[特征]容量 (Volume) : 数据的大小决定所考虑的数据的价值和潜在的信息种类 (Variety) : 数据类型的多样性速度 (Velocity) : 指获得数据的速度可变性 (Variability) : 妨碍了处理和有效地管理数据的过程真实性 (Veracity) : 数据的质量复杂性 (Complexity): 数据量巨大,来源多渠道价值 (value) : 合理运用大数据,以低成本创造高价值。
Big Data,大数据,IT行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。
大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘。但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
适用于大数据的技术,包括大规模并行处理(MPP)数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统。
大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分。
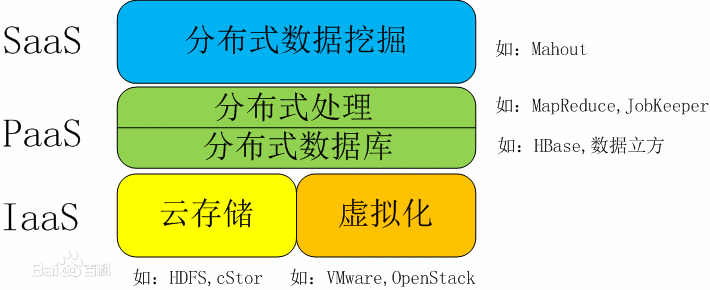
大数据架构
[解决方案]
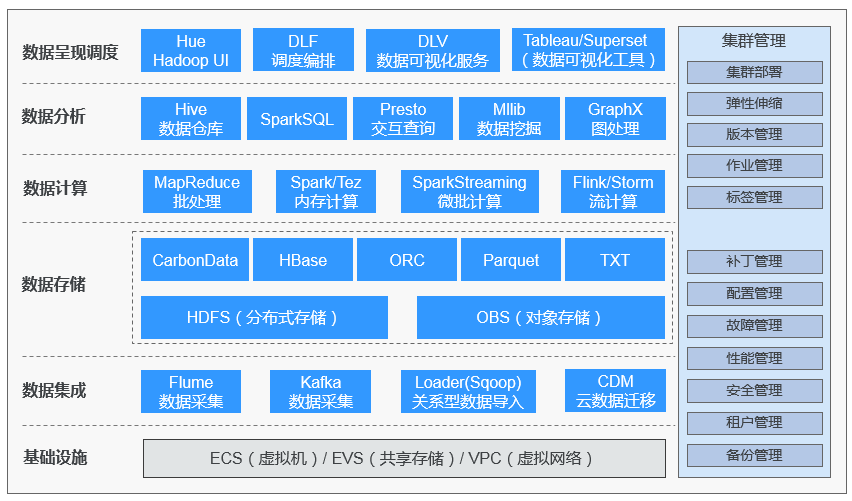
# Hadoop大数据处理的开源解决方案
# 华为大数据架构 <MRS , MapReduce Service>
: https://support.huaweicloud.com/mrs/index.html
: 基础设施
// 虚拟私有云 VPC
// 云硬盘 EVS
// 弹性云服务器 ECS
: 数据集成层
// Flume 数据采集
// Loader 关系型数据导入
// Kafka 高可靠消息队列
: 数据存储
// HDFS 分布式文件系统
// OBS 对象存储服务
// HBase 支持带索引的数据存储,适合高性能基于索引查询的场景
: 数据计算
// MapReduce(批处理)
// Tez(DAG模型)
// Spark(内存计算)
// SparkStreaming(微批流计算)
// Storm(流计算)
// Flink(流计算)
: 数据分析
// Hive(数据仓库)
// SparkSQL以及Presto交互式查询引擎
: 数据呈现调度
// 数据湖工厂(DLF)
: 集群管理
//
// Hadoop、Spark、HBase、Kafka、Storm、SparkSQL、Hive、Hue、CarbonData、Flume、Loader
、Presto、OpenTSDB、Flink、Impala、Kudu、Alluxio、Ranger、
Hadoop
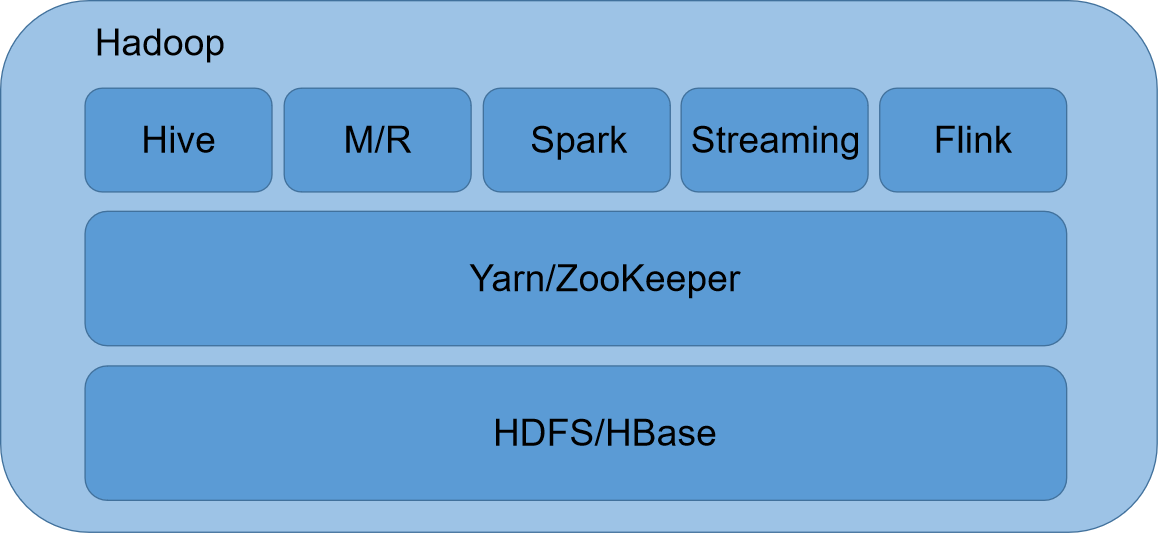
Hadoop是一个开源分布式计算平台,可以充分利用集群的计算和存储能力,完成海量数据的处理。企业自行部署Hadoop系统有成本高,周期长,难运维和不灵活等问题。

若有收获,就点个赞吧
0 人点赞
