- Java4
- Java6
- Java7
- 新特性列表
- suppress异常(新语法)
- try-with-resources(新语法)
- JSR341-Expression Language Specification(新规范)
- JSR203-More New I/O APIs for the Java Platform(新规范)
- JSR292与InvokeDynamic
- 支持JDBC4.1规范
- Path接口(重要接口更新)
- Files
- jcmd utility
- fork/join框架
- Java Mission Control
- 增强泛型推断
- Binary Literals支持
- Numeric Literals的下划线支持
- Strings in switch Statements
- Java8
- Java9
- Java10
- Java11
- Java14
- Java15
- 参考文章
在JDK的演进过程中,会在不同的版本中推出一些新的特性, 能够使得提升开发效率、提升线程安全等的操作。其十分重要,所以需要了解并且去学习其的基本原理。在这一篇中,会对各个版本的JDK的新特性进行整理。
Java4
新特性列表
- XML
- Logging API
- 断言
- Preferences API
- 链式异常处理
- 支持IPV6
- 支持正则表达式
- 引入 Image I/O API
-
XML处理
针对XML处理的JavaTM API 已经被添加到Java 2平台。它通过一套标准的Java平台API提供对XML的基本处理的支持
Logging API
解释:Logging API为程序提供了一种报告其行为的机制。它提供了一种在现场部署应用程序后打开和关闭日志消息的方法,极大地帮助了应用程序的维护。
推荐阅读: https://www.cnblogs.com/liaojie970/p/5582147.html
断言
解释:它是用于对程序进行调试的,对于执行结构的判断,而不是对业务流程的判断。可以理解为一个if()语句,满足条件才会执行,不满足就直接报错
- 语法:assert condition 或者 assert condition : “提示信息” 这里condition是一个必须为真(true)的表达式。如果表达式的结果为true,那么断言为真,则不会有任何行动;如果表达式为false,则断言失败,这时会抛出一个AssertionError。–asser condition:expr这里condition是一个必须为真(true)的表达式。冒号后跟的是一个表达式,通常用于断言失败后的提示信息,简而言之是一个传到AssertionError构造函数的值,如果断言失败,该值被转化为它对应的字符串,并显示出来。
例子:注意(JDK中默认是不开启断言的,需要设置一下VM参数:-enableassertions )
public class AssertTest {public static void main(String[] args) {int x = 10;System.out.println("Testing Assertion that x==100");assert x == 100 : "Out assertion failed!";System.out.println("Test passed!");}}
执行结果如下 ```java Testing Assertion that x==100 Exception in thread “main” java.lang.AssertionError: Out assertion failed! at com.ldl.baselearn.jdk.java4.AssertTest.main(AssertTest.java:11) [ERROR] Command execution failed.
<a name="dOS7T"></a>## Preferences API- 解释:用于将首选项存储到特定于操作系统的后端。在Windows等操作系统上,首选项存储在操作系统级别的注册表中,对于非Windows环境,它们可以存储在其他注册表类存储中,也可以存储在简单的XML文件中```javapublic class PreferencesTest {public static void main(String[] args) {Preferences root = Preferences.userRoot();root.put("age", "19");// 这里的 1 是默认值// 如果 age 没值,则不返回int fontSize = root.getInt("age", 1);System.out.println(fontSize);}}
链式异常处理
- 解释:链式异常允许将一个异常与另一个异常联系起来,即一个异常描述了另一个异常的原因。例如,考虑一种情况,即由于试图除以零而导致抛出ArithmeticException,但实际的异常原因是导致除数为零的I / O错误。该方法只会向调用者抛出ArithmeticException。所以调用者不会知道异常的真正原因。就向在之前的异常部分的讲解一样,有BuilderException返回,其中包装的就是OrderException
```java
public class ExceptionHandling {
public static void main(String[] args) {
} }try { //创建一个错误 NumberFormatException ex = new NumberFormatException("Exception"); //设置错误的触发原因 ex.initCause(new NullPointerException("This is actual cause of the exception")); //抛出错误并指明原因 throw ex; } catch (NumberFormatException ex) { //在控制台打印错误 System.out.println(ex); //获得错误的触发原因 System.out.println(ex.getCause()); }
<a name="uZ796"></a>
## 支持IPV6
- 解释:JDK 1.4开始支持 Linux 和Solaris 平台上的 IPv6(JDK 1.5起加入了 Windows 平台上的支持)
<a name="m5NxX"></a>
## 支持正则表达式
- 推荐教程: [https://www.runoob.com/java/java-regular-expressions.html](https://www.runoob.com/java/java-regular-expressions.html)
<a name="C9qRg"></a>
## 引入image I/O API
- 解释:提供了一组用于操作存在本地文件的或者通过网络传输的图片的可插入式架构。它较之前的API在读取和保存图片方面总体上来看要更加灵活和强大。
- 推荐阅读: [https://www.jianshu.com/p/22bcb11109d0](https://gitee.com/link?target=https%3A%2F%2Fwww.jianshu.com%2Fp%2F22bcb11109d0)
<a name="gyj4t"></a>
## NIO
- 推荐阅读: [https://blog.csdn.net/u011381576/article/details/79876754](https://blog.csdn.net/u011381576/article/details/79876754)
- NIO会在之后学习Java IO、网络编程、Netty详细学习
<a name="ftoGu"></a>
# Java5
<a name="V2bH6"></a>
## 新特性列表
- 泛型
- 枚举
- 装箱拆箱
- 变长参数
- 注解
- foreach循环
- 静态导入
- 格式化
- 线程框架/数据结构
- Arrays工具类/StringBuilder/instrument
<a name="cpbTI"></a>
## 泛型
- 泛型在之前的内容已经详细讲解,此处略过
<a name="oZBOD"></a>
## 枚举
- 枚举在之前的内容已经详细讲解,此处略过
<a name="VNIRm"></a>
## 装箱拆箱 Autoboxing与Unboxing
- 自动拆箱装箱在之前的内容已经详细讲解,此处略过
<a name="Br5W1"></a>
## 可变参数
- 在一些方法中,其参数不确定,又不好使用数组,因此可变参数出现
- 可变参数在使用的时候,只能放在参数列表的末尾
- 注意: 避免带有变长参数的方法重载
```java
public class Client {
/**
* 简单折扣计算
*/
public void calPrice(int price, int discount) {
float knockdownPrice = price * discount / 100.0F;
System.out.println("简单折扣后的价格是: " + formatCurrency(knockdownPrice));
}
/**
* 复杂折扣计算:折上折
*/
public void calPrice(int price, int... discounts) {
float knockdownPrice = price * 2;
for (int discount : discounts) {
knockdownPrice = knockdownPrice * discount / 100;
}
System.out.println("复杂折扣运算后的价格是: " + formatCurrency(knockdownPrice));
}
/**
* 格式化成本的货币形式
*/
private String formatCurrency(float price) {
return NumberFormat.getCurrencyInstance().format(price / 100);
}
public static void main(String[] args) {
Client client = new Client();
client.calPrice(49900, 75);
}
}
当传入的参数为(49900,75)时,调用了第一个方法,而不是第二个方法,重载变长参数时,会使编译器无法判断应调用哪个方法,只能根据默认的调用
注解
-
增强for循环
做得到的事情
- 简化集合和数组的读取
- 做不到的事情
- 遍历同时获取index
- 集合逗号拼接时去掉最后一个
- 遍历的同时删除元素
-
静态导入
可以静态导入一个包,然后其包下的静态常量和方法可以直接调用
- 一般静态导入,用的很少 ```java
import static java.lang.Math.PI; import static java.lang.Math.max;
/**
- @author icanci
- @since 1.0 Created in 2022/02/18 16:45
*/
public class StaticImportTest {
public static void main(String[] args) {
} }System.out.println(PI); System.out.println(max(2, 5));
<a name="sebQX"></a>
## 格式化
- 出现了类似C语言一样的格式化,方便Java程序输出结果,而不是去拼接字符串
```java
/**
* java.text.DateFormat
* java.text.SimpleDateFormat
* java.text.MessageFormat
* java.text.NumberFormat
* java.text.ChoiceFormat
* java.text.DecimalFormat
*
* @author icanci
* @since 1.0 Created in 2022/02/18 16:46
*/
public class FormatTest {
public static void printf() {
//printf
String filename = "this is a file";
try {
File file = new File(filename);
FileReader fileReader = new FileReader(file);
BufferedReader reader = new BufferedReader(fileReader);
String line;
int i = 1;
while ((line = reader.readLine()) != null) {
System.out.printf("Line %d: %s%n", i++, line);
}
} catch (Exception e) {
System.err.printf("Unable to open file named '%s': %s", filename, e.getMessage());
}
}
public static void stringFormat() {
// Format a string containing a date.
Calendar c = new GregorianCalendar(1995, 11, 23);
String s = String.format("Duke's Birthday: %1$tm %1$te,%1$tY", c);
// -> s == "Duke's Birthday: May 23, 1995"
System.out.println(s);
}
public static void formatter() {
StringBuilder sb = new StringBuilder();
// Send all output to the Appendable object sb
Formatter formatter = new Formatter(sb, Locale.US);
// Explicit argument indices may be used to re-order output.
formatter.format("%4$2s %3$2s %2$2s %1$2s", "a", "b", "c", "d");
// -> " d c b a"
// Optional locale as the first argument can be used to get
// locale-specific formatting of numbers. The precision and width can be
// given to round and align the value.
formatter.format(Locale.FRANCE, "e = %+10.4f", Math.E);
// -> "e = +2,7183"
// The '(' numeric flag may be used to format negative numbers with
// parentheses rather than a minus sign. Group separators are
// automatically inserted.
formatter.format("Amount gained or lost since last statement: $ %(,.2f", 6217.58);
// -> "Amount gained or lost since last statement: $ (6,217.58)"
}
public static void messageFormat() {
String msg = "欢迎光临,当前({0})等待的业务受理的顾客有{1}位,请排号办理业务!";
MessageFormat mf = new MessageFormat(msg);
String fmsg = mf.format(new Object[] { new Date(), 35 });
System.out.println(fmsg);
}
public static void dateFormat() {
String str = "2010-1-10 17:39:21";
SimpleDateFormat format = new SimpleDateFormat("yyyyMMddHHmmss");
try {
System.out.println(format.format(format.parse(str)));
} catch (ParseException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
formatter();
stringFormat();
messageFormat();
dateFormat();
printf();
}
}
输出结果
Duke's Birthday: 12 23,1995 欢迎光临,当前(22-2-18 下午4:48)等待的业务受理的顾客有35位,请排号办理业务! 20091030000107-
线程框架/数据结构
线程不抛出异常的方法 ```java public class BubbleSortThread extends Thread { private int[] numbers;
public BubbleSortThread(int[] numbers) {
setName("Simple Thread"); setUncaughtExceptionHandler(new SimpleThreadExceptionHandler()); this.numbers = numbers;}
public void run() {
int index = numbers.length; boolean finished = false; while (!finished) { index--; finished = true; for (int i = 0; i < index; i++) { // Create error condition if (numbers[i + 1] < 0) { throw new IllegalArgumentException("Cannot pass negative numbers into this thread!"); } if (numbers[i] > numbers[i + 1]) { // swap int temp = numbers[i]; numbers[i] = numbers[i + 1]; numbers[i + 1] = temp; finished = false; } } }} }
class SimpleThreadExceptionHandler implements Thread.UncaughtExceptionHandler { public void uncaughtException(Thread t, Throwable e) { System.err.printf(“%s: %s at line %d of %s%n”, t.getName(), e.toString(), e.getStackTrace()[0].getLineNumber(), e.getStackTrace()[0].getFileName()); } }
```java
public class BubbleSortThreadMain {
public static void main(String[] args) {
int[] numbers = { 1, -120, 90 };
new BubbleSortThread(numbers).start();
}
}
输出结果
Simple Thread: java.lang.IllegalArgumentException: Cannot pass negative numbers into this thread! at line 25 of BubbleSortThread.javablocking queue ```java public class Producer extends Thread { private BlockingQueue q; private PrintStream out;
public Producer(BlockingQueue q, PrintStream out) {
setName("Producer"); this.q = q; this.out = out;}
public void run() {
try { while (true) { q.put(produce()); } } catch (InterruptedException e) { out.printf("%s interrupted: %s", getName(), e.getMessage()); }}
private String produce() {
while (true) { double r = Math.random(); // Only goes forward 1/10 of the time if ((r * 100) < 10) { String s = String.format("Inserted at %tc", new Date()); return s; } }} }
```java
public class ProducerTest {
public static void main(String[] args) {
new Producer(new DelayQueue(), System.out).start();
}
}
运行结果
Exception in thread "Producer" java.lang.ClassCastException: java.lang.String cannot be cast to java.util.concurrent.Delayed at java.util.concurrent.DelayQueue.put(DelayQueue.java:70) at com.ldl.baselearn.jdk.java5.Producer.run(Producer.java:24)JUC
-
线程池
会和JUC一起学习
- 每次提交任务时,如果线程数还没达到coreSize就创建新线程并绑定该任务。 所以第coreSize次提交任务后线程总数必达到coreSize,不会重用之前的空闲线程。
- 线程数达到coreSize后,新增的任务就放到工作队列里,而线程池里的线程则努力的使用take()从工作队列里拉活来干。
- 如果队列是个有界队列,又如果线程池里的线程不能及时将任务取走,工作队列可能会满掉,插入任务就会失败,此时线程池就会紧急的再创建新的临时线程来补救。
- 临时线程使用poll(keepAliveTime,timeUnit)来从工作队列拉活,如果时候到了仍然两手空空没拉到活,表明它太闲了,就会被解雇掉。
如果core线程数+临时线程数 >maxSize,则不能再创建新的临时线程了,转头执行RejectExecutionHanlder。默认的AbortPolicy抛RejectedExecutionException异常,其他选择包括静默放弃当前任务(Discard),放弃工作队列里最老的任务(DisacardOldest),或由主线程来直接执行(CallerRuns),或你自己发挥想象力写的一个
Arrays工具类/StringBuilder/instrument
Arrays
StringBuilder出现,先有的StringBuffer,其是线程安全的,String的底层就是创建StringBuffer,在Java5之后,则是创建StringBuilder
Java6
新特性列表
JSR223脚本引擎
- JSR199—Java Compiler API
- JSR269—Pluggable Annotation Processing API
- 支持JDBC4.0规范
-
JSR223脚本引擎
支持各种脚本,包括 JavaScript脚本、mvel表达式、Groovy脚本等,有的需要引入第三方包来实现
后期做项目的时候,需要用到动态脚本去处理规则引擎 ```java public class Test { public void greet() throws ScriptException {
ScriptEngineManager manager = new ScriptEngineManager(); //支持通过名称、文件扩展名、MIMEtype查找 ScriptEngine engine = manager.getEngineByName("JavaScript"); // engine = manager.getEngineByExtension("js"); // engine = manager.getEngineByMimeType("text/javascript"); if (engine == null) { throw new RuntimeException("找不到JavaScript语言执行引擎。"); } engine.eval("print('Hello!');");}
public static void main(String[] args) {
try { new Test().greet(); } catch (ScriptException ex) { Logger.getLogger(Test.class.getName()).log(Level.SEVERE, null, ex); }} }
<a name="SO7Wg"></a>
## JSR199--Java Compiler API
- 使用使用Java API来编译Java源代码
- 用的很少,而且不安全
```java
public class JavaCompilerAPICompiler {
public void compile(Path src, String to) throws IOException {
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
try (StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null)) {
Iterable<? extends JavaFileObject> compilationUnits = fileManager.getJavaFileObjects(src.toFile());
Iterable<String> options = Arrays.asList("-d", to);
JavaCompiler.CompilationTask task = compiler.getTask(null, fileManager, null, options, null, compilationUnits);
boolean result = task.call();
System.out.println(result);
}
}
}
//
其他
- 支持JDBC4.0规范
- JAX-WS 2.0规范(包括JAXB 2.0)
-
推荐阅读
推荐阅读: https://blog.csdn.net/peterwin1987/article/details/7560637
Java7
新特性列表
suppress异常(新语法)
- 捕获多个异常(新语法)
- try-with-resources(新语法)
- JSR341-Expression Language Specification(新规范)
- JSR203-More New I/O APIs for the Java Platform(新规范)
- JSR292与InvokeDynamic
- 支持JDBC4.1规范
- Path接口、DirectoryStream、Files、WatchService
- jcmd
- fork/join framework
- Java Mission Control
- 增强泛型推断
- 数字字面量的改进 二进制和数字的下划线
-
suppress异常(新语法)
这个语法在实际开发中,没用过
public class BaseException extends Exception { public BaseException(Throwable cause) { super(cause); } }```java public class ReadFile { public void read(String filename) throws BaseException {
FileInputStream input = null; IOException readException = null; try { input = new FileInputStream(filename); } catch (IOException ex) { readException = ex; } finally { if (input != null) { try { input.close(); } catch (IOException ex) { if (readException == null) { readException = ex; } else { //使用java7的 readException.addSuppressed(ex); } } } if (readException != null) { throw new BaseException(readException); } }} }
<a name="ZsMOu"></a>
## 捕获多个异常(新语法)
- 注意,捕获多个异常,只能从小到大:意思就是小范围的异常必须在前,大范围的异常在后
```java
public void handle() {
ExceptionThrower thrower = new ExceptionThrower();
try {
thrower.manyExceptions();
} catch (ExceptionA | ExceptionB ab) {
System.out.println(ab.getClass());
} catch (ExceptionC c) {
}
}
try-with-resources(新语法)
- 不使用新语法的异常处理如下
```java
public class ReadFile2 {
public void read(String filename) throws BaseException {
} }FileInputStream input = null; IOException readException = null; try { input = new FileInputStream(filename); } catch (IOException ex) { readException = ex; } finally { if (input != null) { try { input.close(); } catch (IOException ex) { readException = ex; } } if (readException != null) { throw new BaseException(readException); } }
- 使用Java7新语法之后
```java
public class ReadFile3 {
public void read(String filename) throws BaseException {
try (FileInputStream input = new FileInputStream(filename)) {
input.read();
} catch (Exception e) {
throw new BaseException(e);
}
}
}
- 为什么可以,因为实现了 AutoCloseable
看一下继承体系
public class FileInputStream extends InputStream{} public abstract class InputStream implements Closeable {} public interface Closeable extends AutoCloseable {} public interface AutoCloseable {}也就是说,实现了 AutoCloseable 的资源,都可以在try-resource中创建,并被自动执行关闭资源的方法
/** * @author Josh Bloch * @since 1.7 */ public interface AutoCloseable { void close() throws Exception; }实现 AutoCloseable接口 ```java public class CustomResource implements AutoCloseable { private final InputStream INPUT_STREAM;
public CustomResource(InputStream INPUT_STREAM) {
this.INPUT_STREAM = INPUT_STREAM;}
@Override public void close() throws Exception {
if (this.INPUT_STREAM != null) { INPUT_STREAM.close(); }}
public String getPath() {
System.out.println(INPUT_STREAM); return "success";} } public class CustomResource implements AutoCloseable { private final InputStream INPUT_STREAM;
public CustomResource(InputStream INPUT_STREAM) {
this.INPUT_STREAM = INPUT_STREAM;}
@Override public void close() throws Exception {
if (this.INPUT_STREAM != null) { INPUT_STREAM.close(); }} }
```java
public class CustomResourceTest {
public static void main(String[] args) {
String path = "/Users/icanci/ideaProjects/NewLearn/base-learn/src/main/java/com/ldl/baselearn/jdk/java7/hello.txt";
try (CustomResource customResource = new CustomResource(new FileInputStream(path))) {
System.out.println(customResource.getPath());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
}
JSR341-Expression Language Specification(新规范)
-
JSR203-More New I/O APIs for the Java Platform(新规范)
bytebuffer ```java public class ByteBufferUsage { public void useByteBuffer() {
ByteBuffer buffer = ByteBuffer.allocate(32); buffer.put((byte) 1); buffer.put(new byte[3]); buffer.putChar('A'); buffer.putFloat(0.0f); buffer.putLong(10, 100L); System.out.println(buffer.getChar(4)); System.out.println(buffer.remaining());}
public void byteOrder() {
ByteBuffer buffer = ByteBuffer.allocate(4); buffer.putInt(1); buffer.order(ByteOrder.LITTLE_ENDIAN); //值为16777216 buffer.getInt(0);}
public void compact() {
ByteBuffer buffer = ByteBuffer.allocate(32); buffer.put(new byte[16]); buffer.flip(); buffer.getInt(); buffer.compact(); int pos = buffer.position();}
public void viewBuffer() {
ByteBuffer buffer = ByteBuffer.allocate(32); buffer.putInt(1); IntBuffer intBuffer = buffer.asIntBuffer(); intBuffer.put(2); int value = buffer.getInt(); //值为2}
/**
- @param args the command line arguments */ public static void main(String[] args) { ByteBufferUsage bbu = new ByteBufferUsage(); bbu.useByteBuffer(); bbu.byteOrder(); bbu.compact(); bbu.viewBuffer(); }
- filechannel
```java
public class FileChannelUsage {
public void openAndWrite() throws IOException {
FileChannel channel = FileChannel.open(Paths.get("my.txt"), StandardOpenOption.CREATE, StandardOpenOption.WRITE);
ByteBuffer buffer = ByteBuffer.allocate(64);
buffer.putChar('A').flip();
channel.write(buffer);
}
public void readWriteAbsolute() throws IOException {
FileChannel channel = FileChannel.open(Paths.get("absolute.txt"), StandardOpenOption.READ, StandardOpenOption.CREATE, StandardOpenOption.WRITE);
ByteBuffer writeBuffer = ByteBuffer.allocate(4).putChar('A').putChar('B');
writeBuffer.flip();
channel.write(writeBuffer, 1024);
ByteBuffer readBuffer = ByteBuffer.allocate(2);
channel.read(readBuffer, 1026);
readBuffer.flip();
char result = readBuffer.getChar(); //值为'B'
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) throws IOException {
FileChannelUsage fcu = new FileChannelUsage();
fcu.openAndWrite();
fcu.readWriteAbsolute();
}
}
JSR292与InvokeDynamic
- JSR 292: Supporting Dynamically Typed Languages on the JavaTM Platform,支持在JVM上运行动态类型语言。在字节码层面支持了InvokeDynamic。
- 方法句柄MethodHandle
-
支持JDBC4.1规范
abort方法 ```java public class AbortConnection { public void abortConnection() throws SQLException {
Connection connection = DriverManager.getConnection("jdbc:mysql:///test"); ThreadPoolExecutor executor = new DebugExecutorService(2, 10, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>()); connection.abort(executor); executor.shutdown(); try { executor.awaitTermination(5, TimeUnit.MINUTES); System.out.println(executor.getCompletedTaskCount()); } catch (InterruptedException e) { e.printStackTrace(); }}
private static class DebugExecutorService extends ThreadPoolExecutor {
public DebugExecutorService(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue); } public void beforeExecute(Thread t, Runnable r) { System.out.println("清理任务:" + r.getClass()); super.beforeExecute(t, r); }}
public static void main(String[] args) {
AbortConnection ca = new AbortConnection(); try { ca.abortConnection(); } catch (SQLException e) { e.printStackTrace(); }} }
- 自动关闭
```java
public class SetSchema {
public void setSchema() throws SQLException {
try (Connection connection = DriverManager.getConnection("jdbc:derby:///test")) {
connection.setSchema("DEMO_SCHEMA");
try (Statement stmt = connection.createStatement(); ResultSet rs = stmt.executeQuery("SELECT * FROM author")) {
while (rs.next()) {
System.out.println(rs.getString("name"));
}
}
}
}
public static void main(String[] args) {
SetSchema ss = new SetSchema();
try {
ss.setSchema();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
自动映射
public class UseSQLData { public void useSQLData() throws SQLException { try (Connection connection = DriverManager.getConnection("jdbc:mysql:///test")) { Map<String, Class<?>> typeMap = new HashMap<>(); typeMap.put("test.Book", Book.class); try (Statement stmt = connection.createStatement(); ResultSet rs = stmt.executeQuery("SELECT * FROM book")) { while (rs.next()) { System.out.println(rs.getObject(1, Book.class)); } } } } public static void main(String[] args) { UseSQLData usd = new UseSQLData(); try { usd.useSQLData(); } catch (SQLException e) { e.printStackTrace(); } } }Path接口(重要接口更新)
```java public class PathUsage { public void usePath() {
// get 方法的作用 路径串,或当加入形式的路径串,到串的序列转换Path Path path1 = Paths.get("folder1", "sub1"); Path path2 = Paths.get("folder2", "sub2"); //folder1\sub1\folder2\sub2 path1.resolve(path2); //folder1\folder2\sub2 path1.resolveSibling(path2); //..\..\folder2\sub2 path1.relativize(path2); //folder1 path1.subpath(0, 1); //false path1.startsWith(path2); //false path1.endsWith(path2); //folder2\my.text Paths.get("folder1/./../folder2/my.text").normalize();}
/**
- @param args the command line arguments */ public static void main(String[] args) { PathUsage usage = new PathUsage(); usage.usePath(); } }
<a name="Q5esy"></a>
## DirectoryStream
```java
public class ListFile {
public void listFiles() throws IOException {
Path path = Paths.get("");
try (DirectoryStream<Path> stream = Files.newDirectoryStream(path, "*.*")) {
for (Path entry : stream) {
//使用entry
System.out.println(entry);
}
}
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) throws IOException {
ListFile listFile = new ListFile();
listFile.listFiles();
}
}
执行结果
java_pid82782.hprof pom.xml README.md .gitignore .git java_pid82782.hprof.7d7x0.b.ij .ideaFiles
```java public class FilesUtils { public void manipulateFiles() throws IOException {
Path newFile = Files.createFile(Paths.get("hello1.txt").toAbsolutePath()); List<String> content = new ArrayList<String>(); content.add("Hello"); content.add("World"); Files.write(newFile, content, Charset.forName("UTF-8")); Files.size(newFile); byte[] bytes = Files.readAllBytes(newFile); ByteArrayOutputStream output = new ByteArrayOutputStream(); output.write(bytes); Files.copy(newFile, output); // Files.delete(newFile);}
/**
- @param args the command line arguments */ public static void main(String[] args) throws IOException { FilesUtils fu = new FilesUtils(); fu.manipulateFiles(); } }
<a name="Cq1mv"></a>
## WatchService
- **概述**
- java7中 提供了WatchService来监控系统中文件的变化。该监控是基于操作系统的文件系统监控器,可以监控系统是所有文件的变化,这种监控是无需遍历、无需比较的,是一种基于信号收发的监控,因此效率一定是最高的;现在Java对其进行了包装,可以直接在Java程序中使用OS的文件系统监控器了。
- **使用场景**
- **场景一:**比如系统中的配置文件,一般都是系统启动的时候只加载一次,如果想修改配置文件,还须重启系统。如果系统想热加载一般都会定时轮询对比配置文件是否修改过,如果修改过重新加载。
- **场景二:**监控磁盘中的文件变化,一般需要把磁盘中的所有文件全部加载一边,定期轮询一遍磁盘,跟上次的文件状态对比。如果文件、目录过多,每次遍历时间都很长,而且还不是实时监控。
- 而以上两种场景就比较适合使用 WatchService 进行文件监控。
```java
public class WatchAndCalculate {
public void calculate() throws IOException, InterruptedException {
WatchService service = FileSystems.getDefault().newWatchService();
// 使用 Path 来指定要监控的目录
Path path = Paths.get("target").toAbsolutePath();
// Path.register() 方法注册要监控指定目录的那些事件(创建、修改、删除)
path.register(service, StandardWatchEventKinds.ENTRY_CREATE);
while (true) {
WatchKey key = service.take();
for (WatchEvent<?> event : key.pollEvents()) {
Path createdPath = (Path) event.context();
createdPath = path.resolve(createdPath);
long size = Files.size(createdPath);
System.out.println(createdPath + " ==> " + size);
}
key.reset();
}
}
/**
* @param args the command line arguments
*/
public static void main(String[] args) throws Throwable {
WatchAndCalculate wc = new WatchAndCalculate();
wc.calculate();
}
}
StandardWatchEventKinds.ENTRY_CREATE //创建
StandardWatchEventKinds.ENTRY_MODIFY //修改
StandardWatchEventKinds.ENTRY_DELETE //删除
- 调用watchService.take(); 获取监控目录文件的变化的WatchKey。该方法是阻塞方法,如果没有文件修改,则一直阻塞
- 遍历所有的修改事件,并做相应处理
- 完成一次监控就需要重置监控器
-
jcmd utility
jcmd是为了替代jps出现了,包含了jps的大部分功能并新增了一些新的功能。
- jcmd -l 列出所有的Java虚拟机,针对每一个虚拟机可以使用help列出它们支持的命令
- cmd pid GC.heap_dump D:d.dump 导出堆信息
- jcmd pid GC.class_histogram查看系统中类的统计信息
- jcmd pid VM.system_properties查看系统属性内容
- jcmd pid Thread.print 打印线程栈
- jcmd pid VM.uptime 查看虚拟机启动时间
- jcmd pid PerfCounter.print 查看性能统计
-
fork/join框架
Java7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架
- 其使用分治思想,最终一致性
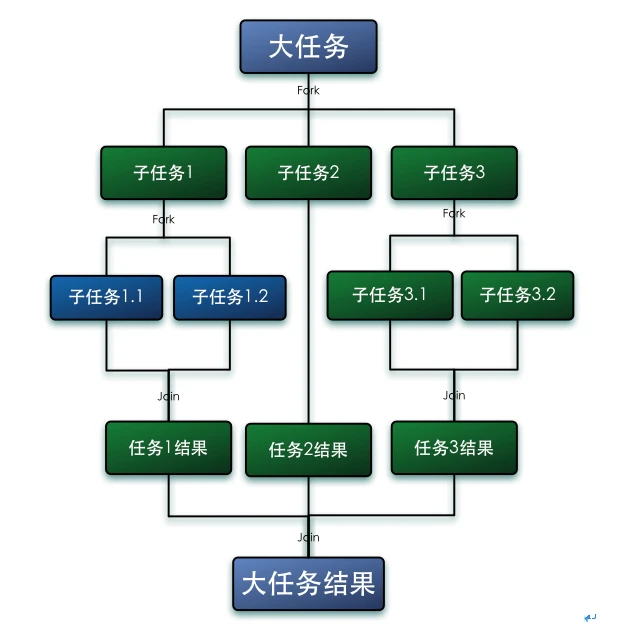
- 使用案例 - 有结果的任务
如果是有输出结果的,则必须继承 RecursiveTask ```java public class CalculateNumbersTask extends RecursiveTask
{ private int start; private int end;
public CalculateNumbersTask(int start, int end) {
this.start = start; this.end = end;}
/**
分治节点 */ private int separate = 5000;
@Override protected Long compute() { Long sum = 0L; boolean canCompute = (end - start) < separate; if (canCompute) {
for (int i = start; i <= end; i++) { sum += i; }} else {
int middle = (start + end) / 2; CalculateNumbersTask taskLeft = new CalculateNumbersTask(start, middle); CalculateNumbersTask taskRight = new CalculateNumbersTask(middle + 1, end); taskLeft.fork(); taskRight.fork(); Long joinLeft = taskLeft.join(); Long joinRight = taskRight.join(); sum = joinLeft + joinRight;} return sum; } }
```java
public class CalculateNumbersTaskTest {
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CalculateNumbersTask task = new CalculateNumbersTask(1222, 66666666);
ForkJoinTask<Long> submit = forkJoinPool.submit(task);
// 2222222210365080
// 如果抛出异常
if (task.isCompletedAbnormally()) {
System.out.println(task.getException());
}
System.out.println(submit.get());
}
}
- 使用案例 - 没有结果的任务
- 如果是有输出结果的,则必须继承 RecursiveAction
不推荐使用 没有结果的任务 去计算,因为要自行设置时间 ```java public class CalculateNumbersAction extends RecursiveAction { private int start; private int end; private Order order;
public CalculateNumbersAction(int start, int end, Order order) {
this.start = start; this.end = end; this.order = order;}
/**
分治节点 */ private int separate = 50000;
@Override protected void compute() { boolean canCompute = (end - start) < separate; if (canCompute) {
for (int i = start; i <= end; i++) { Long order = this.order.getOrder(); this.order.setOrder(order + i); }} else {
int middle = (start + end) / 2; CalculateNumbersAction taskLeft = new CalculateNumbersAction(start, middle, order); CalculateNumbersAction taskRight = new CalculateNumbersAction(middle + 1, end, order); taskLeft.fork(); taskRight.fork(); taskLeft.join(); taskRight.join();} } }
```java
@Data
public class Order {
private Long order;
}
public class CalculateNumbersActionTest {
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Order order = new Order();
order.setOrder(0L);
CalculateNumbersAction task = new CalculateNumbersAction(1, 100, order);
// 5050
forkJoinPool.submit(task);
forkJoinPool.awaitTermination(2, TimeUnit.SECONDS);
//任务完成之后关闭线程池
forkJoinPool.shutdown();
System.out.println(order);
}
}
-
Java Mission Control
在JDK7u40里头提供了Java Mission Control,这个是从JRockit虚拟机里头迁移过来的类似JVisualVm的东东
增强泛型推断
之前
Map<String, List<String>> map = new HashMap<String, List<String>>();之后
Map<String, List<String>> anagrams = new HashMap<>();Binary Literals支持
Java7前支持十进制(123)、八进制(0123)、十六进制(0X12AB)
Java7添加二进制表示(0B11110001、0b11110001)
Numeric Literals的下划线支持
如果一个数据很难查数,此时就可以使用数字的下划线支持,注意:只能放数字类型
long num = 1000_000_000; // 在编译时还需要把下划线去除在Strings in switch Statements
switch中的参数增加 String类型 ,但是底层原理还是比较的是String的HashCode值,而HashCode值就是int类型
public String generate(String name, String gender) { String title = ""; switch (gender) { case "男": title = name + " 先生"; break; case "女": title = name + " 女士"; break; default: title = name; } return title; }Java8
新特性列表
Lambda表达式
- 函数式接口
- 方法引用和构造函数调用
- Stream流
- 在JDK7中的新特性 fork/join 框架和Stream流搭配使用
- 接口中的默认方法和静态方法
- Optional 容器
- 新时间日期API
-
Lambda表达式
Lambda表达式本质上是一段匿名内部类,也是一段可以传递的代码
在没有出现Lambda表达式之前,匿名内部类好大一堆代码 ```java public class LambdaTest { public static void main(String[] args) {
Comparator<Integer> cmt = new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return Integer.compare(o1, o2); } }; TreeSet<Integer> set = new TreeSet<>(cmt); System.out.println("==================="); TreeSet<Integer> set2 = new TreeSet<>((o1, o2) -> Integer.compare(o1, o2));} }

- 注意:在使用Lambda表达式的时候,必须是函数式接口 - 也就是一个接口被@FunctionalInterface注解修饰,指仅含有一个抽象方法的接口
- 尽管下面的比较器Comparator接口都多个方法,但是其父类(此处有争议,因为接口不继承于Object,但是其中有个映射一样的东西,实际上内部含有Object类的方法 )
```java
@FunctionalInterface
public interface Comparator<T> {
// 核心比较方法
int compare(T o1, T o2);
// 非目标方法
boolean equals(Object obj);
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
// 省略其他方法
}
Lmabda表达式的语法总结: () -> (); | 前置 | 语法 | | —- | —- | | 无参数无返回值 | () -> System.out.println(“Hello WOrld”) | | 有一个参数无返回值 | (x) -> System.out.println(x) | | 有且只有一个参数无返回值 | x -> System.out.println(x) | | 有多个参数,有返回值,有多条lambda体语句 | (x,y) -> {System.out.println(“xxx”);return xxxx;}; | | 有多个参数,有返回值,只有一条lambda体语句 | (x,y) -> xxxx |
口诀:左右遇一省括号,左侧推断类型省
注:当一个接口中存在多个抽象方法时,如果使用lambda表达式,并不能智能匹配对应的抽象方法,因此引入了函数式接口的概念
函数式接口
函数式接口的提出是为了给Lambda提供更好的支持
常见的函数式接口
如果Lambda体中的内容有方法已经实现了,那么可以使用“方法引用”
- 也可以理解为方法引用时Lambda表达式的另外一种表现形式并且其语法比Lambda表达式更简单
方法引用
- 对象::实例方法名
- 类::静态方法名
类::实例方法名(Lambda参数列表中第一个参数是实例方法的调用者,第二个参数是实例方法的参数调用) ```java public class MethodInvokeTest { public static void main(String[] args) { test(); }
public static void test() { // lambda体中调用方法的参数列表与返回值类型, // 要与函数式接口中抽象方法的函数列表和返回值类型保持一致! // 若lambda参数列表中的第一个参数是实例方法的调用者, // 而第二个参数是实例方法的参数时,可以使用ClassName::method Consumer
con = (x) -> System.out.println(x); con.accept(100); // 方法引用 - 对象::实例方法 Consumer
con2 = System.out::println; con.accept(200); // 方法引用 - 类命::静态方法名 BiFunction
// 方法引用 BiFunction
- **构造器引用**
- ClassName::new
```java
public class MethodInvokeTest {
public static void main(String[] args) {
test2();
}
public static void test2() {
// 构造方法引用 类名::new
Supplier<User> sup = () -> new User();
System.out.println(sup.get());
Supplier<User> sup2 = User::new;
System.out.println(sup2.get());
// 构造方法引用 类名::new(带有一个参数)
Function<Integer, User> fun = (x) -> new User(x);
Function<Integer, User> fun2 = User::new;
System.out.println(fun2.apply(100));
}
static class User {
int age;
public User(int age) {
this.age = age;
}
public User() {
}
}
}
- 数组引用
Type[] :: new
public class MethodInvokeTest { public static void main(String[] args) { test3(); } public static void test3() { Function<Integer, String[]> fun = (x) -> new String[x]; Function<Integer, String[]> fun2 = String[]::new; String[] apply = fun2.apply(4); Arrays.stream(apply).forEach(System.out::println); } }Stream流
Stream 操作的三个步骤
- 创建Stream
- 中间操作(过滤、map)
- 终止操作
创建Stream
public class StreamTest { public static void test() { // Stream的创建 // 1.校验通过Collection系列集合提供的stream()或者paralleStream() ArrayList<String> list = new ArrayList<>(); Stream<String> stream = list.stream(); // 2.通过Arrays的静态方法Stream()获取数组流 String[] str = new String[10]; Stream<String> stream1 = Arrays.stream(str); // 3.通过Stream类中的静态方法of Stream<String> aa = Stream.of("aa", "bb", "cc"); // 4.创建无限流 // 迭代 Stream<Integer> iterate = Stream.iterate(1, (x) -> x + 2); // 生成 Stream.generate(() -> Math.random()); } }Stream的中间操作 ```java public class StreamTest2 { private static List
users = new ArrayList<>(); public static void test2() {
// 筛选 过滤 去重 users.stream() // .filter(e -> e.getAge() > 10)// .limit(4)// .skip(4)// // 需要流中的元素重写hashcode和equals方法 .distinct()// .forEach(System.out::println); // 生成新的流 通过map映射 users.stream()// .map((e) -> e.getAge())// .forEach(System.out::println); // 非自然排序 users.stream()// .sorted((e1, e2) -> e2.getAge() - e1.getAge())// .forEach(System.out::println);} }
@Data class Emp { private int age; }
- Stream的终止操作
```java
public class StreamTest {
private static List<Emp> users = new ArrayList<>();
public static void test3() {
/**
* 查找和匹配
* allMatch-检查是否匹配所有元素
* anyMatch-检查是否至少匹配一个元素
* noneMatch-检查是否没有匹配所有元素
* findFirst-返回第一个元素
* findAny-返回当前流中的任意元素
* count-返回流中元素的总个数
* max-返回流中最大值
* min-返回流中最小值
*/
// 检查是否匹配元素
boolean b = users.stream().allMatch((e) -> e.getAge() == 18);
System.out.println(b);
boolean b1 = users.stream().anyMatch((e) -> e.getAge() == 18);
System.out.println(b1);
boolean b2 = users.stream().noneMatch((e) -> e.getAge() == 18);
System.out.println(b2);
Optional<Emp> first = users.stream().findFirst();
System.out.println(first.get());
// 并行流
Optional<Emp> any = users.parallelStream().findAny();
System.out.println(any.get());
long count = users.stream().count();
System.out.println(count);
Optional<Emp> max = users.stream().max((e1, e2) -> e1.getAge() - e2.getAge());
System.out.println(max.get());
Optional<Emp> min = users.stream().min((e1, e2) -> e1.getAge() - e2.getAge());
System.out.println(min.get());
}
}
@Data
class Emp {
private int age;
}
- 还有功能比较强大的两个终止操作 reduce和collect ```java // reduce 操作 reduce:(T identity,BinaryOperator)/reduce(BinaryOperator)-可以将流中元素反复结合起来,得到一个值
public class StreamTest {
public static void main(String[] args) {
test4();
}
public static void test4() {
List<Integer> list = Arrays.asList(1, 2, 3, 5, 6, 7, 8, 9, 0);
Integer reduce = list.stream().reduce(0, (x, y) -> x + y);
System.out.println(reduce); // 41
}
}
- collect操作:Collect-将流转换为其他形式,接收一个Collection接口的实现,用于给Stream中元素做汇总的方法
```java
public class StreamTest {
private static List<Emp> users = new ArrayList<>();
public static void test5() {
// collect:收集操作
List<Integer> collect = users.stream().map(Emp::getAge)
.collect(Collectors.toList());
collect.stream().forEach(System.out::println);
}
}
并行流和串形流
Fork/Join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行 join 汇总。
- 关键字:递归分合、分而治之。
- 采用 “工作窃取”模式(work-stealing):当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能.。
要想使用Fork/Join,类必须继承 RecursiveAction(无返回值) 或者 RecursiveTask(有返回值) ```java public class ForkJoinDemo extends RecursiveTask
{ private Long start; private Long end;
// 临界值 private long temp = 1000L;
public ForkJoinDemo(long start, long end) {
this.start = start; this.end = end;}
// 计算方法 @Override protected Long compute() {
Long sum = 0L; if ((end - start) < temp) { for (Long i = start; i <= end; i++) { sum += i; } return sum; } else { // 分支合并计算 long middle = (start + end) / 2; ForkJoinDemo forkJoin1 = new ForkJoinDemo(start, middle); // 拆分任务 把任务压入线程队列 forkJoin1.fork(); ForkJoinDemo forkJoin2 = new ForkJoinDemo(middle + 1, end); // 拆分任务 把任务压入线程队列 forkJoin2.fork(); return forkJoin1.join() + forkJoin2.join(); }} }
class ForkJoinTest { public static void main(String[] args) { test1(); test2(); test3(); }
/**
* 普通程序员
* sum = 500000000500000000 时间:2991 ms
*/
public static void test1() {
long start = System.currentTimeMillis();
Long sum = 0L;
for (Long i = 1L; i <= 10_0000_0000; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println("sum = " + sum + " 时间:" + (end - start) + " ms");
}
/**
* 中级程序员
* sum = 500000000500000000 时间:1919 ms
*/
public static void test2() {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinDemo forkJoinDemo = new ForkJoinDemo(1, 10_0000_0000);
forkJoinPool.submit(forkJoinDemo);
Long sum = 0L;
try {
sum = forkJoinDemo.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("sum = " + sum + " 时间:" + (end - start) + " ms");
}
/**
* 高级程序员
* sum = 500000000500000000 时间:147 ms
*/
public static void test3() {
long start = System.currentTimeMillis();
// Stream 并行流
long sum = LongStream.rangeClosed(0L, 10_0000_0000L).parallel().reduce(0, Long::sum);
long end = System.currentTimeMillis();
System.out.println("sum = " + sum + " 时间:" + (end - start) + " ms");
}
}
<a name="eRxYx"></a>
## 接口中的默认方法和静态方法
- 在JDK8之前,接口中的方法不可以有方法体,但是在JDK8之后,可以有,但是非静态的方法必须使用default修饰
- 也可以有静态方法
```java
public interface Animal {
void run();
void eat();
/**
* 可以定义带有方法体的方法 但是如果不是静态方法,必须使用default修饰
*/
default void hello() {
System.out.println("Animal.hello");
}
/**
* 也可定义含有方法体的静态方法 默认就是public
*/
static void test() {
System.out.println("Animal.test");
}
}
Optional 容器
Optional.of(T t); // 创建一个Optional实例
Optional.empty(); // 创建一个空的Optional实例
Optional.ofNullable(T t); // 若T不为null,创建一个Optional实例,否则创建一个空实例
isPresent(); // 判断是够包含值
orElse(T t); //如果调用对象包含值,返回该值,否则返回T
orElseGet(Supplier s); // 如果调用对象包含值,返回该值,否则返回s中获取的值
ap(Function f): // 如果有值对其处理,并返回处理后的Optional,否则返回Optional.empty();
flatMap(Function mapper);// 与map类似。返回值是Optional
总结:Optional.of(null) 会直接报NPE
public class OptionalTest {
static List<String> list = new ArrayList<>();
static {
list.add("LDL");
list.add("icanci");
}
public static void main(String[] args) {
Optional<String> first = list.stream().filter(s -> s.equals("icanci")).findFirst();
// Optional#isPresent 是否有数据 也就是不为null
System.out.println(first.isPresent());
if (first.isPresent()) {
System.out.println(first.get());
}
}
}
新时间日期API
-
HashMap底层数据结构优化
在JDK8之前,HashMap底层是数组+链表
- 在JDK8之后,HashMap底层是数组+链表+红黑树
-
JRE精简
JRE精简的好处
更小的Java环境需要更少的计算资源。
- 一个较小的运行时环境可以更好的优化性能和启动时间。
- 消除未使用的代码从安全的角度总是好的。
-
概念
紧凑的JRE分3种,分别是compact1、compact2、compact3,他们的关系是compact1<compact2<compact3,他们包含的API如下图所示


移除Permgen
PermGen space简单介绍
- PermGen space的全称是Permanent Generation space,是指内存的永久保存区域,说说为什么会内存益出: 这一部分用于存放Class和Meta的信息,Class在被 Load的时候被放入PermGen space区域,它和和存放Instance的Heap区域不同,所以如果你的APP会LOAD很多CLASS的话,就很可能出现PermGen space错误。这种错误常见在web服务器对JSP进行pre compile的时候。
JVM 种类有很多,比如 Oralce-Sun Hotspot, Oralce JRockit, IBM J9, Taobao JVM(淘宝好样的!)等等。当然武林盟主是Hotspot了,这个毫无争议。需要注意的是,PermGen space是Oracle-Sun Hotspot才有,JRockit以及J9是没有这个区域
元空间(MetaSpace)一种新的内存空间诞生
JDK8 HotSpot JVM 将移除永久区,使用本地内存来存储类元数据信息并称之为: 元空间(Metaspace);这与Oracle JRockit 和IBM JVM’s很相似,如下图所示

- 有关于Java虚拟机的学习,会在后续JVM专栏学习
Mark*
- 关于Stream流、Optional、Lambda表达式、函数式编程,会在High-Java的Stream专栏学习
华丽的分割线,如果没有用到新的版本,那么下面的新版本的新特性,可作为了解。
Java9
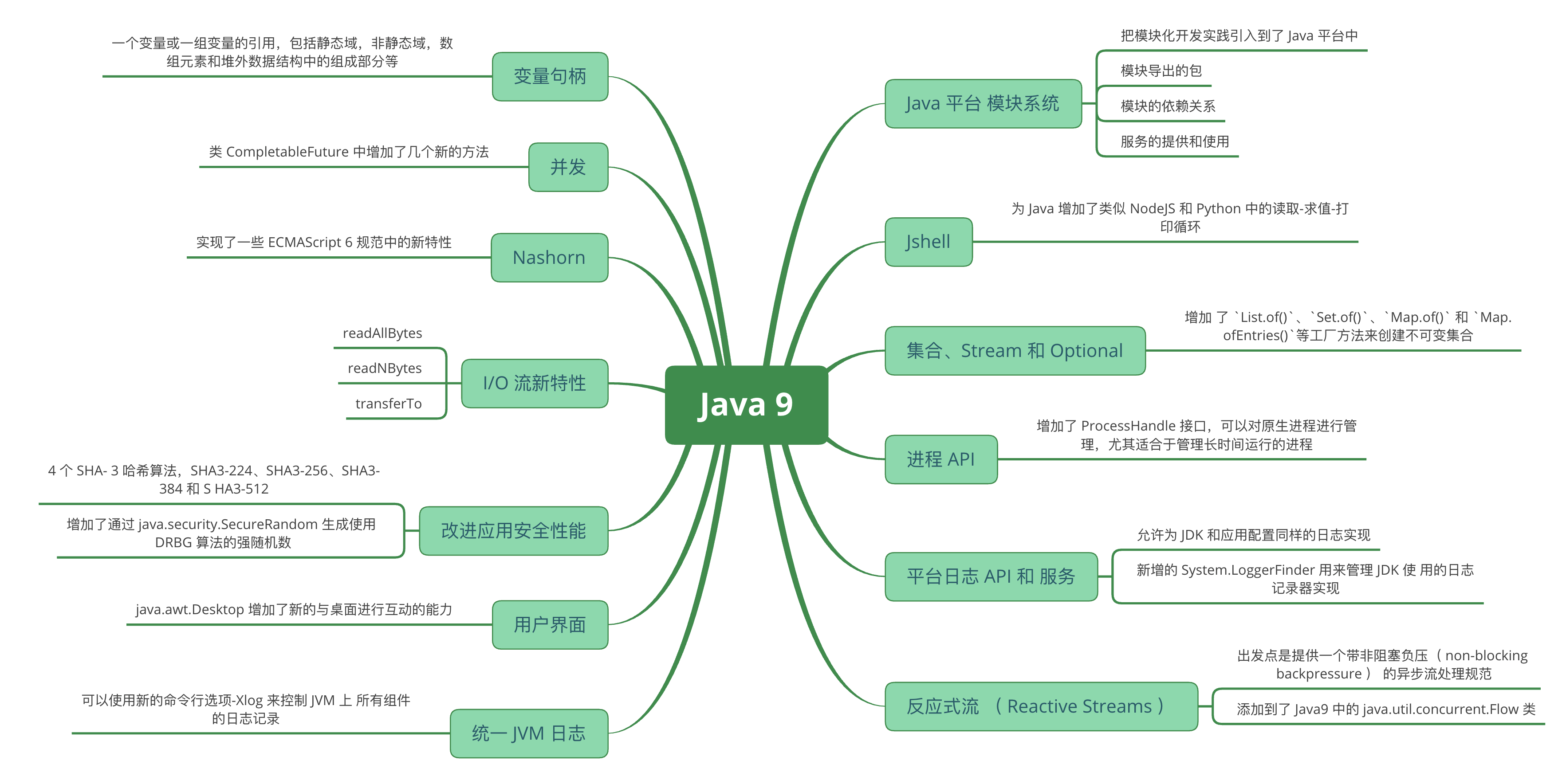
新特性列表
- 模块系统JMS(重磅)
- G1成为默认垃圾回收器
- Jshell
- 集合、Stream和Optional
- 进程API
- 平台日志和服务
- 反应式流(Reactive Stream)
- 变量句柄
- 改进方法句柄(Method Handle)
- 并发
- Nashorn
- I/O 流新特性
- 改进应用安全性能
- 用户界面
- 统一JVM日志
- 其他改动方面
- Java 平台模块系统,也就是 Project Jigsaw,把模块化开发实践引入到了 Java 平台中。在引入了模块系统之后,JDK 被重新组织成 94 个模块。Java 应用可以通过新增的 jlink 工具,创建出只包含所依赖的 JDK 模块的自定义运行时镜像。这样可以极大的减少 Java 运行时环境的大小。这对于目前流行的不可变基础设施的实践来说,镜像的大小的减少可以节省很多存储空间和带宽资源 。
- 模块化开发的实践在软件开发领域并不是一个新的概念。Java 开发社区已经使用这样的模块化实践有相当长的一段时间。主流的构建工具,包括 Apache Maven 和 Gradle 都支持把一个大的项目划分成若干个子项目。子项目之间通过不同的依赖关系组织在一起。每个子项目在构建之后都会产生对应的 JAR 文件。 在 Java9 中 ,已有的这些项目可以很容易的升级转换为 Java 9 模块 ,并保持原有的组织结构不变。
- Java 9 模块的重要特征是在其工件(artifact)的根目录中包含了一个描述模块的 module-info.class 文 件。 工件的格式可以是传统的 JAR 文件或是 Java 9 新增的 JMOD 文件。这个文件由根目录中的源代码文件 module-info.java 编译而来。该模块声明文件可以描述模块的不同特征。模块声明文件中可以包含的内容如下:
- 模块导出的包:使用 exports 可以声明模块对其他模块所导出的包。包中的 public 和 protected 类型,以及这些类型的 public 和 protected 成员可以被其他模块所访问。没有声明为导出的包相当于模块中的私有成员,不能被其他模块使用。
- 模块的依赖关系:使用 requires 可以声明模块对其他模块的依赖关系。使用 requires transitive 可 以把一个模块依赖声明为传递的。传递的模块依赖可以被依赖当前模块的其他模块所读取。 如果一个模块所导出的类型的型构中包含了来自它所依赖的模块的类型,那么对该模块的依赖应该声明为传递的。
- 服务的提供和使用:如果一个模块中包含了可以被 ServiceLocator 发现的服务接口的实现 ,需要使用 provides with 语句来声明具体的实现类 ;如果一个模块需要使用服务接口,可以使用 uses 语句来声明。
- 如下代码中给出了一个模块声明文件的示例。在该声明文件中,模块 com.mycompany.sample 导出了 Java 包 com.mycompany.sample。该模块依赖于模块 com.mycompany.common 。该模块也提供了服务接口 com.mycompany.common.DemoService 的实现类 com.mycompany.sample.DemoServiceImpl
```java
module com.mycompany.sample {
exports com.mycompany.sample;
requires com.mycompany.common;
provides com.mycompany.common.DemoService with
}com.mycompany.sample.DemoServiceImpl;
- 模块系统中增加了模块路径的概念。模块系统在解析模块时,会从模块路径中进行查找。为了保持与之前 Java 版本的兼容性,CLASSPATH 依然被保留。所有的类型在运行时都属于某个特定的模块。对于从 CLASSPATH 中加载的类型,它们属于加载它们的类加载器对应的未命名模块。可以通过 Class 的 getModule()方法来获取到表示其所在模块的 Module 对象。
- 在 JVM 启动时,会从应用的根模块开始,根据依赖关系递归的进行解析,直到得到一个表示依赖关系的图。如果解析过程中出现找不到模块的情况,或是在模块路径的同一个地方找到了名称相同的模块,模块解析过程会终止,JVM 也会退出。Java 也提供了相应的 API 与模块系统进行交互
<a name="f96b1"></a>
## Jshell
- jshell 是 Java 9 新增的一个实用工具。jshell 为 Java 增加了类似 NodeJS 和 Python 中的读取-求值-打印循环( Read-Evaluation-Print Loop ) 。 在 jshell 中 可以直接 输入表达式并查看其执行结果。当需要测试一个方法的运行效果,或是快速的对表达式进行求值时,jshell 都非常实用。只需要通过 jshell 命令启动 jshell,然后直接输入表达式即可。每个表达式的结果会被自动保存下来 ,以数字编号作为引用,类似 $1 和$2 这样的名称 。可以在后续的表达式中引用之前语句的运行结果。 在 jshell 中 ,除了表达式之外,还可以创建 Java 类和方法。jshell 也有基本的代码完成功能。
- 在 如下代码 中,我们直接创建了一个方法 add
```java
jshell> int add(int x, int y) {
...> return x + y;
...> }
| created method add(int,int)
- 接着就可以在 jshell 中直接使用这个方法,如下代码 所示 ```java jshell> add(1, 2) $19 ==> 3
<a name="xsfYa"></a>
## 集合、Stream 和 Optional
- 在集合上,Java 9 增加 了 List.of()、Set.of()、Map.of() 和 Map.ofEntries()等工厂方法来创建不可变集合,如下所示
```java
List.of();
List.of("Hello", "World");
List.of(1, 2, 3);
Set.of();
Set.of("Hello", "World");
Set.of(1, 2, 3);
Map.of();
Map.of("Hello", 1, "World", 2);
- Stream 中增加了新的方法 ofNullable、dropWhile、takeWhile 和 iterate。在 如下代码 中,流中包含了从 1 到 5 的 元素。断言检查元素是否为奇数。第一个元素 1 被删除,结果流中包含 4 个元素
```java
@Test
public void testDropWhile() throws Exception {
final long count = Stream.of(1, 2, 3, 4, 5)
assertEquals(4, count); }.dropWhile(i -> i % 2 != 0) .count();
- Collectors 中增加了新的方法 filtering 和 flatMapping。在 如下代码 中,对于输入的 String 流 ,先通过 flatMapping 把 String 映射成 Integer 流 ,再把所有的 Integer 收集到一个集合中
```java
@Test
public void testFlatMapping() throws Exception {
final Set<Integer> result = Stream.of("a", "ab", "abc")
.collect(Collectors.flatMapping(v -> v.chars().boxed(),
Collectors.toSet()));
assertEquals(3, result.size());
}
- Optional 类中新增了 ifPresentOrElse、or 和 stream 等方法。在 如下代码 中,Optiona l 流中包含 3 个 元素,其中只有 2 个有值。在使用 flatMap 之后,结果流中包含了 2 个值
```java
@Test
public void testStream() throws Exception {
final long count = Stream.of(
).flatMap(Optional::stream)Optional.of(1), Optional.empty(), Optional.of(2)
assertEquals(2, count); }.count();
<a name="sy0lc"></a>
## 进程API
- Java 9 增加了 ProcessHandle 接口,可以对原生进程进行管理,尤其适合于管理长时间运行的进程。在使用 ProcessBuilder 来启动一个进程之后,可以通过 Process.toHandle()方法来得到一个 ProcessHandl e 对象的实例。通过 ProcessHandle 可以获取到由 ProcessHandle.Info 表 示的进程的基本信息,如命令行参数、可执行文件路径和启动时间等。ProcessHandle 的 onExit()方法返回一个 CompletableFuture对象,可以在进程结束时执行自定义的动作。 如下代码中给出了进程 API 的使用示例
```java
final ProcessBuilder processBuilder = new ProcessBuilder("top")
.inheritIO();
final ProcessHandle processHandle = processBuilder.start().toHandle();
processHandle.onExit().whenCompleteAsync((handle, throwable) -> {
if (throwable == null) {
System.out.println(handle.pid());
} else {
throwable.printStackTrace();
}
});
平台日志 API 和 服务
- Java 9 允许为 JDK 和应用配置同样的日志实现。新增的 System.LoggerFinder 用来管理 JDK 使 用的日志记录器实现。JVM 在运行时只有一个系统范围的 LoggerFinder 实例。LoggerFinder 通 过服务查找机制来加载日志记录器实现。默认情况下,JDK 使用 java.logging 模块中的 java.util.logging 实现。通过 LoggerFinder 的 getLogger()方法就可以获取到表示日志记录器的 System.Logger 实现。应用同样可以使用 System.Logger 来记录日志。这样就保证了 JDK 和应用使用同样的日志实现。我们也可以通过添加自己的 System.LoggerFinder 实现来让 JDK 和应用使用 SLF4J 等其他日志记录框架。 代码清单 9 中给出了平台日志 API 的使用示例。
```java
public class Main {
private static final System.Logger LOGGER = System.getLogger(“Main”);
public static void main(final String[] args) {
} }LOGGER.log(Level.INFO, "Run!");
<a name="Af552"></a>
## 反应式流(Reactive Streams)
- 反应式编程的思想最近得到了广泛的流行。 在 Java 平台上有流行的反应式 库 RxJava 和 R eactor。反应式流规范的出发点是提供一个带非阻塞负压( non-blocking backpressure ) 的异步流处理规范。反应式流规范的核心接口已经添加到了 Java9 中的 java.util.concurrent.Flow 类中。
- Flow 中包含了 Flow.Publisher、Flow.Subscriber、Flow.Subscription 和 F low.Processor 等 4 个核心接口。Java 9 还提供了 SubmissionPublisher 作为 Flow.Publisher 的一个实现。RxJava 2 和 Reactor 都可以很方便的 与 Flow 类的核心接口进行互操作
<a name="qTZAE"></a>
## 变量句柄
- 变量句柄是一个变量或一组变量的引用,包括静态域,非静态域,数组元素和堆外数据结构中的组成部分等。变量句柄的含义类似于已有的方法句柄。变量句柄由 Java 类 java.lang.invoke.VarHandle 来表示。可以使用类 java.lang.invoke.MethodHandles.Lookup 中的静态工厂方法来创建 VarHandle 对 象。通过变量句柄,可以在变量上进行各种操作。这些操作称为访问模式。不同的访问模式尤其在内存排序上的不同语义。目前一共有 31 种访问模式,而每种访问模式都 在 VarHandle 中 有对应的方法。这些方法可以对变量进行读取、写入、原子更新、数值原子更新和比特位原子操作等。VarHandle 还 可以用来访问数组中的单个元素,以及把 byte[]数组 和 ByteBuffer 当成是不同原始类型的数组来访问。
- 在如下代码中,我们创建了访问 HandleTarget 类中的域 count 的变量句柄,并在其上进行读取操作
```java
public class HandleTarget {
public int count = 1;
}
public class VarHandleTest {
private HandleTarget handleTarget = new HandleTarget();
private VarHandle varHandle;
@Before
public void setUp() throws Exception {
this.handleTarget = new HandleTarget();
this.varHandle = MethodHandles
.lookup()
.findVarHandle(HandleTarget.class, "count", int.class);
}
@Test
public void testGet() throws Exception {
assertEquals(1, this.varHandle.get(this.handleTarget));
assertEquals(1, this.varHandle.getVolatile(this.handleTarget));
assertEquals(1, this.varHandle.getOpaque(this.handleTarget));
assertEquals(1, this.varHandle.getAcquire(this.handleTarget));
}
}
改进方法句柄(Method Handle)
- 类 java.lang.invoke.MethodHandles 增加了更多的静态方法来创建不同类型的方法句柄
- arrayConstructor:创建指定类型的数组。
- arrayLength:获取指定类型的数组的大小。
- varHandleInvoker 和 varHandleExactInvoker:调用 VarHandle 中的访问模式方法。
- zero:返回一个类型的默认值。
- empty:返 回 MethodType 的返回值类型的默认值。
- loop、countedLoop、iteratedLoop、whileLoop 和 doWhileLoop:创建不同类型的循环,包括 for 循环、while 循环 和 do-while 循环。
- tryFinally:把对方法句柄的调用封装在 try-finally 语句中
- 在 如下代码 中,我们使用 iteratedLoop 来创建一个遍历 String 类型迭代器的方法句柄,并计算所有字符串的长度的总和
```java
public class IteratedLoopTest {
static int body(final int sum, final String value) {
} @Test public void testIteratedLoop() throws Throwable {return sum + value.length();
} }final MethodHandle iterator = MethodHandles.constant( Iterator.class, List.of("a", "bc", "def").iterator()); final MethodHandle init = MethodHandles.zero(int.class); final MethodHandle body = MethodHandles .lookup() .findStatic( IteratedLoopTest.class, "body", MethodType.methodType( int.class, int.class, String.class)); final MethodHandle iteratedLoop = MethodHandles .iteratedLoop(iterator, init, body); assertEquals(6, iteratedLoop.invoke());
<a name="H6Wxn"></a>
## 并发
- 在并发方面,类 CompletableFuture 中增加了几个新的方法。completeAsync 使用一个异步任务来获取结果并完成该 CompletableFuture。orTimeout 在 CompletableFuture 没有在给定的超时时间之前完成,使用 TimeoutException 异常来完成 CompletableFuture。completeOnTimeout 与 orTimeout 类似,只不过它在超时时使用给定的值来完成 CompletableFuture。新的 Thread.onSpinWait 方法在当前线程需要使用忙循环来等待时,可以提高等待的效率。
<a name="fKbLU"></a>
## Nashorn
- Nashorn 是 Java 8 中引入的新的 JavaScript 引擎。Java 9 中的 Nashorn 已经实现了一些 ECMAScript 6 规范中的新特性,包括模板字符串、二进制和八进制字面量、迭代器 和 for..of 循环和箭头函数等。Nashorn 还提供了 API 把 ECMAScript 源代码解析成抽象语法树( Abstract Syntax Tree,AST ) ,可以用来对 ECMAScript 源代码进行分析
<a name="zuNvC"></a>
## I/O 流新特性
- 类 java.io.InputStream 中增加了新的方法来读取和复制 InputStream 中包含的数据。
- readAllBytes:读取 InputStream 中的所有剩余字节。
- readNBytes: 从 InputStream 中读取指定数量的字节到数组中。
- transferTo:读取 InputStream 中的全部字节并写入到指定的 OutputStream 中
```java
public class TestInputStream {
private InputStream inputStream;
private static final String CONTENT = "Hello World";
@Before
public void setUp() throws Exception {
this.inputStream =
TestInputStream.class.getResourceAsStream("/input.txt");
}
@Test
public void testReadAllBytes() throws Exception {
final String content = new String(this.inputStream.readAllBytes());
assertEquals(CONTENT, content);
}
@Test
public void testReadNBytes() throws Exception {
final byte[] data = new byte[5];
this.inputStream.readNBytes(data, 0, 5);
assertEquals("Hello", new String(data));
}
@Test
public void testTransferTo() throws Exception {
final ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
this.inputStream.transferTo(outputStream);
assertEquals(CONTENT, outputStream.toString());
}
}
ObjectInputFilter 可以对 ObjectInputStream 中 包含的内容进行检查,来确保其中包含的数据是合法的。可以使用 ObjectInputStream 的方法 setObjectInputFilter 来设置。ObjectInputFilter 在 进行检查时,可以检查如对象图的最大深度、对象引用的最大数量、输入流中的最大字节数和数组的最大长度等限制,也可以对包含的类的名称进行限制
改进应用安全性能
Java 9 新增了 4 个 SHA- 3 哈希算法,SHA3-224、SHA3-256、SHA3-384 和 S HA3-512。另外也增加了通过 java.security.SecureRandom 生成使用 DRBG 算法的强随机数。如下代码中给出了 SHA-3 哈希算法的使用示例 ```java import org.apache.commons.codec.binary.Hex; public class SHA3 { public static void main(final String[] args) throws NoSuchAlgorithmException {
final MessageDigest instance = MessageDigest.getInstance("SHA3-224"); final byte[] digest = instance.digest("".getBytes()); System.out.println(Hex.encodeHexString(digest));} }
<a name="fHnog"></a>
## 用户界面
类 java.awt.Desktop 增加了新的与桌面进行互动的能力。可以使用 addAppEventListener 方法来添加不同应用事件的监听器,包括应用变为前台应用、应用隐藏或显示、屏幕和系统进入休眠与唤醒、以及 用户会话的开始和终止等。还可以在显示关于窗口和配置窗口时,添加自定义的逻辑。在用户要求退出应用时,可以通过自定义处理器来接受或拒绝退出请求。在 AWT 图像支持方面,可以在应用中使用多分辨率图像
<a name="m7oFR"></a>
## 统一JVM日志
- Java 9 中 ,JVM 有了统一的日志记录系统,可以使用新的命令行选项-Xlog 来控制 JVM 上 所有组件的日志记录。该日志记录系统可以设置输出的日志消息的标签、级别、修饰符和输出目标等。Java 9 移除了在 Java 8 中 被废弃的垃圾回收器配置组合,同时 把 G1 设为默认的垃圾回收器实现。另外,CMS 垃圾回收器已经被声明为废弃。Java 9 也增加了很多可以通过 jcmd 调用的诊断命令
<a name="PBLim"></a>
## 其他改动方面
- 在 Java 语言本身,Java 9 允许在接口中使用私有方法。 在 try-with-resources 语句中可以使用 effectively-final 变量。 类 java.lang.StackWalker 可 以对线程的堆栈进行遍历,并且支持过滤和延迟访问。Java 9 把对 Unicode 的支持升级到了 8.0。ResourceBundle 加载属性文件的默认编码从 ISO-8859-1 改成了 UTF-8,不再需要使用 native2ascii 命 令来对属性文件进行额外处理。注解@Deprecated 也得到了增强,增加了 since 和 forRemoval 两 个属性,可以分别指定一个程序元素被废弃的版本,以及是否会在今后的版本中被删除。
- 在如下代码中,buildMessage 是接口 SayHi 中的私有方法,在默认方法 sayHi 中被使用
```java
public interface SayHi {
private String buildMessage() {
return "Hello";
}
void sayHi(final String message);
default void sayHi() {
sayHi(buildMessage());
}
}
Java10
新特性列表
- 局部变量类型推断
- 整合JDK代码仓库
- 统一的垃圾回收接口
- 并行全垃圾回收器G1
- 应用程序类数据共享
- 线程-局部管控
- 移除Native-Header自动生成工具
- 额外的Unicode语言标签扩展
- 备用存储装备中的堆分配
- 基于Java的实验性JIT编译器
- 根证书验证
-
局部变量类型推断
局部变量类型推断是 Java 10 中最值得开发人员注意的新特性,这是 Java 语言开发人员为了简化 Java 应用程序的编写而进行的又一重要改进。
- 这一新功能将为 Java 增加一些新语法,允许开发人员省略通常不必要的局部变量类型初始化声明。新的语法将减少 Java 代码的冗长度,同时保持对静态类型安全性的承诺。局部变量类型推断主要是向 Java 语法中引入在其他语言(比如 C#、JavaScript)中很常见的保留类型名称 var 。但需要特别注意的是: var 不是一个关键字,而是一个保留字。只要编译器可以推断此种类型,开发人员不再需要专门声明一个局部变量的类型,也就是可以随意定义变量而不必指定变量的类型。这种改进对于链式表达式来说,也会很方便。以下是一个简单的例子:
清单 1. 局部变量类型推断示例
var list = new ArrayList<String>(); // ArrayList<String> var stream = list.stream(); // Stream<String>看着是不是有点 JS 的感觉?有没有感觉越来越像 JS 了?虽然变量类型的推断在 Java 中不是一个崭新的概念,但在局部变量中确是很大的一个改进。说到变量类型推断,从 Java 5 中引进泛型,到 Java 7 的 <> 操作符允许不绑定类型而初始化 List,再到 Java 8 中的 Lambda 表达式,再到现在 Java 10 中引入的局部变量类型推断,Java 类型推断正大刀阔斧地向前进步、发展。
- 而上面这段例子,在以前版本的 Java 语法中初始化列表的写法为
```java
List
list = new ArrayList (); Stream stream = getStream();
- **清单 2. Java 类型初始化示例**
```java
List<String> list = new ArrayList<String>();
Stream<String> stream = getStream();
- 清单 3. Java 7 之后版本类型初始化示例
```java
List
list = new LinkedList<>(); Stream stream = getStream();
- 但这种 var 变量类型推断的使用也有局限性,仅局限于具有初始化器的局部变量、增强型 for 循环中的索引变量以及在传统 for 循环中声明的局部变量,而不能用于推断方法的参数类型,不能用于构造函数参数类型推断,不能用于推断方法返回类型,也不能用于字段类型推断,同时还不能用于捕获表达式(或任何其他类型的变量声明)。
- 不过对于开发者而言,变量类型显式声明会提供更加全面的程序语言信息,对于理解和维护代码有很大的帮助。Java 10 中新引入的局部变量类型推断能够帮助我们快速编写更加简洁的代码,但是局部变量类型推断的保留字 var 的使用势必会引起变量类型可视化缺失,并不是任何时候使用 var 都能容易、清晰的分辨出变量的类型。一旦 var 被广泛运用,开发者在没有 IDE 的支持下阅读代码,势必会对理解程序的执行流程带来一定的困难。所以还是建议尽量显式定义变量类型,在保持代码简洁的同时,也需要兼顾程序的易读性、可维护性
<a name="FzSwv"></a>
## 整合 JDK 代码仓库
- 为了简化开发流程,Java 10 中会将多个代码库合并到一个代码仓库中。
- 在已发布的 Java 版本中,JDK 的整套代码根据不同功能已被分别存储在多个 Mercurial 存储库,这八个 Mercurial 存储库分别是:root、corba、hotspot、jaxp、jaxws、jdk、langtools、nashorn。
- 虽然以上八个存储库之间相互独立以保持各组件代码清晰分离,但同时管理这些存储库存在许多缺点,并且无法进行相关联源代码的管理操作。其中最重要的一点是,涉及多个存储库的变更集无法进行原子提交 (atomic commit)。例如,如果一个 bug 修复时需要对独立存储两个不同代码库的代码进行更改,那么必须创建两个提交:每个存储库中各一个。这种不连续性很容易降低项目和源代码管理工具的可跟踪性和加大复杂性。特别是,不可能跨越相互依赖的变更集的存储库执行原子提交这种多次跨仓库的变化是常见现象。
- 为了解决这个问题,JDK 10 中将所有现有存储库合并到一个 Mercurial 存储库中。这种合并的一个次生效应是,单一的 Mercurial 存储库比现有的八个存储库要更容易地被镜像(作为一个 Git 存储库),并且使得跨越相互依赖的变更集的存储库运行原子提交成为可能,从而简化开发和管理过程。虽然在整合过程中,外部开发人员有一些阻力,但是 JDK 开发团队已经使这一更改成为 JDK 10 的一部分
<a name="RTLQt"></a>
## 统一的垃圾回收接口
- 在当前的 Java 结构中,组成垃圾回收器(GC)实现的组件分散在代码库的各个部分。尽管这些惯例对于使用 GC 计划的 JDK 开发者来说比较熟悉,但对新的开发人员来说,对于在哪里查找特定 GC 的源代码,或者实现一个新的垃圾收集器常常会感到困惑。更重要的是,随着 Java modules 的出现,我们希望在构建过程中排除不需要的 GC,但是当前 GC 接口的横向结构会给排除、定位问题带来困难。
- 为解决此问题,需要整合并清理 GC 接口,以便更容易地实现新的 GC,并更好地维护现有的 GC。Java 10 中,hotspot/gc 代码实现方面,引入一个干净的 GC 接口,改进不同 GC 源代码的隔离性,多个 GC 之间共享的实现细节代码应该存在于辅助类中。这种方式提供了足够的灵活性来实现全新 GC 接口,同时允许以混合搭配方式重复使用现有代码,并且能够保持代码更加干净、整洁,便于排查收集器问题。
<a name="WEZSn"></a>
## 并行全垃圾回收器 G1
- 大家如果接触过 Java 性能调优工作,应该会知道,调优的最终目标是通过参数设置来达到快速、低延时的内存垃圾回收以提高应用吞吐量,尽可能的避免因内存回收不及时而触发的完整 GC(Full GC 会带来应用出现卡顿)。
- G1 垃圾回收器是 Java 9 中 Hotspot 的默认垃圾回收器,是以一种低延时的垃圾回收器来设计的,旨在避免进行 Full GC,但是当并发收集无法快速回收内存时,会触发垃圾回收器回退进行 Full GC。之前 Java 版本中的 G1 垃圾回收器执行 GC 时采用的是基于单线程标记扫描压缩算法(mark-sweep-compact)。为了最大限度地减少 Full GC 造成的应用停顿的影响,Java 10 中将为 G1 引入多线程并行 GC,同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少了 Full GC 的发生,以带来更好的性能提升、更大的吞吐量。
- Java 10 中将采用并行化 mark-sweep-compact 算法,并使用与年轻代回收和混合回收相同数量的线程。具体并行 GC 线程数量可以通过: -XX:ParallelGCThreads 参数来调节,但这也会影响用于年轻代和混合收集的工作线程数。
<a name="WxOWz"></a>
## 应用程序类数据共享
- 在 Java 5 中就已经引入了类数据共享机制 (Class Data Sharing,简称 CDS),允许将一组类预处理为共享归档文件,以便在运行时能够进行内存映射以减少 Java 程序的启动时间,当多个 Java 虚拟机(JVM)共享相同的归档文件时,还可以减少动态内存的占用量,同时减少多个虚拟机在同一个物理或虚拟的机器上运行时的资源占用。简单来说,Java 安装程序会把 rt.jar 中的核心类提前转化成内部表示,转储到一个共享存档(shared archive)中。多个 Java 进程(或者说 JVM 实例)可以共享这部分数据。为改善启动和占用空间,Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置在共享存档中。
- CDS 特性在原来的 bootstrap 类基础之上,扩展加入了应用类的 CDS (Application Class-Data Sharing) 支持。
- 其**原理**为:在启动时记录加载类的过程,写入到文本文件中,再次启动时直接读取此启动文本并加载。设想如果应用环境没有大的变化,启动速度就会得到提升。
- 可以想像为类似于操作系统的休眠过程,合上电脑时把当前应用环境写入磁盘,再次使用时就可以快速恢复环境。
- 对大型企业应用程序的内存使用情况的分析表明,此类应用程序通常会将数以万计的类加载到应用程序类加载器中,如果能够将 AppCDS 应用于这些应用,将为每个 JVM 进程节省数十乃至数百兆字节的内存。另外对于云平台上的微服务分析表明,许多服务器在启动时会加载数千个应用程序类,AppCDS 可以让这些服务快速启动并改善整个系统响应时间。
<a name="MSBaq"></a>
## 线程-局部管控
- 在已有的 Java 版本中,JVM 线程只能全部启用或者停止,没法做到对单独某个线程的操作。为了能够对单独的某个线程进行操作,Java 10 中线程管控引入 JVM 安全点的概念,将允许在不运行全局 JVM 安全点的情况下实现线程回调,由线程本身或者 JVM 线程来执行,同时保持线程处于阻塞状态,这种方式使得停止单个线程变成可能,而不是只能启用或停止所有线程。通过这种方式显著地提高了现有 JVM 功能的性能开销,并且改变了到达 JVM 全局安全点的现有时间语义。
- 增加的参数为:-XX:ThreadLocalHandshakes (默认为开启),将允许用户在支持的平台上选择安全点
<a name="Yydjq"></a>
## 移除 Native-Header 自动生成工具
- 自 Java 9 以来便开始了一些对 JDK 的调整,用户每次调用 javah 工具时会被警告该工具在未来的版本中将会执行的删除操作。当编译 JNI 代码时,已不再需要单独的 Native-Header 工具来生成头文件,因为这可以通过 Java 8(JDK-7150368)中添加的 javac 来完成。在未来的某一时刻,JNI 将会被 Panama 项目的结果取代,但是何时发生还没有具体时间表。
<a name="UxnN9"></a>
## 额外的 Unicode 语言标签扩展
- 自 Java 7 开始支持 BCP 47 语言标记以来, JDK 中便增加了与日历和数字相关的 Unicode 区域设置扩展,在 Java 9 中,新增支持 ca 和 nu 两种语言标签扩展。而在 Java 10 中将继续增加 Unicode 语言标签扩展,具体为:增强 java.util.Locale 类及其相关的 API,以更方便的获得所需要的语言地域环境信息。同时在这次升级中还带来了如下扩展支持:
- 表 1.Unicode 扩展表
| 编码 | 注释 |
| --- | --- |
| cu | 货币类型 |
| fw | 一周的第一天 |
| rg | 区域覆盖 |
| tz | 时区 |
- 如 Java 10 加入的一个方法:
- 清单 4. Unicode 语言标签扩展示例
```java
java.time.format.DateTimeFormatter::localizedBy
通过这个方法,可以采用某种数字样式,区域定义或者时区来获得时间信息所需的语言地域本地环境信息。
备用存储装置上的堆分配
硬件技术在持续进化,现在可以使用与传统 DRAM 具有相同接口和类似性能特点的非易失性 RAM。Java 10 中将使得 JVM 能够使用适用于不同类型的存储机制的堆,在可选内存设备上进行堆内存分配。
- 一些操作系统中已经通过文件系统提供了使用非 DRAM 内存的方法。例如:NTFS DAX 模式和 ext4 DAX。这些文件系统中的内存映射文件可绕过页面缓存并提供虚拟内存与设备物理内存的相互映射。与 DRAM 相比,NV-DIMM 可能具有更高的访问延迟,低优先级进程可以为堆使用 NV-DIMM 内存,允许高优先级进程使用更多 DRAM。
要在这样的备用设备上进行堆分配,可以使用堆分配参数 -XX:AllocateHeapAt =
,这个参数将指向文件系统的文件并使用内存映射来达到在备用存储设备上进行堆分配的预期结果。 基于 Java 的 实验性 JIT 编译器
Java 10 中开启了基于 Java 的 JIT 编译器 Graal,并将其用作 Linux/x64 平台上的实验性 JIT 编译器开始进行测试和调试工作,另外 Graal 将使用 Java 9 中引入的 JVM 编译器接口(JVMCI)。
- Graal 是一个以 Java 为主要编程语言、面向 Java bytecode 的编译器。与用 C++实现的 C1 及 C2 相比,它的模块化更加明显,也更加容易维护。Graal 既可以作为动态编译器,在运行时编译热点方法;亦可以作为静态编译器,实现 AOT 编译。在 Java 10 中,Graal 作为试验性 JIT 编译器一同发布(JEP 317)。将 Graal 编译器研究项目引入到 Java 中,或许能够为 JVM 性能与当前 C++ 所写版本匹敌(或有幸超越)提供基础。
- Java 10 中默认情况下 HotSpot 仍使用的是 C2 编译器,要启用 Graal 作为 JIT 编译器,请在 Java 命令行上使用以下参数:
清单 5. 启用 Graal 为 JIT 编译器示例
-XX:+ UnlockExperimentalVMOptions -XX:+ UseJVMCICompiler根证书认证
自 Java 9 起在 keytool 中加入参数 -cacerts ,可以查看当前 JDK 管理的根证书。而 Java 9 中 cacerts 目录为空,这样就会给开发者带来很多不便。从 Java 10 开始,将会在 JDK 中提供一套默认的 CA 根证书。
作为 JDK 一部分的 cacerts 密钥库旨在包含一组能够用于在各种安全协议的证书链中建立信任的根证书。但是,JDK 源代码中的 cacerts 密钥库至目前为止一直是空的。因此,在 JDK 构建中,默认情况下,关键安全组件(如 TLS)是不起作用的。要解决此问题,用户必须使用一组根证书配置和 cacerts 密钥库下的 CA 根证书。
基于时间的版本发布模式
虽然 JEP 223 中引入的版本字符串方案较以往有了显著的改进。但是,该方案并不适合以后严格按照六个月的节奏来发布 Java 新版本的这种情况。
- 按照 JEP 223 的语义中,每个基于 JDK 构建或使用组件的开发者(包括 JDK 的发布者)都必须提前敲定版本号,然后切换过去。开发人员则必须在代码中修改检查版本号的相关代码,这对所有参与者来说都很尴尬和混乱。
- Java 10 中将重新编写之前 JDK 版本中引入的版本号方案,将使用基于时间模型定义的版本号格式来定义新版本。保留与 JEP 223 版本字符串方案的兼容性,同时也允许除当前模型以外的基于时间的发布模型。使开发人员或终端用户能够轻松找出版本的发布时间,以便开发人员能够判断是否将其升级到具有最新安全修补程序或可能的附加功能的新版本。
- Oracle Java 平台组的首席架构师 Mark Reinhold 在博客上介绍了有关 Java 未来版本的一些想法(你能接受 Java 9 的下一个版本是 Java 18.3 吗?)。他提到,Java 计划按照时间来发布,每半年一个版本,而不是像之前那样按照重要特性来确定大版本,如果某个大的特性因故延期,这个版本可能一拖再拖。
- 当时,Mark 也提出来一种基于时间命名版本号的机制,比如下一个将于 2018 年 3 月发布的版本,就是 18.3,再下一个版本是 18.9,以后版本依此类推。
不过经过讨论,考虑和之前版本号的兼容等问题,最终选择的命名机制是
$FEATURE.$INTERIM.$UPDATE.$PATCH$FEATURE:每次版本发布加 1,不考虑具体的版本内容。2018 年 3 月的版本是 JDK 10,9 月的版本是 JDK 11,依此类推。 $INTERIM:中间版本号,在大版本中间发布的,包含问题修复和增强的版本,不会引入非兼容性修改
Java11
新特性列表
基于嵌套的访问控制
- 基于HTTP Client升级
- Epsilon:低开销垃圾回收器
- 简化单个源代码文件的方法
- 用于Lambda参数的局部变量语法
- 低开销的Heap Profiling
- 支持 TLS 1.3 协议
- ZGC:可伸缩低延迟垃圾收集器
- 飞行记录器
-
基于嵌套的访问控制
与 Java 语言中现有的嵌套类型概念一致, 嵌套访问控制是一种控制上下文访问的策略,允许逻辑上属于同一代码实体,但被编译之后分为多个分散的 class 文件的类,无需编译器额外的创建可扩展的桥接访问方法,即可访问彼此的私有成员,并且这种改进是在 Java 字节码级别的。
- 在 Java 11 之前的版本中,编译之后的 class 文件中通过 InnerClasses 和 Enclosing Method 两种属性来帮助编译器确认源码的嵌套关系,每一个嵌套的类会编译到自己所在的 class 文件中,不同类的文件通过上面介绍的两种属性的来相互连接。这两种属性对于编译器确定相互之间的嵌套关系已经足够了,但是并不适用于访问控制。这里大家可以写一段包含内部类的代码,并将其编译成 class 文件,然后通过 javap 命令行来分析,碍于篇幅,这里就不展开讨论了。
Java 11 中引入了两个新的属性:一个叫做 NestMembers 的属性,用于标识其它已知的静态 nest 成员;另外一个是每个 nest 成员都包含的 NestHost 属性,用于标识出它的 nest 宿主类
标准 HTTP Client 升级
Java 11 对 Java 9 中引入并在 Java 10 中进行了更新的 Http Client API 进行了标准化,在前两个版本中进行孵化的同时,Http Client 几乎被完全重写,并且现在完全支持异步非阻塞。
- 新版 Java 中,Http Client 的包名由 jdk.incubator.http 改为 java.net.http,该 API 通过 CompleteableFutures 提供非阻塞请求和响应语义,可以联合使用以触发相应的动作,并且 RX Flo w 的概念也在 Java 11 中得到了实现。现在,在用户层请求发布者和响应发布者与底层套接字之间追踪数据流更容易了。这降低了复杂性,并最大程度上提高了 HTTP/1 和 HTTP/2 之间的重用的可能性。
- Java 11 中的新 Http Client API,提供了对 HTTP/2 等业界前沿标准的支持,同时也向下兼容 HTTP/1.1,精简而又友好的 API 接口,与主流开源 API(如:Apache HttpClient、Jetty、OkHttp 等)类似甚至拥有更高的性能。与此同时它是 Java 在 Reactive-Stream 方面的第一个生产实践,其中广泛使用了 Java Flow API,终于让 Java 标准 HTTP 类库在扩展能力等方面,满足了现代互联网的需求,是一个难得的现代 Http/2 Client API 标准的实现,Java 工程师终于可以摆脱老旧的 HttpURLConnection 了。下面模拟 Http GET 请求并打印返回内容: ```java HttpClient client = HttpClient.newHttpClient(); HttpRequest request = HttpRequest.newBuilder() .uri(URI.create(“http://openjdk.java.net/“)) .build(); client.sendAsync(request, BodyHandlers.ofString()) .thenApply(HttpResponse::body) .thenAccept(System.out::println) .join();
<a name="xqcqo"></a>
## Epsilon:低开销垃圾回收器
- Epsilon 垃圾回收器的目标是开发一个控制内存分配,但是不执行任何实际的垃圾回收工作。它提供一个完全消极的 GC 实现,分配有限的内存资源,最大限度的降低内存占用和内存吞吐延迟时间。
- Java 版本中已经包含了一系列的高度可配置化的 GC 实现。各种不同的垃圾回收器可以面对各种情况。但是有些时候使用一种独特的实现,而不是将其堆积在其他 GC 实现上将会是事情变得更加简单。
- **下面是 no-op GC 的几个使用场景:**
- **性能测试**:什么都不执行的 GC 非常适合用于 GC 的差异性分析。no-op (无操作)GC 可以用于过滤掉 GC 诱发的性能损耗,比如 GC 线程的调度,GC 屏障的消耗,GC 周期的不合适触发,内存位置变化等。此外有些延迟者不是由于 GC 引起的,比如 scheduling hiccups, compiler transition hiccups,所以去除 GC 引发的延迟有助于统计这些延迟。
- **内存压力测试**:在测试 Java 代码时,确定分配内存的阈值有助于设置内存压力常量值。这时 no-op 就很有用,它可以简单地接受一个分配的内存分配上限,当内存超限时就失败。例如:测试需要分配小于 1G 的内存,就使用-Xmx1g 参数来配置 no-op GC,然后当内存耗尽的时候就直接 crash。
- **VM 接口测试**:以 VM 开发视角,有一个简单的 GC 实现,有助于理解 VM-GC 的最小接口实现。它也用于证明 VM-GC 接口的健全性。
- **极度短暂 job 任务**:一个短声明周期的 job 任务可能会依赖快速退出来释放资源,这个时候接收 GC 周期来清理 heap 其实是在浪费时间,因为 heap 会在退出时清理。并且 GC 周期可能会占用一会时间,因为它依赖 heap 上的数据量。 延迟改进:对那些极端延迟敏感的应用,开发者十分清楚内存占用,或者是几乎没有垃圾回收的应用,此时耗时较长的 GC 周期将会是一件坏事。
- **吞吐改进**:即便对那些无需内存分配的工作,选择一个 GC 意味着选择了一系列的 GC 屏障,所有的 OpenJDK GC 都是分代的,所以他们至少会有一个写屏障。避免这些屏障可以带来一点点的吞吐量提升。
- Epsilon 垃圾回收器和其他 OpenJDK 的垃圾回收器一样,可以通过参数 -XX:+UseEpsilonGC 开启。
- Epsilon 线性分配单个连续内存块。可复用现存 VM 代码中的 TLAB 部分的分配功能。非 TLAB 分配也是同一段代码,因为在此方案中,分配 TLAB 和分配大对象只有一点点的不同。Epsilon 用到的 barrier 是空的(或者说是无操作的)。因为该 GC
- 执行任何的 GC 周期,不用关系对象图,对象标记,对象复制等。引进一种新的 barrier-set 实现可能是该 GC 对 JVM 最大的变化
<a name="HJRLI"></a>
## 简化启动单个源代码文件的方法
- java 11 版本中最令人兴奋的功能之一是增强 Java 启动器,使之能够运行单一文件的 Java 源代码。此功能允许使用 Java 解释器直接执行 Java 源代码。源代码在内存中编译,然后由解释器执行。唯一的约束在于所有相关的类必须定义在同一个 Java 文件中。
- 此功能对于开始学习 Java 并希望尝试简单程序的人特别有用,并且能与 jshell 一起使用,将成为任何初学者学习语言的一个很好的工具集。不仅初学者会受益,专业人员还可以利用这些工具来探索新的语言更改或尝试未知的 API。
- 如今单文件程序在编写小实用程序时很常见,特别是脚本语言领域。从中开发者可以省去用 Java 编译程序等不必要工作,以及减少新手的入门障碍。在基于 Java 10 的程序实现中可以通过三种方式启动:
- 作为 * .class 文件
- 作为 * .jar 文件中的主类
- 作为模块中的主类
- 而在最新的 Java 11 中新增了一个启动方式,即可以在源代码中声明类,例如:如果名为 HelloWorld.java 的文件包含一个名为 hello.World 的类,那么该命令
```java
$ java HelloWorld.java
等价于
$ javac HelloWorld.java $ java -cp . hello.World用于 Lambda 参数的局部变量语法
在 Lambda 表达式中使用局部变量类型推断是 Java 11 引入的唯一与语言相关的特性,这一节,我们将探索这一新特性。
- 从 Java 10 开始,便引入了局部变量类型推断这一关键特性。类型推断允许使用关键字 var 作为局部变量的类型而不是实际类型,编译器根据分配给变量的值推断出类型。这一改进简化了代码编写、节省了开发者的工作时间,因为不再需要显式声明局部变量的类型,而是可以使用关键字 var,且不会使源代码过于复杂。
- 可以使用关键字 var 声明局部变量,如下所示 ```java var s = “Hello Java 11”; System.out.println(s);
- **但是在 Java 10 中,还有下面几个限制:**
- 只能用于局部变量上
- 声明时必须初始化
- 不能用作方法参数
- 不能在 Lambda 表达式中使用
- Java 11 与 Java 10 的不同之处在于允许开发者在 Lambda 表达式中使用 var 进行参数声明。乍一看,这一举措似乎有点多余,因为在写代码过程中可以省略 Lambda 参数的类型,并通过类型推断确定它们。但是,添加上类型定义同时使用 @Nonnull 和 @Nullable 等类型注释还是很有用的,既能保持与局部变量的一致写法,也不丢失代码简洁。
- Lambda 表达式使用隐式类型定义,它形参的所有类型全部靠推断出来的。隐式类型 Lambda 表达式如下
```java
(x, y) -> x.process(y)
Java 10 为局部变量提供隐式定义写法如下
var x = new Foo(); for (var x : xs) { ... } try (var x = ...) { ... } catch ...为了 Lambda 类型表达式中正式参数定义的语法与局部变量定义语法的不一致,且为了保持与其他局部变量用法上的一致性,希望能够使用关键字 var 隐式定义 Lambda 表达式的形参
(var x, var y) -> x.process(y)于是在 Java 11 中将局部变量和 Lambda 表达式的用法进行了统一,并且可以将注释应用于局部变量和 Lambda 表达式 ```java @Nonnull var x = new Foo(); (@Nonnull var x, @Nullable var y) -> x.process(y)
<a name="muucj"></a>
## 低开销的 Heap Profiling
- Java 11 中提供一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并且能够通过 JVMTI 访问堆信息。
- 引入这个低开销内存分析工具是为了达到如下目的:
- 足够低的开销,可以默认且一直开启
- 能通过定义好的程序接口访问
- 能够对所有堆分配区域进行采样
- 能给出正在和未被使用的 Java 对象信息
- 对用户来说,了解它们堆里的内存分布是非常重要的,特别是遇到生产环境中出现的高 CPU、高内存占用率的情况。目前有一些已经开源的工具,允许用户分析应用程序中的堆使用情况,比如:Java Flight Recorder、jmap、YourKit 以及 VisualVM tools.。但是这些工具都有一个明显的不足之处:无法得到对象的分配位置,headp dump 以及 heap histogram 中都没有包含对象分配的具体信息,但是这些信息对于调试内存问题至关重要,因为它能够告诉开发人员他们的代码中发生的高内存分配的确切位置,并根据实际源码来分析具体问题,这也是 Java 11 中引入这种低开销堆分配采样方法的原因。
<a name="ma9cC"></a>
## 支持 TLS 1.3 协议
- Java 11 中包含了传输层安全性(TLS)1.3 规范(RFC 8446)的实现,替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能,例如 OCSP 装订扩展(RFC 6066,RFC 6961),以及会话散列和扩展主密钥扩展(RFC 7627),在安全性和性能方面也做了很多提升。
- 新版本中包含了 Java 安全套接字扩展(JSSE)提供 SSL,TLS 和 DTLS 协议的框架和 Java 实现。目前,JSSE API 和 JDK 实现支持 SSL 3.0,TLS 1.0,TLS 1.1,TLS 1.2,DTLS 1.0 和 DTLS 1.2。
- 同时 Java 11 版本中实现的 TLS 1.3,重新定义了以下新标准算法名称:
- TLS 协议版本名称:TLSv1.3
- SSLContext 算法名称:TLSv1.3
- TLS 1.3 的 TLS 密码套件名称:TLS_AES_128_GCM_SHA256,TLS_AES_256_GCM_SHA384
- 用于 X509KeyManager 的 keyType:RSASSA-PSS
- 用于 X509TrustManager 的 authType:RSASSA-PSS
- 还为 TLS 1.3 添加了一个新的安全属性 jdk.tls.keyLimits。当处理了特定算法的指定数据量时,触发握手后,密钥和 IV 更新以导出新密钥。还添加了一个新的系统属性 jdk.tls.server.protocols,用于在 SunJSSE 提供程序的服务器端配置默认启用的协议套件。
- 之前版本中使用的 KRB5 密码套件实现已从 Java 11 中删除,因为该算法已不再安全。同时注意,TLS 1.3 与以前的版本不直接兼容。
- 升级到 TLS 1.3 之前,需要考虑如下几个兼容性问题:
- TLS 1.3 使用半关闭策略,而 TLS 1.2 以及之前版本使用双工关闭策略,对于依赖于双工关闭策略的应用程序,升级到 TLS 1.3 时可能存在兼容性问题。
- TLS 1.3 使用预定义的签名算法进行证书身份验证,但实际场景中应用程序可能会使用不被支持的签名算法。
- TLS 1.3 再支持 DSA 签名算法,如果在服务器端配置为仅使用 DSA 证书,则无法升级到 TLS 1.3。
- TLS 1.3 支持的加密套件与 TLS 1.2 和早期版本不同,若应用程序硬编码了加密算法单元,则在升级的过程中需要修改相应代码才能升级使用 TLS 1.3。
- TLS 1.3 版本的 session 用行为及秘钥更新行为与 1.2 及之前的版本不同,若应用依赖于 TLS 协议的握手过程细节,则需要注意。
<a name="YbvRV"></a>
## ZGC:可伸缩低延迟垃圾收集器
- GC 即 Z Garbage Collector(垃圾收集器或垃圾回收器),这应该是 Java 11 中最为瞩目的特性,没有之一。ZGC 是一个可伸缩的、低延迟的垃圾收集器,主要为了满足如下目标进行设计:
- GC 停顿时间不超过 10ms
- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
- 方便在此基础上引入新的 GC 特性和利用 colord
- 针以及 Load barriers 优化奠定基础
- 当前只支持 Linux/x64 位平台 停顿时间在 10ms 以下,10ms 其实是一个很保守的数据,即便是 10ms 这个数据,也是 GC 调优几乎达不到的极值。根据 SPECjbb 2015 的基准测试,128G 的大堆下最大停顿时间才 1.68ms,远低于 10ms,和 G1 算法相比,改进非常明显
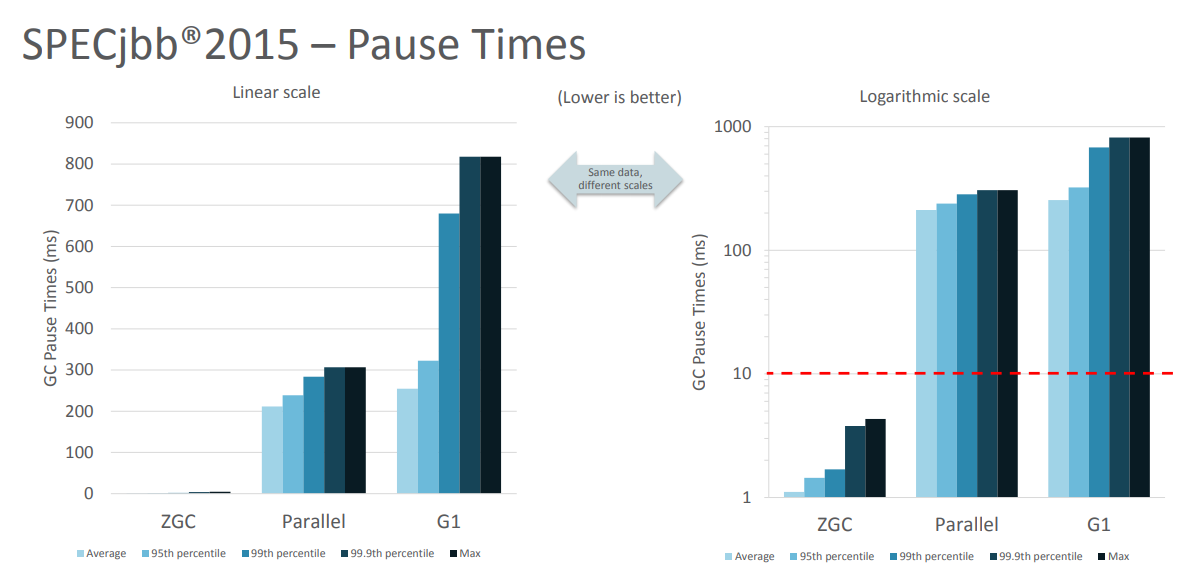
- 本图片引用自: The Z Garbage Collector – An Introduction
- 不过目前 ZGC 还处于实验阶段,目前只在 Linux/x64 上可用,如果有足够的需求,将来可能会增加对其他平台的支持。同时作为实验性功能的 ZGC 将不会出现在 JDK 构建中,除非在编译时使用 configure 参数:--with-jvm-features=zgc 显式启用。
- 在实验阶段,编译完成之后,已经迫不及待的想试试 ZGC,需要配置以下 JVM 参数,才能使用 ZGC,具体启动 ZGC 参数如下
```java
-XX:+ UnlockExperimentalVMOptions -XX:+ UseZGC -Xmx10g
其中参数: -Xmx 是 ZGC 收集器中最重要的调优选项,大大解决了程序员在 JVM 参数调优上的困扰。ZGC 是一个并发收集器,必须要设置一个最大堆的大小,应用需要多大的堆,主要有下面几个考量:
飞行记录器之前是商业版 JDK 的一项分析工具,但在 Java 11 中,其代码被包含到公开代码库中,这样所有人都能使用该功能了。
- Java 语言中的飞行记录器类似飞机上的黑盒子,是一种低开销的事件信息收集框架,主要用于对应用程序和 JVM 进行故障检查、分析。飞行记录器记录的主要数据源于应用程序、JVM 和 OS,这些事件信息保存在单独的事件记录文件中,故障发生后,能够从事件记录文件中提取出有用信息对故障进行分析。
启用飞行记录器参数如下
-XX:StartFlightRecording也可以使用 bin/jcmd 工具启动和配置飞行记录器
$ jcmd <pid> JFR.start $ jcmd <pid> JFR.dump filename=recording.jfr $ jcmd <pid> JFR.stopJFR 使用测试 ```java public class FlightRecorderTest extends Event { @Label(“Hello World”) @Description(“Helps the programmer getting started”) static class HelloWorld extends Event {
@Label("Message") String message;}
public static void main(String[] args) {
HelloWorld event = new HelloWorld(); event.message = "hello, world!"; event.commit();} }
- 在运行时加上如下参数
```java
java -XX:StartFlightRecording=duration=1s, filename=recording.jfr
- 面读取上一步中生成的 JFR 文件:recording.jfr
```java
public void readRecordFile() throws IOException {
final Path path = Paths.get(“D:\ java \recording.jfr”);
final List
recordedEvents = RecordingFile.readAllEvents(path); for (RecordedEvent event : recordedEvents) {
} }System.out.println(event.getStartTime() + "," + event.getValue("message"));
<a name="AmYci"></a>
## 动态类文件常量
- 为了使 JVM 对动态语言更具吸引力,Java 的第七个版本已将 invokedynamic 引入其指令集。
- 不过 Java 开发人员通常不会注意到此功能,因为它隐藏在 Java 字节代码中。通过使用 invokedynamic,可以延迟方法调用的绑定,直到第一次调用。例如,Java 语言使用该技术来实现 Lambda 表达式,这些表达式仅在首次使用时才显示出来。这样做,invokedynamic 已经演变成一种必不可少的语言功能。
- Java 11 引入了类似的机制,扩展了 Java 文件格式,以支持新的常量池:CONSTANT_Dynamic,它在初始化的时候,像 invokedynamic 指令生成代理方法一样,委托给 bootstrap 方法进行初始化创建,对上层软件没有很大的影响,降低开发新形式的可实现类文件约束带来的成本和干扰
<a name="aAB54"></a>
# Java13
<a name="FvdKu"></a>
## 新特性列表
- 动态应用程序类-数据共享
- 增强ZGC是否未使用内存
- Socket API 重构
- Switch 表达式扩展(预览功能)
- 文本块(预览功能)
<a name="D4jQz"></a>
## 动态应用程序类-数据共享
- 在 Java 10 中,为了改善应用启动时间和内存空间占用,通过使用 APP CDS,加大了 CDS 的使用范围,允许自定义的类加载器也可以加载自定义类给多个 JVM 共享使用,具体介绍可以参考 Java 10 新特性介绍一文详细介绍,在此就不再继续展开。
- Java 13 中对 Java 10 中引入的 应用程序类数据共享进行了进一步的简化、改进和扩展,即:允许在 Java 应用程序执行结束时动态进行类归档,具体能够被归档的类包括:所有已被加载,但不属于默认基层 CDS 的应用程序类和引用类库中的类。通过这种改进,可以提高应用程序类-数据使用上的简易性,减少在使用类-数据存档中需要为应用程序创建类加载列表的必要,简化使用类-数据共享的步骤,以便更简单、便捷地使用 CDS 存档。
- 在 Java 中,如果要执行一个类,首先需要将类编译成对应的字节码文件,以下是 JVM 装载、执行等需要的一系列准备步骤:假设给定一个类名,JVM 将在磁盘上查找到该类对应的字节码文件,并将其进行加载,验证字节码文件,准备,解析,初始化,根据其内部数据结构加载到内存中。当然,这一连串的操作都需要一些时间,这在 JVM 启动并且需要加载至少几百个甚至是数千个类时,加载时间就尤其明显。
- Java 10 中的 App CDS 主要是为了将不变的类数据,进行一次创建,然后存储到归档中,以便在应用重启之后可以对其进行内存映射而直接使用,同时也可以在运行的 JVM 实例之间共享使用。但是在 Java 10 中使用 App CDS 需要进行如下操作:
- 创建需要进行类归档的类列表
- 创建归档
- 使用归档方式启动
- 在使用归档文件启动时,JVM 将归档文件映射到其对应的内存中,其中包含所需的大多数类,而
- 需要使用多么复杂的类加载机制。甚至可以在并发运行的 JVM 实例之间共享内存区域,通过这种方式可以释放需要在每个 JVM 实例中创建相同信息时浪费的内存,从而节省了内存空间。
- 在 Java 12 中,默认开启了对 JDK 自带 JAR 包类的存档,如果想关闭对自带类库的存档,可以在启动参数中加上
```java
-Xshare:off
- 而在 Java 13 中,可以不用提供归档类列表,而是通过更简洁的方式来创建包含应用程序类的归档。具体可以使用参数 -XX:ArchiveClassesAtExit 来控制应用程序在退出时生成存档,也可以使用 -XX:SharedArchiveFile 来使用动态存档功能,详细使用见如下示例
- 创建存档文件示例 ```java $ java -XX:ArchiveClassesAtExit=helloworld.jsa -cp helloworld.jar Hello
- 使用存档文件示例
```java
$ java -XX:SharedArchiveFile=hello.jsa -cp helloworld.jar Hello
增强 ZGC 释放未使用内存
- ZGC 是 Java 11 中引入的最为瞩目的垃圾回收特性,是一种可伸缩、低延迟的垃圾收集器,不过在 Java 11 中是实验性的引入,主要用来改善 GC 停顿时间,并支持几百 MB 至几个 TB 级别大小的堆,并且应用吞吐能力下降不会超过 15%,目前只支持 Linux/x64 位平台的这样一种新型垃圾收集器。
- 通过在实际中的使用,发现 ZGC 收集器中并没有像 Hotspot 中的 G1 和 Shenandoah 垃圾收集器一样,能够主动将未使用的内存释放给操作系统的功能。对于大多数应用程序来说,CPU 和内存都属于有限的紧缺资源,特别是现在使用的云上或者虚拟化环境中。如果应用程序中的内存长期处于空闲状态,并且还不能释放给操作系统,这样会导致其他需要内存的应用无法分配到需要的内存,而这边应用分配的内存还处于空闲状态,处于”忙的太忙,闲的太闲”的非公平状态,并且也容易导致基于虚拟化的环境中,因为这些实际并未使用的资源而多付费的情况。由此可见,将未使用内存释放给系统主内存是一项非常有用且亟需的功能。
- ZGC 堆由一组称为 ZPages 的堆区域组成。在 GC 周期中清空 ZPages 区域时,它们将被释放并返回到页面缓存 ZPageCache 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,并按照大小进行组织。在 Java 13 中,ZGC 将向操作系统返回被标识为长时间未使用的页面,这样它们将可以被其他进程重用。同时释放这些未使用的内存给操作系统不会导致堆大小缩小到参数设置的最小大小以下,如果将最小和最大堆大小设置为相同的值,则不会释放任何内存给操作系统。
- Java 13 中对 ZGC 的改进,主要体现在下面几点:
- 释放未使用内存给操作系统
- 支持最大堆大小为 16TB
- 添加参数:-XX:SoftMaxHeapSize 来软限制堆大小
- 这里提到的是软限制堆大小,是指 GC 应努力是堆大小不要超过指定大小,但是如果实际需要,也还是允许 GC 将堆大小增加到超过 SoftMaxHeapSize 指定值。主要用在下面几种情况:当希望降低堆占用,同时保持应对堆空间临时增加的能力,亦或想保留充足内存空间,以能够应对内存分配,而不会因为内存分配意外增加而陷入分配停滞状态。不应将 SoftMaxHeapSize 设置为大于最大堆大小(-Xmx 的值,如果未在命令行上设置,则此标志应默认为最大堆大小。
- Java 13 中,ZGC 内存释放功能,默认情况下是开启的,不过可以使用参数:-XX:-ZUncommit 显式关闭,同时如果将最小堆大小 (-Xms) 配置为等于最大堆大小 (-Xmx),则将隐式禁用此功能。
还可以使用参数:-XX:ZUncommitDelay =
(默认值为 300 秒)来配置延迟释放,此延迟时间可以指定释放多长时间之前未使用的内存 Socket API 重构
Java 中的 Socket API 已经存在了二十多年了,尽管这么多年来,一直在维护和更新中,但是在实际使用中遇到一些局限性,并且不容易维护和调试,所以要对其进行大修大改,才能跟得上现代技术的发展,毕竟二十多年来,技术都发生了深刻的变化。Java 13 为 Socket API 带来了新的底层实现方法,并且在 Java 13 中是默认使用新的 Socket 实现,使其易于发现并在排除问题同时增加可维护性。
- Java Socket API(java.net.ServerSocket 和 java.net.Socket)包含允许监听控制服务器和发送数据的套接字对象。可以使用 ServerSocket 来监听连接请求的端口,一旦连接成功就返回一个 Socket 对象,可以使用该对象读取发送的数据和进行数据写回操作,而这些类的繁重工作都是依赖于 SocketImpl 的内部实现,服务器的发送和接收两端都基于 SOCKS 进行实现的。
- 在 Java 13 之前,通过使用 PlainSocketImpl 作为 SocketImpl 的具体实现。
- Java 13 中的新底层实现,引入 NioSocketImpl 的实现用以替换 SocketImpl 的 PlainSocketImpl 实现,此实现与 NIO(新 I/O)实现共享相同的内部基础结构,并且与现有的缓冲区高速缓存机制集成在一起,因此不需要使用线程堆栈。除了这些更改之外,还有其他一些更便利的更改,如使用 java.lang.ref.Cleaner 机制来关闭套接字(如果 SocketImpl 实现在尚未关闭的套接字上被进行了垃圾收集),以及在轮询时套接字处于非阻塞模式时处理超时操作等方面。
为了最小化在重新实现已使用二十多年的方法时出现问题的风险,在引入新实现方法的同时,之前版本的实现还未被移除,可以通过使用下列系统属性以重新使用原实现方法
-Djdk.net.usePlainSocketImpl = true另外需要注意的是,SocketImpl 是一种传统的 SPI 机制,同时也是一个抽象类,并未指定具体的实现,所以,新的实现方式尝试模拟未指定的行为,以达到与原有实现兼容的目的。但是,在使用新实现时,有些基本情况可能会失败,使用上述系统属性可以纠正遇到的问题,下面两个除外。
- 老版本中,PlainSocketImpl 中的 getInputStream() 和 getOutputStream() 方法返回的 InputStream 和 OutputStream 分别来自于其对应的扩展类型 FileInputStream 和 FileOutputStream,而这个在新版实现中则没有。
- 使用自定义或其它平台的 SocketImpl 的服务器套接字无法接受使用其他(自定义或其它平台)类型 SocketImpl 返回 Sockets 的连接。
通过这些更改,Java Socket API 将更易于维护,更好地维护将使套接字代码的可靠性得到改善。同时 NIO 实现也可以在基础层面完成,从而保持 Socket 和 ServerSocket 类层面上的不变
Switch 表达式扩展(预览功能)
在 Java 12 中引入了 Switch 表达式作为预览特性,而在 Java 13 中对 Switch 表达式做了增强改进,在块中引入了 yield 语句来返回值,而不是使用 break。这意味着,Switch 表达式(返回值)应该使用 yield,而 Switch 语句(不返回值)应该使用 break,而在此之前,想要在 Switch 中返回内容,还是比较麻烦的,只不过目前还处于预览状态。
- 在 Java 13 之后,Switch 表达式中就多了一个关键字用于跳出 Switch 块的关键字 yield,主要用于返回一个值,它和 return 的区别在于:return 会直接跳出当前循环或者方法,而 yield 只会跳出当前 Switch块,同时在使用 yield 时,需要有 default 条件。
- 在 Java 12 之前,传统 Switch 语句写法为
```java
private static String getText(int number) {
String result = “”;
switch (number) {
}; return result; }case 1, 2: result = "one or two"; break; case 3: result = "three"; break; case 4, 5, 6: result = "four or five or six"; break; default: result = "unknown"; break;
- 在 Java 12 之后,关于 Switch 表达式的写法改进为如下
```java
private static String getText(int number) {
String result = switch (number) {
case 1, 2 -> "one or two";
case 3 -> "three";
case 4, 5, 6 -> "four or five or six";
default -> "unknown";
};
return result;
}
- 而在 Java 13 中,value break 语句不再被编译,而是用 yield 来进行值返回,上述写法被改为如下写法
```java
private static String getText(int number) {
return switch (number) {
}; }case 1, 2: yield "one or two"; case 3: yield "three"; case 4, 5, 6: yield "four or five or six"; default: yield "unknown";
<a name="yqs9A"></a>
## 文本块(预览功能)
- 一直以来,Java 语言在定义字符串的方式是有限的,字符串需要以双引号开头,以双引号结尾,这导致字符串不能够多行使用,而是需要通过换行转义或者换行连接符等方式来变通支持多行,但这样会增加编辑工作量,同时也会导致所在代码段难以阅读、难以维护。
- Java 13 引入了文本块来解决多行文本的问题,文本块以三重双引号开头,并以同样的以三重双引号结尾终止,它们之间的任何内容都被解释为字符串的一部分,包括换行符,避免了对大多数转义序列的需要,并且它仍然是普通的 java.lang.String 对象,文本块可以在 Java 中可以使用字符串文字的任何地方使用,而与编译后的代码没有区别,还增强了 Java 程序中的字符串可读性。并且通过这种方式,可以更直观地表示字符串,可以支持跨越多行,而且不会出现转义的视觉混乱,将可以广泛提高 Java 类程序的可读性和可写性。
- 在 Java 13 之前,多行字符串写法为
```java
String html ="<html>\n" +
" <body>\n" +
" <p>Hello, World</p>\n" +
" </body>\n" +
"</html>\n";
String json ="{\n" +
" \"name\":\"mkyong\",\n" +
" \"age\":38\n" +
"}\n";
在 Java 13 引入文本块之后,写法为 ```java String html = “””
<html> <body> <p>Hello, World</p> </body> </html> """;String json = “””
{ "name":"mkyong", "age":38 } """;
- 文本块是作为预览功能引入到 Java 13 中的,这意味着它们不包含在相关的 Java 语言规范中,这样做的好处是方便用户测试功能并提供反馈,后续更新可以根据反馈来改进功能,或者必要时甚至删除该功能,如果该功能立即成为 Java SE 标准的一部分,则进行更改将变得更加困难。重要的是要意识到预览功能不是 beta 形式。
- 由于预览功能不是规范的一部分,因此有必要为编译和运行时明确启用它们。需要使用下面两个命令行参数来启用预览功能
```java
$ javac --enable-preview --release 13 Example.java
$ java --enable-preview Example
Java14
新特性列表
- instanceof 模式匹配(预览阶段)
- G1的NUMA可识别内存分配
- Record类型(预览阶段)
- Switch表达式(正式版)
- 删除CMS垃圾回收器
- ZGC支持MacOS和Windows系统(试验阶段)
- 弃用 ParallelScavenge 和 SerialOld GC 的组合使用
-
instanceof 模式匹配(预览阶段)
Java 14 中对 instanceof 的改进,主要目的是为了让创建对象更简单、简洁和高效,并且可读性更强、提高安全性。
- 在以往实际使用中,instanceof 主要用来检查对象的类型,然后根据类型对目标对象进行类型转换,之后进行不同的处理、实现不同的逻辑 ```java // instanceof 传统使用方式 if (person instanceof Student) { Student student = (Student) person; student.say(); // other student operations } else if (person instanceof Teacher) { Teacher teacher = (Teacher) person; teacher.say(); // other teacher operations }
- 上述代码中,我们首先需要对 person 对象进行类型判断,判断 person 具体是 Student 还是 Teacher,因为这两种角色对应不同操作,亦即对应到的实际逻辑实现,判断完 person 类型之后,然后强制对 person 进行类型转换为局部变量,以方便后续执行属于该角色的特定操作
- 上面这种写法,有下面两个问题:
- 每次在检查类型之后,都需要强制进行类型转换。
- 类型转换后,需要提前创建一个局部变量来接收转换后的结果,代码显得多余且繁琐
```java
// instanceof 模式匹配使用方式
if (person instanceof Student student) {
student.say();
// other student operations
} else if (person instanceof Teacher teacher) {
teacher.say();
// other teacher operations
}
- 首先在 if 代码块中,对 person 对象进行类型匹配,校验 person 对象是否为 Student 类型,如果类型匹配成功,则会转换为 Student 类型,并赋值给模式局部变量 student,并且只有当模式匹配表达式匹配成功是才会生效和复制,同时这里的 student 变量只能在 if 块中使用,而不能在 else if/else 中使用,否则会报编译错误。
- 注意,如果 if 条件中有 && 运算符时,当 instanceof 类型匹配成功,模式局部变量的作用范围也可以相应延长,如下面代码 ```java // Instanceof 模式匹配 && 方式 if (obj instanceof String s && s.length() > 5) {.. s.contains(..) ..}
- 另外,需要注意,这种作用范围延长,并不适用于或 || 运算符,因为即便 || 运算符左边的 instanceof 类型匹配没有成功也不会造成短路,依旧会执行到||运算符右边的表达式,但是此时,因为 instanceof 类型匹配没有成功,局部变量并未定义赋值,此时使用会产生问题
- 与传统写法对比,可以发现模式匹配不但提高了程序的安全性、健壮性,另一方面,不需要显式的去进行二次类型转换,减少了大量不必要的强制类型转换。模式匹配变量在模式匹配成功之后,可以直接使用,同时它还被限制了作用范围,大大提高了程序的简洁性、可读性和安全性。instanceof 的模式匹配,为 Java 带来的有一次便捷的提升,能够剔除一些冗余的代码,写出更加简洁安全的代码,提高码代码效率
<a name="q0VXF"></a>
## G1 的 NUMA 可识别内存分配
- Java 14 改进非一致性内存访问(NUMA)系统上的 G1 垃圾收集器的整体性能,主要是对年轻代的内存分配进行优化,从而提高 CPU 计算过程中内存访问速度。
- NUMA 是 **non-unified memory access** 的缩写,主要是指在当前的多插槽物理计算机体系中,比较普遍是多核的处理器,并且越来越多的具有 NUMA 内存访问体系结构,即内存与每个插槽或内核之间的距离并不相等。同时套接字之间的内存访问具有不同的性能特征,对更远的套接字的访问通常具有更多的时间消耗。这样每个核对于每一块或者某一区域的内存访问速度会随着核和物理内存所在的位置的远近而有不同的时延差异。
- Java 中,堆内存分配一般发生在线程运行的时候,当创建了一个新对象时,该线程会触发 G1 去分配一块内存出来,用来存放新创建的对象,在 G1 内存体系中,其实就是一块 region(大对象除外,大对象需要多个 region),在这个分配新内存的过程中,如果支持了 NUMA 感知内存分配,将会优先在与当前线程所绑定的 NUMA 节点空闲内存区域来执行 allocate 操作,同一线程创建的对象,尽可能的保留在年轻代的同一 NUMA 内存节点上,因为是基于同一个线程创建的对象大部分是短存活并且高概率互相调用的。
- 具体启用方式可以在 JVM 参数后面加上如下参数
```java
-XX:+UseNUMA
- 通过这种方式来启用可识别的内存分配方式,能够提高一些大型计算机的 G1 内存分配回收性能。 改进 NullPointerExceptions 提示信息
- Java 14 改进 NullPointerException 的可查性、可读性,能更准确地定位 null 变量的信息。该特性能够帮助开发者和技术支持人员提高生产力,以及改进各种开发工具和调试工具的质量,能够更加准确、清楚地根据动态异常与程序代码相结合来理解程序。
相信每位开发者在实际编码过程中都遇到过 NullPointerException,每当遇到这种异常的时候,都需要根据打印出来的详细信息来分析、定位出现问题的原因,以在程序代码中规避或解决。例如,假设下面代码出现了一个 NullPointerException
book.id = 99;打印出来的 NullPointerException 信息如下 ```java // NullPointerException 信息 Exception in thread “main” java.lang.NullPointerException at Book.main(Book.java:5)
- 像上面这种异常,因为代码比较简单,并且异常信息中也打印出来了行号信息,开发者可以很快速定位到出现异常位置:book 为空而导致的 NullPointerException,而对于一些复杂或者嵌套的情况下出现 NullPointerException 时,仅根据打印出来的信息,很难判断实际出现问题的位置,具体见下面示例
```java
shoopingcart.buy.book.id = 99;
- 对于这种比较复杂的情况下,仅仅单根据异常信息中打印的行号,则比较难判断出现 NullPointerException 的原因
- 而 Java 14 中,则做了对 NullPointerException 打印异常信息的改进增强,通过分析程序的字节码信息,能够做到准确的定位到出现 NullPointerException 的变量,并且根据实际源代码打印出详细异常信息,对于上述示例,打印信息如下
```java
Exception in thread “main” java.lang.NullPointerException:
at Book.main(Book.java:5)Cannot assign field "book" because "shoopingcart.buy" is null
- 对比可以看出,改进之后的 NullPointerException 信息,能够准确打印出具体哪个变量导致的 NullPointerException,减少了由于仅带行号的异常提示信息带来的困惑。该改进功能可以通过如下参数开启
```java
-XX:+ShowCodeDetailsInExceptionMessages
该增强改进特性,不仅适用于属性访问,还适用于方法调用、数组访问和赋值等有可能会导致 NullPointerException 的地方
Record 类型(预览功能)
Java 14 富有建设性地将 Record 类型作为预览特性而引入。Record 类型允许在代码中使用紧凑的语法形式来声明类,而这些类能够作为不可变数据类型的封装持有者。Record 这一特性主要用在特定领域的类上;与枚举类型一样,Record 类型是一种受限形式的类型,主要用于存储、保存数据,并且没有其它额外自定义行为的场景下。
在以往开发过程中,被当作数据载体的类对象,在正确声明定义过程中,通常需要编写大量的无实际业务、重复性质的代码,其中包括:构造函数、属性调用、访问以及 equals() 、hashCode()、toString() 等方法,因此在 Java 14 中引入了 Record 类型,其效果有些类似 Lombok 的 @Data 注解、Kotlin 中的 data class,但是又不尽完全相同,它们的共同点都是类的部分或者全部可以直接在类头中定义、描述,并且这个类只用于存储数据而已。对于 Record 类型,具体可以用下面代码来说明 ```java public record Person(String name, int age) { public static String address;
public String getName() {
return name;} }
- 对上述代码进行编译,然后反编译之后可以看到如下结果
```java
public final class Person extends java.lang.Record {
private final java.lang.String name;
private final java.lang.String age;
public Person(java.lang.String name, java.lang.String age) { /* compiled code */ }
public java.lang.String getName() { /* compiled code */ }
public java.lang.String toString() { /* compiled code */ }
public final int hashCode() { /* compiled code */ }
public final boolean equals(java.lang.Object o) { /* compiled code */ }
public java.lang.String name() { /* compiled code */ }
public java.lang.String age() { /* compiled code */ }
}
- 根据反编译结果,可以得出,当用 Record 来声明一个类时,该类将自动拥有下面特征
- 拥有一个构造方法
- 获取成员属性值的方法:name()、age()
- hashCode() 方法和 euqals() 方法
- toString() 方法
- 类对象和属性被 final 关键字修饰,不能被继承,类的示例属性也都被 final 修饰,不能再被赋值使用。
- 还可以在 Record 声明的类中定义静态属性、方法和示例方法。注意,不能在 Record 声明的类中定义示例字段,类也不能声明为抽象类等。
- 可以看到,该预览特性提供了一种更为紧凑的语法来声明类,并且可以大幅减少定义类似数据类型时所需的重复性代码。
- 另外 Java 14 中为了引入 Record 这种新的类型,在 java.lang.Class 中引入了下面两个新方法 ```java RecordComponent[] getRecordComponents() boolean isRecord()
- 其中 getRecordComponents() 方法返回一组 java.lang.reflect.RecordComponent 对象组成的数组,java.lang.reflect.RecordComponent也是一个新引入类,该数组的元素与 Record 类中的组件相对应,其顺序与在记录声明中出现的顺序相同,可以从该数组中的每个 RecordComponent 中提取到组件信息,包括其名称、类型、泛型类型、注释及其访问方法。
- 而 isRecord() 方法,则返回所在类是否是 Record 类型,如果是,则返回 true
<a name="WHdSo"></a>
## Switch 表达式(正式版)
- switch 表达式在之前的 Java 12 和 Java 13 中都是处于预览阶段,而在这次更新的 Java 14 中,终于成为稳定版本,能够正式可用。
- switch 表达式带来的不仅仅是编码上的简洁、流畅,也精简了 switch 语句的使用方式,同时也兼容之前的 switch 语句的使用;之前使用 switch 语句时,在每个分支结束之前,往往都需要加上 break 关键字进行分支跳出,以防 switch 语句一直往后执行到整个 switch 语句结束,由此造成一些意想不到的问题。switch 语句一般使用冒号 :来作为语句分支代码的开始,而 switch 表达式则提供了新的分支切换方式,即 -> 符号右则表达式方法体在执行完分支方法之后,自动结束 switch 分支,同时 -> 右则方法块中可以是表达式、代码块或者是手动抛出的异常。以往的 switch 语句写法如下
```java
int dayOfWeek;
switch (day) {
case MONDAY:
case FRIDAY:
case SUNDAY:
dayOfWeek = 6;
break;
case TUESDAY:
dayOfWeek = 7;
break;
case THURSDAY:
case SATURDAY:
dayOfWeek = 8;
break;
case WEDNESDAY:
dayOfWeek = 9;
break;
default:
dayOfWeek = 0;
break;
}
- 而现在 Java 14 可以使用 switch 表达式正式版之后,上面语句可以转换为下列写法 ```java int dayOfWeek = switch (day) { case MONDAY, FRIDAY, SUNDAY -> 6; case TUESDAY -> 7; case THURSDAY, SATURDAY -> 8; case WEDNESDAY -> 9; default -> 0;
};
- 很明显,switch 表达式将之前 switch 语句从编码方式上简化了不少,但是还是需要注意下面几点
- 需要保持与之前 switch 语句同样的 case 分支情况。
- 之前需要用变量来接收返回值,而现在直接使用 yield 关键字来返回 case 分支需要返回的结果。
- 现在的 switch 表达式中不再需要显式地使用 return、break 或者 continue 来跳出当前分支。
- 现在不需要像之前一样,在每个分支结束之前加上 break 关键字来结束当前分支,如果不加,则会默认往后执行,直到遇到 break 关键字或者整个 switch 语句结束,在 Java 14 表达式中,表达式默认执行完之后自动跳出,不会继续往后执行。
- 对于多个相同的 case 方法块,可以将 case 条件并列,而不需要像之前一样,通过每个 case 后面故意不加 break 关键字来使用相同方法块
- 使用 switch 表达式来替换之前的 switch 语句,确实精简了不少代码,提高了编码效率,同时也可以规避一些可能由于不太经意而出现的意想不到的情况,可见 Java 在提高使用者编码效率、编码体验和简化使用方面一直在不停的努力中,同时也期待未来有更多的类似 lambda、switch 表达式这样的新特性出来
<a name="DwLxV"></a>
## 删除 CMS 垃圾回收器
- CMS 是老年代垃圾回收算法,通过标记-清除的方式进行内存回收,在内存回收过程中能够与用户线程并行执行。CMS 回收器可以与 Serial 回收器和 Parallel New 回收器搭配使用,CMS 主要通过并发的方式,适当减少系统的吞吐量以达到追求响应速度的目的,比较适合在追求 GC 速度的服务器上使用。
- 因为 CMS 回收算法在进行 GC 回收内存过程中是使用并行方式进行的,如果服务器 CPU 核数不多的情况下,进行 CMS 垃圾回收有可能造成比较高的负载。同时在 CMS 并行标记和并行清理时,应用线程还在继续运行,程序在运行过程中自然会创建新对象、释放不用对象,所以在这个过程中,会有新的不可达内存地址产生,而这部分的不可达内存是出现在标记过程结束之后,本轮 CMS 回收无法在周期内将它们回收掉,只能留在下次垃圾回收周期再清理掉。这样的垃圾就叫做浮动垃圾。由于垃圾收集和用户线程是并发执行的,因此 CMS 回收器不能像其他回收器那样进行内存回收,需要预留一些空间用来保存用户新创建的对象。由于 CMS 回收器在老年代中使用标记-清除的内存回收策略,势必会产生内存碎片,内存当碎片过多时,将会给大对象分配带来麻烦,往往会出现老年代还有空间但不能再保存对象的情况。
- 所以,早在几年前的 Java 9 中,就已经决定放弃使用 CMS 回收器了,而这次在 Java 14 中,是继之前 Java 9 中放弃使用 CMS 之后,彻底将其禁用,并删除与 CMS 有关的选项,同时清除与 CMS 有关的文档内容,至此曾经辉煌一度的 CMS 回收器,也将成为历史。
- 当在 Java 14 版本中,通过使用参数: -XX:+UseConcMarkSweepGC,尝试使用 CMS 时,将会收到下面信息
```java
Java HotSpot(TM) 64-Bit Server VM warning: Ignoring option UseConcMarkSweepGC; \
support was removed in <version>
ZGC 支持 MacOS 和 Windows 系统(实验阶段)
- ZGC 是最初在 Java 11 中引入,同时在后续几个版本中,不断进行改进的一款基于内存 Region,同时使用了内存读屏障、染色指针和内存多重映射等技,并且以可伸缩、低延迟为目标的内存垃圾回收器器,不过在 Java 14 之前版本中,仅仅只支持在 Linux/x64 位平台。
- 此次 Java 14,同时支持 MacOS 和 Windows 系统,解决了开发人员需要在桌面操作系统中使用 ZGC 的问题。
- 在 MacOS 和 Windows 下面开启 ZGC 的方式,需要添加如下 JVM 参数 ```java -XX:+UnlockExperimentalVMOptions -XX:+UseZGC
<a name="N65z3"></a>
## 弃用 ParallelScavenge 和 SerialOld GC 的组合使用
- 由于 Parallel Scavenge 和 Serial Old 垃圾收集算法组合起来使用的情况比较少,并且在年轻代中使用并行算法,而在老年代中使用串行算法,这种并行、串行混搭使用的情况,本身已属罕见同时也很冒险。由于这两 GC 算法组合很少使用,却要花费巨大工作量来进行维护,所以在 Java 14 版本中,考虑将这两 GC 的组合弃用。
- 具体弃用情况如下,通过弃用组合参数:-XX:+UseParallelGC -XX:-UseParallelOldGC,来弃用年轻代、老年期中并行、串行混搭使用的情况;同时,对于单独使用参数:-XX:-UseParallelOldGC 的地方,也将显示该参数已被弃用的警告信息
<a name="Iws3H"></a>
## 文本块(第二预览版本)
[
](https://www.pdai.tech/md/java/java8up/java14.html)
- Java 13 引入了文本块来解决多行文本的问题,文本块主要以三重双引号开头,并以同样的以三重双引号结尾终止,它们之间的任何内容都被解释为文本块字符串的一部分,包括换行符,避免了对大多数转义序列的需要,并且它仍然是普通的 java.lang.String 对象,文本块可以在 Java 中能够使用字符串的任何地方进行使用,而与编译后的代码没有区别,还增强了 Java 程序中的字符串可读性。并且通过这种方式,可以更直观地表示字符串,可以支持跨越多行,而且不会出现转义的视觉混乱,将可以广泛提高 Java 类程序的可读性和可写性。
- Java 14 在 Java 13 引入的文本块的基础之上,新加入了两个转义符,分别是:\ 和 \s,这两个转义符分别表达涵义如下:
- \:行终止符,主要用于阻止插入换行符;
- \s:表示一个空格。可以用来避免末尾的白字符被去掉。
- 在 Java 13 之前,多行字符串写法为
```java
String literal = "Lorem ipsum dolor sit amet, consectetur adipiscing " +
"elit, sed do eiusmod tempor incididunt ut labore " +
"et dolore magna aliqua.";
- 在 Java 14 新引入两个转义符之后,上述内容可以写为
```java
String text = “””
Lorem ipsum dolor sit amet, consectetur adipiscing \ elit, sed do eiusmod tempor incididunt ut labore \ et dolore magna aliqua.\ """;
- 上述两种写法,text 实际还是只有一行内容。
- 对于转义符:\s,用法如下,能够保证下列文本每行正好都是六个字符长度
```java
String colors = """
red \s
green\s
blue \s
""";
- Java 14 带来的这两个转义符,能够简化跨多行字符串编码问题,通过转义符,能够避免对换行等特殊字符串进行转移,从而简化代码编写,同时也增强了使用 String 来表达 HTML、XML、SQL 或 JSON 等格式字符串的编码可读性,且易于维护
同时 Java 14 还对 String 进行了方法扩展:
Edwards-Curve 数字签名算法 (EdDSA)
- 密封的类和接口(预览)
- 隐藏类
- 移除Nashorn JavaScript引擎
- 重新实现 DatagramSocket API
- 禁用偏向锁定
- instanceof 自动匹配模式
- 垃圾回收器ZGC:可伸缩低延迟垃圾收集器
- 文本块(Text Blocks)
- 第暂停时间垃圾收集器 转正
- 移除了 Solaris 和 SPARC端口
- 外部存储器访问API(孵化器版)
- Records(二次预览)
-
Edwards-Curve 数字签名算法 (EdDSA)
Edwards-Curve 数字签名算法(EdDSA),一种根据 RFC 8032 规范所描述的 Edwards-Curve 数字签名算法(EdDSA)实现加密签名,实现了一种 RFC 8032 标准化方案,但它不能代替 ECDSA。
与 JDK 中的现有签名方案相比,EdDSA 具有更高的安全性和性能,因此备受关注。它已经在OpenSSL和BoringSSL等加密库中得到支持,在区块链领域用的比较多。
EdDSA是一种现代的椭圆曲线方案,具有JDK中现有签名方案的优点。EdDSA将只在SunEC提供商中实现
密封的类和接口(预览)
封闭类(预览特性),可以是封闭类和或者封闭接口,用来增强 Java 编程语言,防止其他类或接口扩展或实现它们。
因为我们引入了sealedclass或interfaces,这些class或者interfaces只允许被指定的类或者interface进行扩展和实现。
- 使用修饰符sealed,您可以将一个类声明为密封类。密封的类使用reserved关键字permits列出可以直接扩展它的类。子类可以是最终的,非密封的或密封的。
- 之前我们的代码是这样的
- 但是我们现在要限制 Person类 只能被这三个类继承,不能被其他类继承,需要这么做 ```java // 添加sealed修饰符,permits后面跟上只能被继承的子类名称 public sealed class Person permits Teacher, Worker, Student{ } //人
// 子类可以被修饰为 final final class Teacher extends Person { }//教师
// 子类可以被修饰为 non-sealed,此时 Worker类就成了普通类,谁都可以继承它 non-sealed class Worker extends Person { } //工人 // 任何类都可以继承Worker class AnyClass extends Worker{}
//子类可以被修饰为 sealed,同上 sealed class Student extends Person permits MiddleSchoolStudent,GraduateStudent{ } //学生
final class MiddleSchoolStudent extends Student { } //中学生
final class GraduateStudent extends Student { } //研究生
- 很强很实用的一个特性,可以限制类的层次结构
<a name="Uk9Pc"></a>
## 隐藏类
> 隐藏类是为框架(frameworks)所设计的,隐藏类不能直接被其他类的字节码使用,只能在运行时生成类并通过反射间接使用它们。
- 该提案通过启用标准 API 来定义 无法发现 且 具有有限生命周期 的隐藏类,从而提高 JVM 上所有语言的效率。JDK内部和外部的框架将能够动态生成类,而这些类可以定义隐藏类。通常来说基于JVM的很多语言都有动态生成类的机制,这样可以提高语言的灵活性和效率。
- 隐藏类天生为框架设计的,在运行时生成内部的class。
- 隐藏类只能通过反射访问,不能直接被其他类的字节码访问。
- 隐藏类可以独立于其他类加载、卸载,这可以减少框架的内存占用。
- **Hidden Classes是什么呢**?
- Hidden Classes就是不能直接被其他class的二进制代码使用的class。Hidden Classes主要被一些框架用来生成运行时类,但是这些类不是被用来直接使用的,而是通过反射机制来调用。
- 比如在JDK8中引入的lambda表达式,JVM并不会在编译的时候将lambda表达式转换成为专门的类,而是在运行时将相应的字节码动态生成相应的类对象。
- 另外使用动态代理也可以为某些类生成新的动态类。
- **那么我们希望这些动态生成的类需要具有什么特性呢**?
- **不可发现性**。 因为我们是为某些静态的类动态生成的动态类,所以我们希望把这个动态生成的类看做是静态类的一部分。所以我们不希望除了该静态类之外的其他机制发现。
- **访问控制**。 我们希望在访问控制静态类的同时,也能控制到动态生成的类。
- **生命周期**。 动态生成类的生命周期一般都比较短,我们并不需要将其保存和静态类的生命周期一致
- **API的支持**
- 所以我们需要一些API来定义无法发现的且具有有限生命周期的隐藏类。这将提高所有基于JVM的语言实现的效率
```java
java.lang.reflect.Proxy // 可以定义隐藏类作为实现代理接口的代理类。
java.lang.invoke.StringConcatFactory // 可以生成隐藏类来保存常量连接方法;
java.lang.invoke.LambdaMetaFactory //可以生成隐藏的nestmate类,以容纳访问封闭变量的lambda主体;
普通类是通过调用ClassLoader::defineClass创建的,而隐藏类是通过调用Lookup::defineHiddenClass创建的。这使JVM从提供的字节中派生一个隐藏类,链接该隐藏类,并返回提供对隐藏类的反射访问的查找对象。调用程序可以通过返回的查找对象来获取隐藏类的Class对象。
移除Nashorn JavaScript引擎
移除了 Nashorn JavaScript 脚本引擎、APIs,以及 jjs 工具。这些早在 JDK 11 中就已经被标记为 deprecated 了,JDK 15 被移除就很正常了
Nashorn引擎是什么?
- Nashorn 是 JDK 1.8 引入的一个 JavaScript 脚本引擎,用来取代 Rhino 脚本引擎。Nashorn 是 ECMAScript-262 5.1 的完整实现,增强了 Java 和 JavaScript 的兼容性,并且大大提升了性能。
- 为什么要移除?
- 官方的描述是,随着 ECMAScript 脚本语言的结构、API 的改编速度越来越快,维护 Nashorn 太有挑战性了,所以……
重新实现 DatagramSocket API
重新实现了老的 DatagramSocket API 接口,更改了 java.net.DatagramSocket 和 java.net.MulticastSocket 为更加简单、现代化的底层实现,更易于维护和调试。
- java.net.datagram.Socket和java.net.MulticastSocket的当前实现可以追溯到JDK 1.0,那时IPv6还在开发中。因此,当前的多播套接字实现尝试调和IPv4和IPv6难以维护的方式。
- 通过替换 java.net.datagram 的基础实现,重新实现旧版 DatagramSocket API。
- 更改java.net.DatagramSocket 和 java.net.MulticastSocket 为更加简单、现代化的底层实现。提高了 JDK 的可维护性和稳定性。
- 通过将java.net.datagram.Socket和java.net.MulticastSocket API的底层实现替换为更简单、更现代的实现来重新实现遗留的DatagramSocket API
新的实现:
在默认情况下禁用偏向锁定,并弃用所有相关命令行选项。目标是确定是否需要继续支持偏置锁定的 高维护成本 的遗留同步优化, HotSpot虚拟机使用该优化来减少非竞争锁定的开销。 尽管某些Java应用程序在禁用偏向锁后可能会出现性能下降,但偏向锁的性能提高通常不像以前那么明显。
该特性默认禁用了biased locking(-XX:+UseBiasedLocking),并且废弃了所有相关的命令行选型(BiasedLockingStartupDelay, BiasedLockingBulkRebiasThreshold, BiasedLockingBulkRevokeThreshold, BiasedLockingDecayTime, UseOptoBiasInlining, PrintBiasedLockingStatistics and PrintPreciseBiasedLockingStatistics)
instanceof 自动匹配模式
模式匹配(第二次预览),第一次预览是 JDK 14 中提出来的。
Java 14 之前 ```java if (object instanceof Kid) { Kid kid = (Kid) object; // … } else if (object instanceof Kiddle) { Kid kid = (Kid) object; // … }
- Java14+
```java
if (object instanceof Kid kid) {
// ...
} else if (object instanceof Kiddle kiddle) {
// ...
}
垃圾回收器ZGC: 可伸缩低延迟垃圾收集器
ZGC是Java 11引入的新的垃圾收集器(JDK9以后默认的垃圾回收器是G1),经过了多个实验阶段,自此终于成为正式特性。ZGC是一个重新设计的并发的垃圾回收器,可以极大的提升GC的性能。支持任意堆大小而保持稳定的低延迟(10ms以内),性能非常可观。目前默认垃圾回收器仍然是 G1,后续很有可以能将ZGC设为默认垃圾回收器。之前需要通过-XX:+UnlockExperimentalVMOptions -XX:+UseZGC来启用ZGC,现在只需要-XX:+UseZGC就可以。
- ZGC 是一个可伸缩的、低延迟的垃圾收集器,主要为了满足如下目标进行设计:
- GC 停顿时间不超过 10ms
- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
- 方便在此基础上引入新的 GC 特性和利用 colord
- 针以及 Load barriers 优化奠定基础
- 当前只支持 Linux/x64 位平台 停顿时间在 10ms 以下,10ms 其实是一个很保守的数据,即便是 10ms 这个数据,也是 GC 调优几乎达不到的极值。根据 SPECjbb 2015 的基准测试,128G 的大堆下最大停顿时间才 1.68ms,远低于 10ms,和 G1 算法相比,改进非常明显。

- 本图片引用自: The Z Garbage Collector – An Introduction
- 不过目前 ZGC 还处于实验阶段,目前只在 Linux/x64 上可用,如果有足够的需求,将来可能会增加对其他平台的支持。同时作为实验性功能的 ZGC 将不会出现在 JDK 构建中,除非在编译时使用 configure 参数:—with-jvm-features=zgc 显式启用。
- 在实验阶段,编译完成之后,已经迫不及待的想试试 ZGC,需要配置以下 JVM 参数,才能使用 ZGC,具体启动 ZGC 参数如下: ```java -XX:+ UnlockExperimentalVMOptions -XX:+ UseZGC -Xmx10g
- 其中参数: -Xmx 是 ZGC 收集器中最重要的调优选项,大大解决了程序员在 JVM 参数调优上的困扰。ZGC 是一个并发收集器,必须要设置一个最大堆的大小,应用需要多大的堆,主要有下面几个考量:
- 对象的分配速率,要保证在 GC 的时候,堆中有足够的内存分配新对象。
- 一般来说,给 ZGC 的内存越多越好,但是也不能浪费内存,所以要找到一个平衡。
<a name="f0Oys"></a>
## 文本块(Text Blocks)
> 文本块,是一个多行字符串,它可以避免使用大多数转义符号,自动以可预测的方式格式化字符串,并让开发人员在需要时可以控制格式。
- Text Blocks首次是在JDK 13中以预览功能出现的,然后在JDK 14中又预览了一次,终于在JDK 15中被确定下来,可放心使用了
```java
public static void main(String[] args) {
String query = """
SELECT * from USER \
WHERE `id` = 1 \
ORDER BY `id`, `name`;\
""";
System.out.println(query);
}
- 输出
``java SELECT * from USER WHEREid= 1 ORDER BYid,name`;
<a name="Txrqz"></a>
## 低暂停时间垃圾收集器 转正
> Shenandoah垃圾回收算法终于从实验特性转变为产品特性,这是一个从 JDK 12 引入的回收算法,该算法通过与正在运行的 Java 线程同时进行疏散工作来减少 GC 暂停时间。Shenandoah 的暂停时间与堆大小无关,无论堆栈是 200 MB 还是 200 GB,都具有相同的一致暂停时间。
- **怎么形容Shenandoah和ZGC的关系呢**?异同点大概如下:
- 相同点:性能几乎可认为是相同的
- 不同点:ZGC是Oracle JDK的。而Shenandoah只存在于OpenJDK中,因此使用时需注意你的JDK版本
- 打开方式:使用-XX:+UseShenandoahGC命令行参数打开。
- Shenandoah在JDK12被作为experimental引入,在JDK15变为Production;之前需要通过-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC来启用,现在只需要-XX:+UseShenandoahGC即可启用
<a name="mCStc"></a>
## 移除了 Solaris 和 SPARC 端口
> 移除了 Solaris/SPARC、Solaris/x64 和 Linux/SPARC 端口的源代码及构建支持。这些端口在 JDK 14 中就已经被标记为 deprecated 了,JDK 15 被移除也不奇怪。
- 删除对Solaris/SPARC、Solaris/x64和Linux/SPARC端口的源代码和构建支持,在JDK 14中被标记为废弃,在JDK15版本正式移除。 许多正在开发的项目和功能(如Valhalla、Loom和Panama)需要进行重大更改以适应CPU架构和操作系统特定代码。
- 近年来,Solaris 和 SPARC 都已被 Linux 操作系统和英特尔处理器取代。放弃对 Solaris 和 SPARC 端口的支持将使 OpenJDK 社区的贡献者能够加速开发新功能,从而推动平台向前发展
<a name="jElwi"></a>
## 外部存储器访问 API(孵化器版)
> 外存访问 API(二次孵化),可以允许 Java 应用程序安全有效地访问 Java 堆之外的外部内存
- 目的是引入一个 API,以允许 Java 程序安全、有效地访问 Java 堆之外的外部存储器。如本机、持久和托管堆。
- 有许多Java程序是访问外部内存的,比如Ignite和MapDB。 该API将有助于避免与垃圾收集相关的成本以及与跨进程共享内存以及通过将文件映射到内存来序列化和反序列化内存内容相关的不可预测性 。该Java API目前没有为访问外部内存提供令人满意的解决方案。但是在新的提议中,API不应该破坏JVM的安全性。
- Foreign-Memory Access API在JDK14被作为incubating API引入,在JDK15处于Second Incubator,提供了改进
<a name="oXHHS"></a>
## Records (二次预览)
> Records 最早在 JDK 14 中成为预览特性,JDK 15 继续二次预览
- Java 14 富有建设性地将 Record 类型作为预览特性而引入。Record 类型允许在代码中使用紧凑的语法形式来声明类,而这些类能够作为不可变数据类型的封装持有者。Record 这一特性主要用在特定领域的类上;与枚举类型一样,Record 类型是一种受限形式的类型,主要用于存储、保存数据,并且没有其它额外自定义行为的场景下。
- 在以往开发过程中,被当作数据载体的类对象,在正确声明定义过程中,通常需要编写大量的无实际业务、重复性质的代码,其中包括:构造函数、属性调用、访问以及 equals() 、hashCode()、toString() 等方法,因此在 Java 14 中引入了 Record 类型,其效果有些类似 Lombok 的 @Data 注解、Kotlin 中的 data class,但是又不尽完全相同,它们的共同点都是类的部分或者全部可以直接在类头中定义、描述,并且这个类只用于存储数据而已。对于 Record 类型,具体可以用下面代码来说明
```java
public record Person(String name, int age) {
public static String address;
public String getName() {
return name;
}
}
对上述代码进行编译,然后反编译之后可以看到如下结果 ```java public final class Person extends java.lang.Record { private final java.lang.String name; private final java.lang.String age;
public Person(java.lang.String name, java.lang.String age) { / compiled code / }
public java.lang.String getName() { / compiled code / }
public java.lang.String toString() { / compiled code / }
public final int hashCode() { / compiled code / }
public final boolean equals(java.lang.Object o) { / compiled code / }
public java.lang.String name() { / compiled code / }
public java.lang.String age() { / compiled code / } }
- 根据反编译结果,可以得出,当用 Record 来声明一个类时,该类将自动拥有下面特征
- 拥有一个构造方法
- 获取成员属性值的方法:name()、age()
- hashCode() 方法和 euqals() 方法
- toString() 方法
- 类对象和属性被 final 关键字修饰,不能被继承,类的示例属性也都被 final 修饰,不能再被赋值使用。
- 还可以在 Record 声明的类中定义静态属性、方法和示例方法。注意,不能在 Record 声明的类中定义示例字段,类也不能声明为抽象类等。
- 可以看到,该预览特性提供了一种更为紧凑的语法来声明类,并且可以大幅减少定义类似数据类型时所需的重复性代码。
- 另外 Java 14 中为了引入 Record 这种新的类型,在 java.lang.Class 中引入了下面两个新方法
```java
RecordComponent[] getRecordComponents()
boolean isRecord()
- 其中 getRecordComponents() 方法返回一组 java.lang.reflect.RecordComponent 对象组成的数组,java.lang.reflect.RecordComponent也是一个新引入类,该数组的元素与 Record 类中的组件相对应,其顺序与在记录声明中出现的顺序相同,可以从该数组中的每个 RecordComponent 中提取到组件信息,包括其名称、类型、泛型类型、注释及其访问方法。
而 isRecord() 方法,则返回所在类是否是 Record 类型,如果是,则返回 true
废除 RMI 激活
RMI Activation被标记为Deprecate,将会在未来的版本中删除。RMI激活机制是RMI中一个过时的部分,自Java 8以来一直是可选的而非必选项。RMI激活机制增加了持续的维护负担。RMI的其他部分暂时不会被弃用
RMI jdk1.2引入,EJB在RMI系统中,我们使用延迟激活。延迟激活将激活对象推迟到客户第一次使用(即第一次方法调用)之前。 既然RMI Activation这么好用,为什么要废弃呢?
- 因为对于现代应用程序来说,分布式系统大部分都是基于Web的,web服务器已经解决了穿越防火墙,过滤请求,身份验证和安全性的问题,并且也提供了很多延迟加载的技术。
所以在现代应用程序中,RMI Activation已经很少被使用到了。并且在各种开源的代码库中,也基本上找不到RMI Activation的使用代码了。 为了减少RMI Activation的维护成本,在JDK8中,RMI Activation被置为可选的。现在在JDK15中,终于可以废弃了
参考文章
Java-Review:https://gitee.com/icanci/Java-Review
- JDK新特性:https://segmentfault.com/a/1190000004417288
- Java8新特性:https://www.pdai.tech/md/java/java8/java8.html
- Java8+新特性:https://www.pdai.tech/md/java/java8up/java-8-up-overview.html

若有收获,就点个赞吧
0 人点赞
