[索引 - 相关字段]# 获取索引结构信息: GET /索引名: _index 索引名: aliases 别名: mappings 索引结构, 数据结构=> properties 属性描述字段-> "字段名": type 字段类型, fields -> keyword [关键字, type=keyword, ignore_above=256 字符串长度超出忽略]: settings 索引配置=> index 索引描述字段-> creation_date="1581053367692"-> number_of_shards="1" // 主分片数, 创建后不能修改-> number_of_replicas="1" // 主分片的副本数-> uuid="xquMd1SBSFG6aTQQdttehg"-> provided_name="索引名"-> "version": {"created": "7020099"},// type 字段类型// store 是否存储,属性有yes或者no, 论那种属性都会被存储,但如果设置成no,在查询的时候是无法用此属性作为查询项的,基于拓展和业务方便维护,建议使用yes// index 是否索引,属性有not_analyzed(分词不分析)、analyzed(分词分析)、no(不分析不分词)// analyzer 分词器, 入库时使用// search_analyzer 分词器, 查询的时候使用哪种分词器// ignore_above 对超过 ignore_above 的字符串,analyzer 不会进行处理, 不会索引// 这个选项主要对 not_analyzed 字段有用,这些字段通常用来进行过滤、聚合和排序。而且这些字段都是结构化的,所以一般不会允许在这些字段中索引过长的项。// format 日期格式要求,例如设置为"yyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"// dynamic 是否使用动态映射, true默认值, 动态添加字段, false忽略新字段, strict如果碰到陌生字段,抛出异常# 创建索引: PUT /索引名 索引结构描述// acknowledged= true/fasle// shards_acknowledged = true/fasle// index=索引名# 删除索引: DELETE /索引名// 每个文档都有type,每种type都会有自己的mapping// mapping定义了type的field,每个field的数据类型,以及es如何处理这些field[索引]# 关闭索引: POST /index/_close# 打开索引: POST /index/_open
字段类型
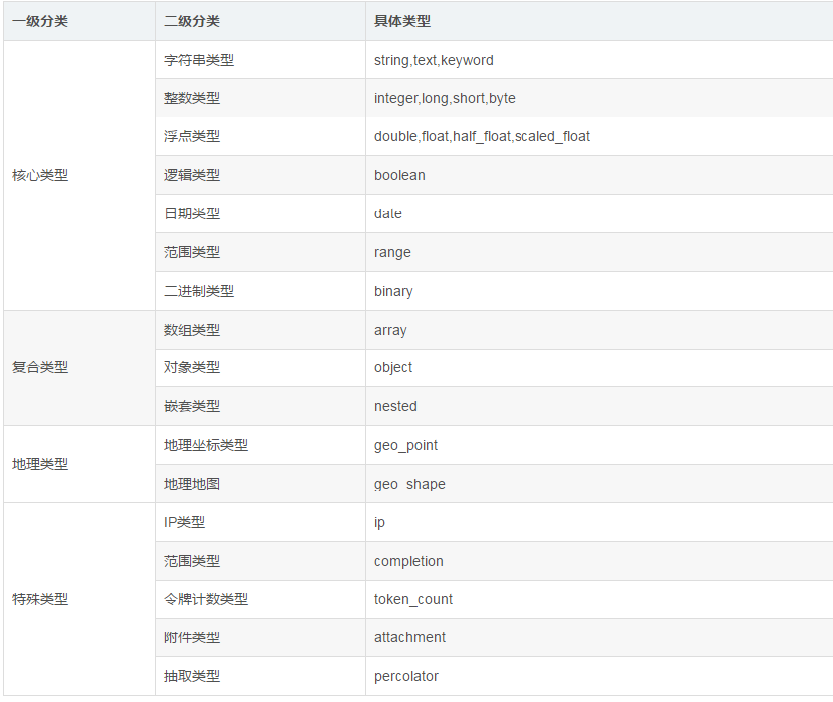
[string]: 字符串类型// string类型在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。[text]: 当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。// 设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项// text类型的字段不用于排序,很少用于聚合。[keyword]: keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签// 如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。[整数类型]: byte short integer long[浮点类型]: doule float half_float scaled_float[date]: 日期类型表示格式// 日期格式的字符串,比如 “2018-01-13” 或 “2018-01-13 12:10:30”// long类型的毫秒数( milliseconds-since-the-epoch,epoch就是指UNIX诞生的UTC时间1970年1月1日0时0分0秒)// integer的秒数(seconds-since-the-epoch)[boolean][binary][array][object][IP]

若有收获,就点个赞吧
0 人点赞
