1 概述
决策树(decision tree)是一种基本的分类与回归方法。本节主要讲解分类方法
2 算法
2.1 决策树模型与学习
决策树模型
定义2.1(决策树) 分类决策树是一种描述对实例进行分类的树形结构。决策树由节点(node)和有向边(directed node)组成。节点有两种类型:内部节点(internal node)和叶节点(leaf node)。内部节点表示一个特征或属性,叶节点表示一个类。
用决策树分类,从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子节点;这时,每一个子节点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直到达到叶节点。最后将实例分到叶节点的类中。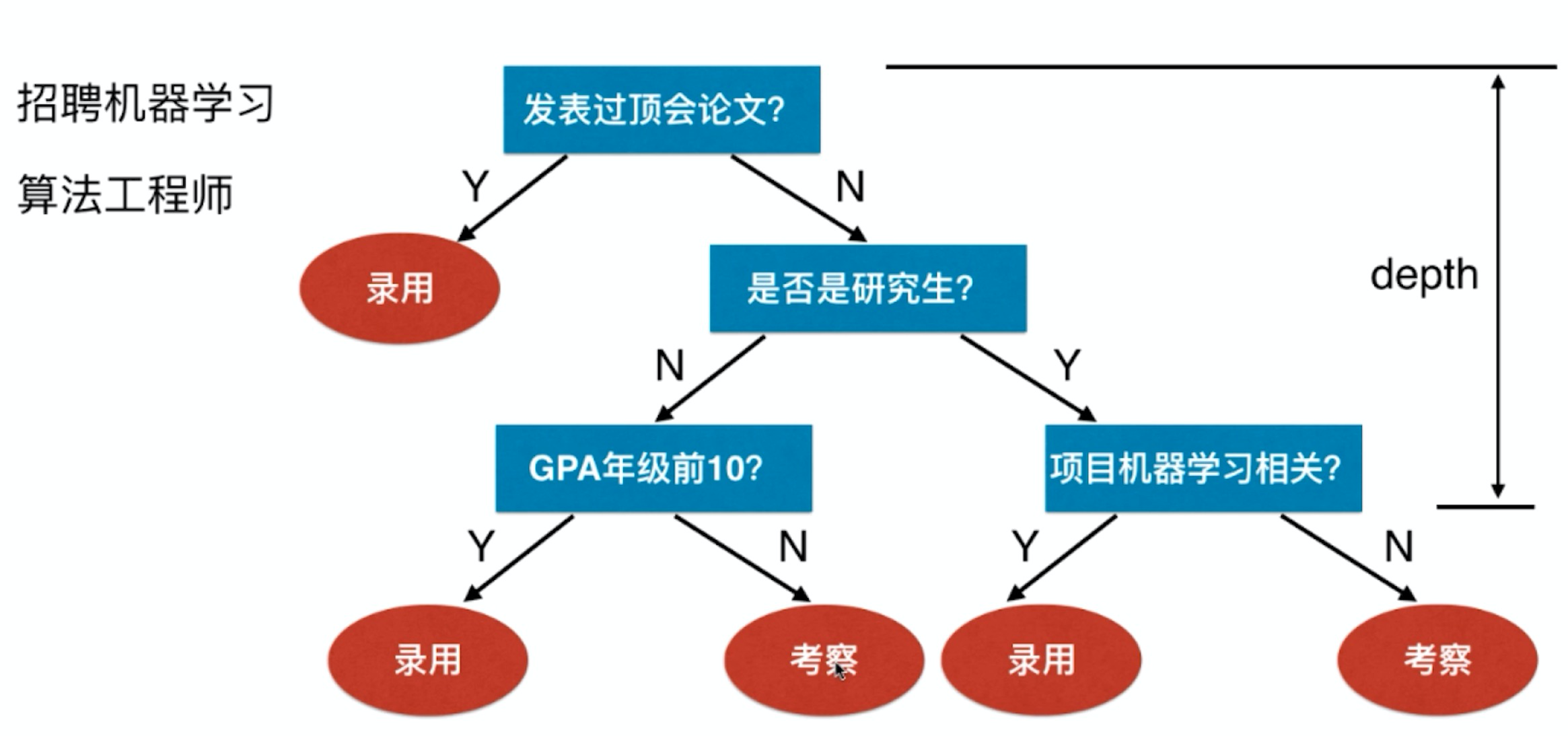
图2-1
决策树与if-then规则
可以将决策树看成一个if-then规则的集合。将将决策树转换成if-then规则的过程是这样的:有决策树的根节点到叶节点的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶节点的类对应着规则的结论。
决策树与条件概率分布
决策树还表示给定特征条件下类的条件概率分布。这一条件概率分布定义在特征空间的一个划分(partition)上。将特征空间划分为互不相交的单元(cell)或区域(region),并在每个单元顶一个类的概率分布就构成了一个条件概率分布。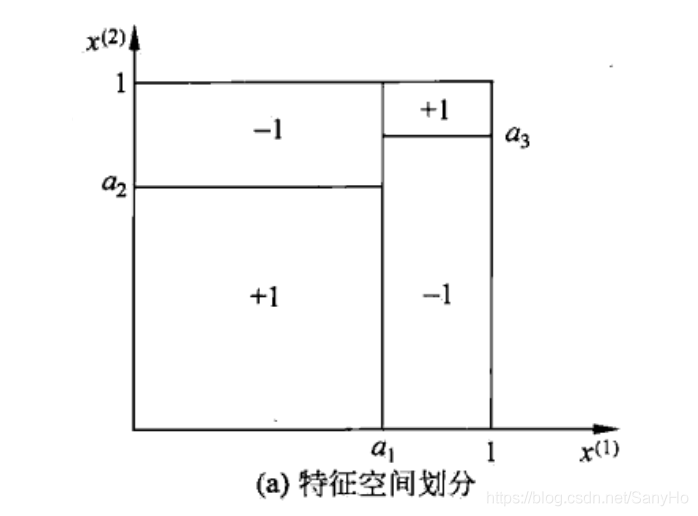
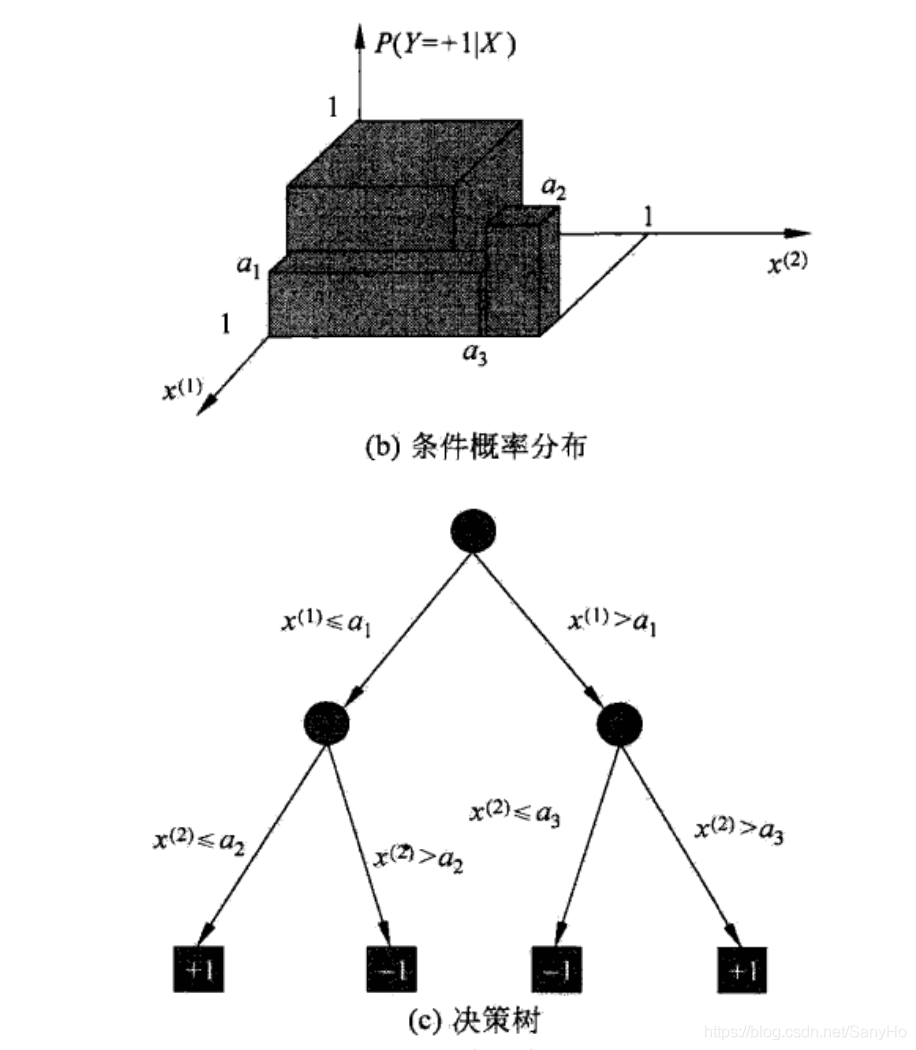
决策树学习
假设给定训练数据集
其中, 为输入实例(特征向量),
为输入实例(特征向量), 为特征个数,
为特征个数, 为类标记,
为类标记, ,
, 为样本容量。决策树学习的目的是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
为样本容量。决策树学习的目的是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
- 决策树学习本质上是从训练集中归纳一组分类规则;
- 决策树学习用损失函数表示这一目标
- 决策树学习的损失函数通常是正则化的极大似然函数。
- 决策树学习的策略是以损失函数为目标函数的最小化
- 决策树学习的算法
- 通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,是的对各个子数据集有一个最好的分类过程
- 决策树容易过拟合
- 决策树可能对训练数据有很好的分类能力,但对未知的测试数据却未必有很好的分类能力
- 需要对已生成的书自下而上进行剪枝,将树变得简单,从而是它具有更好的泛化能力。
由上可以看出,决策树学习算法包含特征选择、决策树的生成与决策树的剪枝过程
决策树学习常用的算法有ID3,ID4.5与CART,下面结合这些算法分布叙述决策树学习的特征选择、决策树的生成和剪枝过程
2.2 特征选择
特征选择问题
特征选择在于选取对训练数据具有分类能力的特征。
- 可以提高决策树学习的效率
- 特征选择的准则是信息增益或信息增益比
信息增益
为了便于说明,先给出熵与条件熵的定义。
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设 是一个取得有限个值的离散随机变量,其概率分布为
是一个取得有限个值的离散随机变量,其概率分布为
则随机变量 的熵定义为
的熵定义为
 (2.1)
(2.1)
在式(2.1)中,若 ,则定义
,则定义 。通常,式(2.1)中的对数以2为底或以
。通常,式(2.1)中的对数以2为底或以 为底(自然对数),这时熵的单位分别称作比特(bit)或纳特(nat)。由定义可知,熵只依赖于
为底(自然对数),这时熵的单位分别称作比特(bit)或纳特(nat)。由定义可知,熵只依赖于 的分布,而与
的分布,而与 的取值无关,所以也可将
的取值无关,所以也可将 的熵记作
的熵记作 ,即
,即 (2.2)
(2.2)
熵越大,随机变量的不确定性去越大。从定义可验证 (2.3)
(2.3)
当随机变量只取两个值,例如1,0时,即 的分布为
的分布为

熵为 (2.4)
(2.4)
这时,熵 随概率
随概率 变化的曲线如图2.1所示(单位为比特)。
变化的曲线如图2.1所示(单位为比特)。
@TODO
当 或
或 时
时 ,随机变量完全没有不确定性。
,随机变量完全没有不确定性。 时,
时, ,熵取值最大,随机变量不确定性最大。
,熵取值最大,随机变量不确定性最大。
设有随机变量 ,其联合概率分布为
,其联合概率分布为
条件熵 表示在已知随机变量
表示在已知随机变量 的条件下随机变量
的条件下随机变量 的不确定性。随机变量
的不确定性。随机变量 给定的条件下随机变量
给定的条件下随机变量 的条件熵(conditional entropy)
的条件熵(conditional entropy) ,定义为
,定义为 给定条件下
给定条件下 的条件概率分布的熵对
的条件概率分布的熵对 的数学期望
的数学期望 (2.5)
(2.5)
这里, 。
。
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。此时,如果有0的概率,令 。
。
信息增益(information gain)表示得知特征 的信息而使得
的信息而使得 的信息的不确定性减少的程度。
的信息的不确定性减少的程度。
定义2.2(信息增益)特征 对训练数据集
对训练数据集 的信息增益
的信息增益 ,定义为集合
,定义为集合 的经验熵
的经验熵 与特征
与特征 给定条件下
给定条件下 的经验条件熵
的经验条件熵 之差,即
之差,即 (2.6)
(2.6)
一般地,熵 与条件熵
与条件熵 之差成为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
之差成为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
算法2.1(信息增益的算法)
输入:训练数据集 和特征
和特征
输出:特征 对训练数据集
对训练数据集 的信息增益
的信息增益 。
。
(1)计算数据集 的经验熵
的经验熵
 (2.7)
(2.7)
(2)计算特征 对数据集
对数据集 的经验条件熵
的经验条件熵
 (2.8)
(2.8)
(3)计算信息增益 (2.9)
(2.9)
信息增益比
以信息增益作为划分数据集的特征,存在偏向于选择取值较多的特征的问题。使用信息增益比(information gain ratio)可以对这一问题进行校正。这是特征选择的另一准则。
定义2.3(信息增益比)特征 对训练数据集
对训练数据集 的信息增益比
的信息增益比 定义为期信息增益
定义为期信息增益 与训练集
与训练集 关于特征
关于特征 的值的熵
的值的熵 之比,即
之比,即 (2.10)
(2.10)
其中, ,
, 是特征
是特征 取值的个数。
取值的个数。
2.3 决策树的生成
本节将介绍决策树学习的生成算法。首先介绍 的生成算法,然后再介绍
的生成算法,然后再介绍 中的生成算法。这些都是决策树学习的经典算法。
中的生成算法。这些都是决策树学习的经典算法。
ID3算法
 算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根节点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由改特征的不同取值减少子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一棵决策树。
算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根节点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由改特征的不同取值减少子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一棵决策树。 相当于用极大似然法进行概率模型的选择。
相当于用极大似然法进行概率模型的选择。
算法2.2(ID3算法)
输入:训练数据集 ,特征集
,特征集 阈值
阈值 ;
;
输出:决策树 。
。
(1)若 中所有实例属于同一类
中所有实例属于同一类 ,则
,则 为单节点树,并将类
为单节点树,并将类 作为该结点的类标记,返回
作为该结点的类标记,返回 ;
;
(2)若 ,则
,则 为单结点树,并将
为单结点树,并将 中实例数最大的类
中实例数最大的类 作为该结点的类标记,返回
作为该结点的类标记,返回 ;
;
(3)否则,按照算法5.1计算 中各特征对
中各特征对 的信息增益,选择信息增益最大的特征
的信息增益,选择信息增益最大的特征 ;
;
(4)如果 的信息增益小于阈值
的信息增益小于阈值 ,则置
,则置 为单结点树,并将
为单结点树,并将 中实例数最大的类
中实例数最大的类 作为该结点的类标记,返回
作为该结点的类标记,返回 ;
;
(5)否则, 的每一可能值
的每一可能值 ,依
,依 将
将 分割为若干非空自己
分割为若干非空自己 ,将
,将 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成
中实例数最大的类作为标记,构建子结点,由结点及其子结点构成 ,返回
,返回 ;
;
(6)对第 个子结点,以
个子结点,以 为训练集,以
为训练集,以 为特征集,递归地调用步(1)~(5),得到子树
为特征集,递归地调用步(1)~(5),得到子树 ,返回
,返回 。
。
C4.5的生成算法
 算法与
算法与 算法类似,
算法类似, 算法对
算法对 进行了改进。
进行了改进。 在生成的过程中,用信息增益比来选择特征。
在生成的过程中,用信息增益比来选择特征。
算法2.3(C4.5算法)
输入:训练数据集 ,特征集
,特征集 阈值
阈值 ;
;
输出:决策树 。
。
(1)若 中所有实例属于同一类
中所有实例属于同一类 ,则
,则 为单节点树,并将类
为单节点树,并将类 作为该结点的类标记,返回
作为该结点的类标记,返回 ;
;
(2)若 ,则
,则 为单结点树,并将
为单结点树,并将 中实例数最大的类
中实例数最大的类 作为该结点的类标记,返回
作为该结点的类标记,返回 ;
;
(3)否则,按照算法(2.10)计算 中各特征对
中各特征对 的信息增益比,选择信息增益最大的特征
的信息增益比,选择信息增益最大的特征 ;
;
(4)如果 的信息增益小于阈值
的信息增益小于阈值 ,则置
,则置 为单结点树,并将
为单结点树,并将 中实例数最大的类
中实例数最大的类 作为该结点的类标记,返回
作为该结点的类标记,返回 ;
;
(5)否则, 的每一可能值
的每一可能值 ,依
,依 将
将 分割为若干非空自己
分割为若干非空自己 ,将
,将 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成
中实例数最大的类作为标记,构建子结点,由结点及其子结点构成 ,返回
,返回 ;
;
(6)对第 个子结点,以
个子结点,以 为训练集,以
为训练集,以 为特征集,递归地调用步(1)~(5),得到子树
为特征集,递归地调用步(1)~(5),得到子树 ,返回
,返回 。
。
2.4 决策树的剪枝
决策树生成算法递归地产生决策树,知道不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化。
在决策树学习中将已生成的树进行简化的过程称为剪枝(pruning)。具体地,剪枝从已生成的树上裁掉一些子树或叶结点。并将其根结点或父结点作为新的叶结点,从而简化分类树模型。
本节介绍一种简单的决策树学习的剪枝算法。
决策树的剪枝往往通过极小化决策树整体的损失函数(loss function)或代价函数(cost function)来实现。设树 的叶结点个数为
的叶结点个数为 ,
, 是树
是树 的叶节点,该叶节点有
的叶节点,该叶节点有 个样本点,其中
个样本点,其中 类的样本点有
类的样本点有 个,
个, ,
, 为叶节点t上的经验熵,
为叶节点t上的经验熵, 为参数,则决策树学习的损失函数可以定义为
为参数,则决策树学习的损失函数可以定义为 (2.11)
(2.11)
其中经验熵为 (2.12)
(2.12)
在损失函数中,将式(2.11)右端的第1项记作 (2.13)
(2.13)
这时有 (2.14)
(2.14)
式(2.14)中, 表示模型对训练数据的预测误差,即模型与训练数据的拟合程度,
表示模型对训练数据的预测误差,即模型与训练数据的拟合程度, 表示模型复杂度,参数
表示模型复杂度,参数 控制两者之间的影响。较大的
控制两者之间的影响。较大的 促使选择较简单的模型(树),较小的
促使选择较简单的模型(树),较小的 促使选择较复杂的模(树)。
促使选择较复杂的模(树)。 意味着只考虑模型与训练数据的拟合程度,不考虑模型的复杂度。
意味着只考虑模型与训练数据的拟合程度,不考虑模型的复杂度。
可以看出,决策树生成只考虑了通过提高信息增益(或信息增益比)对训练数据进行更好的拟合。而决策树剪枝通过优化损失函数的极小值等价于正则化的极大似然估计。所以,利用损失函数最小原则进行剪枝就是用正则化的极大似然估计进行模型选择。
算法2.4(树的剪枝过程)
输入:生成算法产生的整个树 ,参数
,参数 ;
;
输出:修剪后的子树
(1)计算每个结点的经验熵。
(2)递归地从树的叶结点向上回缩。
设一组叶结点回缩到其父节点之前与之后的整体树分别为 与
与 ,其对应的损失函数值分别为
,其对应的损失函数值分别为 与
与 ,如果
,如果 (2.15)
(2.15)
则进行剪枝,即将父节点变为新的叶结点。
(3)返回(2),直到不能继续为止,得到损失函数最小的子树 。
。
注意,式(2.15)只需考虑两个树的损失函数的查,其计算可以在局部进行。所以决策树的剪枝算法可以由一种动态规划的算法实现。
2.5 CART算法
分类与回归树(classification and regression tree,CART)模型由Breiman等人在1984年提出,是应用广泛的决策树学习方法,CART同样由特征选择、树的生成及剪枝组成,既可以用于分类也可以用于回归。以下将用于分类与回归的树统称为决策树。
CART是在给定输入随机变量 条件下输出随机变量
条件下输出随机变量 的条件概率分布的学习方法。CART假设决策树是二叉树,内部节点特征的取值为“是”和“否”,左分支是取值为“是”的分支,有分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。
的条件概率分布的学习方法。CART假设决策树是二叉树,内部节点特征的取值为“是”和“否”,左分支是取值为“是”的分支,有分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。
CART算法由一下两部组成:
(1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大
(2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这是用损失函数最小作为剪枝的标准。
CART的生成
决策树的生成就是递归地构建二叉决策树的过程。对回归树用平方误差最小化标准,对分类树用基尼指数(Gini index)最小化准则,进行特征选择,生成二叉树。
1.回归树的生成
假设 与
与 分别为输入和输出变量,并且
分别为输入和输出变量,并且 是连续变量,给定训练数据集
是连续变量,给定训练数据集
考虑如何生成回归树。
一棵树回归对应着输入空间(即特征空间)的一个划分以及在划分的单元上的输出值。假设已将输入空间划分为M个单元 ,并且在每个单元
,并且在每个单元 上有一个固定的输出值
上有一个固定的输出值 ,于是回归树模型可表示为
,于是回归树模型可表示为 (2.16)
(2.16)
当输入空间的划分确定时,可以用平方误差 来表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上的最优输出值。易知,单元
来表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上的最优输出值。易知,单元 上的
上的 的最优值
的最优值 是
是 上的所有输入实例
上的所有输入实例 对应的输出
对应的输出 的均值,即
的均值,即 (2.17)
(2.17)
问题是怎样对输入空间进行规划。这里采用启发式的方法,选择第 个变量
个变量 和它取得值
和它取得值 ,作为切分变量(splitting variable)和切分点(splitting point),并定义两个区域:
,作为切分变量(splitting variable)和切分点(splitting point),并定义两个区域: (2.18)
(2.18)
然后寻找最优切分变量 和最优切分点
和最优切分点 。具体地,求解
。具体地,求解 (2.19)
(2.19)
对固定输入变量 可以找到最优切分点
可以找到最优切分点 。
。 (2.20)
(2.20)
遍历所有输入变量,找到最优的切分变量 ,构成一对
,构成一对 。依此将输入空间划分为两个区域。接着,对每个区域重复上述划分过程,直至满足停止条件为止。这样就生成一颗回归树。这样的回归树通常成为最小二乘回归树(least quares regression tree),先将算法叙述如下。
。依此将输入空间划分为两个区域。接着,对每个区域重复上述划分过程,直至满足停止条件为止。这样就生成一颗回归树。这样的回归树通常成为最小二乘回归树(least quares regression tree),先将算法叙述如下。
算法2.5(最小二乘回归树生成算法)
输入:训练数据集 ;
;
输出:回归树 。
。
在训练数据集所在的输入空间中,递归地将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉树:
(1)选择最优切分变量 与切分点
与切分点 ,求解
,求解 (2.21)
(2.21)
遍历变量 ,对固定的切分变量
,对固定的切分变量 扫描切分点
扫描切分点 ,选择是式(2.21)达到最小的对
,选择是式(2.21)达到最小的对 。
。
(2)用选定的对 划分区域并决定相应的输出值:
划分区域并决定相应的输出值:

(3)继续对两个子区域调用步骤(1),(2),直至满足停止条件。
(4)将输入空间划分为 个区域
个区域 ,生成决策树:
,生成决策树:
2.分类树的生成
分类树用基尼指数选择最优特征,同时决定该特征最优二值切分点。
定义2.4(基尼系数)分类问题中,假设有 个类,样本点属于第
个类,样本点属于第 类的概率为
类的概率为 ,则概率分布的基尼指数定义为
,则概率分布的基尼指数定义为 (2.22)
(2.22)
对于二类分类问题,若样本点属于第1个类的概率是 ,则概率分布的基尼指数为
,则概率分布的基尼指数为 (2.23)
(2.23)
对于给定的样本集合 ,其基尼系数为
,其基尼系数为 (2.24)
(2.24)
这里, 是
是 中属于第
中属于第 类的样本子集,
类的样本子集, 是类的个数。
是类的个数。
如果样本集合 根据特征
根据特征 是否去某一个可能值
是否去某一个可能值 被分割成
被分割成 和
和 两部分,即
两部分,即
则在特征 的条件下,集合
的条件下,集合 的基尼指数定义为
的基尼指数定义为 (2.25)
(2.25)
基尼系数 表示集合
表示集合 的不确定性,基尼系数
的不确定性,基尼系数 表示经
表示经 分隔后集合
分隔后集合 的不确定下。基尼指数值越大,样本集合的不确定下也就越大,这一点与熵相差。
的不确定下。基尼指数值越大,样本集合的不确定下也就越大,这一点与熵相差。
算法2.6(CART生成算法)
输入:训练数据集 ,停止计算的条件;
,停止计算的条件;
输出: 决策树。
决策树。
根据训练数据集,从根节点开始,递归地对每个节点进行以下操作,构建二叉决策树。
(1)设结点的训练数据集为 ,计算现有特征对该数据集的基尼系数。此时,对每一个特征
,计算现有特征对该数据集的基尼系数。此时,对每一个特征 ,对其有可能取的每个值
,对其有可能取的每个值 ,根据样本点对
,根据样本点对 的测试为“是”或“否”将
的测试为“是”或“否”将 分割成
分割成 和
和 两部分,利用式(2.25)计算
两部分,利用式(2.25)计算 的基尼系数
的基尼系数
(2)在所有可能的特征 以及它们所有可能的切分点
以及它们所有可能的切分点 ,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
(3)对生成两个子结点递归调用(1),(2),直至满足停止条件;
(4)生成 决策树
决策树
算法停止计算的条件是节点中的样本个数小于预定阈值,或样本集的基尼系数小于预定阈值(样本基于属于同一类),或者没有更多特征。
CART剪枝
CART剪枝算法从“完成生长“的决策树的底端减去一些子树,是决策树变小(模型变简单),从而能够对未知数据有更准确的预测。CART剪枝算法有两步组成:首先从省城算法产生的决策树 底端开始不断剪枝,直到
底端开始不断剪枝,直到 的根节点,形成一个子树序列
的根节点,形成一个子树序列 ;然后通过交叉验证法在独立的验证数据集上对子树序列进行预测,从中选择最优子树。
;然后通过交叉验证法在独立的验证数据集上对子树序列进行预测,从中选择最优子树。
1.剪枝,形成一个子树系列
在剪枝过程中,计算子树的损失函数: (2.26)
(2.26)
其中, 为任意子树,
为任意子树, 为对训练数据的预测误差(如基尼指数),
为对训练数据的预测误差(如基尼指数), 为子树叶结点个数,
为子树叶结点个数, 为参数,
为参数, 为参数是
为参数是 时的子树
时的子树 的整体损失。参数
的整体损失。参数 权衡训练数据的拟合程度与模型的复杂度。
权衡训练数据的拟合程度与模型的复杂度。
对固定的 ,一定存在使损失函数
,一定存在使损失函数 最小的子树,将其表示为
最小的子树,将其表示为 。
。 在损失函数
在损失函数 最小的意义下是最优的。容易验证这样的最优子树是唯一的。当
最小的意义下是最优的。容易验证这样的最优子树是唯一的。当 大的时候,最优子树
大的时候,最优子树 偏小;当
偏小;当 小的时候,最优子树
小的时候,最优子树 偏大;极端情况,当
偏大;极端情况,当 时,整体树是最优的。当
时,整体树是最优的。当 时,根节点组成的单节点树是最优的。
时,根节点组成的单节点树是最优的。
Breiman等人证明:可以用递归的方法对数进行剪枝。将 从小增大,
从小增大, ,产生一系列的区间
,产生一系列的区间 ;剪枝得到的子树序列对应着区间
;剪枝得到的子树序列对应着区间 的最优子树序列
的最优子树序列 ,序列中的子树是嵌套的。
,序列中的子树是嵌套的。
具体地,从整体树 开始剪枝。对
开始剪枝。对 的任意内部节点
的任意内部节点 ,以
,以 为单结点的损失函数是
为单结点的损失函数是 (2.27)
(2.27)
以 为根结点的子树
为根结点的子树 的损失函数是
的损失函数是 (2.28)
(2.28)
当 时及
时及 充分小时,有不等式
充分小时,有不等式 (2.29)
(2.29)
当 增大时,在某一
增大时,在某一 有
有 (2.30)
(2.30)
当 再增大时,不等式(2.29)反向。只要
再增大时,不等式(2.29)反向。只要 ,
, 与
与 有相同的损失函数值,而
有相同的损失函数值,而 的节点少,因此
的节点少,因此 比
比 更可取,对
更可取,对 进行剪枝。
进行剪枝。
为此,对 中每一内部结点
中每一内部结点 ,计算
,计算 (2.31)
(2.31)
它表示剪枝后整体损失函数减少的程度。在 中剪去
中剪去 最小的
最小的 ,将得到的子树作为
,将得到的子树作为 ,同时将最小的
,同时将最小的 设为
设为 。
。 位区间
位区间 的最优子树。
的最优子树。
如此剪枝下去,直到根节点。在这一过程中,不断地增加 的值,产生新的区间。
的值,产生新的区间。
2.在剪枝得到的子树系列 中通过交叉验证选取最优子树
中通过交叉验证选取最优子树
具体地,利用独立的验证数据集,测试子树序列 中各棵子树的平方误差或基尼系数。平方误差或基尼系数最小的决策树被认为是最优的决策树。在子树序列中,没课子树
中各棵子树的平方误差或基尼系数。平方误差或基尼系数最小的决策树被认为是最优的决策树。在子树序列中,没课子树 都对应于一个参数
都对应于一个参数 。所以,当最优子树
。所以,当最优子树 确定时,对应的
确定时,对应的 也确定了,即得到最优决策树
也确定了,即得到最优决策树 。
。
现在写出CART剪枝算法。
算法2.7(CART剪枝算法)
输入:CART算法生成的决策树 ;
;
输出:修剪后的子树 ;
;
(1)设 。
。
(2)设 。
。
(3)自下而上地对内部结点 计算
计算 ,
, 以及
以及 

这里, 表示以
表示以 为根结点的子树,
为根结点的子树, 是对训练数据的预测误差,
是对训练数据的预测误差, 是
是 的叶结点个数。
的叶结点个数。
(4)对 的内部结点
的内部结点 进行剪枝,并对叶结点
进行剪枝,并对叶结点 以多数表决法决定其类,得到树
以多数表决法决定其类,得到树 。
。
(5)设 。
。
(6)如果 不是由根结点及两个叶结点构成的树,则回到步骤(2);否则零
不是由根结点及两个叶结点构成的树,则回到步骤(2);否则零 。
。
(7)采用交叉验证法在子树序列 中选取最优子树
中选取最优子树 。
。
3实现
算法实现(普通)
from math import logdef calc_shannon_ent(data_set):"""计算香农熵:param data_set:数据集:return: 香农熵值"""num_entries = len(data_set)label_counts = {}for feat_vec in data_set:current_label = feat_vec[-1]if current_label not in label_counts.keys():label_counts[current_label] = 0label_counts[current_label] += 1shannon_ent = 0.0for key in label_counts:prob = float(label_counts[key] / num_entries)shannon_ent -= prob * log(prob, 2)return shannon_entdef split_data_set(data_set, axis, value):"""获取训练数据集中指定列满足分类值的所有数据:param data_set: 训练数据集:param axis: 列序号:param value: 分类值:return: 包含训练值的数据"""ret_data_set = []for feat_vec in data_set:if feat_vec[axis] == value:reduced_feat_vec = feat_vec[:axis]reduced_feat_vec.extend(feat_vec[axis + 1:])ret_data_set.append(reduced_feat_vec)return ret_data_setdef choose_best_feature_to_split(data_set):"""ID3算法 计算信息增益最大的特征:param data_set:训练数据集:return: 选择信息增益最大的特征分类"""num_features = len(data_set[0]) - 1base_entropy = calc_shannon_ent(data_set)best_info_gain = 0.0best_feature = -1for i in range(num_features):feat_list = [example[i] for example in data_set]unique_vals = set(feat_list)new_entropy = 0.0for value in unique_vals:sub_data_set = split_data_set(data_set, i, value)prob = len(sub_data_set) / float(len(data_set))new_entropy += prob * calc_shannon_ent(sub_data_set)info_gain = base_entropy - new_entropyif info_gain > best_info_gain:best_info_gain = info_gainbest_feature = ireturn best_featuredef majority_cnt(class_list):"""当存在多个分类选择时,选取概率较大的分类:param class_list: 分类集合:return: 分类较大的标签"""class_count = {}for vote in class_list:if vote not in class_count.keys():class_count[vote] = 0class_count[vote] += 1import operatorsorted_class_count = sorted(class_count.items(),key=operator.itemgetter(1), reverse=True)return sorted_class_count[0][0]def create_tree(data_set, labels):"""生成决策树:param data_set: 训练数据集:param labels: 特征标签:return: 决策树"""# 计算所有分类项class_list = [example[-1] for example in data_set]# (1)若中所有实例属于同一类,则为单节点树# 将类作为该结点的类标记,返回Tif class_list.count(class_list[0]) == len(class_list):return class_list[0]# (2)若A为空集合,则为单结点树# 将中实例数最大的类作为该结点的类标记,返回Tif len(data_set[0]) == 1:return majority_cnt(class_list)# (3)否则,按照算法计算中各特征对的信息增益# 选择信息增益最大的特征Ag = best_feat_labelbest_feat_index = choose_best_feature_to_split(data_set)best_feat_label = labels[best_feat_index]del (labels[best_feat_index]) # 删除信息最大增益的特征# (4)创建以该特征为节点的树my_tree = {best_feat_label: {}}# (5)构建子结点feat_values = [example[best_feat_index] for example in data_set]unique_vals = set(feat_values)# (6)以子结点递归调用(1)~(5)for value in unique_vals:sub_lables = labels[:]my_tree[best_feat_label][value] = create_tree(split_data_set(data_set, best_feat_index, value), sub_lables)return my_treedef create_data_set():"""创建训练数据:return:(训练数据集,标签集)"""data_set = [[1, 1, 'yes'],[1, 1, 'yes'],[1, 0, 'no'],[0, 1, 'no'],[0, 1, 'no'],[1, 0, 'no'], # 制作分类冲突,引发majority_cnt调用[1, 0, 'yes'], # 制作分类冲突,引发majority_cnt调用]labels = ['no surfacing', 'flippers']return data_set, labelsif __name__ == '__main__':myDat, labels = create_data_set()myTree = create_tree(myDat, labels)print(myTree)
4 实践
4.1 一般使用流程
(1)收集数据:可以使用任何方法(2)准备数据:树构造算法只适用于标称型数据,一次数据型数据必须离散化(3)分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期(4)训练算法:构造树的数据结构(5)测试算法:使用经验树计算错误率(6)使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义
4.2 超参数和模型参数
4.3 基于scikit-learn的使用
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:,2:]
y = iris.target
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=2, criterion="entropy", random_state=42)
dt_clf.fit(X, y)
5 问题集合
1. 根据表1所给的训练数据集,利用信息增益比( 算法)生成决策树。
算法)生成决策树。
2. 已知表2所示的训练数据,使用平方误差损失准则生成一个二叉回归树
表2(待补充)
3. 证明 剪枝算法中,当
剪枝算法中,当 确定时,存在唯一的最小子树
确定时,存在唯一的最小子树 使损失函数
使损失函数 最小。
最小。
4. 证明 剪枝算法中求出的子树序列
剪枝算法中求出的子树序列 分别是区间
分别是区间 的最优子树
的最优子树 ,这里
,这里 ,
, 。
。
面试知识点
问题1 决策树有哪些常用的启发函数?
常用的决策树算法有ID3、C4.5、CART。
首先,我们回顾一下这几种决策树构造时使用的准则。
ID3——最大信息增益
C4.5——最大信息增益比
CART——最大基尼系数
问题2 如何对决策树进行剪枝?
决策树的剪枝通常有两种方法,预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。
预剪枝,即在生成决策树的过程中提前停止树的增长。
后剪枝,是在已生成的过拟合决策树上进行剪枝,得到简化版的剪枝决策树。
这两种方法是如何进行的呢?
它们又各有什么优缺点?
6 继续阅读
详见《统计机器学习》第二版 参考文献
参考文献
CHANGELOG
2020年12月19日15:35:20
第一版更新,参考自《统计机器学习》第二版  -
-

若有收获,就点个赞吧
0 人点赞
