一、架构
1.1 概述
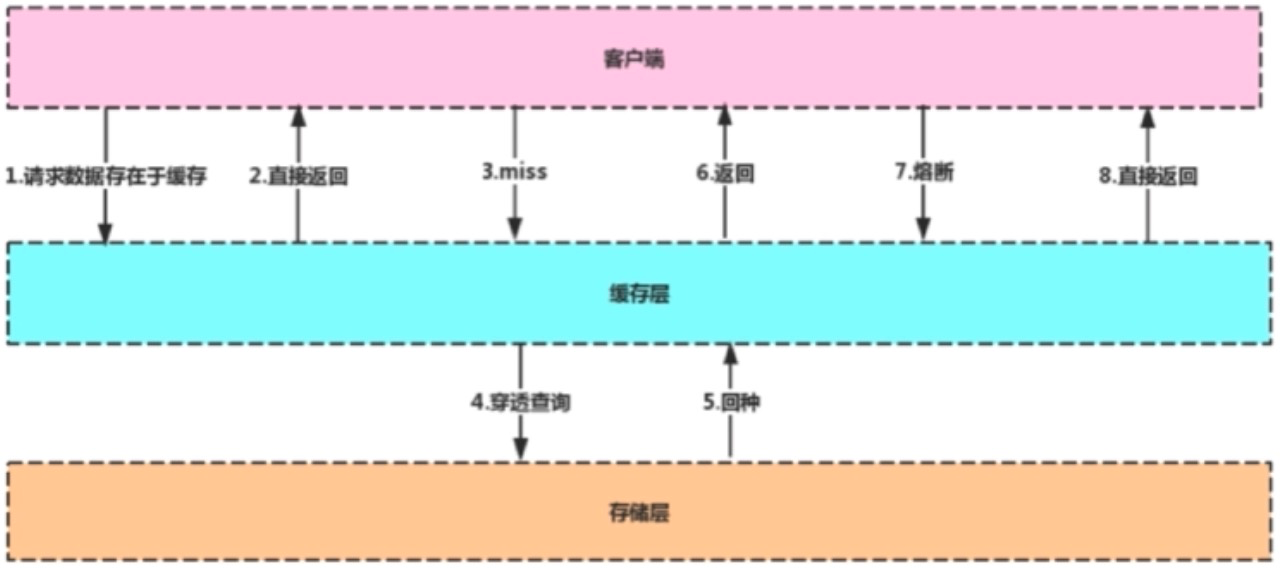
100000+QPS(QPS即query per second,每秒内查询次数),为什么能这么快?
1.2 Redis快的原因
1.2.1 完全基于内存
1.2.2 数据结构简单
1)String
2)Hash
3)List
4)Set
5)Sorted Set
通过分数来为集合中的成员进行从小到大的排序
1.2.3 使用多路I/O复用模型,非阻塞IO
Redis采用的I/O多路复用函数:epool/kqueque/evport/select
- 因地制宜
- 优先选择时间复杂度为O(1)的I/O多路复用函数作为底层实现
- 以实践复杂度为O(n)的select作为保底
- 基于react设计模式监听I/O事件
1)FD(文件描述符)
File Descriptor是一个打开的文件通过唯一的描述符进行引用,该描述符是打开文件的元数据到文件本身的映射。
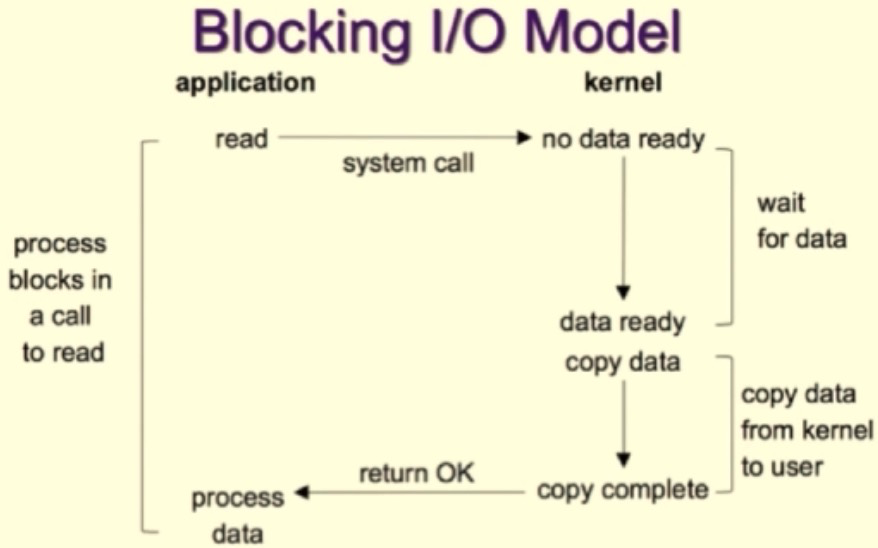
2)传统的阻塞I/O模型
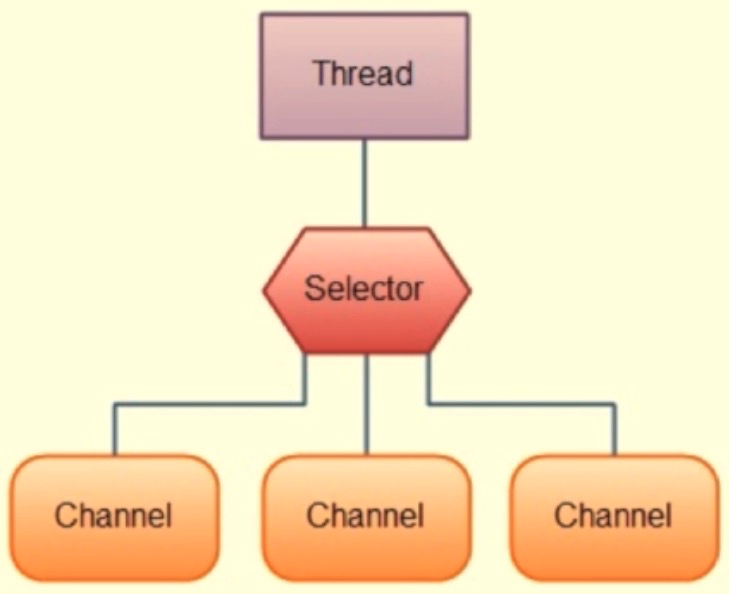
3)Select系统调用
二、实操
2.1 从海量key里查询出某一固定前缀的key
2.1.1 keys Parttern
查找所有符合给定模式pattern的key
- KEYS指令一次性返回所有匹配的key
-
2.1.2 SCAN cursor [match PARTTERN] [count COUNT]
基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程。具体操作步骤如下:
以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历
- 不保证每次执行都返回某个给定数量的元素,支持模糊查询
- 一次返回的数量不可控,职能大概率符合count参数
2.2 通过Redis实现分布式锁
2.2.1 分布式锁需要解决的问题
1)互斥性
2)安全性
3)死锁
4)容错
2.2.2 SETNX key value
如果key不存在,则创建并复制
- 时间复杂度:O(1)
- 返回值:设置成功,返回1;设置失败,返回0

若有收获,就点个赞吧
0 人点赞
