其实对于分治算法,如果有了解快速排序,归并排序的同学,其实就懂得差不多了
分治,也就是分而治之。
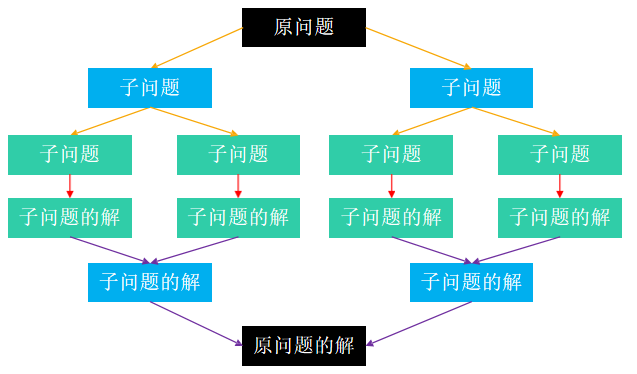
它的一般步骤是
① 将原问题分解成若干个规模较小的子问题(子问题和原问题的结构一样,只是规模不一样)
② 子问题又不断分解成规模更小的子问题,直到不能再分解(直到可以轻易计算出子问题的解)
③ 利用子问题的解推导出原问题的解
因此,分治策略非常适合用递归 需要注意的是:子问题之间是相互独立的
主定理

最大连续子序列和
我们还是通过做题来讲解一下分治的运用
问题:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
这道题也属于最大切片问题(最大区段,Greatest Slice)
概念区分
子串、子数组、子区间必须是连续的,子序列是可以不连续的
暴力出奇迹
这中解题方法我们丝毫都不推荐,暴力的确能解决问题,但是花费的时间太长了,损耗也很高;穷举出所有可能的连续子序列,并计算出它们的和,最后取它们中的最大值
static int maxSubarray2(int[] nums) {if (nums == null || nums.length == 0) return 0;int max = Integer.MIN_VALUE;for (int begin = 0; begin < nums.length; begin++) {int sum = 0;for (int end = begin; end < nums.length; end++) {// sum是[begin, end]的和sum += nums[end];max = Math.max(max, sum);}}return max;}
空间复杂度O(1)
时间复杂度O(n)
分治
将序列均匀地分割成 2 个子序列
[begin , end) = [begin , mid) + [mid , end),mid = (begin + end) >> 1
假设 [begin , end) 的最大连续子序列和是 S[i , j) ,那么它有 3 种可能
[i , j) 存在于 [begin , mid) 中,同时 S[i , j) 也是 [begin , mid) 的最大连续子序列和
[i , j) 存在于 [mid , end) 中,同时 S[i , j) 也是 [mid , end) 的最大连续子序列和
[i , j) 一部分存在于 [begin , mid) 中,另一部分存在于 [mid , end) 中
[i , j) = [i , mid) + [mid , j)
S[i , mid) = max { S[k , mid) },begin ≤ k < mid
S[mid , j) = max { S[mid , k) },mid < k ≤ end
简笔画
示例:
public static void main(String[] args) {int[] nums = {-2, 1, -3, 4, -1, 2, 1, -5, 4 };System.out.println(maxSubArray(nums));}static int maxSubArray(int[] nums) {if (nums == null || nums.length == 0) {return 0;}return maxSubArray(nums, 0, nums.length);}static int maxSubArray(int[] nums, int begin, int end) {if (end - begin < 2){return nums[begin];}int mid = (begin + end) >> 1;int leftMax = nums[mid - 1];int leftSum = leftMax;for (int i = mid - 2; i >= begin; i--) {leftSum += nums[i];leftMax = Math.max(leftMax, leftSum);}int rightMax = nums[mid];int rightSum = rightMax;for (int i = mid + 1; i < end; i++) {rightSum += nums[i];rightMax = Math.max(rightMax, rightSum);}return Math.max(leftMax + rightMax,Math.max(maxSubArray(nums, begin, mid),maxSubArray(nums, mid, end)));}

动态规划
分治并不是这道题的最优解,还有一种更好的解题方式
动态规划传送门
思考
分治和动态规划的时间复杂度相同,但是因为分治使用了递归,并且维护了四个信息的结构体,运行的时间略长,空间复杂度也不如方法一优秀,而且难以理解。那么这种方法存在的意义是什么呢?
对于这道题而言,确实是如此的。但是仔细观察分治,它不仅可以解决区间 [0, n-1][0,n−1],还可以用于解决任意的子区间 [l,r][l,r] 的问题。如果我们把 [0, n-1][0,n−1] 分治下去出现的所有子区间的信息都用堆式存储的方式记忆化下来,即建成一颗真正的树之后,我们就可以在 O(\log n)O(logn) 的时间内求到任意区间内的答案,我们甚至可以修改序列中的值,做一些简单的维护,之后仍然可以在 O(\log n)O(logn) 的时间内求到任意区间内的答案,对于大规模查询的情况下,这种方法的优势便体现了出来。

若有收获,就点个赞吧
0 人点赞
