1 Attention 原理及其类别
1.1 Attention 概述
Attention 注意力,字面意思,就是有重点的关注应该关注的东西。在数学里面,我们想让某一个东西 x 的重要性变大(被关注),那就给所有与 x 争宠的玩意都加上一个权重 w ,然后 x 的权重高一点,最后我们做一个加权和就 OK 了。所以重点就是这个权重怎么计算的问题,也就是 Attention 的核心问题。
Attention 中将输入(训练数据)分成了三类:query (Q), key (K), value (V)。query 相当于是目标;key 代表 value 的一个类别,key 的个数也就是所有 value 的种类数;value 就是具体的值,每一个种类 K 下都有很多 value。
在这篇文章中给了一个很形象的比喻:比如我们想在图书馆找一些书(value)来了解有关漫威的知识(query),为此我们首先定位了一些可能类别(key)的书,比如动漫、电影甚至二战(美国队长)。这就构成了三个类别。每一种书我们都可能选了好几本。我们首先会对每一个 key 与 query 的相似度进行度量,相似度高的权重就高,上例中可能动漫和电影的权重(分别 0.4)高一点,二战的权重(0.2)低一点。那么接下来我们就可以挑选书啦:根据上面的权重,我们可以动漫和电影里面各选 40%,而二战的只选 20%,这就把权重分别乘到了对应的 value 上。然后我们会将所有的书都打包带走,结合上面的权重,这就做了一个带权输入和。
所以一般 Attention 分为 3 步: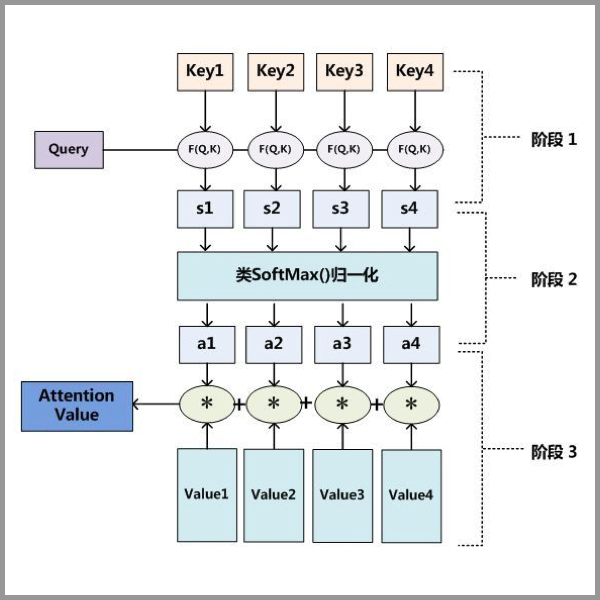
- query 和 key 进行相似度计算,得到权重
- softmax 对权重归一化
- 权重与 value 加权求和
总之就四个字,带权求和。
Attention 分类以及与其他模型结合,主要参考文章并且想深入了解一下原理,这里主要摘了一些常用的 Attention 并记录其实现方式。References 章节里面的东西才是精髓,可视化 + 具体方法。这篇文章对 Attention 的数学原理讲得很形象,容易理解。这里引用文章的图片,将 attention 机制的类别总结的比较全面。
为了充分发挥计算机中向量运算的效率,一般所有的  都会写成矩阵形式进行运算,以上面比较常见的 Dot-Product Attention 为例:
都会写成矩阵形式进行运算,以上面比较常见的 Dot-Product Attention 为例:
1.2 Soft Attention
之前 Encoder-Decoder 模型框架可以这么看:我们的人物是给定输入句子 Source,期望通过这个框架来输出句子 Target。Source 和 Target 可能是同种语言(文章主题提取),也可能是不同语言(翻译)。每一个句子都是有一个个单词构成的:
Encoder 的工作就是将输入的句子(每个单词)经过非线性变换,得到一个定长的代表句子语义的向量  。
。

而 Decoder 的实现方式,基本都是该时刻的输出,由前面时刻所有的输出以及语义向量 来决定。

但这样显然是注意力不集中的分心模型。因为:
不管生成哪一个输出单词,使用的语义信息 都是一样的。 也就是说 Source 中的任意单词,对目标单词的影响力都是一样的。文章中举了一个很恰当的例子,是 Source = “Tom Chases Jerry”,Target = “汤姆追杰瑞”。按道理来说在生成 “汤姆” 的时候,应该 “Tom” 的影响力大于另外两个,而在传统的 Encoder-Decoder 框架中这三个单词对 “汤姆” 的影响力是相同的。所以更好的方法是,针对每一个输出单词  ,我们使用不同的语义向量
,我们使用不同的语义向量  ,也就是使用 Source 中单词施以不同权重的组合来构成针对特定 的语义向量。就变成了下面这种形式:
,也就是使用 Source 中单词施以不同权重的组合来构成针对特定 的语义向量。就变成了下面这种形式:
而针对上面的例子呢,可能就是这样的:
 函数代表 Encoder 对输入单词的某种变换函数,有可能是 RNN 的输出等。而
函数代表 Encoder 对输入单词的某种变换函数,有可能是 RNN 的输出等。而  函数代表 Encoder 根据单词的向量表示来合成整个句子的语义向量,一般来说 都是加权求和。
函数代表 Encoder 根据单词的向量表示来合成整个句子的语义向量,一般来说 都是加权求和。

其中  是句子的长度;
是句子的长度; 是在 Target 输出第
是在 Target 输出第  个单词时,Source 中第
个单词时,Source 中第  个单词的注意力权重;
个单词的注意力权重; 就是单词
就是单词  的向量表示。具体在 RNN 中如何求得上面这个注意力权重,可以如下操作:
的向量表示。具体在 RNN 中如何求得上面这个注意力权重,可以如下操作: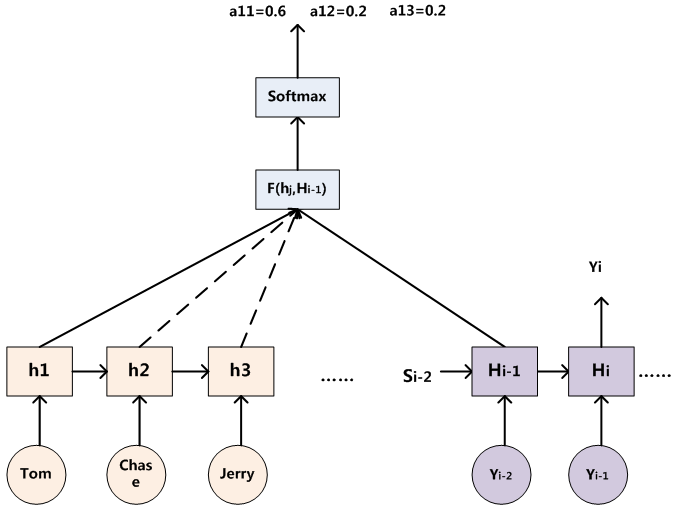
Soft Attention 是 Key = Value 的 Attention 的一种特例。也可以看做一种软寻址。这种 Attention 更像是在做两种语言的单词对齐,比如 “Tom” 和 “汤姆” 对齐。
1.3 Self Attention
Self Attention 呢就更加特例了,它是 Q = K = V 的 Attention。如何理解 Self Attention 到底在提取什么特征呢,它其实可以看做在寻找不同单词所能组成的短语结构后者语义特征。比如下图: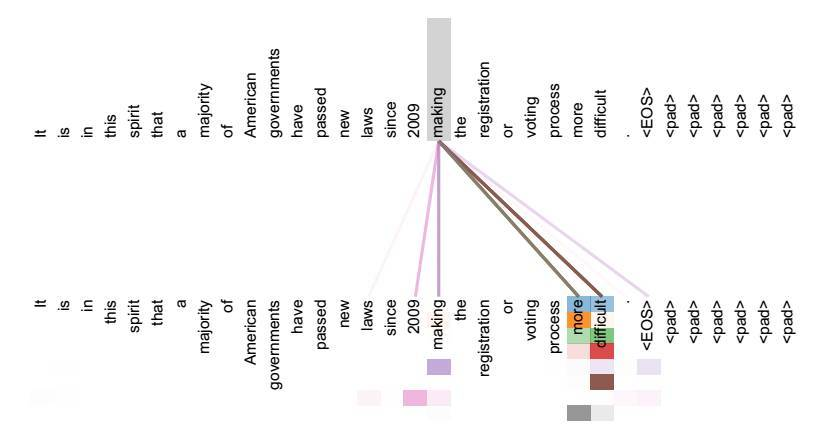
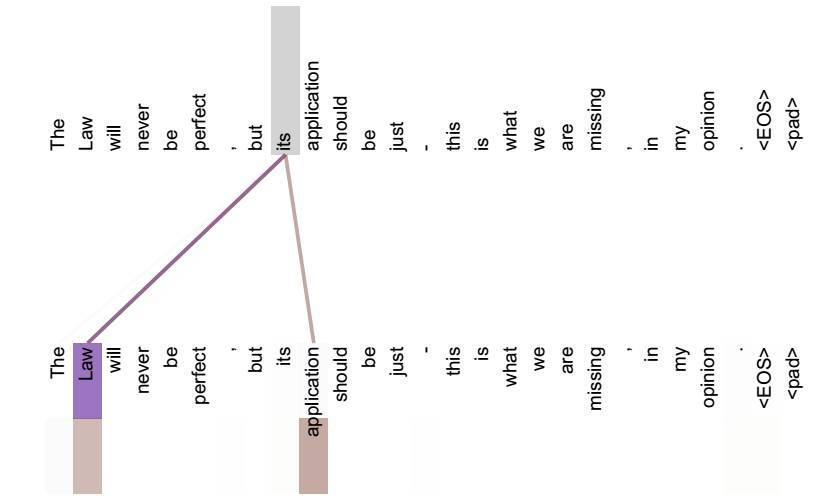
Self Attention 更容易捕获句子中长距离的相互依赖特征,而 RNN 和 LSTM 就不大行。而且 Self Attention 也解决了 RNN 不能并行计算的问题。
2 Attention 应用细节
常见的度量 Q 和 K 相似性的方法:
- 点乘,最简单的方法

- 矩阵相乘:

- cos 相似度:

- 将 q 和 k 简单拼接:

- 多层感知机:

- 点乘,最简单的方法
Attention 应用比较成功的就是现在大火的 Transformer 和 BERT。后面两篇文章会结合 Attention 机制在 Transformer 以及 BERT 中的应用,来看看 Attention 的实践(怎么写代码)。
References
[1]《Seq2seq+Attention 通俗易懂的讲解》
[2]《NLP 中的 Attention 原理和源码解析》
[3]《Attention 用于 NLP 的一些小结》
[4]《一文看懂 Attention 机制》

若有收获,就点个赞吧
0 人点赞
