1 概述
逻辑斯蒂回归(logistic regression)是统计学习中的经典分类方法。
最大熵是概率模型学习的一个准则,将其推广到分类问题得到最大熵模型(maximun entropy model)。
1.1 应用
1.1.1 适用场景
1.1.2 适用特征
高维稀疏类别特征,故而天然适用于ctr场景
- 鲁棒性
- 引入非线性
1.2 相关知识
1.2.1 Sigmoid 函数
函数公式:
函数性质
- 将任意input压缩到(0,1)之间
- 1/2处导数最大
- 设
 ,
, 的导函数为:
的导函数为:
- 两边梯度区域饱和(梯度消失:作为激活函数在神经网络中的弊端)
- 不以原点为中心(作为激活函数在神经网络中的弊端)
- 单调性
1.2.2 模型评估
损失函数以及由来
结论:交叉熵损失


损失函数的由来推导
假设样本服从的是伯努利分布(0-1)分布,有:极大似然估计
目标
总结
1)样本服从伯努利(0-1)分布
2)损失函数的由来:伯努利分布的极大似然估计
正则化
目的
通用形式

说明

L2正则化的特点:参数变小,但不会为零,不会形成稀疏解
L1正则化法:对参数进行一次约束,会形成稀疏解 **
**
注意一点:无论L1、L2正则化方法,本质上都是乘法参数W使其等于或者趋向于0;但又没有可能一种正则化方法会使参数W趋向于非零值呢?答案是:可以这样做如

L1、L2形成稀疏解和非稀疏解的原因解释:三种解释角度
第一种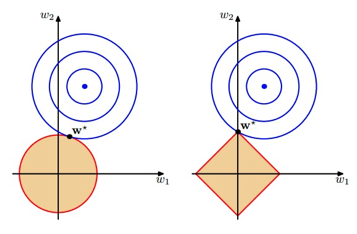
直观感受(几何):黄色区域表示正则项限制,蓝色区域表示优化项的等高线,要满足在二者交点上的点才符合最优解w*,故:当w的等高线逐步向正则限制条件区域扩散时,前者交点大多在非坐标轴上,后者在坐标轴上,哪个形成稀疏解显而易见
Accuracy
AUC
1.2.3 梯度下降
说明
- 梯度下降属于优化算法(同牛顿法)
- LR中,梯度下降是求解参数矩阵

- 梯度下降中的“梯度”针对的是损失函数loss
公式


梯度法推导

参数更新

常见的优化算法
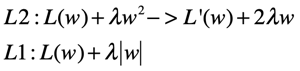
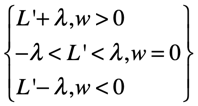
介绍两种:梯度法、牛顿法
一、梯度法:不必赘述
思考:为何沿着梯度方向就是最速下降,即函数的下降的速度最快
当我们在某个要优化的函数,这里设为f(x) ,我们在x点处,然后沿方向v进行移动,到达f(x+v),
图示表示了移动过程:
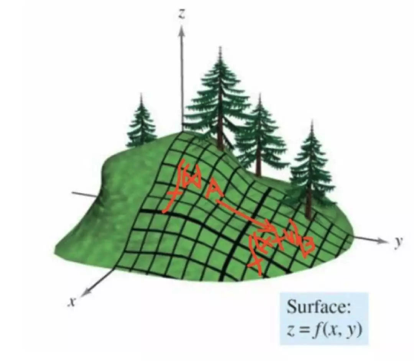
此图显示了从A点,移动到B点的过程。那么 v方向是什么的时候,
局部下降的最快呢?换成数学语言来说就是,
f(x+v)-f(x)的值在 v是什么的时候,达到最大!
•知识点:泰勒展开:下面以二阶为例
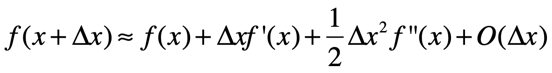

则 f(x+v)-f(x)=d f(x)v ,则我们可以得出: d f(x)v 为函数值的变化量,注意的是 d f(x) 和 v 均为向量, d f(x)v 也就是两个向量进行点积,而向量进行点积的最大值,也就是两者共线的时候,也就是说 v 的方向和 d f(x) 方向相同的时候,点积值最大,这个点积值也代表了从A点到B点的上升量。
而 df(x)正是代表函数值在x处的梯度。前面又说明了v的方向和df(x)方向相同的时候,点积值(变化值)最大,所以说明了梯度方向是函数局部上升最快的方向。也就证明了梯度的负方向是局部下降最快的方向
牛顿法:先摆结论,再给出证明!
结论:(也可以加入步长)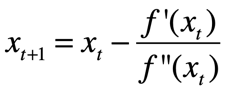
证明:再一次划重点,泰勒级数!
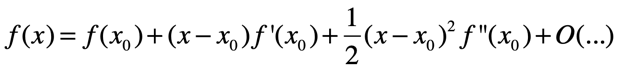
两边同时对x(变量)求梯度得: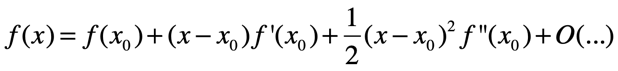
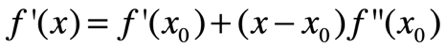
令f’(x)=0得:可得结论: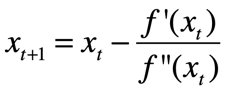
1.3 优缺点
优点
1.4 使用流程
(1)收集数据:采用任意方法收集数据(2)准备数据:由于需要进行距离计算,因此要求数据类型为数值。另外,结构化数据格式最佳(3)分析数据:采用任意方法对数据进行分析(4)训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数(5)测试算法:一旦训练步骤完成,分类将会很快(6)使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数据;接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
2 算法
2.1 逻辑斯蒂分布
定义2.1(逻辑斯蒂分布) 设 是连续随机变量,服从逻辑死地分布是指具有下列分布函数和密度函数
是连续随机变量,服从逻辑死地分布是指具有下列分布函数和密度函数


式中, 为参数位置,
为参数位置, 为形状参数。
为形状参数。
定义2.2(逻辑斯蒂回归模型) 二项逻辑斯蒂回归模型是如下的条件概率分布

这里, 是输入,
是输入, 是输出,
是输出, 和
和 是参数,
是参数, 称为权值向量,
称为权值向量, 称为偏置,
称为偏置, 为和
为和 的内积。
的内积。
有时候为了方便,将权值向量和输入向量加以扩充,仍记作,,即 和
和 。这时,逻辑斯蒂回归模型如下:
。这时,逻辑斯蒂回归模型如下:

3 实现
算法实现
基于sklearn接口实现
3.2 应用
算法版使用
sklearn使用
4 实践
5 问题集合
知识点
问题1 逻辑回归相比于线性回归,有何异同?
- 逻辑回归处理的是分类问题,线性回归处理的是回归问题
- 逻辑回归的因变量是离散的,对于二分类任务因变量服从二项分布;而线性回归中的因变量是连续的,因变量是服从正向分布的
- 逻辑回归中通过对似然函数的学习,得到最佳参数
 。线性回归使用极大似然估计的一个化简。
。线性回归使用极大似然估计的一个化简。
问题2 当实验逻辑回归处理多标签的分类问题时,有哪些常见做法,分别应用于哪些场景,它们之间又有什么关系?
当存在样本可能属于多个标签的情况时,我们可以训练k个二分类的逻辑分类器。第i个分类器用以区分每个样本是否可以归为第 类,训练该分类器时,需要把标签重新整理为「第i类标签」与「非第i类标签」两类。通过这样的办法,我们就解决了每个样本可能拥有多个标签的情况。
类,训练该分类器时,需要把标签重新整理为「第i类标签」与「非第i类标签」两类。通过这样的办法,我们就解决了每个样本可能拥有多个标签的情况。
6 继续阅读

若有收获,就点个赞吧
0 人点赞
