横向伸缩指控制 pod 数量.
- HorizontalpodAutoscaler (HPA) 资源
15.1.1 了解自动伸缩过程
三个步骤:
- 获取被伸缩资源对象所管理的所有 pod 度量
- 计算使度量数值到达 (或接近) 所指定目标数值所需的 pod 数量
- 更新被伸缩资源的 replicas 字段
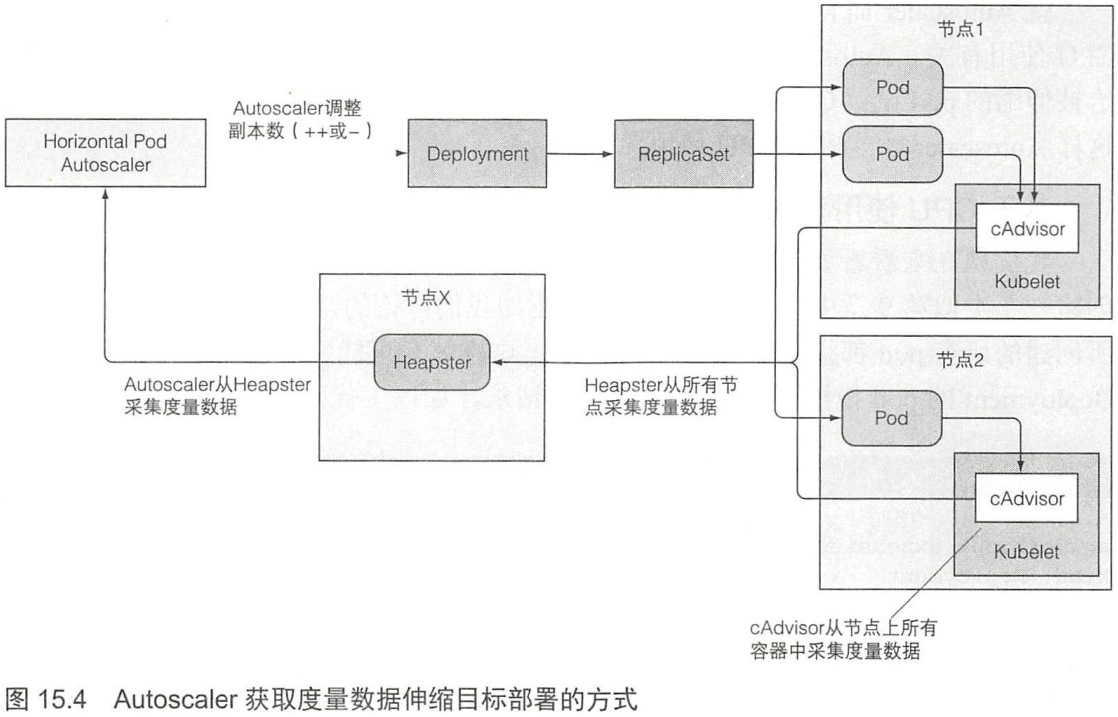
获取 pod 度量
- 度量数据由 cAdvisor 的 agent 采集
- 再由集群级组件 Heapster 聚合
- HPA 想 Heapster 发起 RESt 调用来获取所有 pod 度量数据

计算所需的 pod 数量


不知道为啥这么算.
更新被伸缩资源的副本数
Autoscaler 控制器通过 Scale 子资源来修改被伸缩资源的 replicas 字段.

API 服务需要暴露可伸缩资源的 Scale 子资源, Autoscaler 才能操作该资源, 目前暴露了 Scale 子资源的资源:
- Deployment
- ReplicaSet
- ReplicationController
- StatefulSet
了解整个自动伸缩过程
15.1.2 基于 CPU 使用率进行自动伸缩
Autoscaler 需要对比 pod 的实际 CPU 使用与它的请求.
基于 CPU 使用率创建 HPA
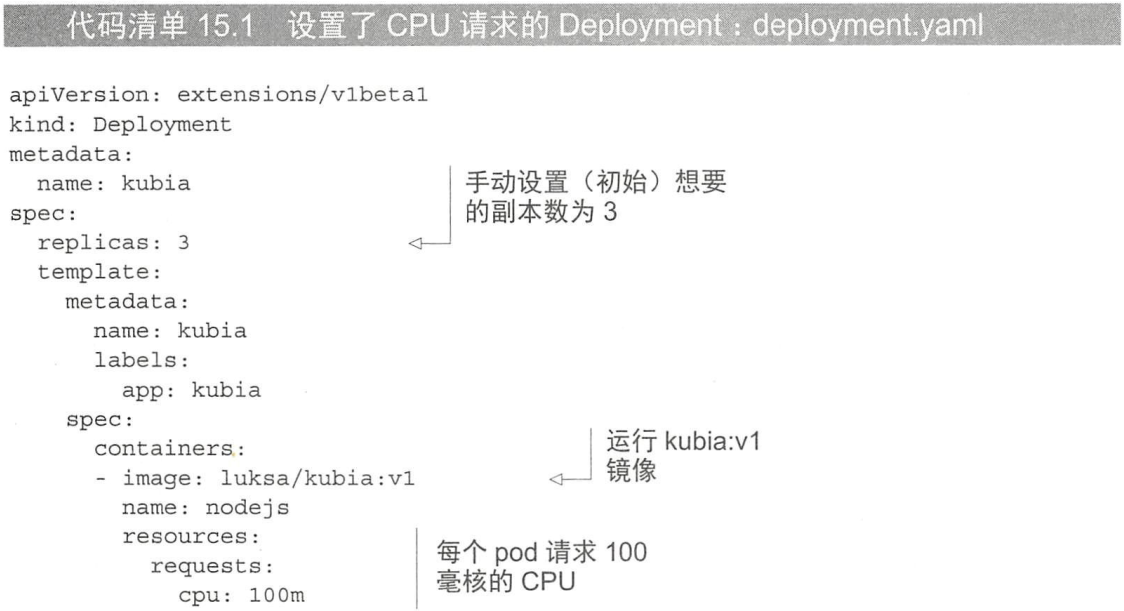
先整个正常的 dep:
使用命令创建 HPA:
$ kubectl autoscale deployment kubia --cpu-percent=30 --min=1 --max=5
HPA 的 yaml:

观察第一个自动伸缩事件
收集度量需要一阵子:

没什么请求量, 所以 hpa 把 dep 收缩到1个副本:

查看 hpa 当前状态:

触发一次自动扩容
暴露一个 service, 用于在多个 pod 前负载均衡:

在另一个终端中观察 hpa 和 dep:

启动客户端对服务加压:

观察 Autoscaler 扩容 Deployment
书上说 pod 的 cpu 从108%降到26%, pod 数量从1变4, 我还是没搞懂咋回事, 调度到别的节点了吗?
感觉应该是实际 cpu用量/request 所得百分比.

计算一下 pod 数怎么来的:

了解伸缩操作的最大速率
- Autoscaler 单次操作至多使副本数翻倍
- 3分钟内没有任何伸缩操作时才会触发扩容
- 缩容间隔需要5分钟
修改一个已有 HPA 对象的目标度量值
kubectl edit:

如果删除一个 hpa, 那么 dep 的规模将不变, 直到新的 hpa 被关联.
15.1.3 基于内存使用进行自动伸缩
不使用 k8s 的话, 内存不足时可能会利用 swap, 但是在 k8s 中已关闭.
15.1.4 基于其他自定义度量进行自动伸缩
Kubernetes 自动伸缩特别小组 (SIG).

有三种度量:
- 定义 metric 类型
- 使用情况会被监控的资源
- 资源的目标使用量
了解 Resource 度量类型
之前的容器资源请求.
了解 Pods 度量类型
Pods 类型用来引用任何其他种类的(包括自定义的)与 pod 直接相关的度量.
- qps

了解 Object 度量类型
Object 度 量 类型被用来让 Autoscaler 基于并非 直接与 pod 关 联的度 量 来进行伸缩 。
- 基于另一 个 集 群对 象 ,比如 Ingress 对 象 ,来伸缩你的pod
- qps
- 平均请求延迟

15.1.5 确定哪些度量适合用于自动伸缩
不是所有度 量都适合 作为自动伸缩的基础:
- 内存占用不是
- qps 是
15.1.6 缩容到0个副本
HPA 不允许设置 minReplicas 字段为0, 所以 autoscaler 永远不会缩容到0个副本.
未来可能会实现.

若有收获,就点个赞吧
0 人点赞
