 流量预测

4.5 ZooKeeper介绍
分布式同步服务-Zookeeper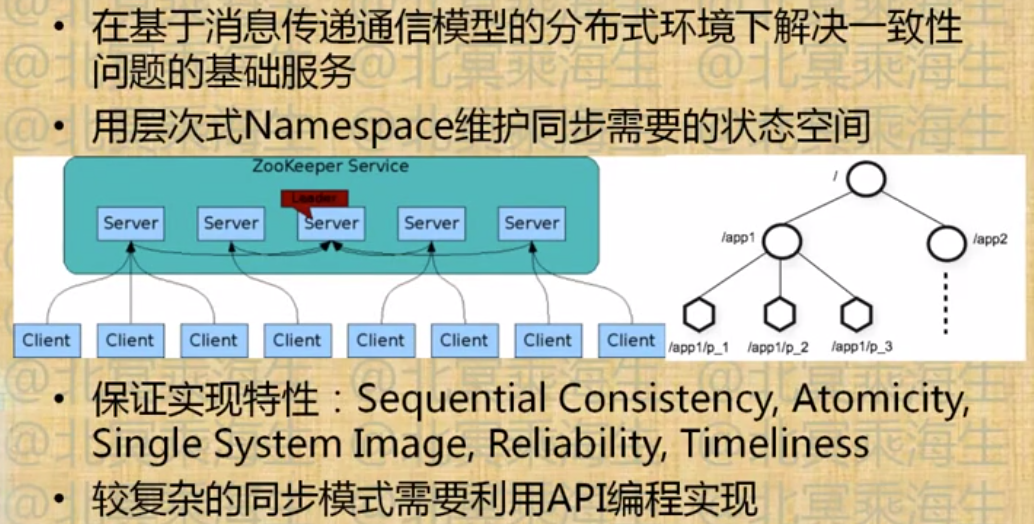
Paxos算法概念
4.6 点击率预测与逻辑回归
点击率预测
逻辑回归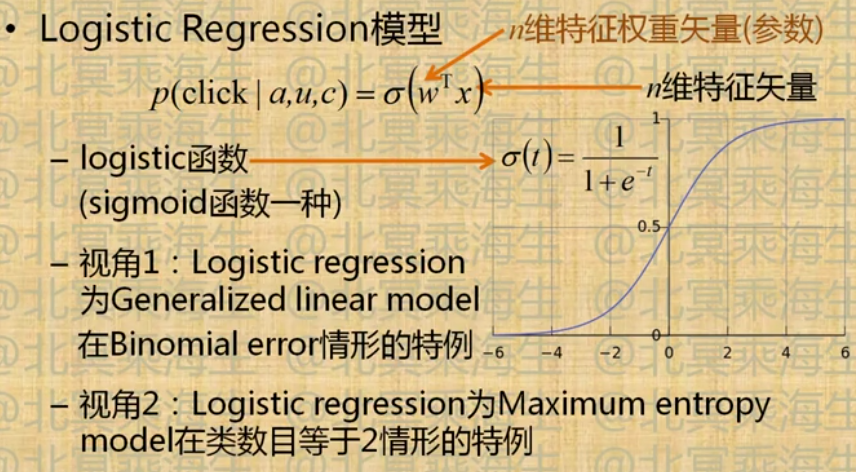
4.7 逻辑回归优化方法介绍
逻辑回归优化方法-L-BFGS
ADMM方法
逻辑回归的ADMM分布式解法
4.8 动态特征
动态特征-多层次点击反馈
5 搜索广告与广告网络Demand
6 广告交易市场

若有收获,就点个赞吧
0 人点赞
