- 常见面试题以及参考答案
- 01 你是怎样理解“特征”
- 02 给定场景和问题,你如何设计特征?
- 03 开发特征时候如何做数据探索,怎样选择有用的特征?
- 04 你是如何做数据清洗的?距离说明
- 05 如何发现数据中的异常值,你是如何处理?
- 06 缺失值如何处理?
- 07 对于数值类型数据,你会怎样处理?为什么要做归一化?归一化有哪些方法?离散化有哪些方法,离散化和归一化有哪些优缺点?
- 08 标准化和归一化异同?
- 09 你是如何处理CTR类特征?
- 10 讲解贝叶斯平滑原理?以及如何训练得到平滑参数
- 11 类别特征数据你是如何处理的?比如游戏品类、地域、设备
- 12 序号编码、one-hot编码、二进制编码都是什么?是否怎样的类别数据?
- 13 时间类型数据你的处理方法是什么?原因?
- 14 你怎样理解组合特征?举个例子,并说明它和单特征有啥区别
- 15 如何处理高维组合特征?比如用户ID和内容ID?
- 16 如何理解笛卡尔积、外积、内积?
- 17 文本数据你会如何处理?
常见面试题以及参考答案
01 你是怎样理解“特征”
特征就是,于己而言,特征是某些突出性质的表现,于他而言,特征是区分事物的关键。
02 给定场景和问题,你如何设计特征?
基于人工经验的特征工程依然是目前的主流。
漏斗特征、时间窗口特征、多值离散特征
03 开发特征时候如何做数据探索,怎样选择有用的特征?
数据描述方法
- 集中趋势分析
- 离中趋势分析
- 数据分布分析
- 图分析
数理统计方法
- 假设检验
- 方差分析
- 相关分析
- 回归分析
- 因子分析
过滤式:方差选择、卡方检验、互信息
优点是既然时间上高效,对于过拟合问题也具有较高的鲁棒性。缺点就是强相遇选择冗余的特征,因为他们不考虑特征之间的相关性,有可能某一个特征的分类能力很差,但是它和其它特征组合起来会得到不错的效果。
包裹式:Las Vagas算法
消耗资源
嵌入式:基于惩罚项的选择、基于树的选择GBDT
04 你是如何做数据清洗的?距离说明
过滤、填补缺失值、处理异常值
05 如何发现数据中的异常值,你是如何处理?
看发布、箱线图
06 缺失值如何处理?
删除
填充:离散的用众数、连续的用平均数(或中位数)
07 对于数值类型数据,你会怎样处理?为什么要做归一化?归一化有哪些方法?离散化有哪些方法,离散化和归一化有哪些优缺点?
归一化可以提高收敛速度,提升收敛的精度
归一化:最大值、均值
标准化:Z-score
离散化:分段、等频等距离
参考文章
08 标准化和归一化异同?
相同点:这俩都是线性变换,将原有数据进行了缩放,数据的大小顺序没有发生改变。
不同点:归一化一般放缩到[0,1],标准化则转为服从正态分布,,影响归一化的主要是两个极值,而标准化里每个数据都会有影响,因为计算均值和标准差。
09 你是如何处理CTR类特征?
放缩然后离散化
10 讲解贝叶斯平滑原理?以及如何训练得到平滑参数
防止出现估计概率为0,影响后续计算
11 类别特征数据你是如何处理的?比如游戏品类、地域、设备
序号编码、one-hot编码、二进制编码
12 序号编码、one-hot编码、二进制编码都是什么?是否怎样的类别数据?
- 序号编码通常用于处理类别间具有大小关系的数据
- one-hot编码用于处理类别间不具有大小关系的特征。但是当类别取值较多的时候需要注意:
- 用系数向量来节省空间
- 配合特征选择来降低维度
- 二进制编码,先用序号编码给每个类别赋予一个类别id,然后将类别id转为二进制编码,本质上是利用二进制对id进行了hash映射,得到0-1特征向量,且维度少于one-hot编码
13 时间类型数据你的处理方法是什么?原因?
一般取到小时或者天,太细维度一来可解释性不强,二来造成特征维度增加,数据过于稀疏,也增加训练资源
14 你怎样理解组合特征?举个例子,并说明它和单特征有啥区别
组合特征其实就是特征的交叉。举个例子,比方说浏览新闻,给用户推荐新闻的时候如果按照性别或者兴趣这个特征来推,可能效果不是特别好,但经过观察发现,性别和兴趣有比较强的关系,例如女性可能更喜欢看娱乐类,男性更喜欢体育财经类,把这俩特征做组合加入到模型,效果比单特征要强很多。
15 如何处理高维组合特征?比如用户ID和内容ID?
使用矩阵分解,常用的矩阵分解有
QR分解:Q是正交矩阵,R是上三角矩阵
LU分解:下三角和上三角
SVD: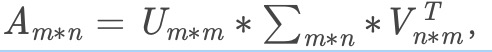 其中U , V U,VU,V是酉矩阵(矩阵A乘以其共轭转置是单位阵)
其中U , V U,VU,V是酉矩阵(矩阵A乘以其共轭转置是单位阵)
Jordan分解:分成多个Jordan块,每个Jordan块都是对角线是相同的特征值,次对角线是1。
16 如何理解笛卡尔积、外积、内积?
笛卡尔积是两两相乘,m条记录和n条记录的结果为mn条记录,内积是两个向量点乘,结果是一个数值,外积是列向量乘以行向量,结果是一个矩阵。
17 文本数据你会如何处理?
利用各种文本模型

若有收获,就点个赞吧
0 人点赞
