[官网]:http://kafka.apache.org/: http://kafka.apachecn.org/
Apache 软件基金会开发的一个开源流处理平台,由Scala和Java编写,于2010年贡献给了Apache基金会并成为顶级开源项目
最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统。
高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。它可以处理消费者规模的网站中的所有动作流数据,这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。
kafka的诞生,是为了解决linkedin的数据管道问题,起初linkedin采用了ActiveMQ来进行数据交换,大约是在2010年前后,那时的ActiveMQ还远远无法满足linkedin对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,linkedin决定研发自己的消息传递系统,当时linkedin的首席架构师jay kreps便开始组织团队进行消息传递系统的研发。<br /> <br />
[Kafka 是一种高吞吐量的分布式发布订阅消息系统]
:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能
:高吞吐量,即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
:支持通过Kafka服务器和消费机集群来分区消息
:支持Hadoop并行数据加载
:高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
:集群支持热扩展
// 流处理平台, 发布和订阅消息(流)
基本概念
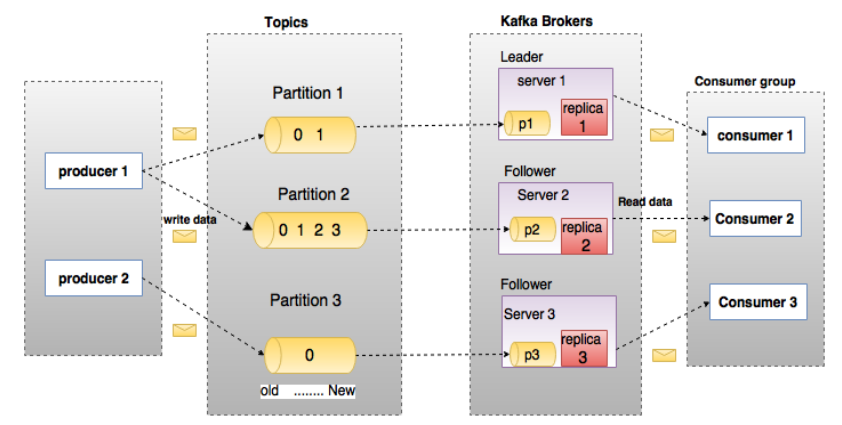
[Topic 主题]
: 每条发布到Kafka集群的消息都有一个类别, 这个类别被称为Topic, 消息存放的目录即主题, 发布订阅的对象
[producer 生产者]
: 向topic发布消息的客户端, 往某个Topic上发布消息, 选择发布到Topic上的哪一个分区
[consumer 消费者]
: 从topic订阅消息的客户端
[Consumer Group 消费分组]
:一个Consumer Group包含多个consumer, 这个是预先在配置文件中配置好的
:各个consumer可以组成一个组,partition中的每个message只能被组中的一个consumer消费
:如果一个message可以被多个consumer消费的话,那么这些consumer必须在不同的组
// Producers和consumers可以同时从多个topic读写数据
// 一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息
[Broker]
:Kafka节点, 一个Kafka节点就是一个broker, 多个broker可以组成一个Kafka集群
[Partition 分组]
:topic物理上的分组, 一个topic可以分为多个partition, 每个partition是一个有序的队列
[Segment]
:partition物理上由多个segment组成,每个Segment存着message信息
// Kafka不支持一个partition中的message由两个或两个以上的consumer处理,即便是来自不同的consumer group
[Zookeeper]
:协调kafka的正常运行
主题 Topic 和 日志 Log
[主题 Topic 和 日志 Log]
: topic是发布的消息的类别名, 一个topic可以有零个, 一个或多个消费者订阅该主题的消息
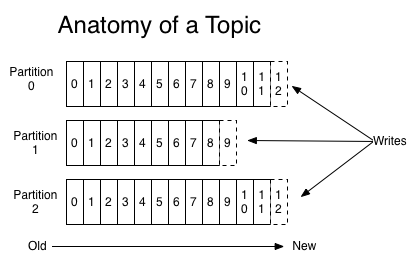
: 对于每个topic, Kafka集群都会维护一个分区log
: 每一个分区 (partition) 都是一个顺序的、不可变的消息队列, 并且可以持续的添加
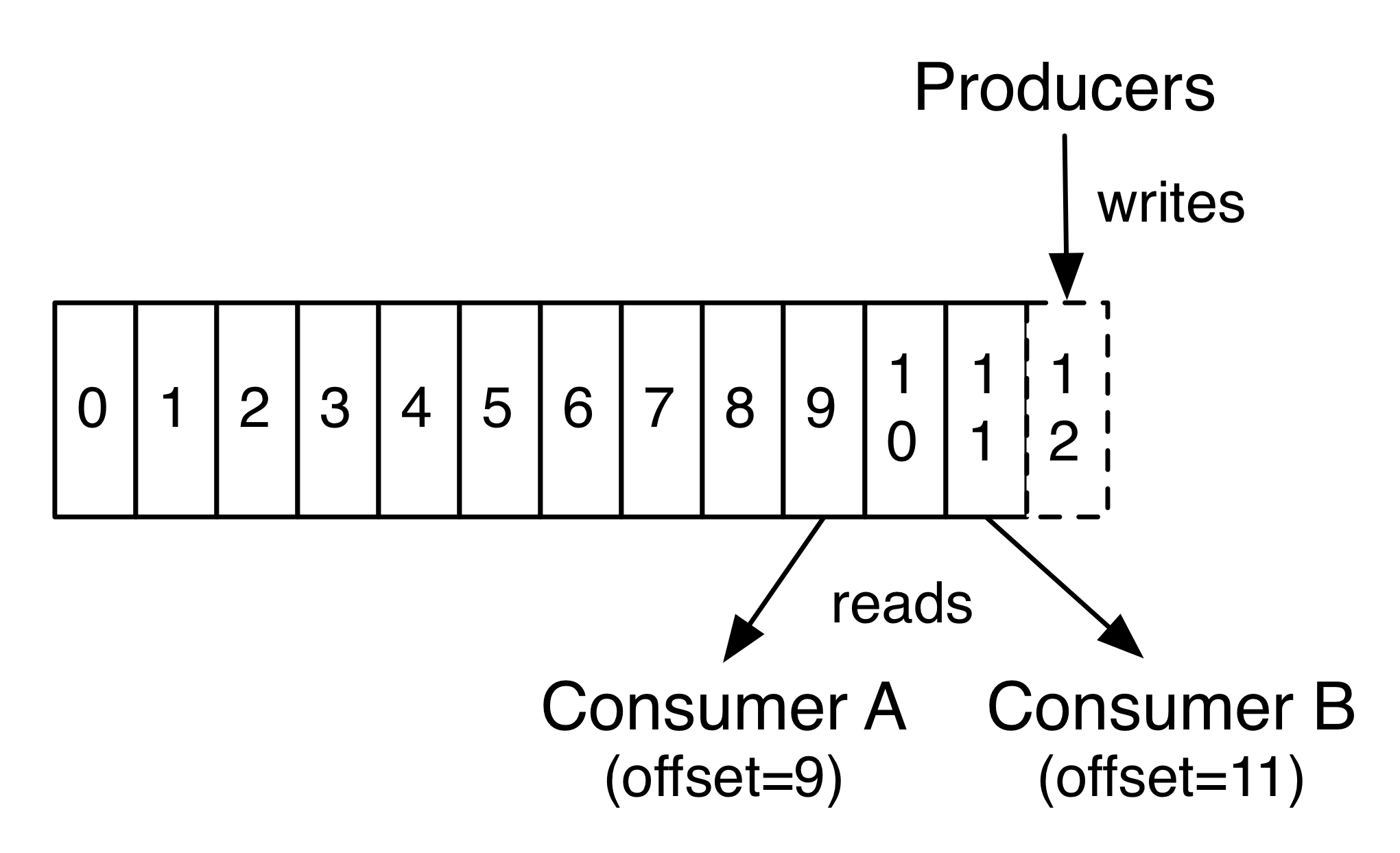
: 分区中的消息都被分了一个序列号, 称之为偏移量(offset),在每个分区中此偏移量都是唯一的
// Kafka集群保持所有的消息, 直到它们过期 (无论消息是否被消费)
// 实际上消费者所持有的仅有的元数据就是这个偏移量 (offset), 偏移量由消费者来控制
// 正常情况当消费者消费消息的时候, 偏移量也线性的的增加, 实际偏移量由消费者控制, 消费者可以将偏移量重置为更早的位置, 重新读取消息
// 一个消费者的操作不会影响其它消费者对此log的处理
主题存储(日志)解析
生产者 & 消费者
[分布式 Distribution]
: Kafka中采用分区的设计, 可以处理更多的消息,不受单台服务器的限制, 它可以不受限的处理更多的数据
: 分区可以作为并行处理的单元
: Log的分区被分布到集群中的多个服务器上, 根据配置每个分区还可以复制到其它服务器作为备份容错
// 每个分区有一个leader, 零或多个follower, Leader处理此分区的所有的读写请求, 而follower被动的复制数据
// leader宕机, 其它的一个follower会被推举为新的leader
// 一台服务器可能同时是一个分区的leader, 另一个分区的follower, 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理
: Kakfa Broker集群受Zookeeper管理
// 所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点, 因为只有一个Kafka Broker会注册成功
// 成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller
// 其他的Kafka broker叫Kafka Broker follower
// 选取ISR列表中的一个replica作为partition leader
[Geo-Replication 异地数据同步技术]
: MirrorMaker, 消息可以跨多个数据中心或云区域进行复制, active/passive场景中用于备份和恢复
// active/passive方案中将数据置于更接近用户的位置,或数据本地化

若有收获,就点个赞吧
0 人点赞
