Seq2Seq 模型就是字面意思,输入序列,输出也是序列的这么一种模型。比如翻译任务,输入的是文本,输出的也是文本; 语音识别等也是如此。大多数 Seq2Seq 的实现方式都是 Encoder-Decoder,即前面是编码器 Encoder,将现实问题(字符串等)转换成数学问题(机器能认识的向量,就是数字);而后面的是解码器 Decoder,负责根据编码器输出的编码向量映射回现实世界(字符串等)。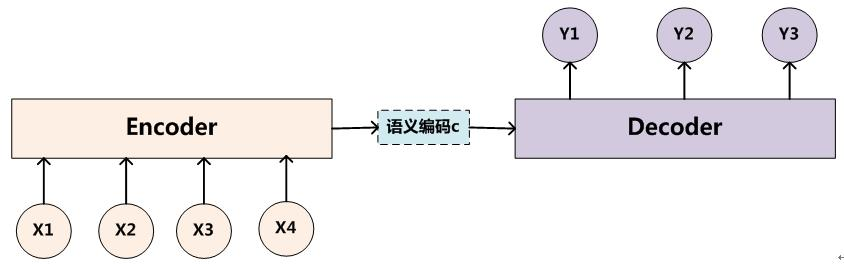
图1 Encoder-Decoder 模型图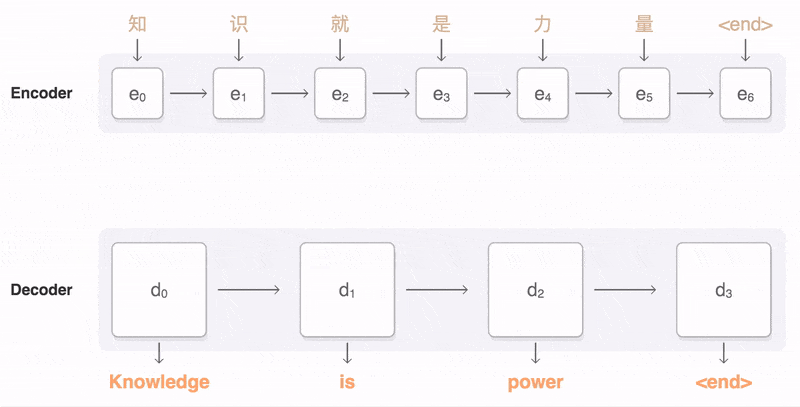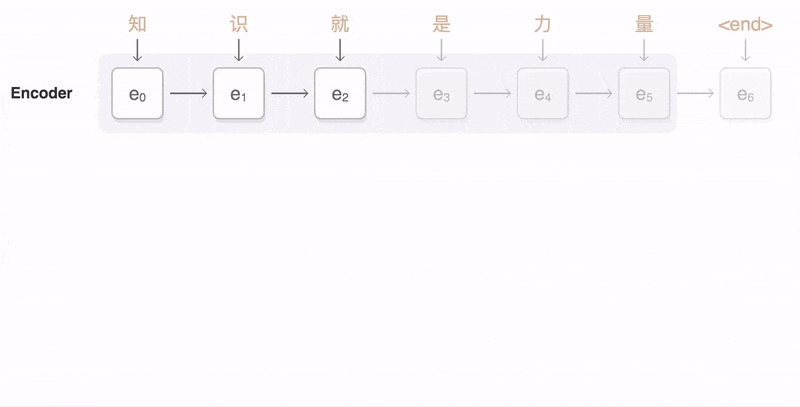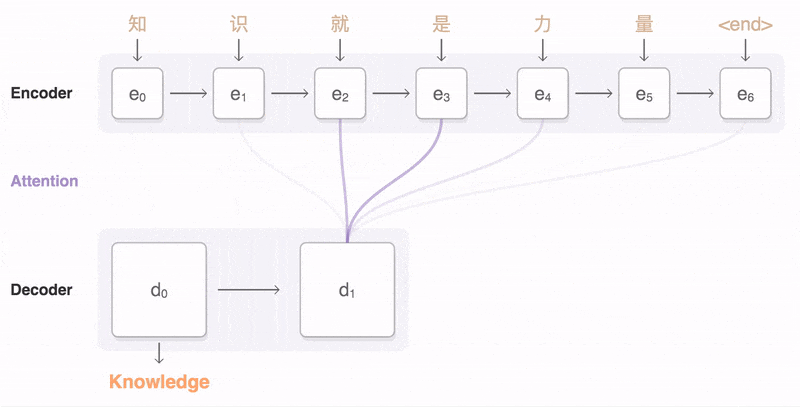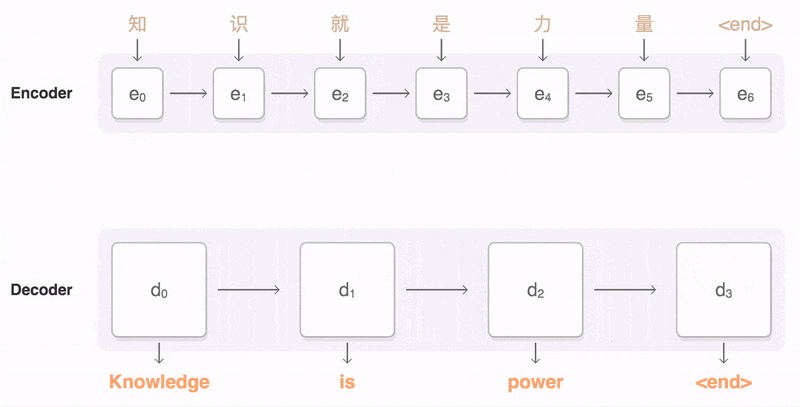
图2 Seq2Seq 任务示例
所以 Seq2Seq 可以理解为目的,Encoder-Decoder 可以理解为具体实现方式。
Encoder 和 Decoder 一般都是使用 CNN, RNN, LSTM, GRU, BiLSTM 等模型实现的。图1 中展示了 Encoder 和 Decoder 之间的连接方式。Encoder 将所有词( )揉在一起,提取它们整体表示的语义向量,这一点非常像关系抽取任务中 Encoder 抽取关系向量。这个语义向量是定长的,也是考虑到后面 Decoder 的方面考虑,但这样就带来了 Encoder-Decoder 模型致命的缺点:
)揉在一起,提取它们整体表示的语义向量,这一点非常像关系抽取任务中 Encoder 抽取关系向量。这个语义向量是定长的,也是考虑到后面 Decoder 的方面考虑,但这样就带来了 Encoder-Decoder 模型致命的缺点:
Encoder 要将真个序列的信息压缩到一个固定长度的向量中:
- 一方面语义向量无法完全表示整个序列的信息
- 另一方面前面输入的信息会被后面输入的信息稀释掉(越往后的信息越重要嘛),序列越长这样的情况就越严重
在这篇文章中提到 Encoder-Decoder 就像是【压缩-解压】的过程:将  的图像压缩成 100KB 看上去还比较清晰,而将
的图像压缩成 100KB 看上去还比较清晰,而将  像素的图像压缩成 100KB 就会糊。
像素的图像压缩成 100KB 就会糊。
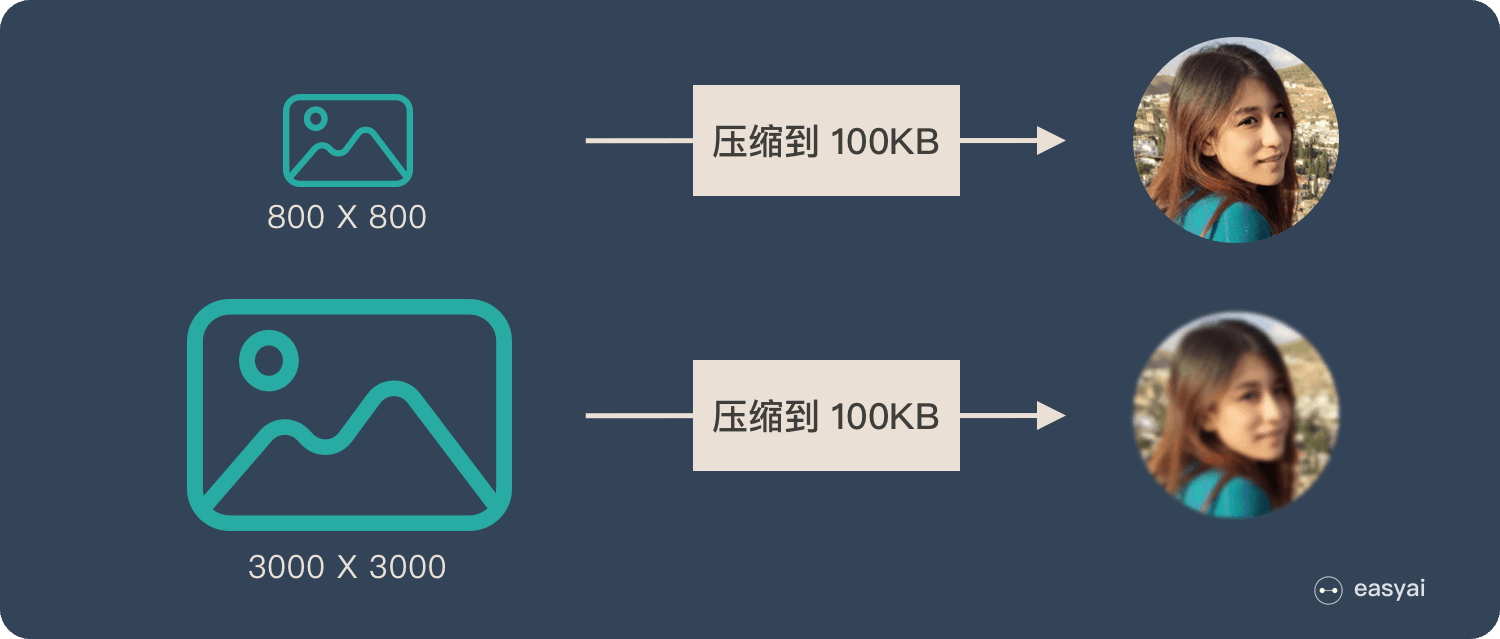
图3 Encoder-Decoder 弊端解释
为了解决上述问题,就出现了 Attention 机制。
References

若有收获,就点个赞吧
0 人点赞
