1 音频的表示 —— 常识概念
1.1 时域、频域、梅尔谱图
音频是模拟信号(连续的),但是计算机存储的是数字信号(离散的),这之间就存在数模转换的问题。实际上也很简单,就是以非常高的采样频率对模拟信号进行采样,以此来用数字信号来逼近真实的音频。
采样示意图,来源于博客
经过采样后存储在 .wav 等文件中的数据,画出图是声波的时域图, 轴为时间,
轴为时间, 轴是信号的幅值(对应声音的响度)。
轴是信号的幅值(对应声音的响度)。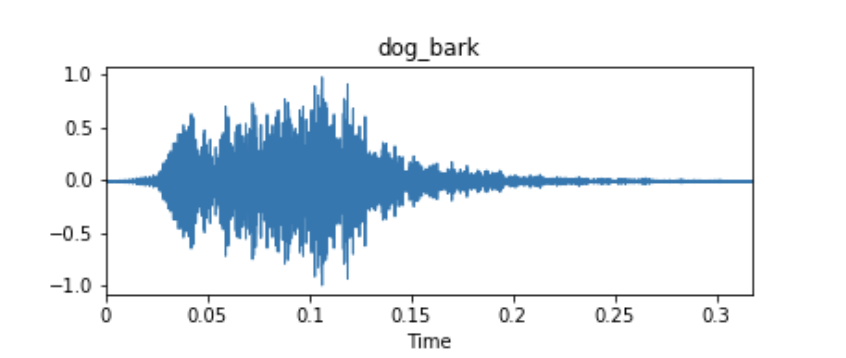
声波的时域图,来源于博客
人耳能听到的频率范围是 20-20000 Hz,但人耳对 Hz 这种标度单位并不是线性感知关系。例如如果我们适应了 1000Hz 的音调,如果把音调频率提高到 2000Hz,我们的耳朵只能觉察到频率提高了一点点,根本察觉不到频率提高了一倍。如果将普通的频率标度转化为梅尔频率标度。
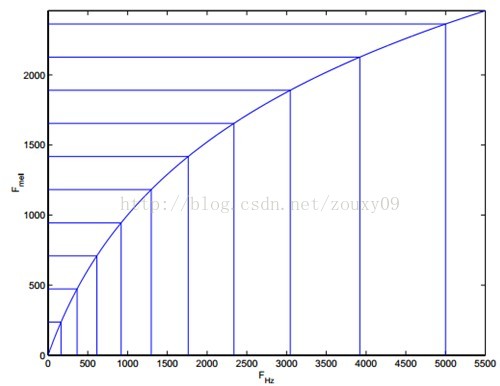
本图摘自博客。
参考资料:
- https://blog.csdn.net/HeroIsUseless/article/details/112180345https://blog.csdn.net/qq_36002089/article/details/108378796
- https://blog.csdn.net/calvinpaean/article/details/103204271
1.2 将音频转换为深度学习输入的形式
想使用深度学习训练模型,首先而且最重要的就是准备数据,因为模型可以从很简单的入手,而数据总得有个你能掌控能理解的输入和输出的形式才行。
一般我们拿到的是 .wav 等格式的音频文件,使用 pytorch 也好,librosa 也好读出来的实际上都是以一定采样频率采样得到的时域声波。目前用的最多的,比较入门的数据转换方式就是计算音频的 MFCC,然后 MFCC 就能直接作为模型的输入。
这里直接上一个示例,从读入音频到计算 MFCC,到处理成输入模型的格式。
2 Quick Start

若有收获,就点个赞吧
0 人点赞
