[安装模式]: 本地(独立)模式: 伪分布式模式: 全分布式模式: Hadoop HA安装// 区分的依据是NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器// 安装// https://blog.csdn.net/hliq5399/article/details/78193113/
| 模式名称 | 各个模块占用的JVM进程数 | 各个模块运行在几个机器数上 |
|---|---|---|
| 本地模式 | 1个 | 1个 |
| 伪分布式模式 | N个 | 1个 |
| 完全分布式模式 | N个 | N个 |
| HA完全分布式 | N个 | N个 |

安装环境配置
[安装步骤]: 00 关闭防火墙// service iptables status && service iptables stop// -> chkconfig iptables off// - 关闭selinux// vim /etc/sysconfig/selinuxSELINUX=disabledSELINUXTYPE=targeted: 01 修改Hostname// hostname local.hadoop.xknower.com// vim /etc/sysconfig/network (/etc/sysconfig/network-scripts/ifcfg-ens33)NETWORKING=yes #使用网络HOSTNAME=local.hadoop.xknower.com #设置主机名: 02 配置JDK// vim /etc/profileexport JAVA_HOME=/opt/hadoop/jdk1.8.0_211export PATH=$JAVA_HOME/bin:$PATH
安装配置 - 本地模式
[]
本地模式是最简单的模式, 所有模块都运行与一个JVM进程中, 使用的本地文件系统,而不是HDFS,
本地模式主要是用于本地开发过程中的运行调试用。
下载hadoop安装包后不用任何设置, 默认的就是本地模式。
[安装]
: 01 创建安装目录
// mkdir /opt/hadoop
: 02 解压安装包
// tar -zxf /opt/hadoop/hadoop-2.10.0.tar.gz -C /opt/hadoop/
[测试]
//-- 准备测试数据
cat /opt/hadoop/data/wc.input
hadoop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop
# 执行案例
: cd /opt/hadoop/hadoop-2.10.0/
: bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar \
wordcount /opt/hadoop/data/wc.input /opt/hadoop/data/
//-- 查看结果 ll /opt/hadoop/data && cat /opt/hadoop/data/part-r-00000
[root@localhost hadoop-2.10.0]# cat /opt/hadoop/data/part-r-00000
hadoop 3
hbase 1
hive 2
mapreduce 1
spark 2
sqoop 1
storm 1
- 执行结果
[root@localhost hadoop-2.10.0]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar \
> wordcount /opt/hadoop/wc.input /opt/hadoop/data
20/03/24 08:02:53 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
20/03/24 08:02:53 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
20/03/24 08:02:53 INFO input.FileInputFormat: Total input files to process : 1
20/03/24 08:02:53 INFO mapreduce.JobSubmitter: number of splits:1
20/03/24 08:02:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local566207135_0001
20/03/24 08:02:54 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
-- 本地模式启动
20/03/24 08:02:54 INFO mapreduce.Job: Running job: job_local566207135_0001
-- 本地模式启动
20/03/24 08:02:54 INFO mapred.LocalJobRunner: OutputCommitter set in config null
20/03/24 08:02:54 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
20/03/24 08:02:54 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
20/03/24 08:02:54 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
20/03/24 08:02:54 INFO mapred.LocalJobRunner: Waiting for map tasks
20/03/24 08:02:54 INFO mapred.LocalJobRunner: Starting task: attempt_local566207135_0001_m_000000_0
20/03/24 08:02:54 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
20/03/24 08:02:54 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
20/03/24 08:02:54 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
20/03/24 08:02:54 INFO mapred.MapTask: Processing split: file:/opt/hadoop/wc.input:0+71
20/03/24 08:02:54 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
20/03/24 08:02:54 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
20/03/24 08:02:54 INFO mapred.MapTask: soft limit at 83886080
20/03/24 08:02:54 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
20/03/24 08:02:54 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
20/03/24 08:02:54 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
20/03/24 08:02:54 INFO mapred.LocalJobRunner:
20/03/24 08:02:54 INFO mapred.MapTask: Starting flush of map output
20/03/24 08:02:54 INFO mapred.MapTask: Spilling map output
20/03/24 08:02:54 INFO mapred.MapTask: bufstart = 0; bufend = 115; bufvoid = 104857600
20/03/24 08:02:54 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214356(104857424); length = 41/6553600
20/03/24 08:02:54 INFO mapred.MapTask: Finished spill 0
20/03/24 08:02:54 INFO mapred.Task: Task:attempt_local566207135_0001_m_000000_0 is done. And is in the process of committing
20/03/24 08:02:54 INFO mapred.LocalJobRunner: map
20/03/24 08:02:54 INFO mapred.Task: Task 'attempt_local566207135_0001_m_000000_0' done.
20/03/24 08:02:54 INFO mapred.Task: Final Counters for attempt_local566207135_0001_m_000000_0: Counters: 18
File System Counters
FILE: Number of bytes read=303512
FILE: Number of bytes written=782499
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=4
Map output records=11
Map output bytes=115
Map output materialized bytes=94
Input split bytes=90
Combine input records=11
Combine output records=7
Spilled Records=7
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
Total committed heap usage (bytes)=212860928
File Input Format Counters
Bytes Read=71
20/03/24 08:02:54 INFO mapred.LocalJobRunner: Finishing task: attempt_local566207135_0001_m_000000_0
20/03/24 08:02:54 INFO mapred.LocalJobRunner: map task executor complete.
20/03/24 08:02:54 INFO mapred.LocalJobRunner: Waiting for reduce tasks
20/03/24 08:02:54 INFO mapred.LocalJobRunner: Starting task: attempt_local566207135_0001_r_000000_0
20/03/24 08:02:54 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
20/03/24 08:02:54 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
20/03/24 08:02:54 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
20/03/24 08:02:54 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@20c89a7d
20/03/24 08:02:54 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10
20/03/24 08:02:54 INFO reduce.EventFetcher: attempt_local566207135_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
20/03/24 08:02:54 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local566207135_0001_m_000000_0 decomp: 90 len: 94 to MEMORY
20/03/24 08:02:54 INFO reduce.InMemoryMapOutput: Read 90 bytes from map-output for attempt_local566207135_0001_m_000000_0
20/03/24 08:02:54 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 90, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->90
20/03/24 08:02:54 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
20/03/24 08:02:54 INFO mapred.LocalJobRunner: 1 / 1 copied.
20/03/24 08:02:54 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
20/03/24 08:02:54 INFO mapred.Merger: Merging 1 sorted segments
20/03/24 08:02:54 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 81 bytes
20/03/24 08:02:54 INFO reduce.MergeManagerImpl: Merged 1 segments, 90 bytes to disk to satisfy reduce memory limit
20/03/24 08:02:54 INFO reduce.MergeManagerImpl: Merging 1 files, 94 bytes from disk
20/03/24 08:02:54 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
20/03/24 08:02:54 INFO mapred.Merger: Merging 1 sorted segments
20/03/24 08:02:54 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 81 bytes
20/03/24 08:02:54 INFO mapred.LocalJobRunner: 1 / 1 copied.
20/03/24 08:02:54 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
20/03/24 08:02:54 INFO mapred.Task: Task:attempt_local566207135_0001_r_000000_0 is done. And is in the process of committing
20/03/24 08:02:54 INFO mapred.LocalJobRunner: 1 / 1 copied.
20/03/24 08:02:54 INFO mapred.Task: Task attempt_local566207135_0001_r_000000_0 is allowed to commit now
20/03/24 08:02:54 INFO output.FileOutputCommitter: Saved output of task 'attempt_local566207135_0001_r_000000_0' to file:/opt/hadoop/data/_temporary/0/task_local566207135_0001_r_000000
20/03/24 08:02:54 INFO mapred.LocalJobRunner: reduce > reduce
20/03/24 08:02:54 INFO mapred.Task: Task 'attempt_local566207135_0001_r_000000_0' done.
20/03/24 08:02:54 INFO mapred.Task: Final Counters for attempt_local566207135_0001_r_000000_0: Counters: 24
File System Counters
FILE: Number of bytes read=303732
FILE: Number of bytes written=782665
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=7
Reduce shuffle bytes=94
Reduce input records=7
Reduce output records=7
Spilled Records=7
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=7
Total committed heap usage (bytes)=212860928
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
Bytes Written=72
20/03/24 08:02:54 INFO mapred.LocalJobRunner: Finishing task: attempt_local566207135_0001_r_000000_0
20/03/24 08:02:54 INFO mapred.LocalJobRunner: reduce task executor complete.
20/03/24 08:02:55 INFO mapreduce.Job: Job job_local566207135_0001 running in uber mode : false
20/03/24 08:02:55 INFO mapreduce.Job: map 100% reduce 100%
20/03/24 08:02:55 INFO mapreduce.Job: Job job_local566207135_0001 completed successfully
20/03/24 08:02:55 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=607244
FILE: Number of bytes written=1565164
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=4
Map output records=11
Map output bytes=115
Map output materialized bytes=94
Input split bytes=90
Combine input records=11
Combine output records=7
Reduce input groups=7
Reduce shuffle bytes=94
Reduce input records=7
Reduce output records=7
Spilled Records=14
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=7
Total committed heap usage (bytes)=425721856
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=71
File Output Format Counters
Bytes Written=72
安装配置 - 伪分布式模式安装
[安装]
: 01 创建用户
// useradd hadoop && passwd hadoop
: 02 用户分配权限
// vim /etc/sudoers (chmod u+w /etc/sudoers)
root ALL=(ALL) ALL
hadoop ALL=(root) NOPASSWD:ALL
: 03 切换用户
// su - hadoop
: 04 创建安装目录
// mkdir /opt/hadoop
: 05 解压安装包
// tar -zxf /opt/hadoop/hadoop-2.10.0.tar.gz -C /opt/hadoop/
// -> sudo chown -R hadoop:hadoop /opt/hadoop
[配置]
: 01 配置环境
// vim /etc/profile (source /etc/profile)
export HADOOP_HOME=/opt/hadoop/hadoop-2.10.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
: 配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh
-> JAVA_HOME 参数配置
vim ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/hadoop/jdk1.8.0_211
: 配置 vim ${HADOOP_HOME}/etc/hadoop/core-site.xml
<!-- fs.defaultFS参数配置的是HDFS的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://local.hadoop.xknower.com:8020</value>
</property>
<!-- hadoop.tmp.dir 配置的是Hadoop临时目录 -->
<!-- mkdir -p /opt/hadoop/data/tmp && chown -R hadoop:hadoop /opt/hadoop/data/tmp -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data/tmp</value>
</property>
: 配置 vim ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
<!-- dfs.replication HDFS存储时的备份数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
[配置 - 格式化 HDFS]
# 格式化是对HDFS这个分布式文件系统中的DataNode进行分块, 统计所有分块后的初始元数据的存储在NameNode中。
: hdfs namenode -format
# 查看格式化后数据
// ll /opt/hadoop/data/tmp/dfs/name/current
-- fsimage*.md5 是校验文件, 用于校验fsimage的完整性
-- seen_txid 是hadoop的版本
-- vession
namespaceID:NameNode的唯一ID
clusterID:集群ID,NameNode和DataNode的集群ID应该一致,表明是一个集群
[启动]
# 启动 NameNode
: sbin/hadoop-daemon.sh start namenode
# 启动 DataNode
: sbin/hadoop-daemon.sh start datanode
# 启动 SecondaryNameNode
: sbin/hadoop-daemon.sh start secondarynamenode
[查看]
: jps
[root@localhost hadoop]# jps
1844 DataNode
2008 Jps
1742 NameNode
1951 SecondaryNameNode
[验证]
# 创建目录
: hdfs dfs -mkdir /demo1
# 上传文件
: hdfs dfs -put ${HADOOP_HOME}/etc/hadoop/core-site.xml /demo1
# 读取文件
: hdfs dfs -cat /demo1/core-site.xml
# 下载文件
: hdfs dfs -get /demo1/core-site.xml
[配置 YARN]
# 默认没有mapred-site.xml文件, 但是有个mapred-site.xml.template配置模板文件
# cp ${HADOOP_HOME}/etc/hadoop/mapred-site.xml.template ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
: vim ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
<!-- 指定mapreduce运行在yarn框架上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
# 配置
: vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
<!-- yarn.nodemanager.aux-services 配置了yarn的默认混洗方式, 选择为mapreduce的默认混洗算法 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- yarn.resourcemanager.hostname 指定了Resourcemanager运行在哪个节点上 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>local.hadoop.xknower.com</value>
</property>
[启动]
# 启动 Resourcemanager
: sbin/yarn-daemon.sh start resourcemanager
# 启动nodemanager
: sbin/yarn-daemon.sh start nodemanager
[检测]
[root@localhost hadoop]# jps
1844 DataNode
2251 ResourceManager
2620 Jps
1742 NameNode
1951 SecondaryNameNode
2511 NodeManager
# YARN WEB管理界面
: http://local.hadoop.xknower.com:8088/
[测试]
# 创建输入目录
: bin/hdfs dfs -mkdir -p /wordcountdemo/input
# 创建原始数据并上传
: /opt/hadoop/data/wc.input
: bin/hdfs dfs -put /opt/hadoop/data/wc.input /wordcountdemo/input
# 运行 WordCount MapReduce Job
: bin/yarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar \
wordcount /wordcountdemo/input /wordcountdemo/output
# 查看输出结果
: bin/hdfs dfs -ls /wordcountdemo/output
: bin/hdfs dfs -cat /wordcountdemo/output/part-r-00000
[停止]
: sbin/hadoop-daemon.sh stop namenode
: sbin/hadoop-daemon.sh stop datanode
: sbin/yarn-daemon.sh stop resourcemanager
: sbin/yarn-daemon.sh stop nodemanager
[开启历史记录服务]
// sbin/mr-jobhistory-daemon.sh start historyserver
// http://local.hadoop.xknower.com:19888/
[开启日志聚集]
: MapReduce是在各个机器上运行的, 在运行过程中产生的日志存在于各个机器上,
为了能够统一查看各个机器的运行日志, 将日志集中存放在HDFS上, 这个过程就是日志聚集。
: vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
<!-- yarn.log-aggregation-enable 是否启用日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- yarn.log-aggregation.retain-seconds 设置日志保留时间, 单位是秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
# 文件分发到其他机器
: scp ${HADOOP_HOME}/etc/hadoop/yarn-site.xml local.hadoop.xknower.com:${HADOOP_HOME}/etc/hadoop/
: scp ${HADOOP_HOME}/etc/hadoop/yarn-site.xml local.hadoop.xknower.com:${HADOOP_HOME}/etc/hadoop/
# 重启 YARN
: sbin/stop-yarn.sh && sbin/start-yarn.sh
# 重启 HistoryServer
: sbin/mr-jobhistory-daemon.sh stop historyserver && sbin/mr-jobhistory-daemon.sh start historyserver
- 格式化
[root@localhost hadoop]# hdfs namenode -format
20/03/24 21:12:52 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = local.hadoop.xknower.com/192.168.10.10
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.10.0
STARTUP_MSG: classpath = /opt/hadoop/hadoop-2.10.0/etc/hadoop:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/hadoop-auth-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jersey-core-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jetty-6.1.26.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-io-2.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jets3t-0.9.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/json-smart-1.3.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/slf4j-api-1.7.25.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/netty-3.10.6.Final.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-lang3-3.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/xmlenc-0.52.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/snappy-java-1.0.5.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/httpclient-4.5.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/curator-framework-2.7.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/servlet-api-2.5.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/avro-1.7.7.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/asm-3.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jcip-annotations-1.0-1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/stax-api-1.0-2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/guava-11.0.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jersey-json-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-compress-1.19.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-lang-2.6.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jersey-server-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/nimbus-jose-jwt-4.41.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-configuration-1.6.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/paranamer-2.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-net-3.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-collections-3.2.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jsr305-3.0.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/hamcrest-core-1.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/activation-1.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jettison-1.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-cli-1.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/stax2-api-3.1.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/junit-4.11.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/httpcore-4.4.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jetty-sslengine-6.1.26.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/curator-client-2.7.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/log4j-1.2.17.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jsch-0.1.54.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-math3-3.1.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/gson-2.2.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/mockito-all-1.8.5.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-codec-1.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/zookeeper-3.4.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-logging-1.1.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jetty-util-6.1.26.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-beanutils-1.9.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/jsp-api-2.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/commons-digester-1.8.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/woodstox-core-5.0.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/lib/hadoop-annotations-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/hadoop-common-2.10.0-tests.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/hadoop-common-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/common/hadoop-nfs-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/xercesImpl-2.12.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/commons-io-2.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/netty-3.10.6.Final.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/okio-1.6.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/xml-apis-1.4.01.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/okhttp-2.7.5.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/asm-3.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/guava-11.0.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jackson-annotations-2.7.8.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/hadoop-hdfs-client-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jackson-core-2.7.8.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jackson-databind-2.7.8.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/htrace-core4-4.1.0-incubating.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-client-2.10.0-tests.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-client-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-2.10.0-tests.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-native-client-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-rbf-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-nfs-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-rbf-2.10.0-tests.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/hdfs/hadoop-hdfs-native-client-2.10.0-tests.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/mssql-jdbc-6.2.1.jre7.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jersey-core-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jetty-6.1.26.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/api-util-1.0.0-M20.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-io-2.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/json-io-2.5.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/guice-3.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/aopalliance-1.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/geronimo-jcache_1.0_spec-1.0-alpha-1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jets3t-0.9.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/json-smart-1.3.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/ehcache-3.3.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/netty-3.10.6.Final.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/java-util-1.9.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/apacheds-i18n-2.0.0-M15.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-lang3-3.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/xmlenc-0.52.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/snappy-java-1.0.5.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/httpclient-4.5.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/fst-2.50.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/curator-framework-2.7.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/servlet-api-2.5.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/curator-recipes-2.7.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/avro-1.7.7.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/asm-3.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jcip-annotations-1.0-1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/guava-11.0.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/java-xmlbuilder-0.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jersey-json-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-compress-1.19.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-lang-2.6.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jersey-server-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/nimbus-jose-jwt-4.41.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-configuration-1.6.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/paranamer-2.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-net-3.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/api-asn1-api-1.0.0-M20.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/javax.inject-1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/metrics-core-3.0.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/activation-1.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jettison-1.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-cli-1.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/stax2-api-3.1.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/httpcore-4.4.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jetty-sslengine-6.1.26.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/curator-client-2.7.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/log4j-1.2.17.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jsch-0.1.54.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jersey-client-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-math3-3.1.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/gson-2.2.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-codec-1.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/zookeeper-3.4.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/htrace-core4-4.1.0-incubating.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/HikariCP-java7-2.4.12.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-beanutils-1.9.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/jsp-api-2.1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/commons-digester-1.8.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/lib/woodstox-core-5.0.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-timeline-pluginstorage-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-common-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-common-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-client-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-tests-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-api-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-registry-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/yarn/hadoop-yarn-server-router-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/guice-3.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/netty-3.10.6.Final.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/snappy-java-1.0.5.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/avro-1.7.7.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/asm-3.2.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/commons-compress-1.19.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/javax.inject-1.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/junit-4.11.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/lib/hadoop-annotations-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.10.0-tests.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.10.0.jar:/opt/hadoop/hadoop-2.10.0/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = ssh://git.corp.linkedin.com:29418/hadoop/hadoop.git -r e2f1f118e465e787d8567dfa6e2f3b72a0eb9194; compiled by 'jhung' on 2019-10-22T19:10Z
STARTUP_MSG: java = 1.8.0_211
************************************************************/
20/03/24 21:12:52 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
20/03/24 21:12:53 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-887e7202-5111-49be-88b9-78a72974ac0d
20/03/24 21:12:53 INFO namenode.FSEditLog: Edit logging is async:true
20/03/24 21:12:53 INFO namenode.FSNamesystem: KeyProvider: null
20/03/24 21:12:53 INFO namenode.FSNamesystem: fsLock is fair: true
20/03/24 21:12:53 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
20/03/24 21:12:54 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
20/03/24 21:12:54 INFO namenode.FSNamesystem: supergroup = supergroup
20/03/24 21:12:54 INFO namenode.FSNamesystem: isPermissionEnabled = true
20/03/24 21:12:54 INFO namenode.FSNamesystem: HA Enabled: false
20/03/24 21:12:54 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling
20/03/24 21:12:54 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000
20/03/24 21:12:54 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
20/03/24 21:12:54 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
20/03/24 21:12:54 INFO blockmanagement.BlockManager: The block deletion will start around 2020 三月 24 21:12:54
20/03/24 21:12:54 INFO util.GSet: Computing capacity for map BlocksMap
20/03/24 21:12:54 INFO util.GSet: VM type = 64-bit
20/03/24 21:12:54 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB
20/03/24 21:12:54 INFO util.GSet: capacity = 2^21 = 2097152 entries
20/03/24 21:12:54 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
20/03/24 21:12:54 WARN conf.Configuration: No unit for dfs.heartbeat.interval(3) assuming SECONDS
20/03/24 21:12:54 WARN conf.Configuration: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
20/03/24 21:12:54 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
20/03/24 21:12:54 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0
20/03/24 21:12:54 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000
20/03/24 21:12:54 INFO blockmanagement.BlockManager: defaultReplication = 1
20/03/24 21:12:54 INFO blockmanagement.BlockManager: maxReplication = 512
20/03/24 21:12:54 INFO blockmanagement.BlockManager: minReplication = 1
20/03/24 21:12:54 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
20/03/24 21:12:54 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
20/03/24 21:12:54 INFO blockmanagement.BlockManager: encryptDataTransfer = false
20/03/24 21:12:54 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
20/03/24 21:12:54 INFO namenode.FSNamesystem: Append Enabled: true
20/03/24 21:12:54 INFO namenode.FSDirectory: GLOBAL serial map: bits=24 maxEntries=16777215
20/03/24 21:12:54 INFO util.GSet: Computing capacity for map INodeMap
20/03/24 21:12:54 INFO util.GSet: VM type = 64-bit
20/03/24 21:12:54 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB
20/03/24 21:12:54 INFO util.GSet: capacity = 2^20 = 1048576 entries
20/03/24 21:12:54 INFO namenode.FSDirectory: ACLs enabled? false
20/03/24 21:12:54 INFO namenode.FSDirectory: XAttrs enabled? true
20/03/24 21:12:54 INFO namenode.NameNode: Caching file names occurring more than 10 times
20/03/24 21:12:54 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: falseskipCaptureAccessTimeOnlyChange: false
20/03/24 21:12:54 INFO util.GSet: Computing capacity for map cachedBlocks
20/03/24 21:12:54 INFO util.GSet: VM type = 64-bit
20/03/24 21:12:54 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB
20/03/24 21:12:54 INFO util.GSet: capacity = 2^18 = 262144 entries
20/03/24 21:12:54 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
20/03/24 21:12:54 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
20/03/24 21:12:54 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
20/03/24 21:12:54 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
20/03/24 21:12:54 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
20/03/24 21:12:54 INFO util.GSet: Computing capacity for map NameNodeRetryCache
20/03/24 21:12:54 INFO util.GSet: VM type = 64-bit
20/03/24 21:12:54 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
20/03/24 21:12:54 INFO util.GSet: capacity = 2^15 = 32768 entries
20/03/24 21:12:54 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1555952358-192.168.10.10-1585055574372
20/03/24 21:12:54 INFO common.Storage: Storage directory /opt/data/tmp/dfs/name has been successfully formatted.
20/03/24 21:12:54 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/data/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
20/03/24 21:12:54 INFO namenode.FSImageFormatProtobuf: Image file /opt/data/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds .
20/03/24 21:12:54 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
20/03/24 21:12:54 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
20/03/24 21:12:54 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at local.hadoop.xknower.com/192.168.10.10
************************************************************/
- 执行结果
[root@localhost hadoop]# yarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar \
> wordcount /wordcountdemo/input /wordcountdemo/output
20/03/24 21:27:44 INFO client.RMProxy: Connecting to ResourceManager at local.hadoop.xknower.com/192.168.10.10:8032
20/03/24 21:27:44 INFO input.FileInputFormat: Total input files to process : 1
20/03/24 21:27:45 INFO mapreduce.JobSubmitter: number of splits:1
20/03/24 21:27:45 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
20/03/24 21:27:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1585056159190_0001
20/03/24 21:27:46 INFO conf.Configuration: resource-types.xml not found
20/03/24 21:27:46 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
20/03/24 21:27:46 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
20/03/24 21:27:46 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
20/03/24 21:27:47 INFO impl.YarnClientImpl: Submitted application application_1585056159190_0001
20/03/24 21:27:47 INFO mapreduce.Job: The url to track the job: http://local.hadoop.xknower.com:8088/proxy/application_1585056159190_0001/
20/03/24 21:27:47 INFO mapreduce.Job: Running job: job_1585056159190_0001
20/03/24 21:27:54 INFO mapreduce.Job: Job job_1585056159190_0001 running in uber mode : false
20/03/24 21:27:54 INFO mapreduce.Job: map 0% reduce 0%
20/03/24 21:27:59 INFO mapreduce.Job: map 100% reduce 0%
20/03/24 21:28:04 INFO mapreduce.Job: map 100% reduce 100%
20/03/24 21:28:06 INFO mapreduce.Job: Job job_1585056159190_0001 completed successfully
20/03/24 21:28:06 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=94
FILE: Number of bytes written=410911
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=201
HDFS: Number of bytes written=60
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3039
Total time spent by all reduces in occupied slots (ms)=2551
Total time spent by all map tasks (ms)=3039
Total time spent by all reduce tasks (ms)=2551
Total vcore-milliseconds taken by all map tasks=3039
Total vcore-milliseconds taken by all reduce tasks=2551
Total megabyte-milliseconds taken by all map tasks=3111936
Total megabyte-milliseconds taken by all reduce tasks=2612224
Map-Reduce Framework
Map input records=4
Map output records=11
Map output bytes=115
Map output materialized bytes=94
Input split bytes=130
Combine input records=11
Combine output records=7
Reduce input groups=7
Reduce shuffle bytes=94
Reduce input records=7
Reduce output records=7
Spilled Records=14
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=140
CPU time spent (ms)=1390
Physical memory (bytes) snapshot=460193792
Virtual memory (bytes) snapshot=4258467840
Total committed heap usage (bytes)=293076992
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=71
File Output Format Counters
Bytes Written=60
安装配置 - 完全分布式安装
[环境配置]
: 01 配置 hostname 和 hosts
// hostname local01.hadoop.xknower.com
// 192.168.101.10 local01.hadoop.xknower.com
:
- 服务器配置规划
| local01.hadoop.xknower.com | local02.hadoop.xknower.com | local03.hadoop.xknower.com |
|---|---|---|
| NameNode | ResourceManage | |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| HistoryServer | SecondaryNameNode |
[安装]
: 01 创建用户
// useradd hadoop && passwd hadoop
: 02 用户分配权限
// vim /etc/sudoers (chmod u+w /etc/sudoers)
root ALL=(ALL) ALL
hadoop ALL=(root) NOPASSWD:ALL
: 03 切换用户
// su - hadoop
: 04 创建安装目录
// mkdir /opt/hadoop
: 05 解压安装包
// tar -zxf /opt/hadoop/hadoop-2.10.0.tar.gz -C /opt/hadoop/
// -> sudo chown -R hadoop:hadoop /opt/hadoop
: 分发到其他两台机器上的方式来安装集群
[设置SSH无密码登录]
# 01 生成密钥对
: ssh-keygen -t rsa
> ~/.ssh (id_rsa.pub , id_rsa)
# 02 分发公钥
: ssh-copy-id local01.hadoop.xknower.com
: ssh-copy-id local02.hadoop.xknower.com
: ssh-copy-id local03.hadoop.xknower.com
# 03 每个主机执行, 密码对生成和公钥分发
[配置]
: 01 配置环境
// vim /etc/profile (source /etc/profile)
export HADOOP_HOME=/opt/hadoop/hadoop-2.10.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
: 配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh
-> JAVA_HOME 参数配置
vim ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/hadoop/jdk1.8.0_211
: 配置 vim ${HADOOP_HOME}/etc/hadoop/core-site.xml
<!-- fs.defaultFS参数配置的是HDFS的地址, NameNode 地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://local01.hadoop.xknower.com:8020</value>
</property>
<!-- hadoop.tmp.dir 配置的是Hadoop临时目录 -->
<!-- 默认情况下, NameNode和DataNode的数据文件都会存在这个目录下的对应子目录下 -->
<!-- mkdir -p /opt/hadoop/data/tmp && chown -R hadoop:hadoop /opt/hadoop/data/tmp -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data/tmp</value>
</property>
: 配置 vim ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
<!-- dfs.replication HDFS存储时的备份数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
: vim ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
<!-- dfs.namenode.secondary.http-address 指定secondaryNameNode的http访问地址和端口号 -->
<!-- SecondaryNameNode -> local03.hadoop.xknower.com -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>local03.hadoop.xknower.com:50090</value>
</property>
: 配置 slaves -> vim ${HADOOP_HOME}/etc/hadoop/slaves
// slaves 文件是指定HDFS上有哪些DataNode节点
local01.hadoop.xknower.com
local02.hadoop.xknower.com
local03.hadoop.xknower.com
: yarn-site.xml -> vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
<!-- -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- yarn.resourcemanager.hostname 指定ResourceManage服务器 -->
<!-- ResourceManage -> local02.hadoop.xknower.com -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>local02.hadoop.xknower.com</value>
</property>
<!-- yarn.log-aggregation-enable 是否启用日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- yarn.log-aggregation.retain-seconds 配置聚集的日志在HDFS上最多保存多长时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
: mapred-site.xml
> cp ${HADOOP_HOME}/etc/hadoop/mapred-site.xml.template ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
> vim ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
<!-- mapreduce.framework.name 设置mapreduce任务运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- mapreduce.jobhistory.address 设置mapreduce的历史服务器安装的机器上 -->
<!-- HistoryServer -> local01.hadoop.xknower.com -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>local01.hadoop.xknower.com:10020</value>
</property>
<!-- mapreduce.jobhistory.webapp.address 设置历史服务器的web页面地址和端口号 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>local01.hadoop.xknower.com:19888</value>
</property>
[分发Hadoop文件]
: 01 创建安装目录并配置 HADOOP_HOME
: 02 删除, 文档目录
> du -sh ${HADOOP_HOME}/share/doc
> rm -rf
> scp -r ${HADOOP_HOME}/ local02.hadoop.xknower.com:${HADOOP_HOME}/
> scp -r ${HADOOP_HOME}/ local03.hadoop.xknower.com:${HADOOP_HOME}/
[NameNode 格式化]
# NameNode机器上执行格式化
# 重新格式化NameNode, 需要先将原来NameNode和DataNode下的文件全部删除, 不然会报错
// NameNode和DataNode所在目录是在
// core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的
: hdfs namenode –format
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
[启动集群]
# 启动 HDFS
: sbin/start-dfs.sh
# 启动 YARN
: sbin/start-yarn.sh
# 启动 ResourceManager (ResourceManager 服务器)
: sbin/yarn-daemon.sh start resourcemanage
# 启动日志服务器 (HistoryServer 服务器)
: sbin/mr-jobhistory-daemon.sh start historyserver
[]
# HDFS Web
: http://bigdata-senior01.chybinmy.com:50070/
# YARN Web
: http://bigdata-senior02.chybinmy.com:8088/cluster
[测试Job]
# 测试数据
: cat /opt/data/wc.input
hadoop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop
# 创建输入目录 input
: hdfs dfs -mkdir /input
# wc.input上传到HDFS
: hdfs dfs -put /opt/data/wc.input /input/wc.input
# 执行任务
: yarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar \
wordcount /input/wc.input /output
# 查看输出结果
: hdfs dfs -ls /output
安装配置 - HA 安装
[]
: HA的意思是 High Availability高可用,
// 指当当前工作中的机器宕机后, 会自动处理这个异常, 并将工作无缝地转移到其他备用机器上去, 以来保证服务的高可用。
// HA方式安装部署才是最常见的生产环境上的安装部署方式
: Hadoop HA是Hadoop 2.x中新添加的特性, 包括NameNode HA 和 ResourceManager HA
// 因为DataNode和NodeManager本身就是被设计为高可用的, 所以不用对他们进行特殊的高可用处理。
[时间服务器搭建 NTP服务器]
: 集群中各个机器的时间同步要求比较高, 要求各个机器的系统时间不能相差太多
# 检查ntp服务是否已经安装
: sudo rpm -qa | grep ntp
> ntpdate-4.2.6p5-1.el6.centos.x86_64 用来和某台服务器进行同步的
> ntp-4.2.6p5-1.el6.centos.x86_64 用来提供时间同步服务的
: vim /etc/ntp.conf
> 启用restrice, 修改网段, 注释 并且将网段改为集群的网段,我们这里是100网段
> restrict 192.168.100.0 mask 255.255.255.0 nomodify notrap
> 注释掉server域名配置, 时间服务器的域名,这里不需要连接互联网,所以将他们注释掉
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
> server 127.127.1.0
> fudge 127.127.1.0 stratum 10
: vim /etc/sysconfig/ntpd
> SYNC_CLOCK=yes
# 启动 NTP
: chkconfig ntpd on
# 配置其他机器的同步
: crontab -e
# 查看服务器时间
: date "+%Y-%m-%d %H:%M:%S"
(date -s '2016-01-01 00:00:00' 修改时间)
- HA 架构图
| bigdata-senior01.chybinmy.com | bigdata-senior01.chybinmy.com | bigdata-senior01.chybinmy.com |
|---|---|---|
| NameNode | NameNode | |
| Zookeeper | Zookeeper | Zookeeper |
| DataNode | DataNode | DataNode |
| ResourceManage | ResourceManage | |
| NodeManager | NodeManager | NodeManager |
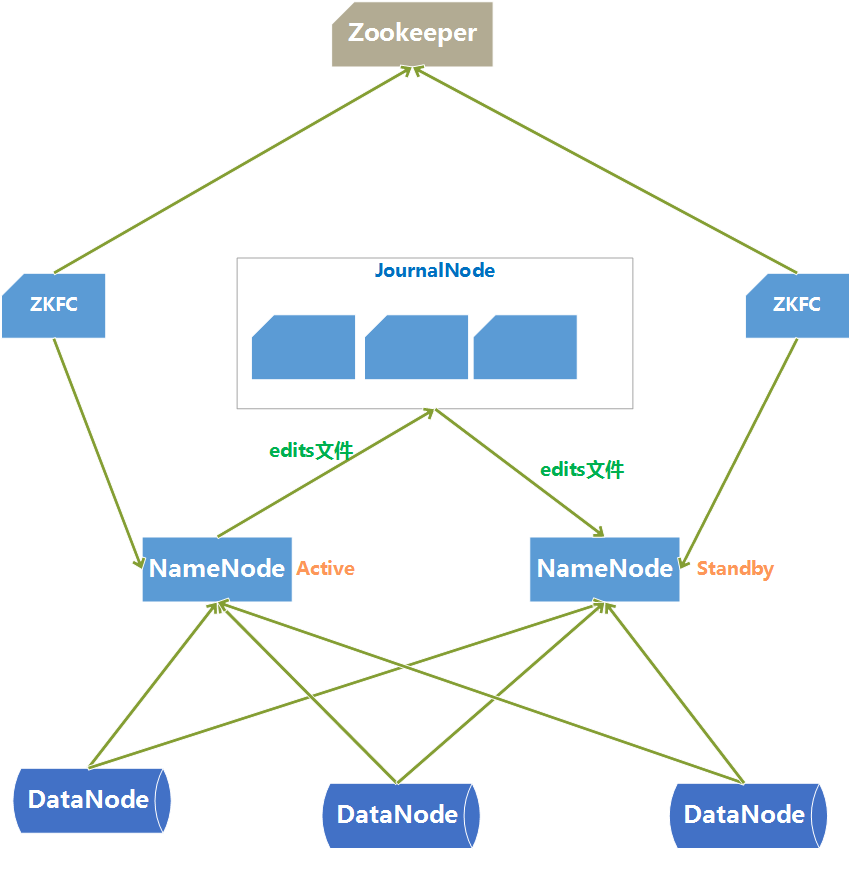
HDFS HA架构中有两台NameNode节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
元数据文件有两个文件:fsimage和edits,备份元数据就是备份这两个文件。JournalNode用来实时从Active NameNode上拷贝edits文件,JournalNode有三台也是为了实现高可用。
Standby NameNode不对外提供元数据的访问,它从Active NameNode上拷贝fsimage文件,从JournalNode上拷贝edits文件,然后负责合并fsimage和edits文件,相当于SecondaryNameNode的作用。最终目的是保证Standby NameNode上的元数据信息和Active NameNode上的元数据信息一致,以实现热备份。
Zookeeper来保证在Active NameNode失效时及时将Standby NameNode修改为Active状态。
ZKFC(失效检测控制)是Hadoop里的一个Zookeeper客户端,在每一个NameNode节点上都启动一个ZKFC进程,来监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群,其实就是在Zookeeper上创建了一个Znode节点,节点里保存了NameNode状态信息。当NameNode失效后,ZKFC检测到报告给Zookeeper,Zookeeper把对应的Znode删除掉,Standby ZKFC发现没有Active状态的NameNode时,就会用shell命令将自己监控的NameNode改为Active状态,并修改Znode上的数据。 Znode是个临时的节点,临时节点特征是客户端的连接断了后就会把znode删除,所以当ZKFC失效时,也会导致切换NameNode。
DataNode会将心跳信息和Block汇报信息同时发给两台NameNode,DataNode只接受Active NameNode发来的文件读写操作指令。
HDFS 命令
[root@localhost hadoop]# hdfs -h
Usage: hdfs [--config confdir] [--loglevel loglevel] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
classpath prints the classpath
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
datanode run a DFS datanode
debug run a Debug Admin to execute HDFS debug commands
dfsadmin run a DFS admin client
dfsrouter run the DFS router
dfsrouteradmin manage Router-based federation
haadmin run a DFS HA admin client
fsck run a DFS filesystem checking utility
balancer run a cluster balancing utility
jmxget get JMX exported values from NameNode or DataNode.
mover run a utility to move block replicas across
storage types
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to an legacy fsimage
oev apply the offline edits viewer to an edits file
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options
portmap run a portmap service
nfs3 run an NFS version 3 gateway
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
storagepolicies list/get/set block storage policies
version print the version
-- 查看版本
[root@localhost hadoop]# hdfs version
Hadoop 2.10.0
Subversion ssh://git.corp.linkedin.com:29418/hadoop/hadoop.git -r e2f1f118e465e787d8567dfa6e2f3b72a0eb9194
Compiled by jhung on 2019-10-22T19:10Z
Compiled with protoc 2.5.0
From source with checksum 7b2d8877c5ce8c9a2cca5c7e81aa4026
This command was run using /opt/hadoop/hadoop-2.10.0/share/hadoop/common/hadoop-common-2.10.0.jar
Zookeeper 分布式机器部署
[安装]
# 解压安装
: tar -zxf /opt/sofeware/zookeeper-3.4.8.tar.gz -C /opt/modules/
# zoo.cfg 配置
: cp conf/zoo_sample.cfg conf/zoo.cfg 配置
# 数据文件存放的目录
> dataDir=/opt/modules/zookeeper-3.4.8/data/zData
# 指定zookeeper集群中各个机器的信息
// server后面的数字范围是1到255, 所以一个zookeeper集群最多可以有255个机器
> server.1=bigdata-senior01.chybinmy.com:2888:3888
> server.2=bigdata-senior02.chybinmy.com:2888:3888
> server.3=bigdata-senior03.chybinmy.com:2888:3888
# myid 文件 (DataDir所指定的目录下创一个名为myid的文件)
> 文件内容为server点后面的数字, 每个机器对应一个数字
[启动]
# 集群中每个服务器分别启动
: zkServer.sh start
[zookeeper 命令]
: bin/zkCli.sh


若有收获,就点个赞吧
0 人点赞
