关于特征编码器
特征编码器起到的作用是将数据集中的特征提取出来以供神经网络学习。你必须在训练时指定一个编码器。目前整合包支持 4 个基础编码器:
| 编码器名称 | 优点 | 缺点 |
|---|---|---|
| vec256l9 | - | 不支持扩散模型 |
| vec768l12(推荐) | 最还原音色、有大型底模、支持响度嵌入 | 咬字能力较弱 |
| hubertsoft | 咬字能力较强 | 音色泄露 |
| whisper-ppg | 咬字最强 | 音色泄露、显存占用高 |
1下载对应编码器的必备模型(见后表),以原文件名放置在pretrain文件夹
2重启 WebUI,编码器列表里就会出现新的编码器选项
额外编码器不自带预训练模型,因此训练难度会大幅提升,请谨慎启用。如果你有额外编码器的预训练模型,可以放置在pre_trained_model文件夹下的对应文件夹,训练时会自动加载。
| 编码器名称 | 下载地址 | | —- | —- | | CNHuBERT-Large | chinese-hubert-large-fairseq-ckpt.pt | | DPHuBERT | DPHuBERT-sp0.75.pth | | WavLM-Base+ | WavLM-Base+.pt | | Whisper-PPG-Large | large-v2.pt | 关于浅扩散
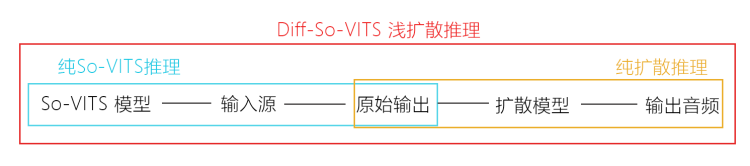
So-VITS 4.1 近期的一个重大更新就是引入了浅扩散 (Shallow Diffusion) 机制,将 So-VITS 的原始输出音频转换为Mel谱图,加入噪声并进行浅扩散处理后经过声码器输出音频。经过测试,原始输出音频在经过浅扩散处理后可以显著改善电音、底噪等问题,输出质量得到大幅增强。
要使用浅扩散机制:
1你必须在原有数据集上训练一个新的扩散模型
2数据预处理时勾选“训练扩散模型”
3确保扩散模型和 So-VITS 模型配置文件中的说话人名称一致
4在推理时加载扩散模型
扩散模型与 So-VITS 模型是独立的,得益于浅扩散机制的向下兼容性,你仍然可以只使用其中任意一个模型进行推理,或者同时使用 So-VITS 和扩散模型进行完整的浅扩散推理。
关于浅扩散步数(训练)
在 v2.3.6 之前的版本,浅扩散模型是训练完整 1000 步深度的,但在大多数情况下,推理时很少会用到完整深度扩散。在 Diffusion-SVC 的实现中,可以只训练一个特定步数深度的浅扩散模型(例如 100 步),由此可以进一步加快浅扩散的训练速度。在理论和实践测试中,只训练部分步数浅扩散的模型表现也比纯扩散模型更好。但代价是在推理时无法进行超过该步数的浅扩散推理。
So-VITS 近期也引入了真浅扩散训练,你可以在训练界面找到相应的设置参数。
真浅扩散训练时,loss 会比完整扩散训练更高,这是正常现象,不会影响模型最终质量。
关于浅扩散步数(推理)
完整的高斯扩散为 1000 步,当浅扩散步数达到 1000 步时,此时的输出结果完全是扩散模型的输出结果,So-VITS 模型将被抑制。浅扩散步数越高,越接近扩散模型输出的结果。如果你只是想用浅扩散去除电音底噪,尽可能保留 So-VITS 模型的音色,浅扩散步数可以设定为 50-100.
关于响度嵌入和音量增强
原版 So-VITS 模型输出音频的响度是与你的数据集响度匹配的。在预处理过程中,你的所有数据集音频会被自动匹配到 0db 的响度,这是一个非常高的数值,会导致你的模型最终输出的响度非常高,并且损坏音质。
启用了响度嵌入后,预处理会对原音频进行响度增强处理,模型会学习音频的响度信息,这样模型输出的响度就会匹配到输入源音频,而非数据集响度。
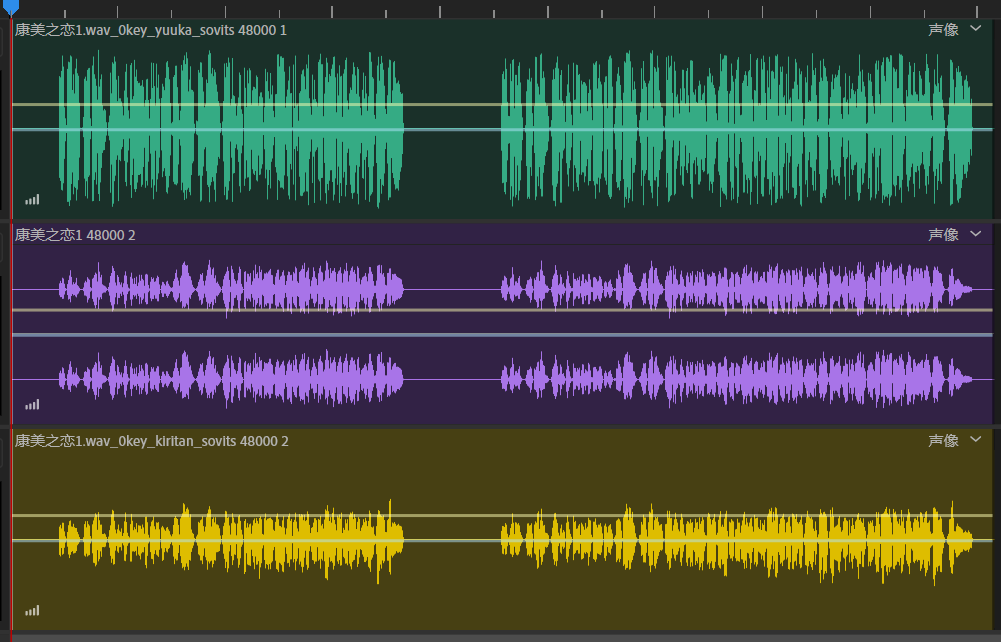
图中从上到下分别是:原始输出音频、输入源音频、启用了响度嵌入的模型输出的音频
⚠️启用了响度嵌入后,模型需要重新训练,并且仅支持 Vec768L12 编码器。
关于聚类模型
聚类方案可以减小音色泄漏,使得模型训练出来更像目标的音色(但其实不是特别明显),但是单纯的聚类方案会降低模型的咬字(会口齿不清,这个很明显)。本模型采用了融合的方式,可以线性控制聚类方案与非聚类方案的占比,也就是可以手动在”像目标音色” 和 “咬字清晰” 之间调整比例,找到合适的折中点。
使用聚类只需要额外训练一个聚类模型,虽然效果比较有限,但训练成本也比较低。
⌚️聚类模型现在可以使用 GPU 训练了,只要约不到 1 分钟即可完成训练。
聚类模型的训练基于数据集,因此请在预处理完成后再训练聚类。
关于特征检索
特征检索和聚类方案一样,可以减少音色泄露,使得模型的输出更像目标音色,但特征检索的咬字比聚类稍好一些。特征检索同样使用了混合比例,可以线性控制特征检索的占比。启用特征检索会稍微降低推理速度(不是很明显)。要启用特征检索:
1需要完成数据集预处理
2需要训练一个特征检索模型
⚠️在云端训练的特征检索模型,因为依赖不一致,可能在本地无法加载。
特征检索模型的大小与训练集大小挂钩,较大的数据集将会训练出较大的特征检索模型。
3特征检索和聚类方案共用参数,在推理时启用特征检索将会自动禁用聚类。

若有收获,就点个赞吧
0 人点赞
