数组和链表是两种数据结构,而在每种数据结构下,又有其非常多的变种。我以前在学习数组和链表的时候,这样理解:数组和链表是数据结构的基石,其不仅仅是不同的存储方式,其也是数据变种的根源。任何一种数据结构都可以使用数组和链表演化而来。
数组
- 数组:顾名思义,其就是一组数据组成的。这种数据可以是任意的数据类型,包括基本数据类型和引用数据类型。
- 数组可以是多维度的,但是多维数组,只是想象中的数组,计算机只能存储一维数组。怎么理解呢?我们稍后会解释,现在看下图。我们来重新理解下数组为啥是从0开始的,而非从1或者其他的数字开始作为下标。
- 解释
- 在运行的时候,会为这个数组分配一块内存
- 那么这个引用strings引用到的地址就是111的地址(0x11 1000号位置)
- 这里假设每个元素大小是4字节,那么数组在进行循环或者查找指定位置的元素的时候,会拿到整个4个字节的空间,才能拿到准确的值。
- 假如这个时候数组下标是从1开始的,那么计算111的占用的空间区间就是 1000+4(1-1) ~ 1000+4(2-1) - 1 = 1000 ~ 1003
- 假如这个时候数组下标是从0开始的,那么计算111的占用的空间区间就是 1000+40 ~ 1000+41 - 1 = 1000 ~ 1003
- 这样就少了2次减法运算,增加了处理速度

- 局部性原理
- CPU Cache 结构
- 速度越来越高 内存 -> L3 -> L2 -> L1 多级缓存
- 本质上内存是一个大的一维数组,二维数组在内存中按行排列,先存放a[0]行,在存放a[1]行
- 第一种遍历方式,是行遍历,先遍历完第一行在遍历第二行,符合局部性原理,Cache Hit (缓存命中率高)
- 第二种遍历方式,是列遍历,遍历完第一列在遍历第二列,因为每列的数据不是连贯的,所以可能导致Cache Miss (缓存未命中),CPU需要去内存载入数据,速度比CPU L1 Cache 的速度降低了很多(主存 100ns L1 Cache 0.5 ns)
测试如下:非必现的,可能 j,i 的方式更快 ```java public class ArraySpeedDemo2 { // m = n = 100 结果很不稳定 // m = n = 10000 结果很稳定 final static int m = 1000; final static int n = 1000;
final static int time = 100000;
// m:表示这个二维数组有多少个一维数组。 // n:表示每一个一维数组的元素有多少个。
// case: m = n = 1000,time = 100000 // result -> tip:iMore2J show less more total time. total time:100000, iMore2J time:739 // case: m = n = 100,time = 1000000 tip:iMore2J show less more total time. total time:1000000, iMore2J time:5051
public static void main(String[] args) {
int iMore2J = 0;for (int i = 0; i < time; i++) {if (testFromI2J() - testFromJ2I() > 0) {iMore2J++;}}System.out.println("tip:iMore2J show less more total time. total time:" + time + ", iMore2J time:" + iMore2J);
}
private static long testFromI2J() {
long startTime = System.nanoTime(); int[][] array = new int[m][n]; for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { array[i][j] = i + j; } } return System.nanoTime() - startTime;}
private static long testFromJ2I() {
long startTime = System.nanoTime(); int[][] array = new int[m][n]; for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { array[j][i] = i + j; } } return System.nanoTime() - startTime;} }
- **那么Java中二维数组是怎么分配的:这个地方要区分三种初始化方式**
- **方式一**
- 数据类型[][] 数组名 = new 数据类型[m][n];
- m 表示这个二维数组有多少个一维数组
- n 表示每一个一维数组的元素有多少个
- 例如:int arr[][] = new int[3][2];
```java
public class _2DArrayDemo01 {
public static void main(String[] args) {
int arr[][] = new int[3][2];
System.out.println(arr); // 0x001 1000
System.out.println(arr[0]); // 0x0001 1004
System.out.println(arr[1]); // 0x0002 1008
System.out.println(arr[2]); // 0x0003 1012
System.out.println(arr[0][0]);
System.out.println(arr[0][1]);
}
}

- 方式二
- 数据类型[][] 数组名 = new 数据类型[m][];
- m 表示这个二维数组有多少个一维数组
- 列没有给出,可以动态的给,这是一个变化的列数
例如:int arr[][] = new int[3][];
public class _2DArrayDemo02 { public static void main(String[] args) { int arr[][] = new int[3][]; System.out.println(arr); // 0x001 1000 System.out.println(arr[0]); // null System.out.println(arr[1]); // null System.out.println(arr[2]); // null // 动态分配 arr[0] = new int[2]; arr[1] = new int[3]; arr[2] = new int[1]; System.out.println(arr[0][0]); // 0 System.out.println(arr[0][1]); // 0 } }
方式三
- 基本格式:数据类型[][] 数组名 = new 数据类型[][]{{元素1,元素2…},{元素1,元素2…},{元素1,元素2…}};
简化格式:数据类型[][] 数组名 = {{元素1,元素2…},{元素1,元素2…},{元素1,元素2…}}; ```java public class _2DArrayDemo03 { public static void main(String[] args) {
// 分好了就不能变了,除非直接给某个数组进行赋值 int arr[][] = { { 1, 2, 3 }, { 4, 5 }, { 6 } }; arr[1] = new int[] { 7, 8, 9 }; System.out.println(arr); System.out.println(arr[0]); System.out.println(arr[1]); System.out.println(arr[2]);} }
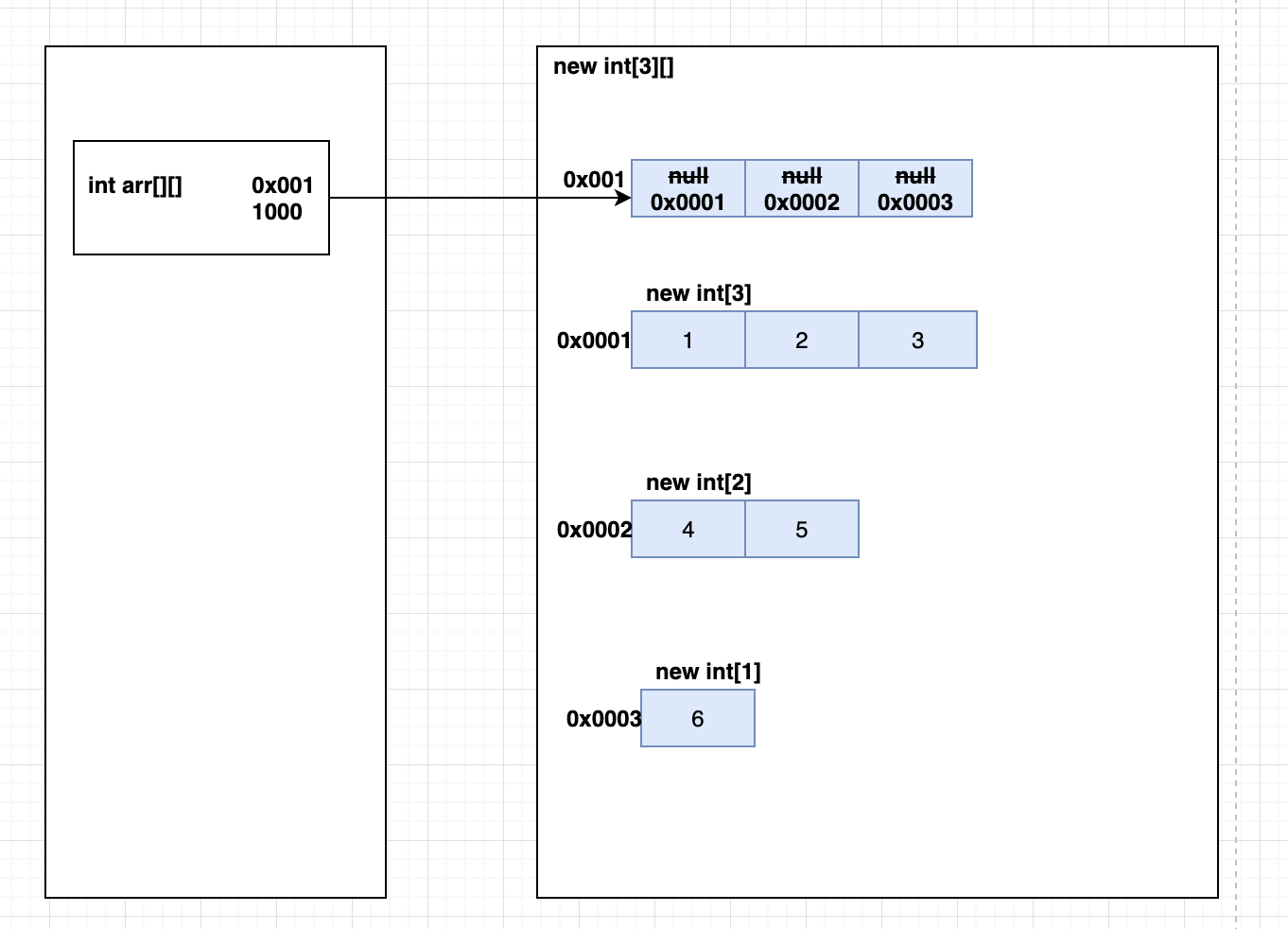
- **内存分配解释:**引用类型的默认值为null,定义二维数组时,会在堆内存为其分配内存空间(必须知道二维数组的行数,即一维数组的个数,才能够为其分配内存空间),首先给一个地址值0x001给arr,然后为二维数组里的一维数组分配内存空间,分别给一个地址值给一维数组,即0x0001给arr[0],0x0002给arr[1],0x0003给arr[2]。如果arr[3][]第二个元素值没有给出(相当于里面的一维数组的元素个数不知道),即以格式2定义二维数组,那么就无法为一维数组静态的分配内存空间了,即打印出来的arr[0],arr[1],arr[2]地址值是默认值null,可以动态的为其分配内存空间。
- **实际上:**针对于二维数组,其存储的方式是存储多个一维数组,每个二维数组都的一维数组,存储的是一位数组的地址。在使用第一种方式或第三种方式的时候**【int arr[][] = new int[3][2]; / int arr[][] = { { 1, 2, 3 }, { 4, 5 }, { 6 } };】**我们可以理解为其已经分配好了内存空间,直接向内存空间丢值即可。可以理解为其数据占用的内存是连续的。但是实际上,二维数组的内存分配不是一次性的,而是根据一维数组的数量和大小进行分配的。
- **明确一点:数组的长度是不可变的,看起来改变了数据的长度,实际上是新分配了一块内存空间,然后把引用返回。**
- **基本类型数据数组,存储的是基本数据类型数据;而引用数据类型数组,存储的是引用数据类型的引用。**
```java
public class ArrayDemo {
public static void main(String[] args) {
Person persons[] = new Person[5];
persons[0] = new Person();
persons[1] = new Person();
persons[2] = new Person();
persons[3] = new Person();
persons[4] = new Person();
}
}
class Person {
private String username;
private String password;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}

- 小结:
- 数组是不可变的,内存空间分配好就固定了。数组的类型是固定
- 数组是一种连续存储线性结构,元素类型相同,大小相等
- 数组的优点:
- 存取速度快
数组的缺点:
链表是离散存储线性结构
- n个节点离散分配,彼此通过指针相连,每个节点只有一个前驱节点,每个节点只有一个后续节点,首节点没有前驱节点,尾节点没有后续节点。
- 链表和火车相似,是一节一节的。确定一个链表只需要一个头节点。
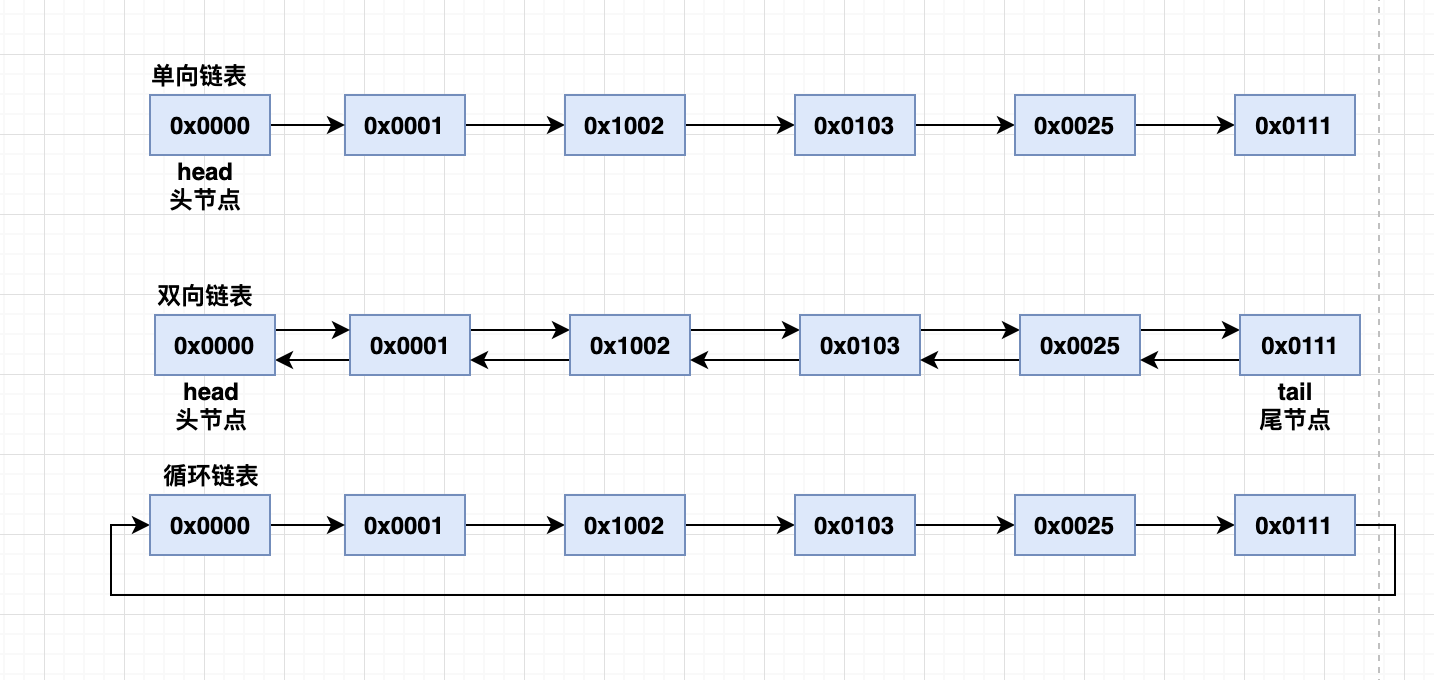
- 链表分类
- 单向链表:一个节点指向下一个节点
- 双向链表:一个节点有两个指针域
- 循环链表:能通过任何一个节点找到其他所有的节点,将两种(双向/单向)链表的最后一个结点指向第一个结点从而实现循环
- 操作链表要时刻记住的是:节点中指针域指向的就是一个节点了!
- 链表有很多相关的算法,超级多,本次只演示单向链表的增删改查的实现。后续在算法上会加深学习。
- 链表的结构如下
针对单向链表的初始化:初始化只需要创建一个头节点数据为空的节点即可
private class Node<T> { // 当前节点的数据 private T data; // 下一个节点对象引用 private Node<T> next; private Node() { } private Node(T data) { this.data = data; } }那么对于整个单向链表,只需要存储这样的数据即可
public class SinglyLinkedList<T> { // 头节点引用 private Node<T> head; // 链表长度大小 private int size; }单向链表的增加,找到链表最后一个节点,然后将新增节点丢上去

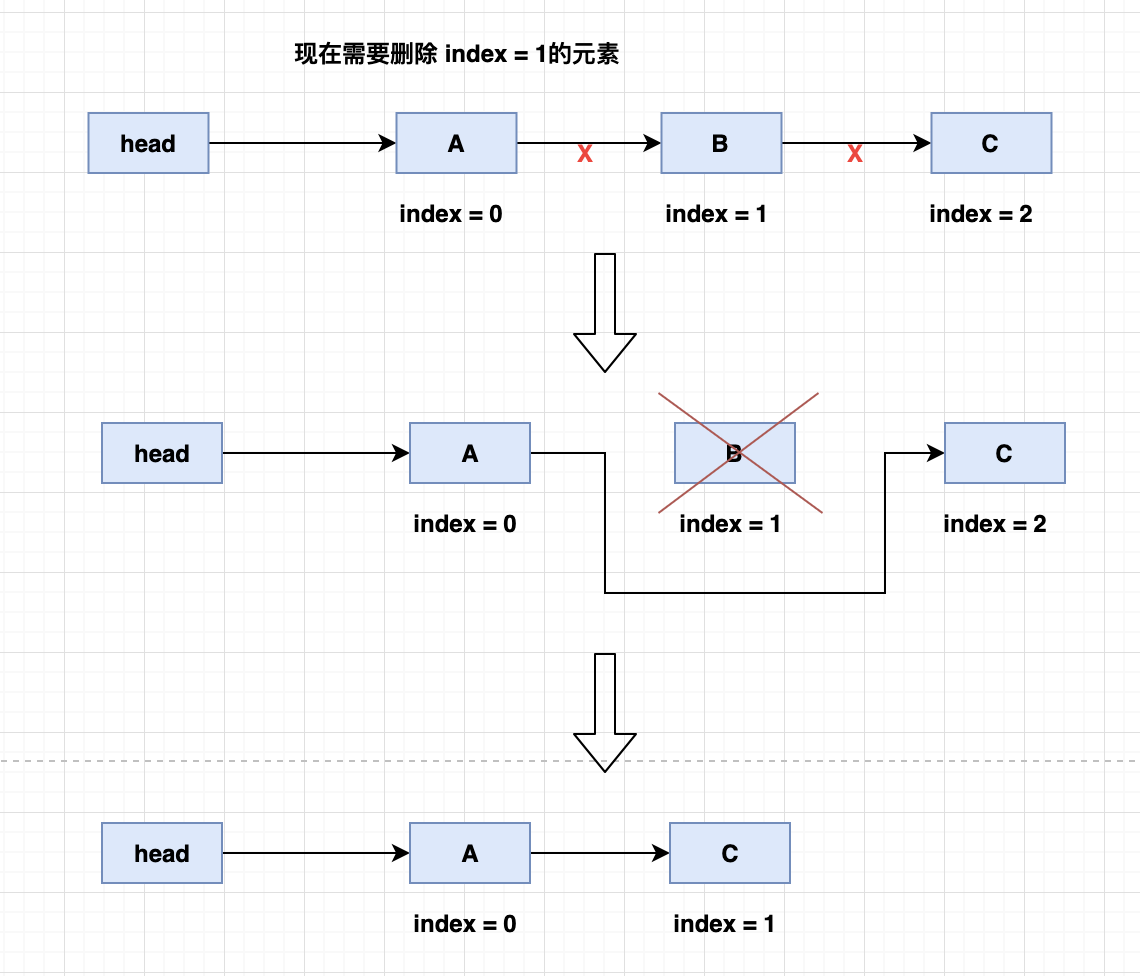
- 单向链表的删除指定下标元素 index
- 找到需要删除的元素的位置 B
- 取出需要删除元素的上一个节点 A
- 取出需要删除元素的下一个节点 C
- 将上一个节点A的下一个元素指向 C
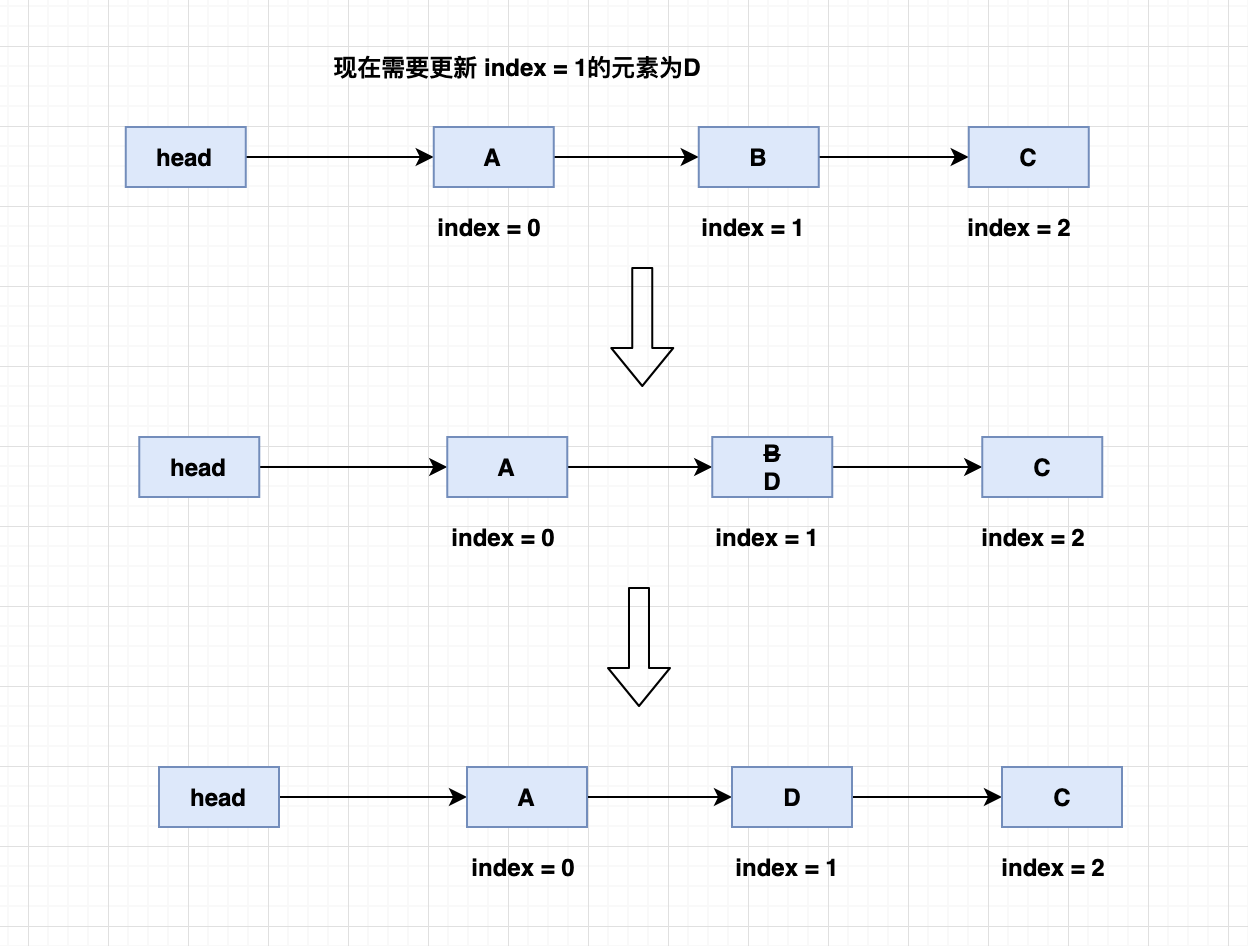
- 单向链表的更新指定下标元素
- 单向链表插入指定下标元素

完整代码 ```java public class SinglyLinkedList
{ private Node
head; private int size; private class Node
{ private T data; private Node<T> next; private Node() { } private Node(T data) { this.data = data; }}
/**
创建一个新的链表 */ public SinglyLinkedList() { head = new Node<>(); }
/**
- 增加一个元素 默认增加在尾部
@param t 元素 */ public void add(T t) { // 创建需要插入的节点 Node
tNode = new Node<>(t); // 临时节点 Node temp = head; // 遍历现有节点,找到尾巴节点 while (temp.next != null) { temp = temp.next;} temp.next = tNode; size++; }
/**
- 插入节点 *
- @param index 需要插入的下标
@param data 需要插入的值 */ public boolean insert(int index, T data) { // 小于0,或者是大于size,返回失败 if (index < 0 || index > size) {
return false;} //记录遍历的当前位置 int currentPos = 0; // 临时节点,从头节点开始 Node
temp = head; // 需要插入的节点 Node tNode = new Node<>(data); while (temp != null) { // 找到上一个节点的位置了 if (index == currentPos) { // temp 表示是上一个节点 // 取出到需要插入的下一个节点 Node<T> next = temp.next; // 插入节点挂在上个节点的下面 temp.next = tNode; // 插入节点的下个就是next tNode.next = next; size++; return true; }} return false; }
/**
- 更新节点的数据
- @param index index
- @param data data
@return 是否更新成功 */ public boolean update(int index, T data) { // 小于0,或者是大于size,返回失败 if (index < 0 || index > size) {
return false;} //记录遍历的当前位置 int currentPos = 0; // 临时节点,从头节点开始 Node
temp = head; // 找到需要更新的节点 while (temp != null) { // 找到上一个节点的位置了 if (index == currentPos) { temp.next.data = data; size++; return true; }} return false; }
/**
- 删除一个元素
- @param index index位置
@return 返回是否删除 */ public boolean delete(int index) { if (index < 0 || index >= size) {
return false;} //记录遍历的当前位置 int currentPos = 0; // 开始节点 存储头节点 Node
temp = head; while (temp != null) { if (index == currentPos) { // temp 表示上一个节点 // temp.next 表示需要删除的节点 // 将想要删除的节点存储一下 Node<T> deleteNode = temp.next; // 将上一个节点的下一个节点执行要删除的下一个节点 temp.next = deleteNode.next; // deleteNode 设置为 null 不设置也是也可以的 垃圾回收器会自动进行回收 deleteNode = null; // 个数变小 size--; return true; } // 不符合条件 继续自增 currentPos++; // 指针下移 temp = temp.next;} return false; }
/**
- 获取大小 *
@return 返回链表的大小 */ public int getSize() { return size; }
/**
打印链表 */ public void print() { // 控制头节点不输出数据 Node
temp = head.next; while (temp != null) {
System.out.println(temp.data); temp = temp.next;} }
@Override public String toString() { StringBuilder builder = new StringBuilder(); builder.append(“size:” + size); // 控制头节点不输出数据 Node
temp = head.next; if (temp != null) { builder.append(" eles:");} while (temp != null) {
builder.append(temp.data + ","); temp = temp.next;} return builder.toString(); } }
class SinglyLinkedListTest {
public static void main(String[] args) {
SinglyLinkedList
- 小结
- 链表优点:空间没有限制、插入删除元素很快
-
分析一下
数组插入删除元素:O(n)
- 数组查找元素:O(1)
- 单向链表插入删除元素:O(1)
- 单向链表查找元素:O(n)
- 数组更新元素:O(1)
-
参考文章
Java实现单向链表基本功能:https://www.cnblogs.com/Java3y/p/8664874.html

若有收获,就点个赞吧
0 人点赞
