1 前言
该文档主要依据论文《From Word Embeddings To Document Distance》并参考网上博客与文章,简单概述论文中 WMD 算法的主要思想,实现方式与个人思考。
WMD 算法的全称是 Word Mover’s Distance,即 词移距离,是用来度量两个文本(document)之间距离(相似度的)一种方法。它不像之前看到的 NMF 和 SeaNMF 这种完整的算法模型(Topic Modeling),而只是一种度量文本相似性的方法,一般会在使用该方法得到文本距离后使用 KNN 算法对全体文本(corpus)进行聚类。
既然要度量距离,就需要将文本向量化,论文中首先提到了目前常见的一些方法。
1.1 文本向量化
1.1.1 拉跨兄弟 —- BOW & TF-IDF
词袋模型(BOW, Bag Of Words)和词频-逆文本频率(TF-IDF Term Frequency-Inverse Document Frequency)是常用的两种文本向量化方法;前者就是用单词出现的频次来将其代替,还有一种变种是归一化词袋模型(nBOW, normalized BOW),就是将向量化后的文本向量进行归一化(除以自己向量的二范式长度),后者的公式如下:

其中  表示文本中词
表示文本中词  出现的次数,
出现的次数, 为该文本中词的总数;
为该文本中词的总数; 表示所在语料(corpus)中文档的总数,
表示所在语料(corpus)中文档的总数, 表示词 在多少文档中出现。
表示词 在多少文档中出现。
用这两种方法表示的文本倒是可以计算距离,如欧氏距离和 cosin 距离,但是这俩兄弟存在严重的问题:
- 近似正交性(near-orthogonality)
通常由全体文本构建的 单词表(由独立的去除停止词构成)中的单词数目非常大,这造成了每一个文本向量都是高维的;而通常一个单词不会在很多文本中都出现,这就造成了文本向量是稀疏的,进而文本向量之间是两两近似正交的。
- 无法获取两两单词之间的距离信息
使用上述两种方法进行向量化后的文本,只能计算距离,而无法获得一个文本中某个单词到另一个文本中某个单词的距离(相似性)。论文中举了一个例子:
“Obama speaks to the media in Illinois“
“The President greets the press in Chicago“
我们搭眼一看,就能看出以下单词对 (Obama, President), (speaks, greets), (media, press) 以及 (Illinois, Chicago) 具有很明显的相似性,而在上述两种模型中是无法洞悉的。
1.1.2 扛把子 —- word2vec
word2vec 是词嵌入(word embeddings)中的一个模型,它将文本表示为稠密的向量形式,并且将词义(semantic)相近的单词映射到距离较近的一片区域中,即有效提取了单词的词义信息。它有一个重要的思想是 语义关系可以通过单词向量间的运算来体现(”semantic relationships are often preserved in vector operations on word vectors”)。比如:

2 WMD 算法
WMD 算法的目标是:将单词对(word pairs)的语义相似性(semantic similarity)融入文本距离的计算标准中。
2.1 词移距离(Word travel cost)
在该论文中使用的单词向量间距离度量的方法是在 word2vec 空间下的欧氏距离,即  ,并将这种距离称为一个单词 “移动”(travel)到另一个单词的代价。
,并将这种距离称为一个单词 “移动”(travel)到另一个单词的代价。
2.2 文本间的距离
有了单词之间的距离, WMD 算法提出,两个文本之间的距离是两个文本中每一个单词对之间距离的加权和,即
其中  为单词表中的单词总数,
为单词表中的单词总数, 表示单词
表示单词  到单词
到单词  之间的移动权重,
之间的移动权重, 表示单词 和单词 之间的欧氏距离。这就是
表示单词 和单词 之间的欧氏距离。这就是 WMD 算法计算文本距离的最关键的公式。
先看例子: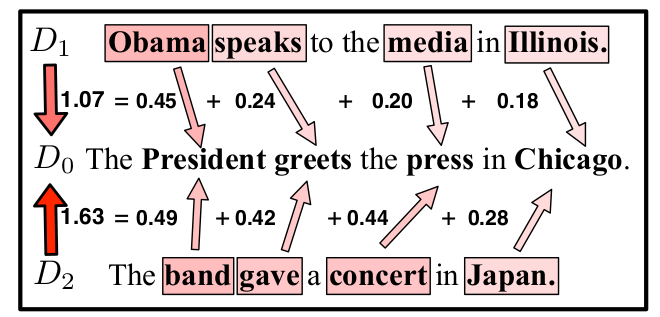
上图清晰的展示了 “文本距离是单词距离导出的” 这一重要算法思想。
但是,上图  和
和  与
与  的非停止词个数是相同的,可以很完美的将一个词映射到另一个词上;如果出现了两个文本非停止词的个数不同的情况(见下图)呢?
的非停止词个数是相同的,可以很完美的将一个词映射到另一个词上;如果出现了两个文本非停止词的个数不同的情况(见下图)呢?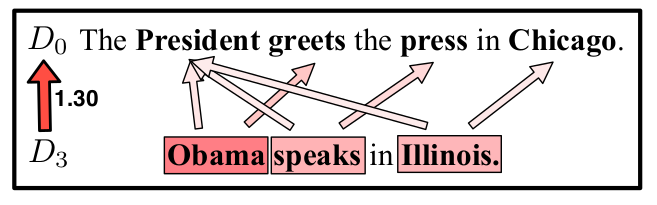
为了解决这个问题,我们可以使得  中的每一个单词都有机会映射到 中,只要赋予他们相应的权重即可。必须单词 Obama 到 President 的权重大一点,到其他单词的权重小一点。
中的每一个单词都有机会映射到 中,只要赋予他们相应的权重即可。必须单词 Obama 到 President 的权重大一点,到其他单词的权重小一点。
当然,为了最终得到的权重不那么离谱,我们需要对权重做一些限制。假设现在我们要计算文本 和  之间的距离,让 的每一个词都移动(travel)到 的每一个单词上。我们需要保证文本 的单词 的所有出度上的权重之和等于单词 在文本 中的权重
之间的距离,让 的每一个词都移动(travel)到 的每一个单词上。我们需要保证文本 的单词 的所有出度上的权重之和等于单词 在文本 中的权重  ,即
,即  ,其中 的计算方法有很多,比如在
,其中 的计算方法有很多,比如在 nBOW 模型下就可以表示为该单词的出现频次除以该文本的总词数。同理,还有一个限制条件就是  。
。
2.3 算法描述
有了上面的文本距离公式以及两个限制条件,我们就可以给出 WMD 算法的数学表达:



该数学模型是 EMD 算法的一个特例,而 EMD 算法的提出是为了解决运输问题(transportation problem),运输问题是线性规划中的一类。通过 EMD 算法,我们就可以在限制条件下的权重矩阵  ,进而求解出两个文档之间的最小累积距离(minumum cumulative cost of moving)。
,进而求解出两个文档之间的最小累积距离(minumum cumulative cost of moving)。
但是通过 EMD 算法的时间复杂度可以推导出, WMD 算法的时间复杂度为  ,其中
,其中  是单词表中的总数。这对于一个比较大的数据集来说,是相当高的复杂度。所以我们需要优化!
是单词表中的总数。这对于一个比较大的数据集来说,是相当高的复杂度。所以我们需要优化!
需要说明的是,
WMD算法只能计算两个文档之间的距离**。**所以一般我们要做的是,先确定一个基准文本(query document)所有文本都要向他看齐,然后使用WMD计算其他若干文本到这个基准文本的距离。
3 优化计算复杂度
既然这么高的算法复杂度是无法接受的,论文的作者提出通过寻找距离下界以缩小数据量(即文本数量)的方法。按常理讲,不应该是寻找距离上界,然后到基准文本的距离大于这个上界的文本会被剔除掉吗?这个跟最后使用 KNN 算法进行聚类有关,留到下面第 4.2 节剪枝中详细说明。
作者提出了两种下界的计算方法,一种是词质心距离(WCD, Word Centroid Distance),另一种是条件宽松的 WMD(Relaxed Word Moving Distance)。
3.1 WCD
词质心距离其实就是对词向量进行加权平均,其定义如下:

至于 WCD 距离是 WMD 距离的下界,具体证明详见论文第 4 页 4.1 节 Word centroid distance。
使用 WCD 来代替 WMD ,得到的时间复杂度为  ,其中 为文本的总数。但
,其中 为文本的总数。但 WCD 这个下界过于宽松,对于限制数据集规模不能起到很好的作用。所以作者又提出了 RWMD 来计算距离。
3.2 RWMD
RWMD 就是通过拿掉两个限制条件中的一个,以到达快速计算的目的。比如拿掉原式中的第二个限制条件,得到
不能同时拿掉两个限制条件,不然会出现
这种下界值
在上面的约束条件下,就可以简单地求出 矩阵,即
这个证明其实也比较简单,在论文的第 4 页右侧。
计算 WCD 的时间复杂度为  ,相比
,相比 WMD 已经快了不少。而且重要的是, WCD 是一个很紧(tight)的下界,它与 WMD 的差距非常小。下图展示了 WMD 、 WCD 以及 RWMD 的对比情况。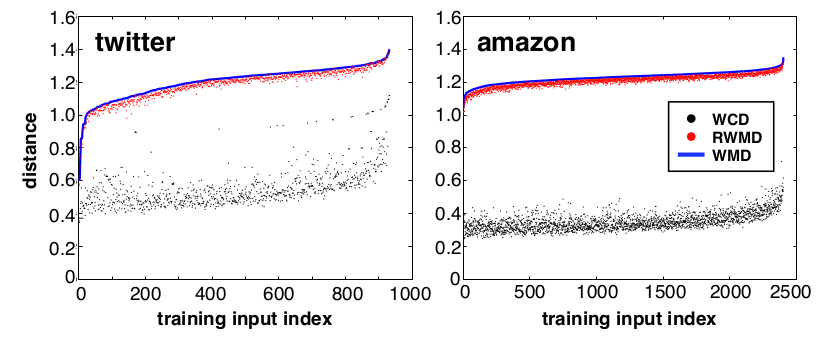
有了上述两个计算下界的方法,我们就可以通过对文本集合进行预处理,筛选一定数量(远小于文本总数)的文本投入 KNN 算法中进行聚类。作者将这种思想称为预取与剪枝(prefetch and prune),同时也通过这个思想给出了完整的 WMD 算法的描述。
4 整体算法
简单而言,完整的 WMD 算法就是首先通过 WCD 和 RWMD 对原始数据集中的文本进行预取和剪枝,然后对筛选出的文本计算 WMD ,最后使用 KNN 算法进行分类。具体算法步骤如下:
4.1 预取(prefetch)
首先计算所有文本(假设全体文本序列为 D ,文本总数为 m )到基准文本(query document)的 WCD ,然后按照从小到大的顺序进行排序。最后选择其中前 k 个(即在 WCD 下距离最近的 k 个)文本,计算他们到基准文本的 WMD 距离。
在这里
k就是K-NN算法中的k的最近的邻居,所以我们将这k个文本组成的数组称为 KNN-Array,简称KArr
所谓预取,就是从 m 个文本中预先取了 k 个作为最初的训练集。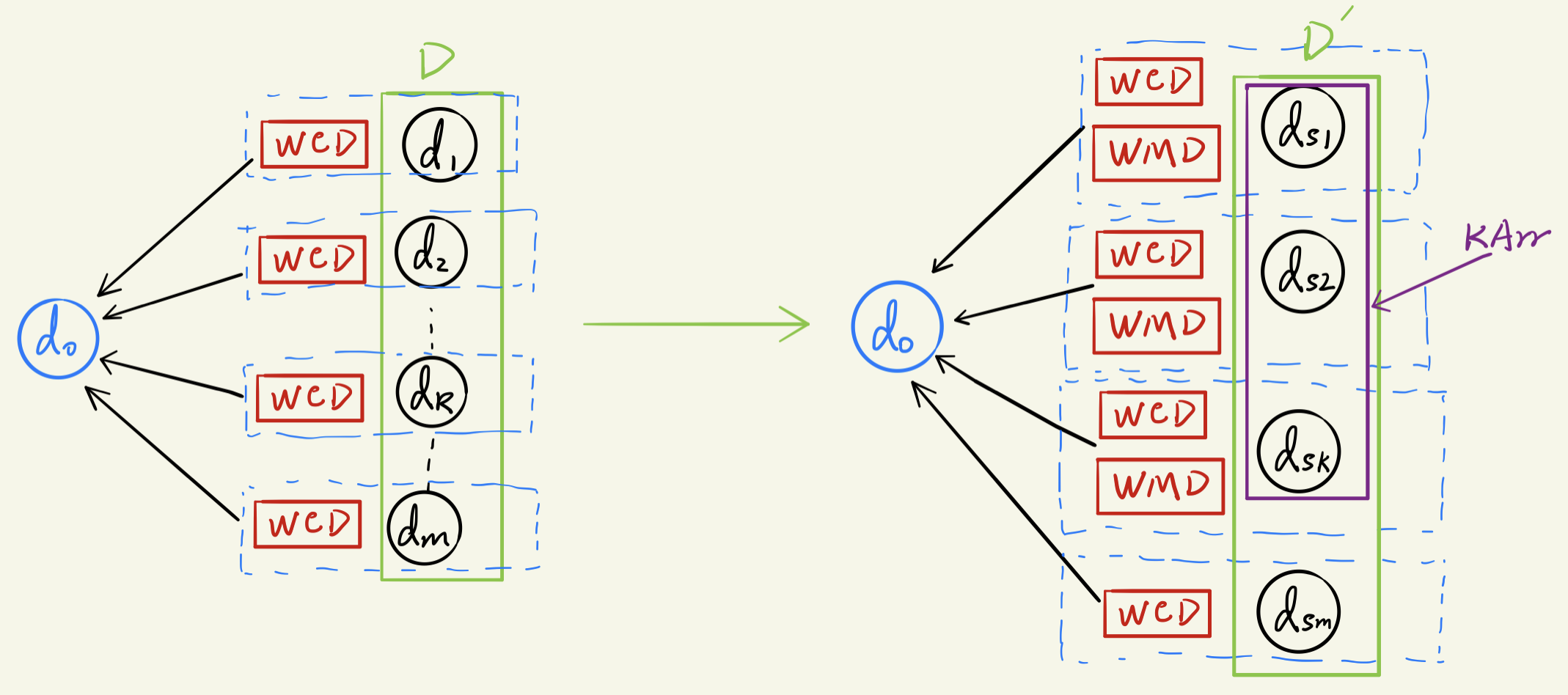
这里也就填上了第 3 节一开始挖的一个坑:我们设 WMD 距离为  ,
,RWMD 距离为  ,
, WCD 距离为 。通过对 进行排序的方法我们看到,计算下界是基于这样一个事实
。通过对 进行排序的方法我们看到,计算下界是基于这样一个事实
如果某一个文本的 WCD 距离都已经很大了,那它的 WMD 距离自然会更大。
4.2 剪枝(prune)
既然上面都说了, WCD 距离是一个非常宽松的下界,所以还有对 KArr 进行处理才能得到最后的训练集。
剪枝操作是建立在遍历剩下 m-k 个文档的基础上的。对于遍历到的每一个文档  ,首先计算它的
,首先计算它的 RWMD 距离 ,如果 大于 KArr 中最后一个(即第 k 个)文档的 WMD 距离,则将  彻底删除(剪枝);如果不大于,则计算 的
彻底删除(剪枝);如果不大于,则计算 的 WMD 距离 ,如果 小于 KArr 中某个文档的 WMD ,则需要更新 KArr 。
4.3 算法伪代码
Let d0 be the query document; d1, d2, ..., dm be data documents.Let D = [d1, d2, ..., dm] denotes the raw document array./* Prefetch */for i in [1, m]:D[i].wcd <-- compute_wcd(D[i], d0) // get WCD for each doc in DD <-- sort_by_wcd(D) // get sorted doc array in terms of WCDKArr <-- D[1:k] // get pre-set k nearest doc arrayfor i in [1, k]:KArr[i].wmd <-- compute_wmd(KArr[i], d0) // get WMD for each doc in KArr/* Prune */for i in [k+1, m]:rwmd <-- compute_rwmd(D[i], d0) // get RWMD of the current docif rwmd > KArr[k].wmd:D.remove(i) // remove the current doc from D (prune)else:wmd <-- compute_rwmd(D[i], d0) // get WMD of the current docif wmd > ${any WMD of doc in KArr}:KArr.update_arr(D[i]) // update KArr using the current doc
5 总结与展望
5.1 算法总结
5.1.1 优点
- 不需要设置超参数
- 无监督,不依赖标注数据,没有冷启动问题
- 有全局最优解
- 可以认为敢于词的重要性
5.1.2 缺点
- 词袋模型,没有保留语序信息 (ngram)
- 不能处理OOV问题 (因为 word2vec 导致的,这里可以使用 fasttext)
- 处理否定词能力差 (加入情感极性信息)
- 处理领域同义词互斥词的能力偏差
5.2 展望
论文的最后,作者提到 WMD 算法今后可行的发展方向:
WMD具有较强的可解释性(interpretability)
因为文本的距离是由单词距离导出的,所以我们可以清晰的看到在机器的视角中,两个单词之间的相似性有多大。
- 将文章结构融入
WMD的计算中
比如用 WMD 来计算 paper 之间的相似程度,那么 introduction 移动到 method section ,它们同样作为大标题,就应该比 introduction 移动到别的单词或词组(统一叫 term)的代价要小。
【参考链接】
https://jozeelin.github.io/2019/07/26/WMD/
https://zhuanlan.zhihu.com/p/76958536

若有收获,就点个赞吧
0 人点赞
