一、MySQL事务
1.1 什么是事务
事务用于保证数据的一致性,它由一组相关的 DML 语句组成,该组的 DML 语句要么全部成功,要么全部失败。如:转账就要用事务来处理,用以保证数据的一致性。
事务操作的示意图: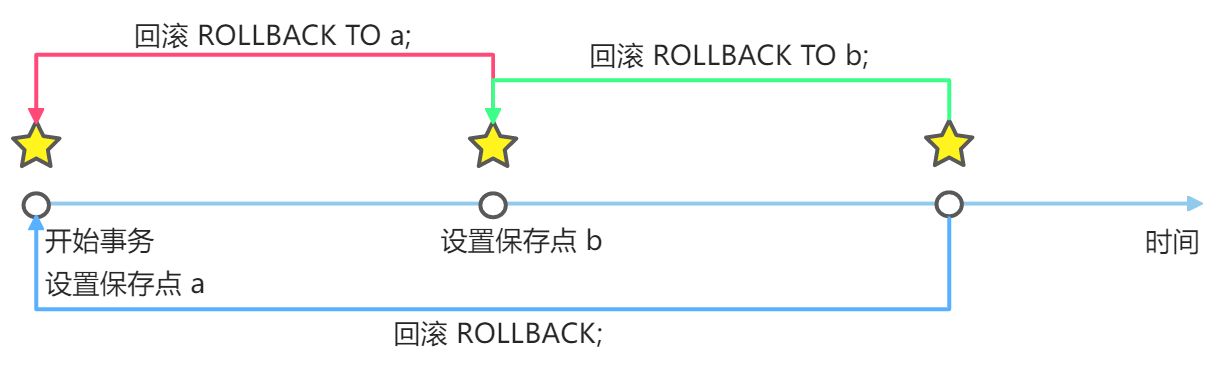
1.2 事务和锁
当执行事务操作时(DML语句),MySQL会在表上加锁,防止其他用户改表的数据。这对用户来讲是非常重要的。
MySQL 数据库控制事务的几个重要操作:
- start transaction 开始一个事务
- savepoinit 保存点名 设置保存点
- rollback to 保存点名 回退事务
- rollback 回退全部事务(回到开始事务的状态)
- commit 提交事务,所有的操作生效,不能回退
-- 事务的一个重要的概念和具体操作-- 看一个图[看示意图]-- 演示-- 1. 创建一张测试表CREATE TABLE t27( id INT,`name` VARCHAR(32));-- 2. 开始事务START TRANSACTION-- 3. 设置保存点SAVEPOINT a-- 执行 dml 操作INSERT INTO t27 VALUES(100, 'tom');SELECT * FROM t27;SAVEPOINT b-- 执行 dml 操作INSERT INTO t27 VALUES(200, 'jack');-- 回退到 bROLLBACK TO b-- 继续回退 aROLLBACK TO a-- 如果这样, 表示直接回退到事务开始的状态.ROLLBACKCOMMIT
1.3 回退事务
在介绍回退事务前,先介绍一下保存点(savepoint)保存点是事务中的点,用于取消部分事务,当结束事务时(commit)会自动删除该事务所定义的所有保存点,当执行回退事务时,通过指定保存点可以回退到指定的状态。
1.4 提交事务
使用commit 语句可以提交事务,当执行了 commit 语句后,会确认事务的变化、结束事务、删除保存点、释放锁,数据生效。当使用 从commit 语句结束事务后,其它会话将可以查看到事务变化后的新数据。
1.5 事务细节讨论
- 如果不开始事务,默认情况下,DML 操作是自动提交的,不能回滚
- 如果开始一个事务,但没有创建保存点,可以执行 ROLLBACK,默认就是回退到事务开始的状态
- 提交前,在事务中可以创建多个保存点
- 提交前,可以选择回退到哪个保存点,注意:如果回退到时间较早的保存点后就不能再回退到时间较晚的保存点
- MySQL 事务机制需要使用 INNODB 存储引擎,MyISAM 不支持
- 开始一个事务:START TRANSACTION / SET AUTOCOMMIT=off
二、MySQL事务隔离级别
2.1 基本介绍
- 多个连接开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性。
- 如果不考虑隔离性,可能会引发如下问题:
- 脏读
- 不可重复读
- 幻读
2.2 查看事务隔离级别
脏读(dirty read):当一个事务读取另一个事务尚未提交的改变(DML操作)时,产生脏读。
不可重复读(nonrepeatable read):同一查询在某一事务中多次进行,由于其他提交事务所做的修改或删除,导致返回不同的结果集,此时发生不可重复读。
幻读(phantom read):同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读。
2.3 事务隔离级别
概念:MySQL 隔离级别定义了事务与事务之间的隔离程度。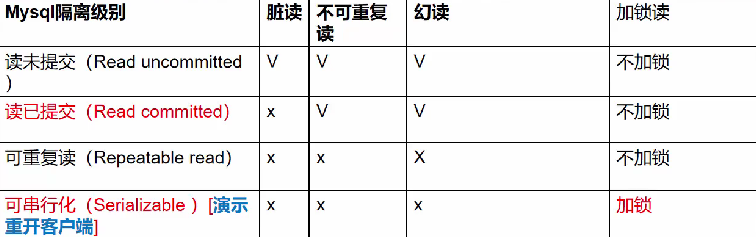

2.4 设置事务隔离级别
- 查看当前会话隔离级别
select @@tx_isolation; - 查看系统当前隔离级别
select @@global.tx_isolation; - 设置当前会话隔离级别
set session transaction level repeatable read; - 设置系统当前隔离级别
set global transaction isolation level repeatable read; - MySQL 默认的事务隔离级别是 repeated read,一般情况下,没有特殊需求,没有必要修改。

-- 演示 mysql 的事务隔离级别-- 1. 开了两个 mysql 的控制台-- 2. 查看当前 mysql 的隔离级别SELECT @@tx_isolation;-- mysql> SELECT @@tx_isolation;-- +-----------------+-- | @@tx_isolation |-- +-----------------+-- | REPEATABLE-READ |-- +-----------------+-- 3.把其中一个控制台的隔离级别设置 Read uncommittedSET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED-- 4. 创建表CREATE TABLE `account`(id INT,`name` VARCHAR(32),money INT);-- 查看当前会话隔离级别SELECT @@tx_isolation-- 查看系统当前隔离级别SELECT @@global.tx_isolation-- 设置当前会话隔离级别SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED-- 设置系统当前隔离级别SET GLOBAL TRANSACTION ISOLATION LEVEL [你设置的级别]
三、事务 ACID
3.1 事务的ACID特性
- 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 - 一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另一个一致性状态 - 隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 - 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
3.2 综合练习
- 登录 mysq| 控制客户端A,创建表dog (id, name),开始个事务,添加两条记录;
- 登录 mysq| 控制客户端B,开始一个事务,设置为读未提交
- A客户端修改Dog一条记录不要提交。看看B客户端是否看到变化,说明什么问题?
- 登录 mysq| 客户端C,开始一个事务,设置为读已提交,这时A客户修改一条记录,不要提交,看看C客户端是否看到变化,说明什么问题?
四、MySQL表类型和存储引擎
4.1 基本介绍
- MySQL的表类型由存储引擎(Storage Engines)决定,主要包括 MyISAM、InnoDB、Memory等
- MySQL 数据表主要支持六种类型,分别是:CSV、Memory、ARCHIVE、MRG_MYISAM、MYSIAM、InnoDB
- 这六种又分类两类,一类是“事务安全型”(transaction-safe),比如:InnoDB;其余都属于第二类,称为“非事务安全型”(non-transaction-safe)[MYSIAM 和 Memory]
显示当前数据库支持的存储引擎:show engines;
4.2 主要的存储引擎/表类型特点
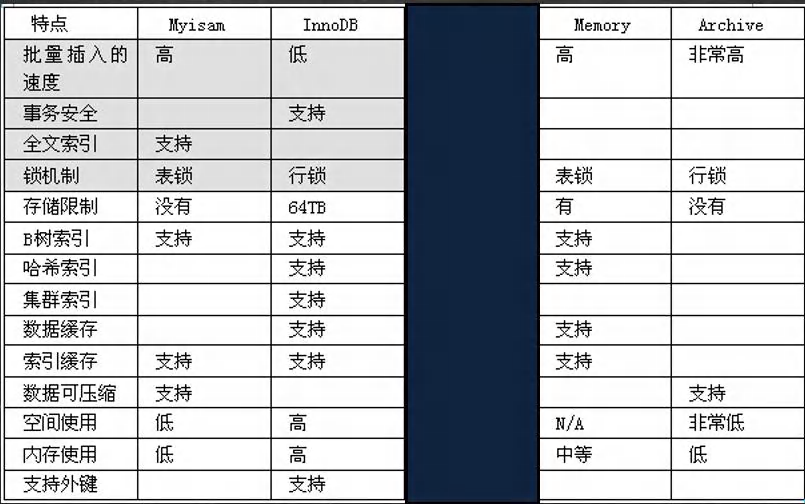
4.3 细节说明
- MyISAM 不支持事务、也不支持外键,但其访问速度快,对事务完整性没有要求
- InnoDB 存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全,但是比起 MyISAM 存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引
- MEMORY 存储引擎使用存在内存中的内容来创建表。每个MEMORY表只实际对应一个磁盘文件。MEMORY 类型的表访问速度非常快,因为它的数据是放在内存中的,并且默认使用 HASH 索引。但是一旦 MySQL 服务关闭再重启,表中的数据就会丢失掉,表的结构还在。
4.4 三种存储引擎表使用案例
-- 表类型和存储引擎-- 查看所有的存储引擎SHOW ENGINES-- innodb 存储引擎,是前面使用过.-- 1. 支持事务 2. 支持外键 3. 支持行级锁-- myisam 存储引擎CREATE TABLE t28 (id INT,`name` VARCHAR(32)) ENGINE MYISAM-- 1. 添加速度快 2. 不支持外键和事务 3. 支持表级锁START TRANSACTION;SAVEPOINT t1INSERT INTO t28 VALUES(1, 'jack');SELECT * FROM t28;ROLLBACK TO t1-- memory 存储引擎-- 1. 数据存储在内存中[关闭了 Mysql 服务,数据丢失, 但是表结构还在]-- 2. 执行速度很快(没有 IO 读写) 3. 默认支持索引(hash 表)CREATE TABLE t29 (id INT,`name` VARCHAR(32)) ENGINE MEMORYDESC t29INSERT INTO t29VALUES(1,'tom'), (2,'jack'), (3, 'hsp');SELECT * FROM t29-- 指令修改存储引擎ALTER TABLE `t29` ENGINE = INNODB
4.5 如何选择表的存储引擎
- 如果你的应用不需要事务,处理的只是基本的CRUD操作,那么 MyISAM 是不二选择,速度快
- 如果需要支持事务,选择 InnoDB
- Memory 存储引擎就是将数据存储在内存中,由于没有磁盘 I/O 的等待,速度极快。但由于是内存存储引擎,所做的任何修改在服务器重启后都将消失。(经典用法:用户的在线状态)
4.6 修改存储引擎

五、视图(View)
5.1 看一个需求
emp 表的列信息很多,有些信息是个人重要信息(比如 sal,comm,mgr,hiredate)如果我们希望某个用户只能查询 emp 表的某些信息(empno、ename、job 和 deptno)信息,有什么办法?
视图可以解决上诉问题。
5.2 基本概念
- 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含列,其数据来自对应的真实表(基表)
- 视图和基表对应关系如下图

5.3 视图的基本使用
- create view 视图名 as select语句 from 基表
- alter view 视图名 as select语句 —更新成新的视图
- show create view 视图名
- drop view 视图名1,视图名2
5.4 案例演示
创建一个视图 emp_view01,只能查询 emp 表的(empno、ename, job 和 deptno ) 信息
-- 视图的使用-- 创建一个视图 emp_view01,只能查询 emp 表的(empno、ename, job 和 deptno ) 信息-- 创建视图CREATE VIEW emp_view01ASSELECT empno, ename, job, deptno FROM emp;-- 查看视图DESC emp_view01SELECT * FROM emp_view01;SELECT empno, job FROM emp_view01;-- 查看创建视图的指令SHOW CREATE VIEW emp_view01-- 删除视图DROP VIEW emp_view01;-- 视图的细节-- 1. 创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式: 视图名.frm)-- 2. 视图的数据变化会影响到基表,基表的数据变化也会影响到视图[insert update delete ]-- 修改视图 会影响到基表UPDATE emp_view01SET job = 'MANAGER'WHERE empno = 7369SELECT * FROM emp; -- 查询基表SELECT * FROM emp_view01-- 修改基本表, 会影响到视图UPDATE empSET job = 'SALESMAN'WHERE empno = 7369-- 3. 视图中可以再使用视图 , 比如从 emp_view01 视图中,选出 empno,和 ename 做出新视图DESC emp_view01CREATE VIEW emp_view02ASSELECT empno, ename FROM emp_view01SELECT * FROM emp_view02
5.5 视图细节讨论
- 创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式:视图名.frm)
- 视图的数据变化会影响到基表,基表的数据变化也会影响到视图
- 视图中可以再使用视图,数据仍然来自基表
5.6 视图最佳实践
- 安全。一些数据表有着重要的信息。有些字段是保密的,不能让用户直接看到。这时就可以创建一个视图,在这张视图中只保留一部分字段。这样,用户就可以查询自己需要的字段,不能查看保密的字段。
- 性能。关系数据库的数据常常会分表储存,使用外键建立这些表之间的关系。这时,数据库查询通常会用到连接(JOIN)。这样做不但麻烦,效率相对也较低。如果建立一个视图,将相关的表和字段组合在一起,就可以避免使用 JOIN 查询数据。
- 灵活。如果系统中有一张旧的表,这张表由于设计的问题,即将被废弃。然而,很多应用都是基于这张表,不易修改。这时就可以建立一张视图,视图中的数据直接映射到新建的表。这样,就可以少做很多改动,也达到了升级数据表的目的。
5.7 小练习
针对 emp ,dept , 和 salgrade 张三表.创建一个视图 emp_view03,可以显示雇员编号,雇员名,雇员部门
名称和 薪水级别[即使用三张表,构建一个视图]
-- 视图的课堂练习-- 针对 emp ,dept , 和 salgrade 张三表.创建一个视图 emp_view03,-- 可以显示雇员编号,雇员名,雇员部门名称和 薪水级别[即使用三张表,构建一个视图]/*分析: 使用三表联合查询,得到结果将得到的结果,构建成视图*/CREATE VIEW emp_view03ASSELECT empno, ename, dname, gradeFROM emp, dept, salgradeWHERE emp.deptno = dept.deptno AND(sal BETWEEN losal AND hisal)DESC emp_view03SELECT * FROM emp_view03
六、MySQL 管理
6.1 MySQL用户
MySQL 中的用户,都存储在系统数据库 MySQL 中 user 表中
其中 user 表的重要字段说明:
- host:允许登录的“位置”,localhost 表示该用户只允许本机登录,也可以指定 ip 地址
- user:用户名
- authentication_string:密码,是通过MySQL的password()函数加密之后的密码
6.2 创建用户

6.3 删除用户

6.4 用户修改密码

6.5 MySQL中的权限
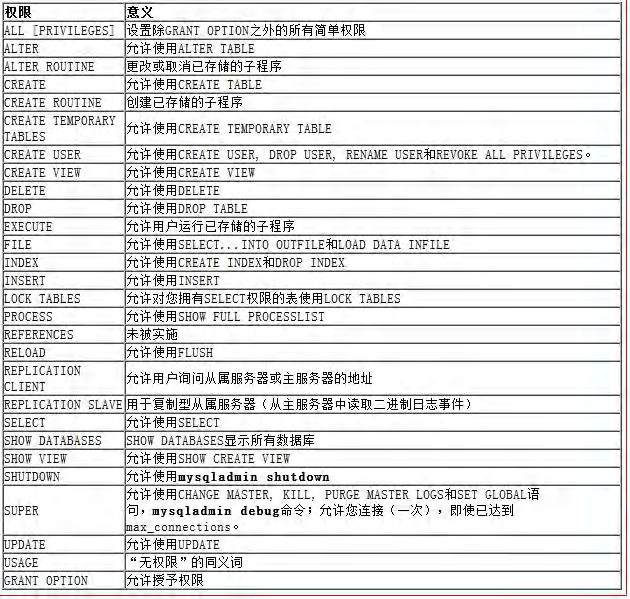
6.6 给用户授权
基本语法:
grant 权限列表 on 库.对象名 to ‘用户名’@’登录位置’ 【identified by ‘密码’】
说明:
- 权限列表,多个权限用逗号隔开
grant select on ….
grant select, delete, create on …..
grant all 【privileges】 on …. //表示赋予该用户在该对象上的所有权限 - 特别说明:
.:代表本系统的所有数据库的所有对象(表、视图、存储过程)
库.*:表示某个数据库中的所有数据对象(表、视图、存储过程等)
- identified by 可以省略,也可以写上
- 如果用户存在,就是修改该用户的密码
- 如果用户不存在,就是创建该用户
6.7 回收用户授权
基本语法:
revoke 权限列表 on 库.对象名 from ‘用户名’@’登录位置’;
6.8 权限生效指令
如果权限没有生效,可以执行下面命令
基本语法:
FLUSH PRIVILEGES;

-- 演示 用户权限的管理-- 创建用户 shunping 密码 123 , 从本地登录CREATE USER 'shunping'@'localhost' IDENTIFIED BY '123'-- 使用 root 用户创建 testdb ,表 newsCREATE DATABASE testdbCREATE TABLE news (id INT ,content VARCHAR(32));-- 添加一条测试数据INSERT INTO news VALUES(100, '北京新闻');SELECT * FROM news;-- 给 shunping 分配查看 news 表和 添加 news 的权限GRANT SELECT , INSERTON testdb.newsTO 'shunping'@'localhost'-- 可以增加 update 权限GRANT UPDATEON testdb.newsTO 'shunping'@'localhost'-- 修改 shunping 的密码为 abcSET PASSWORD FOR 'shunping'@'localhost' = PASSWORD('abc');-- 回收 shunping 用户在 testdb.news 表的所有权限REVOKE SELECT , UPDATE, INSERT ON testdb.news FROM 'shunping'@'localhost'REVOKE ALL ON testdb.news FROM 'shunping'@'localhost'-- 删除 shunpingDROP USER 'shunping'@'localhost'
6.9 细节说明
- 在创建用户的时候,如果不指定 Host,则为 % ,表示所有 IP 都有连接权限
- 也可以通过下面的方式指定:
create user ‘xxx’@’192.168.1.%’ 表示 xxx 用户在 192.168.1.* 的IP可以登录 MySQL - 在删除用户的时候,如果 host 不是 %,需要明确指定 ‘用户’@’host值’ ```sql — 说明 用户管理的细节 — 在创建用户的时候,如果不指定 Host, 则为% , %表示表示所有 IP 都有连接权限 — create user xxx;
CREATE USER jack
SELECT host, user FROM mysql.user
— 你也可以这样指定 — create user ‘xxx’@’192.168.1.%’ 表示 xxx 用户在 192.168.1.*的 ip 可以登录 mysql
CREATE USER ‘smith’@’192.168.1.%’
— 在删除用户的时候,如果 host 不是 %, 需要明确指定 ‘用户’@’host 值’
DROP USER jack — 默认就是 DROP USER ‘jack’@’%’
DROP USER ‘smith’@’192.168.1.%’
<a name="k33iW"></a>### 七、本章作业2. 写出查看 dept 表和 emp 表结构的sql语句<br />desc dept;<br />desc emp;2. 使用简单查询语句完成:1. 显示所有部门名称1. 显示所有雇员名及其全年收入13月(工资+补助),并指定列别名“年收入”4. 限制查询数据。1. 显示工资超过2850的雇员姓名和工资。1. 显示工资不在1500到2850之间的所有雇员名及工资。1. 显示编号为7566的雇员姓名及所在部门编号。1. 显示部门10和30中工资超过1 500的雇员名及工资1. 显示无管理者的雇员名及岗位。5. 排序数据。1. 显示在1991年2月1日到1991年5月1日之间雇用的雇员名,岗位及雇佣日期,并以雇佣日期进行排序。1. 显示获得补助的所有雇员名.工资及补助,并以工资降序排序6. 根据:emp员工表 写出正确SQL1. 选择部门 ]30中的所有员工.1. 列出所有办事员(CLERK)的姓名, 编号和部门]编号.1. 找出佣金高于薪金的员工.1. 找出佣金高于薪金60%的员工,1. 找出部门 ]10中所有经理(MANAGER)和部门]20中所有办事员(CLERK)的详细资料.1. 找出部门 ]10中所有经理(MANAGER),部]20中所有办事员(CLERK),还有既不是经理又不是办事员但其薪金大于或等于2000的所有员工的详细资料.1. 找出收取佣金的员工的不同工作.1. 找出不收取佣金或收取的佣金低于100的员工,1. 找出各月倒数第3天受雇的所有员工,1. 找出早于12年前受雇的员工.1. 以首字母小写的方式显示所有员工的姓名.1. 显示正好为5个字符的员工的姓名.1. 显示不带有"R"的员工 的姓名.1. 显示所有员工姓名的前三个字符.1. 显示所有员工的姓名,用a替换所有"A"1. 显示满10年服务年限的员I的姓名和受雇日期.1. 显示员工的详细资料按姓名排序1. 显示员工的姓名和受雇日期,根据其服务年限,将最老的员工排在最前面.1. 显示所有员工的姓名、工作和薪金按工作降序排序,若工作相同则按薪金排序1. 显示所有员工的姓名、加入公司的年份和月份按受雇日期所在月排序若月份相同则将最早年份的员工排在最前面.1. 显示在一个月为30天的情况所有员工的日薪金忽略余数.1. 找出在(任何年份的)2月受聘的所有员工。1. 对于每个员工,显示其加入公司的天数.1. .显示姓名字段的任何位置包含”A"的所有员工的姓名.1. 以年月 日的方式显示所有员工的服务年限, (大概)7. 根据:emp员工表, dept部门表,工资 = 薪金sal +佣金comm 写出正确SQL1. 列出至少有一个员工的所有部门1. 列出薪金比"SMITH"多的所有员工。1. 列出受雇日期晚于其直接上级的所有员工。1. 列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门。1. 列出所有"CLERK" (办事员)的姓名及其部门名称。1. 列出最低薪金大于1500的各种工作。1. 列出在部门"SALES" (销售部)工作的员工的姓名。1. 列出薪金高于公司平均薪金的所有员工。1. 列出与"SCOTT"从事相同工作的所有员工。1. 列出薪金高于在部门30工作的所有员工的薪金的员工姓名和薪金。1. 列出在每个部门工作的员工数量、平均工资和平均服务期限。1. 列出所有员工的姓名、部门名称和工资。1. 列出所有部门的详细信息和部门人数。1. 列出各种工作的最低工资。1. 列出MANAGER (经理)的最低薪金。1. 列出所有员工的年工资,按年薪从低到高排序。8. 设学校环境如下:一 个系有若干个专业,每个专业一年只招一个班,每个班有若干个学生。<br />现要建立关于系、学生、班级的数据库,关系模式为:<br />班 CLASS (班号classid, 专业名subject, 系名deptname, 入学年份enrolltime, 人数num)<br />学生 STUDENT (学号studentid, 姓名name,年龄age,班号classid)<br />系 DEPARTMENT (系号departmentid, 系名deptname)<br />试用SQL语言完成以下功能:(1)建表,在定义中要求声明:<br />(1)每个表的主外码。<br />(2) deptname是唯一约束。<br />(3)学生姓名不能为空。<br />(2)插入如下数据<br />DEPARTMENT ( 001, 数学;<br />002, 计算机;<br />003, 化学;<br />004, 中文;<br />005, 经济; )<br />(3)完成以下查询功能<br />3.1找出所有姓李的学生。<br />3.2列出所有开设超过1个专业的系的名字。<br />3.3列出人数大于等于30的系的编号和名字。<br />(4)学校又新增加了一个物理系,编号为006<br />(5)学生张三退学,请更新相关的表```sqlCREATE TABLE department (departmentid CHAR(3) PRIMARY KEY,deptname VARCHAR(10) UNIQUE);CREATE TABLE class (classid CHAR(3) PRIMARY KEY,`subject` VARCHAR(10),deptname VARCHAR(10),enrolltime CHAR(4),num INT,FOREIGN KEY (deptname) REFERENCES department(deptname));CREATE TABLE student (studentid CHAR(4) PRIMARY KEY,`name` VARCHAR(32) NOT NULL DEFAULT '',age INT,classid CHAR(3),FOREIGN KEY (classid) REFERENCES class(classid));INSERT INTO department VALUES('001','数学'),('002','计算机'),('003','化学'),('004','中文'),('005','经济');INSERT INTO class VALUES('101','软件','计算机','1995',20),('102','微电子','计算机','1996',30),('111','无机化学','化学','1995',29),('112','高分子化学','化学','1996',25),('121','统计数学','数学','1995',20),('131','现代语言','中文','1996',20),('141','国际贸易','经济','1997',30),('142','国际金融','经济','1996',14);INSERT INTO student VALUES('8101','张三',18,'101'),('8102','钱四',16,'121'),('8103','王玲',17,'131'),('8105','李飞',19,'102'),('8109','赵四',18,'141'),('8110','李可',20,'142'),('8201','张飞',18,'111'),('8302','周瑜',16,'112'),('8203','王亮',17,'111'),('8305','董庆',19,'102'),('8409','赵龙',18,'101'),('8510','李丽',20,'142');SELECT * FROM student WHERE `name` LIKE '李%';SELECT deptname FROM(SELECT COUNT(*) AS cot,deptname FROM class GROUP BY deptname) tmpWHERE cot > 1;SELECT departmentid,department.deptname FROM department,(SELECT SUM(num) AS sum_num,deptname FROM class GROUP BY deptname) tmpWHERE department.deptname = tmp.deptname AND sum_num >= 30;INSERT INTO department values ('006','物理系');DELETE FROM student WHERE `name` = '张三';
学习参考(致谢):
- B站 @程序员鱼皮 Java学习一条龙
- B站 @韩顺平 零基础30天学会Java

若有收获,就点个赞吧
0 人点赞
