本文算是一个使用深度学习进行音频分类的入门,提供从读入 .wav 音频文件到将数据处理成输入模型的张量形式。主要依次包含以下内容:
- 读入音频与音频的时域表示
- 音频采样与预处理
- 音频的频域表示与傅里叶变换(Fourier Transform)
- 频谱图与 Mel 谱图
- MFCC 的计算
本文主要是对该博客的翻译与复现,同时展开一些细节并加入我在入门过程中遇到问题的解答。
更重要的是,整个计算 MFCC 的过程,不仅仅是为了计算 MFCC,更重要的是在整个流程中熟悉音频处理常见的概念与定义(时域、频谱图、Mel 刻度、傅里叶变换等),掌握处理音频典型的流程等。
1 读取音频文件
这里需要自己准备一个 .wav 格式的音频文件,我准备了一个叫 ale-400.wav 的。
import numpy as npimport scipy.io.wavfilefrom scipy.fftpack import dctfrom matplotlib import pyplot as plt%matplotlib inlinesample_rate, signal = scipy.io.wavfile.read('./cis-12.wav') # File assumed to be in the save directorysignal = signal[0: int(3.5 * sample_rate)] # Keep the first 3.5 secondsprint(f"signal shape: {signal.shape}")plt.xlabel('Frame')plt.ylabel('Amptitude')plt.plot(range(int(3.5 * sample_rate)), signal, 'b-', label='cis-12.wav')plt.legend(loc='upper right')
Out:signal shape: (33600,)
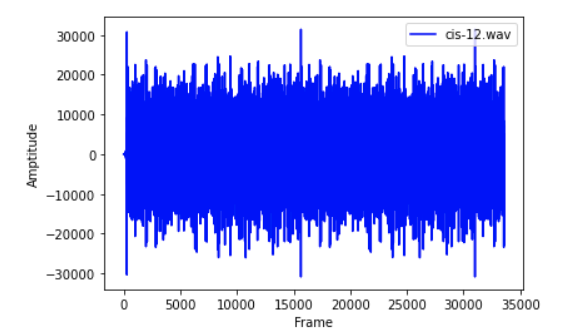
信号的时域图像
上图即为音频的时域图,横轴为时间,纵轴为声波震动的幅值(气体压强)。
2 Pre-Emphasis 预增强
接下来对读取到的音频文件进行处理。第一步是使用 pre-emphasis 过滤器增强信号的高频成分,有如下原因:
- 平衡频谱图中的高频成分。因为高频信号的幅值通常比低频成分的要小。
- 避免在进行傅里叶变换的时候遇到数值问题。
- 有可能提高有效信号与噪音信号的比例。
Pre-emphasis 过滤器可以使用一阶过滤器的形式实现:
过滤系数  一般取 0.95 或 0.97,可以使用下面这一行代码完成(
一般取 0.95 或 0.97,可以使用下面这一行代码完成(pre_emphasis=0.97):
pre_emphasis = 0.97emphasized_signal = np.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
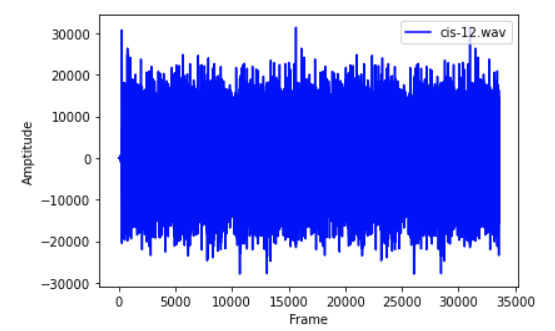
预增强后的时域信号
3 分帧
经过了 pre-emphasis,接下来我们要将信号截成时间更短的帧。这么做的原因是,信号中频率的成分是随着时间而变化的,所以大多数情况下我们不能直接的将一整段音频直接做傅里叶变换,那样就会丧失频率随时间变化的边缘(we would lose the frequency contours of the signal over time)。而如果我们进行分帧,就可以通过将相邻帧拼接起来,最终获取频率随时间变化的边缘。
一般截取的每一帧长度为 20 ms 到 40 ms,相邻帧之间重叠 50%(+/-10%)。比较常用的参数为每一帧 25 ms,步长为 10 ms,也就意味着相邻帧之间重叠 15 ms。
frame_size, frame_stride = 0.025, 0.01frame_length, frame_step = frame_size * sample_rate, frame_stride * sample_ratesignal_length = len(emphasized_signal)frame_length = int(round(frame_length))frame_step = int(round(frame_step))# Make sure that we have at least 1 framenum_frames = int(np.ceil(float(np.abs(signal_length - frame_length)) / frame_step))# Pad signal to make sure that all frames have equal number of samplespad_signal_length = num_frames * frame_step + frame_lengthz = np.zeros((pad_signal_length - signal_length))pad_signal = np.append(emphasized_signal, z)indices = np.tile(np.arange(0, frame_length), (num_frames, 1))indices += np.tile(np.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).Tframes = pad_signal[indices.astype(np.int32, copy=False)]
4 加窗
接下来需要对每一帧加一个窗口函数(如 Hamming window)。Hamming 窗口的公式如下:
其中  , 是窗口的长度,也即每一帧的长度。窗口函数的图像如下:
, 是窗口的长度,也即每一帧的长度。窗口函数的图像如下: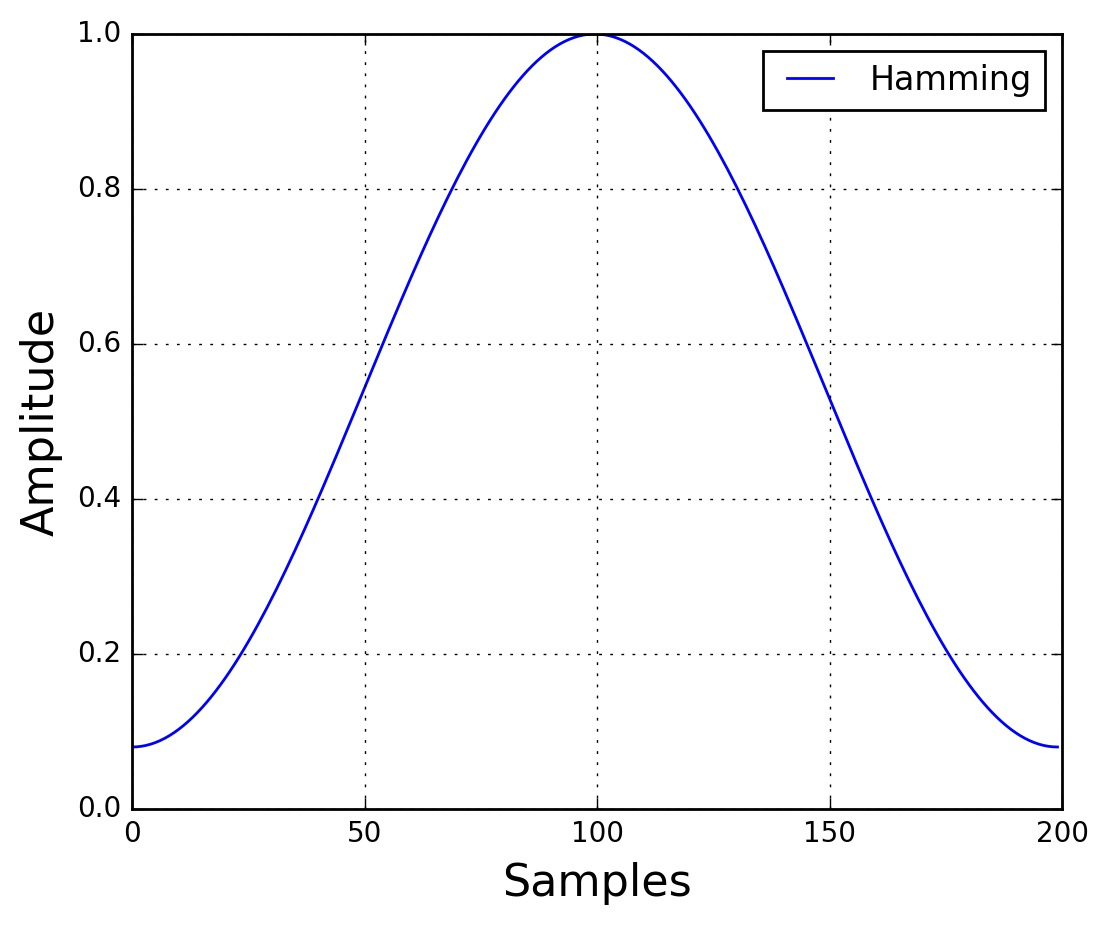
Hamming Window
具体代码实现如下:
frames *= np.hamming(frame_length)# frames *= 0.54 - 0.46 * np.cos((2 * np.pi * n) / (frame_length - 1))
5 傅里叶变换与功率谱图
现在就可以对每一帧做一个 点快速傅里叶变化( -point FFT),以此计算频谱图,这也叫短时傅里叶变换(Short-Time Fourier-Transform, STFT),一般
-point FFT),以此计算频谱图,这也叫短时傅里叶变换(Short-Time Fourier-Transform, STFT),一般  取 256 或 512。然后就是计算功率谱图,按照如下的计算公式:
取 256 或 512。然后就是计算功率谱图,按照如下的计算公式:
n_fft = 512mag_frames = np.abs(np.fft.rfft(frames, n_fft)) # Magnitude of the FFTpow_frames = ((1.0 / n_fft) * ((mag_frames ** 2))) # Power Spectrum
关于傅里叶变换机器变体,下面给出本人学习过程中参考的资料,建议按照顺序学习!
此时得到的功率普图,其实就是一种频谱图,它的 轴代表每一帧, 轴代表每一帧经过傅里叶变换得到的多个频率,不同颜色代表震动幅度大小。
import librosaspec = librosa.power_to_db(pow_frames, ref=np.max) # Convert power to dBplt.imshow(spec)plt.ylabel('Frequency Bin')plt.xlabel('Frames')plt.colorbar(format='%+2.0f dB')plt.title('Spectrogram')
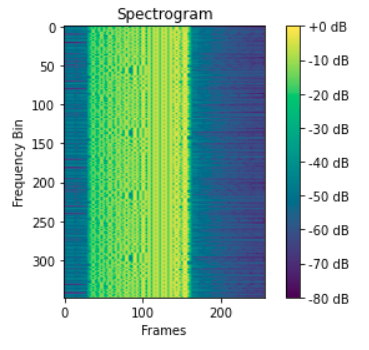
频谱图
通过对图像的每一列以及每一行进行观察,能发现一些有意思的东西。
6 梅尔过滤器组
Mel 刻度在之前的入门文章中已经讲过了,这里之说说过滤器组(filter banks)。一般我们使用 40 个 Mel 过滤器组成一个过滤器组,将它们应用到功率谱图上提取频率带(frequency bands)。首先放上 Mel 刻度与普通频率刻度的转换公式:
每一个过滤器都是一个三角形的频带,频带的宽度随频率的上升而变大。因为人耳在低频下能够更好地分辨频率的差异,而高频则不敏感。所以在低频部分,滤波器会比较窄,人耳可以清楚地发觉差异,因此在我们的分析中,低频差异要更重要一些。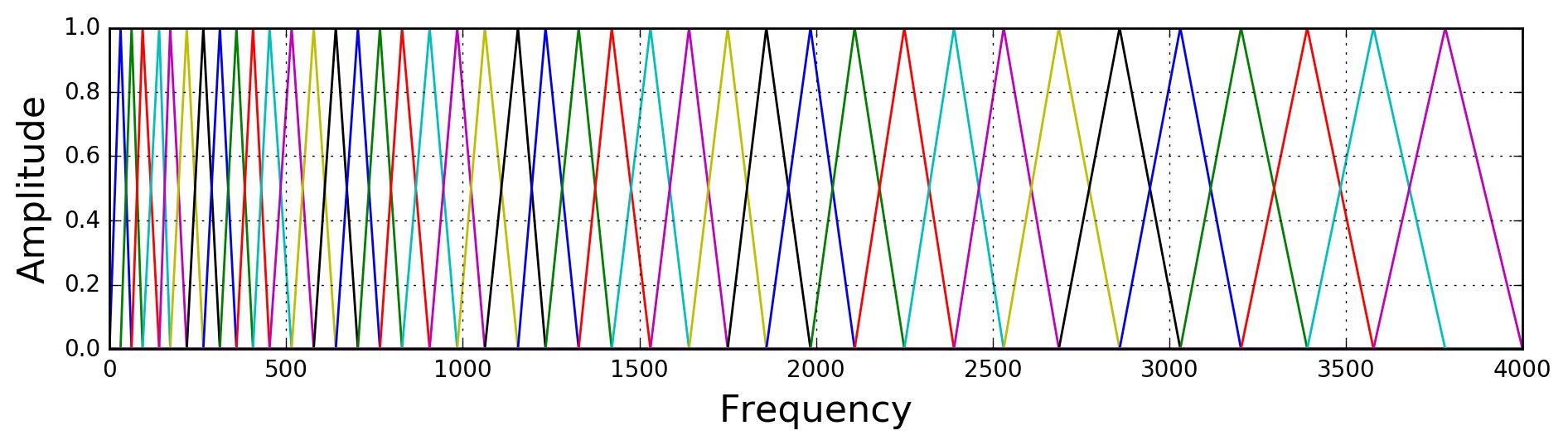
Mel 过滤器组
注意到过滤器的横轴是频率,纵轴是幅值(是 0~1 的),所以过滤器的用法就是将过滤器函数放在功率谱图的每一列上(即每一帧),用过滤器函数乘以该帧每一个频率对应的幅值就可以了。
Mel 过滤器组可以通过如下公式生成(该公式摘自网络):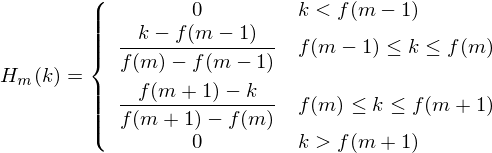
n_filt = 40low_freq_mel = 0high_freq_mel = (2595 * np.log10(1 + (sample_rate / 2) / 700)) # Convert Hz to Melmel_points = np.linspace(low_freq_mel, high_freq_mel, n_filt+2) # Equally spaced in Mel scalehz_points = (700 * (10 ** (mel_points / 2595) - 1)) # Convert Mel to Hzbin = np.floor((n_fft + 1) * hz_points / sample_rate)fbank = np.zeros((n_filt, int(np.floor(n_fft / 2 + 1))))for m in range(1, n_filt + 1):f_m_minus = int(bin[m-1]) # leftf_m = int(bin[m]) # centerf_m_plus = int(bin[m+1]) # rightfor k in range(f_m_minus, f_m):fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])for k in range(f_m, f_m_plus):fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])filter_banks = np.dot(pow_frames, fbank.T)filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks) # Numerical Stabilityfilter_banks = 20 * np.log10(filter_banks) # dB
然后在观察变换后的 Mel 谱图:
plt.imshow(filter_banks.T)plt.xlabel('Frames')plt.ylabel('Frequency Bin')plt.title('Mel-frequency spectrogram')plt.colorbar(format='%+2.0f dB')
Mel 谱图也经常被称为倒谱图,因为 Mel 刻度与正常的频率是近似倒数的关系。
7 MFCCs 梅尔倒频谱系数
Mel-frequency Cepstral Coefficients, MFCCs.
不难发现上一步通过 Mel 过滤器组计算得到的系数有很强的相关性(highly correlated),直观的看就是多个过滤器之间有很大重叠的部分,很强的相关性就会在机器学习算法中造成一些麻烦。所以我们需要使用离散余弦变换(Discrete Cosine Transform, DCT)来消除上述系数的相关性。
一般来收,在音频识别中结果到频谱系数中的 2~13 会被保留,剩下的会被丢弃。丢弃的原因是它们代表过滤器组输出系数中快速变化的部分并且对音频识别没有帮助。
num_ceps = 12mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1:(num_ceps+1)] # Keep 2-13
这样得到的 MFCCs: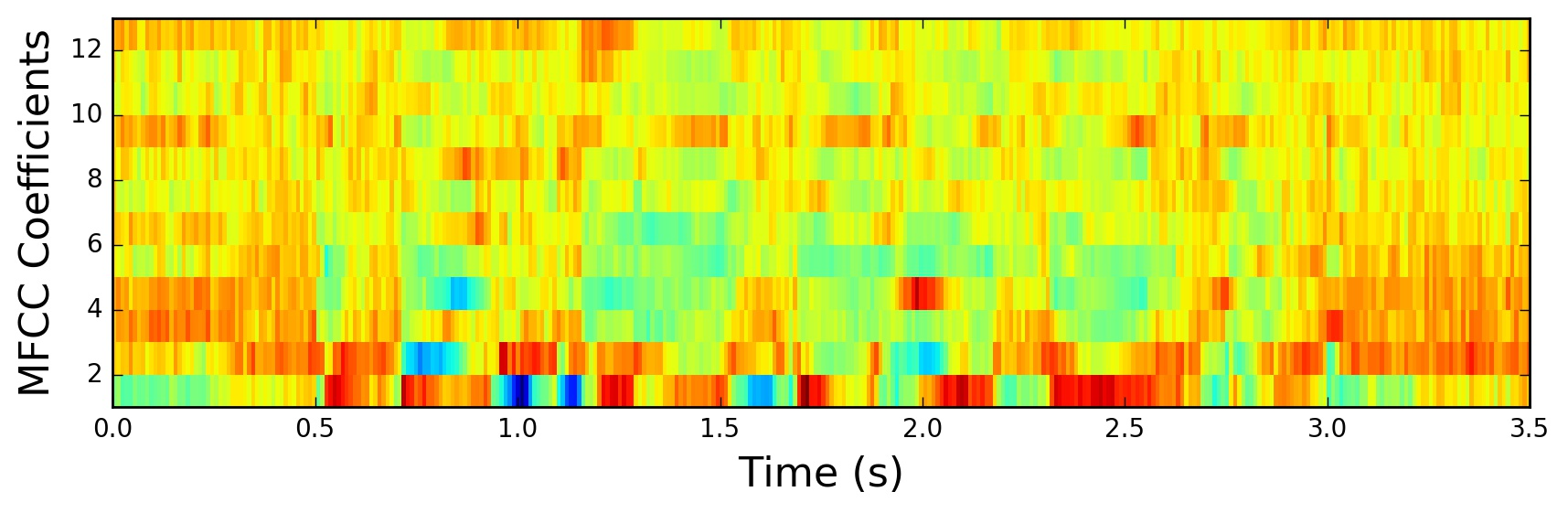
图来源于网络
8 总结
最后得到的 MFCCs 其实就是一张单通道的图像, 可以直接喂给 CNN 之类的分类器。至此音频数据预处理部分就结束啦。

若有收获,就点个赞吧
0 人点赞
