整理分库分表相关知识点,为以后实践做准备(未完成)
一、什么是分库分表?
1.1、什么是分库?
分库:一个库的并发最多支撑到2000,超过则宕机崩溃,而一个健康的单库并发大概在每秒1000左右。
1.2、什么是分表?
分表:单表数据达到几百万时,sql 的执行性能相对开始较差了,当其超过千万数据时,sql 的执行性能急剧下降,为了最大限度的保持 sql 的执行性能,必须分表;
- 分表方式
- 水平拆分
- 垂直拆分
1.3、分库分表策略
- 按照范围划分,例如:按照月份、年份
- hash+mod 的组合,选择某个字段,对其hash 然后取模
二、分库分表带来的复杂性?
2.1、关联查询
- 字段冗余:把需要关联的字段放入主表中,避免 join 操作;
- 数据抽象:通过 ETL 等将数据汇合聚集,生成新的表;
- 全局表:比如一些基础表可以在每个数据库中都放一份;
-
2.2、分布式事务
单数据库可以用本地事务搞定,使用多数据库就只能通过分布式事务解决了。
常用解决方案有: 基于可靠消息(MQ)的解决方案
- 两阶段事务提交、柔性事务等。
中间件
2.4、数据迁移
- 停机迁移方案
- 数据库双写迁移方案
- 第一步:(同步双写)修改应用配置和代码,加上双写,部署;
- 第二步:(同步双写)将老库中的老数据复制到新库中;
- 第三步:(同步双写)以老库为准校对新库中的老数据;
- 第四步:(同步双写)修改应用配置和代码,去掉双写,部署;
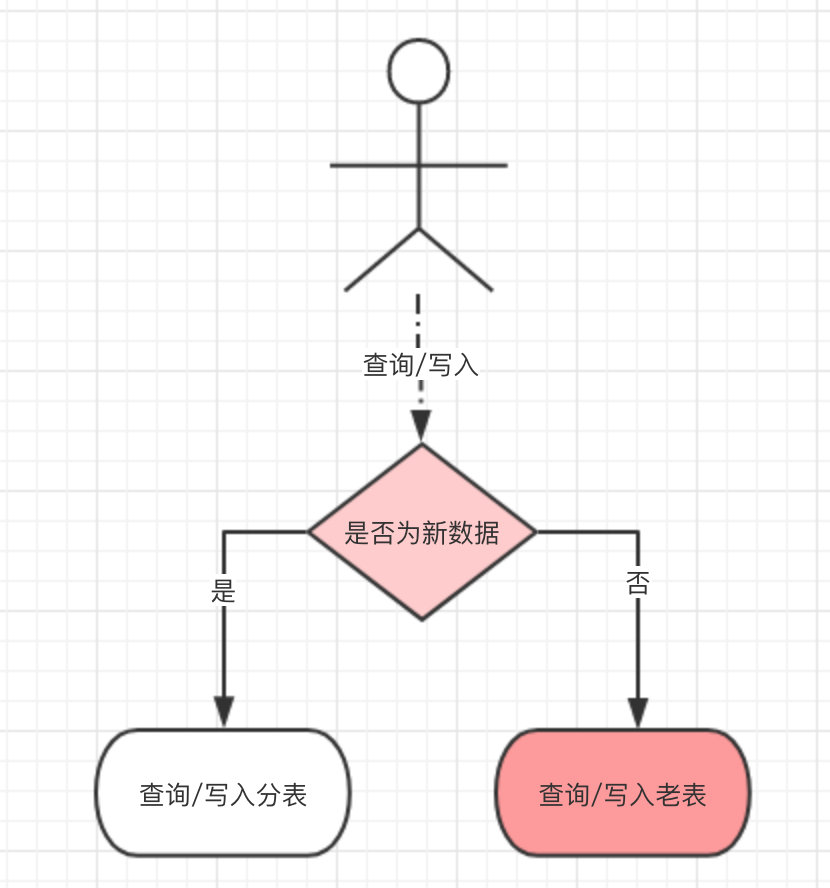
2.5、非拆分键的查询方案
- 建立映射表
- 建立拆分键和其它搜索关键字的映射表
- NoSQL 法
- 借助 ES、Hbase等服务进行查询
- 需要监听binlog 同步到 NoSQL
冗余法
用 NoSQL 法解决
三、分库分表工具选型
3.1、分库分表中间件
- sharding-sphere:jar,前身是sharding-jdbc;
- TDDL:jar,Taobao Distribute Data Layer;
- Mycat:中间件。
参考
- https://github.com/DragonV96/study-notes/blob/master/%E5%88%86%E5%B8%83%E5%BC%8F/%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8/%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8%E6%80%BB%E7%BB%93.md
- https://crossoverjie.top/2019/07/24/framework-design/sharding-db-03/
- https://tech.meituan.com/2016/12/19/mtddl.html
- https://www.cnblogs.com/littlecharacter/p/9342129.html#_label4
- https://www.cnblogs.com/wingsless/p/11406481.html
- https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html
- https://dbaplus.cn/news-160-3549-1.html

若有收获,就点个赞吧
0 人点赞
