1 算法概述
最初 Google 为了解决网页去重的问题,在 2007 年发表了一篇论文《Detecting Near-Duplicates for Web Crawling》并提出了 Simhash 算法。该算法的主要思想是通过提取文档中的关键词,通过对关键词进行处理(编码等操作)得到文档的二进制字符串表示,最后通过汉明距离计算两个文档之间的距离,进而得到两个文档的相似性。
传统的 hash 算法产生的两个签名,如果相等,说明原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别极大。所以传统的 hash 算法只适合相同性的检测而不适合相似性检测。而用来度量相似性的 hash 函数,需要对几乎相同的输入内容,产生相同或者相近的 hash 值,换言之,hash 值的相似程度要能直接反映输入内容的相似程度。
Simhash 其实是一种局部敏感 hash(Local Sensitive Hash)。它的核心任务就是在保留数据相对位置的条件下对数据进行降维,这里的降维不一定是从一个数字空间到另一个数字空间,如果把一个含有大量文字的文档用一串很短的数字来表示,这也是一种降维,
1.1 实例解析
下例展示了计算一个文档的 Simhash 值的过程。
假设我们现有的文档是“美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人”。
首先,我们对文本进行预处理:去除文本中的停止词并对文本进行分词。这样我们得到了文档经过分词的单词向量:
[ “美国”, “51区”, “雇员”, “称”, “内部”, “有”, “9架”, “飞碟”, “曾”, “看见”, “灰色”, “外星人” ]
为了提取该文本中的关键词,我们可以根据每个单词的重要性赋予他们权重。赋予权重这一步在多文本的条件下一般使用 TF-IDF ,在此我们先粗略的给他们赋予权重,然后取权重最大的前 5 个关键词(权重数字越大说明越重要):
[ “美国(5)”, “51区(2)”, “飞碟(3)”, “灰色(1)”, “外星人(4)” ]
提取关键词的步骤其实就蕴含了降维的思想。
然后,使用 hash 函数,将关键词映射成固定长度的二进制字符串(一般为 32 位或 64 位,这里使用 6 位)。hash 函数的选择至关重要,这个留到算法原理中讲。这里直接给出各关键词的 hash 值:
美国:100101
51区:101011
飞碟:100111
灰色:101111
外星人:111011
随后,针对每个单词 hash 值的每一位,如果是 1 则将其替换为该词的权重 W ;如果是 0 则将其替换为该词权重的负数 -W 。这样得到如下关键词向量:
美国:[ 5, -5, -5, 5, -5, 5 ]
51区:[ 2, -2, 2, -2, 2, 2 ]
飞碟:[ 3, -3, -3, 3, 3, 3 ]
灰色:[ 1, -1, 1, 1, 1, 1 ]
外星人:[ 4, 4, 4, -4, 4, 4 ]
紧接着对所有关键词向量的列进行求和,得到初始文本向量:[ 15, -7, -1, 3, 5, 15 ]
最后,将初始文本向量中的正数取 1,负数取 0,得到该文本最终的 Simhash 值:[ 1, 0, 0, 1, 115, 1 ]
随后可以使用汉明距离计算两个文本的距离,以得到相似性。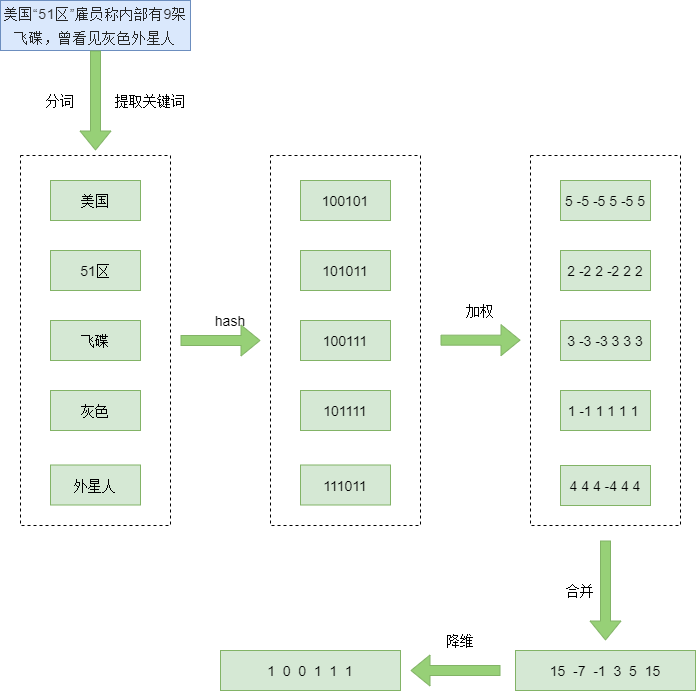
1.2 算法基本原理
Simhash 是局部敏感哈希( locality sensitive hash)的一种,其主要思想是降维,将高维的特征向量映射成低维的特征向量(把文档降维到 hash 数字),通过两个向量的海明距离来确定文章是否重复或者高度近似。Simhash 算法分为 5 个步骤:
- 分词
- 去除停止词并分词
- 给每个词赋予权重
- 选出关键词
- hash —- 计算关键词的 hash 值
- 加权 —- 利用 hash 值和关键词在文本中的权重值进行运算得到关键词向量
- 合并 —- 将所有的关键词向量进行合并,得到初始文本向量
- 降维 —- 对初始文本向量进行二进制编码,得到最终的文本二进制表示
- 计算距离 —- 使用汉明距离计算两个文档的 Simhash 值,一般距离
 3 就认为两个文本是相似的
3 就认为两个文本是相似的- 汉明距离的计算一般使用异或法,即两个 Simhash 数作异或操作,然后数出结果中 1 的个数
2 算法细节
首先是分词后给每一个单词赋予权重。这一步在多文本中一般使用 TF-IDF 对文本进行数值化,进而得到每一个词的权重。同时 GitHub 上的源码有使用 Jieba 作为关键词提取工具的,这一点也可以借鉴。
然后是 hash 函数的选择。目前发现有如下:
PHASH—- 32位,最快的,但最不准确MD5—- 128位,第二快的,更准确一点,目前普遍使用SHA—- SHA-160,最慢的,但最准确jenkins—- 在 GitHub 看到有用的,还没有仔细了解
3 基于 Simhash 的去重框架
Simhash 虽然在度量文本相似度方面精度不够,但因其计算速度快的特点可以帮助我们完成海量文本的去重、聚类等工作。下面对这个基于 Simhash 的文本去重框架进行描述。
假设我们需要对 m 篇文档进行去重。
3.1 简单暴力大法
上面也说过,论文中提出如果两篇文档的 Simhash 值的汉明距离  3 就被认为是相似的,应该被除去。所以最容易想到的方式就是我们假设现有原始文档列表
3 就被认为是相似的,应该被除去。所以最容易想到的方式就是我们假设现有原始文档列表 M 和已经被计算且不重复的文档列表 N 。每次从 M 中提取一个文档 d ,计算它与 N 中文档的相似度,如果发现有与 d 相似的,则对 d 进行去重,否则加入 N 。如果我们假设 N 中文档的数量为 n ,最坏情况下( d 与这 n 篇文档都不相似)要计算 次。如果在原始文本库
次。如果在原始文本库 M 中,每两个文档都不相似,那计算量不言而喻!(注意,我们说的是海量文本去重)
所以我们可以使用倒排索引的方法从 N 中取出一小部分与 d 进行比较,从而降低计算量。
3.2 简单倒排索引
在正向索引,也就是我们一般理解中的索引,形式是 ,其中
,其中  一般都被称为
一般都被称为  。也就是我们通过一个玩意的 (也就是索引)来确定这个玩意的属性。而这种方法是不利于去重和搜索的,因为简单比较两个文档的 是无法判断它们是否相似的。如果我们把索引设计成 ,把
。也就是我们通过一个玩意的 (也就是索引)来确定这个玩意的属性。而这种方法是不利于去重和搜索的,因为简单比较两个文档的 是无法判断它们是否相似的。如果我们把索引设计成 ,把 simhash_code 作为索引,就可以直接判断两个文档是否相似了。
以64位 simhash 编码表示的数据集为例,我们可以构建 64 个倒查索引,对应 simhash 码的 64 个维度;每个倒查索引只有两个 key,即 0 和 1,表示文本编码在这个维度上的取值;这样,我们就可以把所有的文档,按照 simhash 编码在各维度上的取值,放到各个倒查索引中。
在实际去重的时候,每遍历到一个不重复的文档,就把它添加到 64 个倒查索引中。
在考察一篇文档是否重复的时候,我们首先把 64 个倒查索引中,与当前文档编码匹配的部分召回(recall),然后比对当前文档与召回文档的相似度,进而判断是否重复。这种查询方式比 3.1 所述的方式,需要比对的次数要少很多。
当然,这种倒查索引的 key 还是比较稠密,每次查询会召回比较多的文档。
3.3 基于鸽巢原理升级倒排索引
我们可以设计更稀疏的 key,来获得更高的查询精度,进而进一步减少召回的文档数量。
我们已经明确了,如果两个文档的 simhash 值的汉明距离  就算是相似的。这样我们可以将 64 位的 simhash 编码分成 4 个子串。根据鸽巢原理,如果两个 simhash 编码的汉明距离 ,那么它们至少有 1 个子串是完全相同的(否则它们 4 个子串都不相同,那么汉明距离一定大于 3)。
就算是相似的。这样我们可以将 64 位的 simhash 编码分成 4 个子串。根据鸽巢原理,如果两个 simhash 编码的汉明距离 ,那么它们至少有 1 个子串是完全相同的(否则它们 4 个子串都不相同,那么汉明距离一定大于 3)。
这样我们可以把 simhash 码切分为 4 个连续的子串,然后以子串的值为 key 构建倒排索引。这时候,倒查索引的数量降到了 4 个。每个字串是一个 16 位的二进制编码,命中的文档数量相比 3.2 所述key更少。结果就是,查询的时候,召回的文档数量更少了。
4 参考资料
对simhash的简单理解 - 李鹏宇的文章 - 知乎
https://github.com/yanyiwu/simhash
https://github.com/ferd/simhash
https://www.cnblogs.com/maybe2030/p/5203186.html#_label3
https://www.biaodianfu.com/simhash.html
《Detecting Near-Duplicates for Web Crawling》

若有收获,就点个赞吧
0 人点赞
