审题
无外乎两大类:实现原理、工作方式?
更加细化的问题:原理是什么?代码组织方式是什么?设计模式是什么?某个功能是如何实现的?等等。
实现原理:由外到内。每个库的根本原理都是跳出自身生态以外的,然后回到库本身,梳理内部实践方案。
工作方式:从整体到局部(俯瞰整个技术栈)。包含整体设计模式、关机模块(官网常用模块)的实现方案。
破题
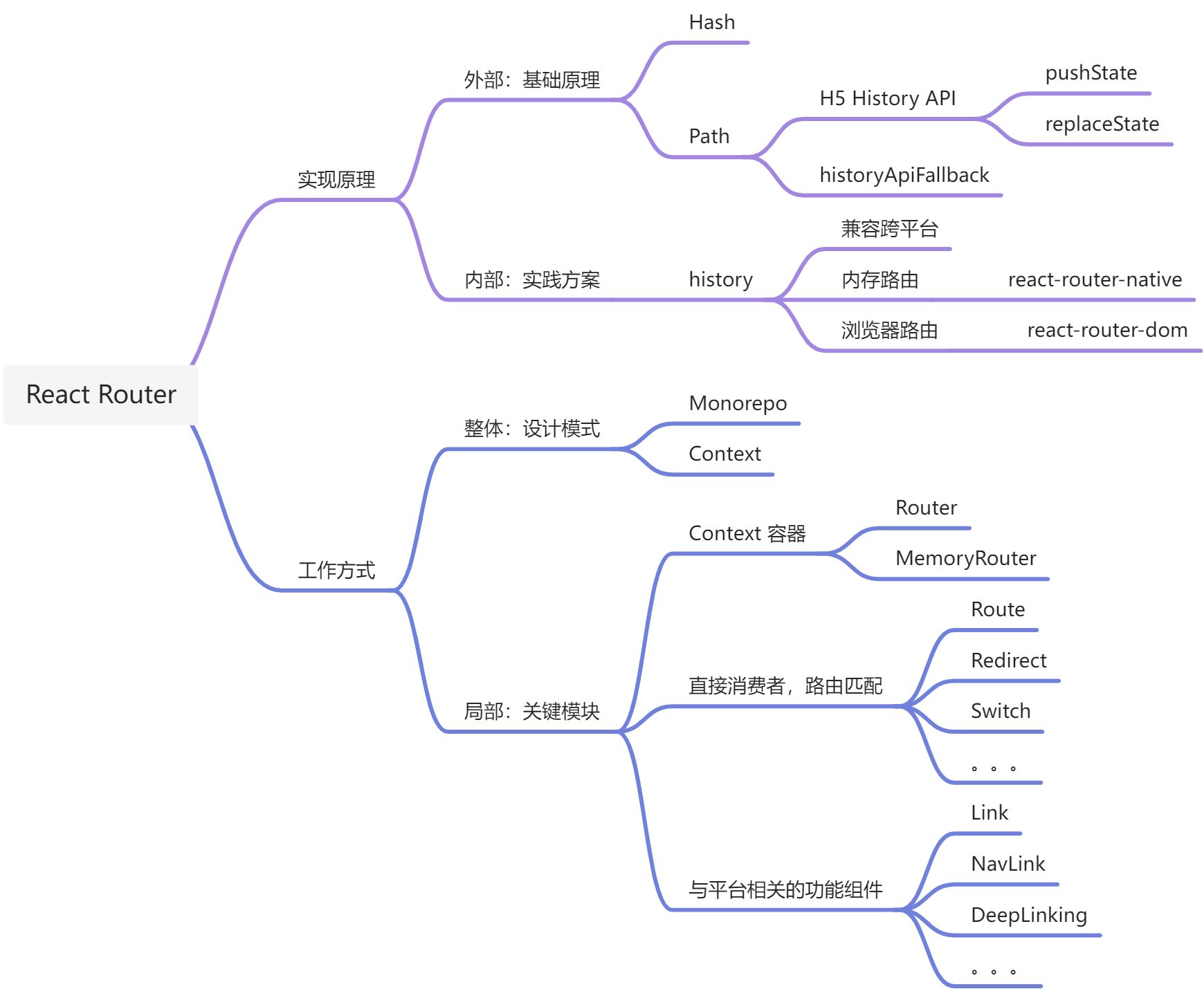
实现原理
基础原理
现在 SPA ,路由完全由前端开发者在网页层自行控制。
前端路由的 4 次变化:
- 起初,路由完全由后端控制,前端通过模板插入后端语言变量完成开发。如 JAVA 中的 JSP,前后混淆。
- AJAX 技术,前后端分离,多个 HTML 页面,并由 Nginx 等静态文件服务完成托管。缺点:各自维护各自资源文件,工程复用难度大。
- JS 成为前端开发主角。HTML,CSS ,路由都可通过 JS 来控制,此阶段,最具代表性的技术栈是 AngularJS,路由使用 Hash 路由。
- H5 中的 History pushState ,前端路由进一步变化,可直接写路径,不用
#a这样写 Hash 路由了。
问:为什么 History pushState 可办到呢?分为两部分
第一部分:在浏览器完成,H5 引入 history.pushState()和history.replaceState()两个函数。它们在浏览器的表现行为是:
history.pushState():修改当前浏览器地址栏中的网址路径;history.replaceState():替换网址路径。
使用这两个 API 时,网页并不会刷新,只是修改网址,当用户刷新页面时,才会重新拉取。
注意:http://idspring.cn指向 index.html,那http://idspring.cn/a也需指向 index.html ,此时就需在服务端配置完成。
第二部分:服务端修改配置,被称为:historyApiFallback。如 webpack 中通过 historyApiFallback 将 404 请求响应到 index.html 。同理可通过 Nginx 或 Node 配置 historyApiFallback ,来达到同样效果。
实践方案
React Router 内有三个库:react-router,react-router-dom,react-router-native。
react-router-dom = react-router + DOM UI
react-router-native = react-router + native UI
DOM 版本与 Native 版本最大限度复用了同一个底层路由逻辑。
DOM 版本提供的基础路由是:BrowserRouter,源码如下:
import { Router } from "react-router";import { createBrowserHistory as createHistory } from "history"; // 重点class BrowserRouter extends React.Component {history = createHistory(this.props);render() {return <Router history={this.history} children={this.props.children} />;}}
解析:在 render部分,使用了 react-router 中的 Router 组件,history属性赋值了 createBrowserHistory生成的变量。
React Router 中路由通过 抽象 history 库统一管理完成,history 库支持 BrowserHistory 和 MemoryHistory 两种类型。
工作方式
设计模式
Monorepo:一个仓库可用多个子工程。工程代码对团队中的每一个人 具备透明度,在同一次迭代中,库之间相互引用代码更为容易。常用:Lerna 作为开发管理 Monorepo 的开发工具,如:Babel,React,umi,React Router 等。
Multirepo:一个仓库对应一个工程,子团队自行维护。
Context:
第二个设计模式是使用 Context 完成数据共享。可自行阅读下 packages/react-router/modules/RouterContext.js、packages/react-router/modules/Router.js 文件。除此以外再阅读下 packages/react-router/modules/withRouter.js 的源码。
关键模块
分类,将 React Router 的组件分为 3 类:
- Context 容器,分别是 Rotuer ,MemoryRouter,主要提供上下文消费容器;
- 直接消费者,提供路由匹配功能,分别是:Route,Redirect,Switch;
与平台相关联的组件,分别是:react-router-dom 中的 Link,NavLink;react-router-native 中的 DeepLinking。
答题
React Router 路由的基础实现原理分为两种:
若是切换 Hash 方式,依靠浏览器 Hash 变化即可;
- 若是切换网址中的 Path,就需用到 H5 History API 中的
pushState,replaceState,这种方式需在服务端完成 historyApiFallback 配置。
在 React Router 内部主要依赖 history 库完成,这是 React Router 自己封装的库,为了实现跨平台运行的特性,内部提供两套基础 history,一套是使用浏览器的 History API,用于支持 react-router-dom;另一套是内存实现版本,一个数组,用于支持 react-router-native。
React Router 在工作方式分为:设计模式、关键模块。
- 设计模式:采用 Monorepo 架构进行库管理。此架构具有团队间透明,迭代遍历优点。整体通信上采用 ContextAPI 完成上下文传递。
- 关键模块,主要分为 3 类组件:
1. Context 容器,如:Router 与 MemoryRouter;
2. 消费者组件,用以匹配路由,主要有 Route,Redirect,Switch 等;
3. 与平台相关联功能组件,主要有 Link,NavLink,DeepLinking 等。
掌握:学习源码技巧。

若有收获,就点个赞吧
0 人点赞
