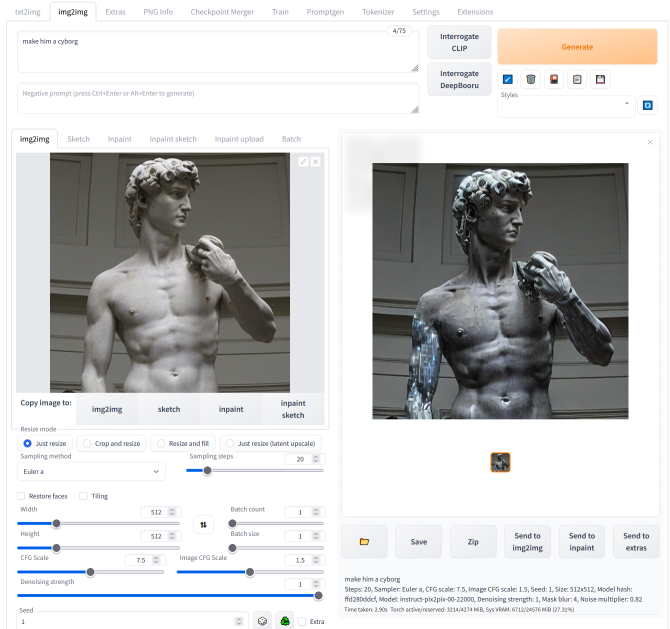
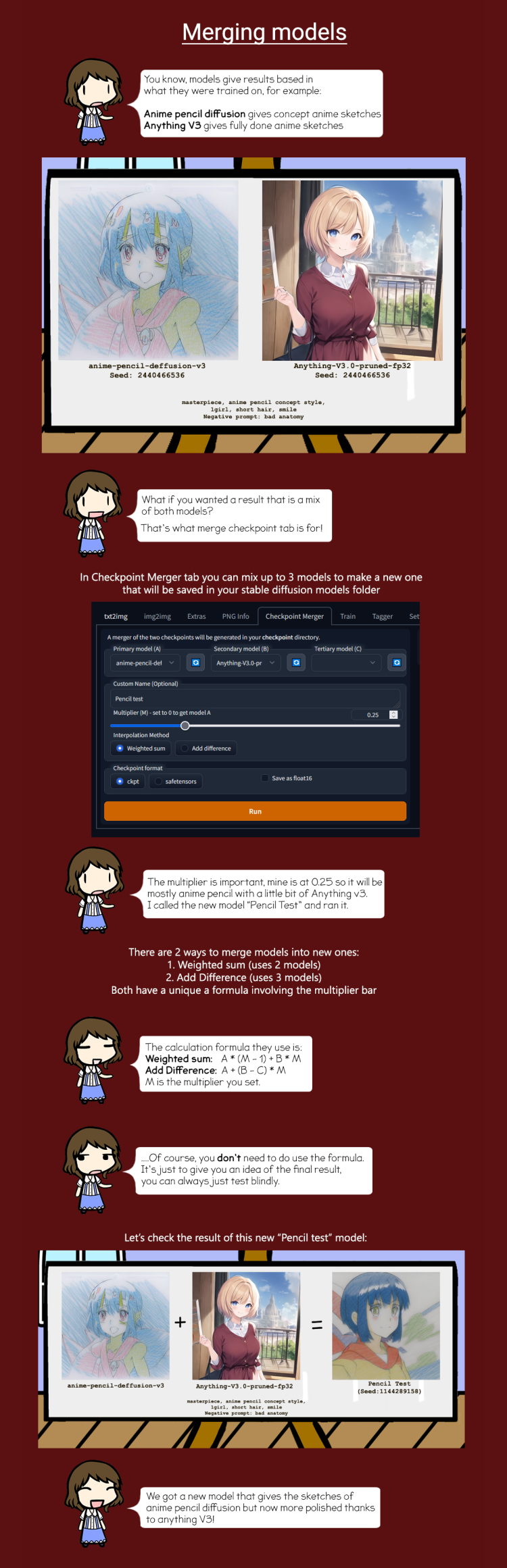
InstructPix2Pix
Checkpoint 在img2img标签中完全受支持。不需要额外的操作。以前,需要一个贡献者的扩展来生成图片:现在不再需要,但应该仍然有效。大部分的img2img实现都是由同一个人完成的。
要复现原始存储库的结果,请使用 denoising 1.0、Euler a采样器,并编辑configs/instruct-pix2pix.yaml中的配置,将其改
改成:
Extra networks
一个带有卡片图片的按钮。它将多种扩展融合到一个界面中。
在大的生成按钮旁找:

Extra networks 提供一组卡片,每张卡片对应一份模型文件,您可以训练或从其他地方获取部分模型。单击卡片将模型添加到 prompt 中,以影响生成图像
| Extra network | 目录 | 文件类型 | 在prompt 符中的使用方法 |
|---|---|---|---|
| Textual Inversion | embeddings | *.pt,images | 嵌入的文件名 |
| Lora | models/Lora | *.pt | |
| Hypernetworks | models/hypernetworks | .pt,.ckpt,*. safetensors |
Textual Inversion
CLIP中用于Stable Diffusion的标记权重微调方法,该方法源于2021年夏季。 作者网站。 Textual Inversion
LoRa
用于CLIP和Unet的权重微调方法,这是2021年由Stable Diffusion使用的语言模型和实际图像去噪器。论文。训练Lora的好方法是使用kohya-ss。
Web UI 内置了对 Lora 的支持,但是 kohya-ss 的原始实现 扩展 也可用。
现在,Web UI不支持Stable Diffusion 2.0+模型的Lora网络。
通过将以下文本放入任意位置,可以将Lora添加到prompt 中:
添加“Lora”到 prompt 中
超网络 Hypernetworks
使用的语言模型和实际图像去噪器,由我们的朋友 Novel AI 在2022年秋天慷慨捐赠。其工作方式与Lora相同,但其某些层会共享权重。可以使用 multiplier 来选择 Hypernetworks 将对输出产生多大的影响。
添加超级网络到 prompt 中的规则与 Lora 相同:hypernet:filename:multiplier。
Alt-Diffusion
一个训练有素的模型,能够接受多种语言的输入。更多信息。PR。
●请从Huggingface下载 Checkpoint
●将文件放入 models/Stable-Diffusion。
从理论上说,支持强调机制,但似乎作用很小,可能是由于 Alt-Diffusion 的实现方式所致。 Clip skip 不受支持,该设置被忽略。
●建议使用 —xformers 运行。添加额外的节省内存的参数并不起作用,例如 —xformers —medvram 。
Stable Diffusion 2.0
1从Huggingface下载您的Checkpoint 文件。
2把文件放入models/Stable-Diffusion文件夹中。
●768 (2.0) - (model, yaml)
●768 (2.1) - (model+yaml) - .safetensors
●512 (2.0) - (model, yaml)
如果2.0或2.1生成黑色图像,请使用“—no-half”启用完整精度,或尝试使用“—xformers”优化。
注:由于其新的 cross attention module 模块,SD 2.0和2.1更容易受到FP16数值不稳定性的影响(如他们在此处所述)。
关于fp16: 在webui-user.bat中启用注释
深度引导模型 Depth Guided Model
该深度引导模型(depth-guided model) 仅适用于 img2img 标签。更多信息。PR。
●512 depth (2.0) - (model+yaml) - .safetensors
●512 depth (2.0) - (model, yaml)
图像修复模型SD2 Inpainting Model SD2
专为 SD 2.0 512 基础训练而设计的修复模型。
●512 inpainting (2.0) - (model+yaml) - .safetensors
inpainting_mask_weight 修复条件遮罩强度也会受到影响
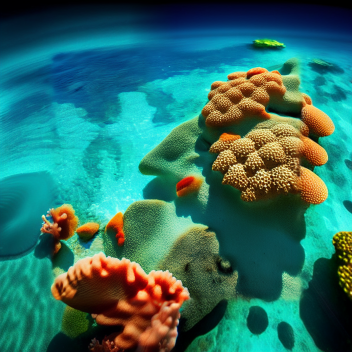
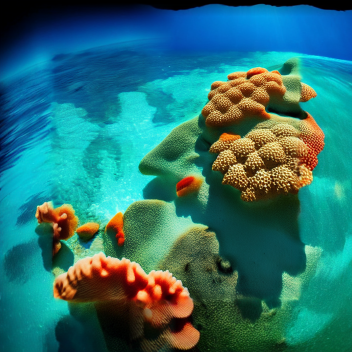
外扩技术 Outpainting extends
外扩技术(Outpainting extends)在原图的基础上进行扩展并填补所创造的空白区域。
例如:
| 原始 | 塗鴉 | 再次塗鴉 |
|---|---|---|
 |
 |
 |
原始图像来自4chan的匿名用户。谢谢匿名用户。
在“img2img”选项卡底部可以找到该功能,在“脚本”下可以找到“Poor man’s outpainting”选项。
与普通图像生成不同,外观绘制似乎非常受益于大步数。一种好的外观绘制的配方是一个符合图片的好prompt ,去噪和 CFG 规模滑块设置为最大,50到100步的 Euler ancestral 或 DPM2 ancestral 采样器。
| 81 步,Euler A | 30 步,Euler A | 10 步,Euler A | 80 步,Euler A |
|---|---|---|---|
 |
 |
 |
 |
Inpainting
在img2img选项卡中,对图像的一部分进行遮罩处理,被遮罩处理的部分将会被修复。

修复选项:
● 在网络编辑器中自己画一个遮罩。
● 使用外部编辑器擦除图片的一部分,并上传透明的图片。任何稍微透明的区域都将成为遮罩的一部分。请注意,某些编辑器 默认将完全透明的区域保存为黑色。
● 将模式更改为“上传遮罩”(图片右下方),并为遮罩选择单独的黑白图像(白色=修复)。
修复模型 Inpainting model
RunwayML 已经训练了一个专门用于修复图像缺陷的模型。这个模型可以接受额外的输入 - 没有噪点的初始图像和遮罩,而且看起来在这方面的表现要好得多。
下载和模型的信息在这里:https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion。
要使用该模型,您必须将Checkpoint 重命名为以 inpainting.ckpt 结尾的文件名,例如 1.5-inpainting.ckpt。
之后,只需像选择其它 Checkpoint 一样选择这个 Checkpoint ,就可以了。
屏蔽内容 Masked content
屏蔽内容字段确定内容被放置到遮罩区域之前进行修复。这不代表最终输出,仅仅是在中间过程中的展示。
| 遮罩 | 填充 | 原始图像 | 潜在噪声 | 潜在空白 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
修复区域 Inpaint area
通常情况下,修复图像会将图像大小调整到 webUI 中指定的目标分辨率。启用“仅遮罩修复区域”后,只有遮罩区域被调整大小,处理后再粘贴回原始图像。这使得您可以使用大图片并以更高的分辨率渲染修复图片。
| 输入 | 修复区域:整张图片 | 修复区域:仅遮罩区域 |
|---|---|---|
 |
 |
 |
遮罩模式 Masking mode
有两种遮罩模式:
●Inpaint masked -在蒙版下的区域被修复。
●Inpaint not masked - 修复不遮掩区域-遮罩下面保持不变,其他部分被修复了。
锐化遮罩 Alpha mask
| 输入 | 输出 |
|---|---|
 |
 |
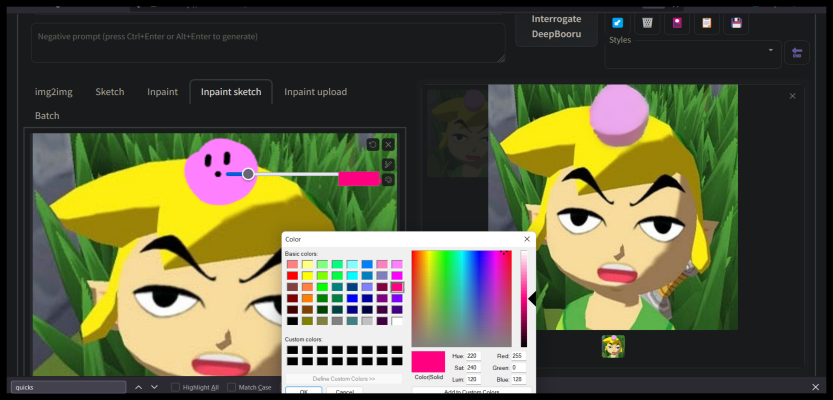
颜色素描 Color Sketch
基本着色工具适用于img2img选项卡。基于Chromium的浏览器支持吸管工具。
Prompt 矩阵 Prompt matrix
请使用|字符分隔多个prompt ,系统将为每个组合生成一张图像。例如,如果您使用“a busy city street in a modern city|illustration|cinematic lighting” prompt ,则有四种可能的组合(prompt 的第一部分始终保留):
●a busy city street in a modern city 现代城市中繁忙的街道
●a busy city street in a modern city, illustration 现代城市中繁忙的街道,插图
●a busy city street in a modern city, cinematic lighting 现代城市中繁忙的街道,银幕灯光。
●a busy city street in a modern city, illustration, cinematic lighting现代城市繁忙的街道,插画,电影般的灯光。
将会生成四张图片,按照顺序排列,所有图片都使用同一个“种子”并与对应的 prompt 一起出现:
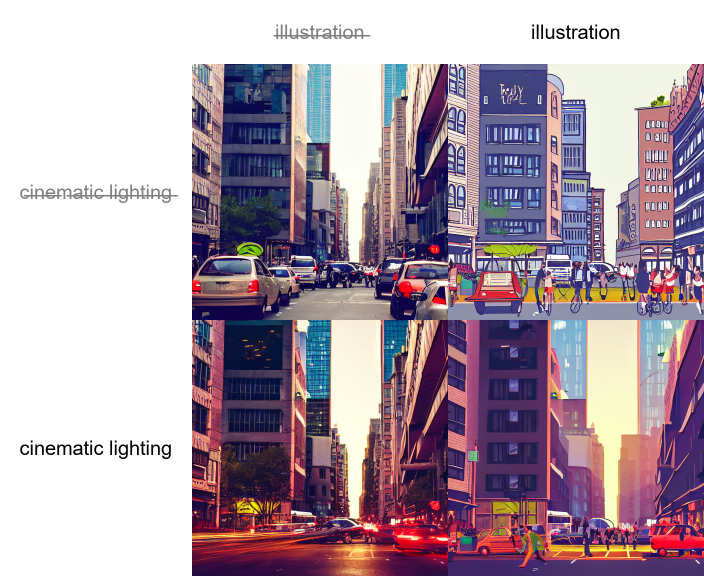
另一个例子,这次有5个prompt 和16个组合变体。

你可以在底部找到该功能,在“脚本->prompt matrix”下面。
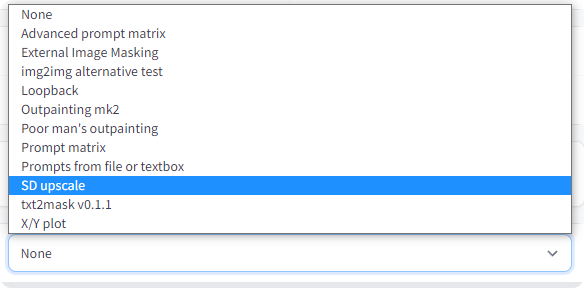
Stable Diffusion upscale
使用 RealESRGAN / ESRGAN 升级图像,然后通过结果的几个 tiles,使用img2img进行改进。它还可以选择让您自己在外部程序中完成升级部分,然后使用img2img浏览tiles。
此为独立实现,原始想法来自于:https://github.com/jquesnelle/txt2imghd。
使用此功能,请从脚本下拉选项中选择“SD upscale”(img2img选项卡)。
输入的图像将被放大到原始宽度和高度的两倍,UI的宽度和高度滑块指定了单个tiles的大小。由于四方连续,tiles 的大小非常重要:512x512图像需要九个512x512 tile(用于重叠),但只需要四个640x640 tile。
推荐的扩展参数:
●取样方法:Euler a
●去噪强度:0.2,如果你想挑战一下,可以调高到0.4
| Original | RealESRGAN | Topaz Gigapixel | SD upscale |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
无限 prompt 长度 Infinite prompt length
超过标准75个tokens的输入会导致Stable Diffusion接受更高的prompt 大小限制,从75增加到150。再写更多字的话会进一步增加 prompt 大小。这是通过将 prompt 分成75个tokens的块,独立处理每个块,使用CLIP的Transformers neural network ,然后在反给Stable Diffusion 的下一个组件Unet之前将结果连接在一起完成处理。
例如,包含120个tokens的prompt 将被分成两个块:第一个块包含75个tokens,第二个块包含45个tokens。两者都将填充到75个tokens,并使用起始/结束标记扩展到77。通过CLIP传递这两个块后,我们将获得两个形状为(1,77,768)的张量。将这些结果连接起来形成(1,154,768)张量,然后传递给Unet。
中断关键字 BREAK keyword
添加一个大写的 BREAK 关键词会用填充字符填满当前块。在 BREAK 文本后面添加更多文本会开始一个新的块。
Attention/emphasis
使用括号()可以增加模型对其内含词的关注度,而使用方括号[]则会减少它的关注度。您可以组合多个修饰符。

Cheat sheet:
●a (word) - 提高对(word)的关注度1.1倍
●a ((word)) - 将对 词语 的关注度提高1.21倍 (= 1.1 1.1)`
●a [word] - 将对[单词]的关注度降低1.1倍
●a (word:1.5) - 将“word”的关注度增加1.5倍。
●a (word:0.25) - 将对「word」的关注降低四倍(即 1/0.25)。
●a (word) - 在 prompt 中直接使用()字符
使用括号(),可以指定文字的权重,例如:(text:1.4)。如果没有指定权重,则默认为1.1。只有应用括号()才能指定权重,而不能在方括号[]中指定。
如果你想在 prompt 中使用任何 ()[] 字符(不是指定关注度用,而是直接用这个符号),请使用反斜杠来转义它们:anime_(角色)。
2022年9月29日,新的实现方式支持转义字符和数字权重。新实现的缺点是旧的并不完美,有时会吃掉字符:例如 a (((farm))), daytime ,没有逗号会变成 “a farm daytime”。 这种行为不同于新的实现,新的实现可以正确保留所有文本,这意味着您保存的种子可能会产生不同的图片。 目前,在设置中有一个选项可以使用旧的实现。
NAI 使用我在 2022-09-29 之前的实现,除了他们使用1.05作为乘数,并使用“{ }”而不是“()”。因此,转换适用:
● 他们的{word} = 我们的(word:1.05)
● 他们的{{word}} = 我们的 (word:1.1025)
● 他们的[word] = 我们的 (word:0.952) (0.952 = 1/1.05)
● 他们的[[word]] = 我们的 (word:0.907) (0.907 = 1/1.05/1.05)
*Lookback
在img2img中选择 loopback 脚本,可以自动将输出图像作为下一批输入。相当于保存输出图像,并用它替换输入图像。批次计数设置控制此操作的迭代次数。
通常情况下,你会自己选择下一次迭代中的许多图里的一张,因此这个功能的实用性可能会受到质疑,但我用它地得到了很好的输出结果,否则我是办不到的。
例子:(精选结果)

由4chan匿名用户原创图片。谢谢匿名用户。
X/Y/Z plot
创建多个具有不同参数的图像网格。X 和 Y 被用作行和列,而 Z 网格则用作批量尺寸。

使用 X 类型、Y 类型和 Z 类型字段选择应由行、列和批处理共享的参数,并将这些参数分别输入到 X/Y/Z 值字段中,支持整数、浮点数和范围。示例:
●简单区间:
○1-5 = 1, 2, 3, 4, 5
●以括号表示的带增量的范围
○1-5 (+2) = 1, 3, 5
○10-5 (-3) = 10, 7
○1-3 (+0.5) = 1, 1.5, 2, 2.5, 3
●括号中的计数范围
○1-10 [5] = 1, 3, 5, 7, 10
○0.0-1.0 [6] = 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
Prompt S/R
Prompt S/R是X/Y Plot中较难理解的操作模式之一。S/R代表搜索/替换,也就是它的功能 - 您输入一个单词或短语列表,它将列表中的第一个作为关键字,并用列表中的其他条目替换该关键字的所有实例。”
例如,使用prompt a man holding an apple, 8k clean,和prompt an apple, a watermelon, a gun ,您将得到三个prompt :
●a man holding an apple, 8k clean 一个人拿着苹果,8K清晰。
●a man holding a watermelon, 8k clean 一个拿着西瓜、8k 清晰的男人。
●a man holding a gun, 8k clean 一个持枪男子,8K无清晰。 该列表使用与CSV文件中的行相同的语法,因此如果您想在条目中包含逗号,则必须将文本放在引号中,并确保引号和分隔逗号之间没有空格:
●darkness, light, green, heat - 4个条目 - darkness, light, green, heat
●darkness, “light, green”, heat - 错误的 - 4 个条目 - darkness, “light, green”, heat
●darkness,”light, green”,heat - 正确的 - 3 个条目 - darkness, light, green, heat
文本 prompts 或文件 prompts
使用此脚本可以创建一个作业列表,这些作业将按顺序执行。
示例输入:
示例输出:

支持以下参数:
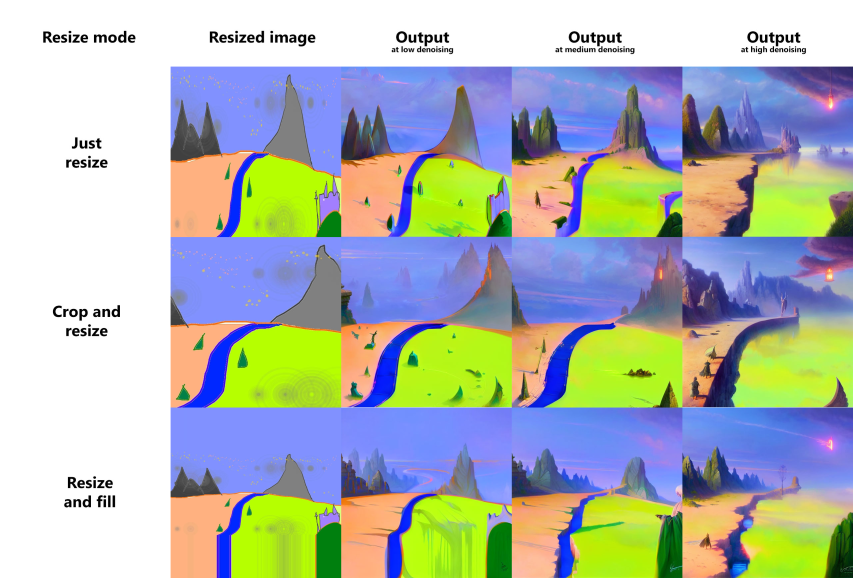
调整尺寸
在img2img模式下,调整输入图像大小有三个选项:
● 只需调整大小 - 只需将源图像调整到目标分辨率,导致不正确的宽高比。
● 裁剪和调整大小-调整源图像的大小以保持纵横比,使其充满目标分辨率,并裁剪出突出的部分。
● 调整大小并填充-调整源图像大小以保留宽高比,使其完全适合目标分辨率,并通过源图像的行/列来填充空白处。 例子:
Sampling method selection
从多个抽样方法中选择txt2img:

调整种子
这个函数允许您在不同分辨率下从已知种子生成图像。通常情况下,当您改变分辨率时,图像会完全改变,即使您保留所有其他参数,包括种子。 使用种子调整大小,您可以指定原始图像的分辨率,模型很可能会在不同的分辨率下生成非常相似的图像。在下面的示例中,最左边的图片是512x512,其他图片使用相同的参数生成,但纵向分辨率更大。
| 信息 | 图像 |
|---|---|
| 未启用种子调整大小 |  |
| 种子从512x512调整大小 |  |
Variations
Ancestral 采样者在这方面略逊一筹。 你可以通过在种子附近勾选“额外(Extra)”复选框来找到这个功能。 一种变化强度滑块和变化种子字段允许您指定现有图片应该怎样被改变来看起来更像另一张图片。在最大强度时,您将得到带有变化种子的图片,而在最小时- 带有原始种子的图片(除非使用Ancestral采样器)。

你可以通过在种子旁边勾选“额外(Extra)”复选框来找到这个功能。
样式 Styles
按下“保存样式prompt ”按钮,将当前prompt 保存到styles.csv,该文件包含样式集合。prompt 右侧的下拉框允许您选择以前保存的任何样式,并自动将其添加到您的输入。要删除样式,请从styles.csv手动删除并重新启动程序。
如果您在样式中使用特殊字符串“{prompt}”,它将替换当前prompt 中的所有内容,而不是将该样式附加到prompt 中。
负面提示 Negative prompt
允许您使用另一个prompt 来告诉模型在生成图片时不要的东西。这是通过在采样过程中使用负面 prompt 来实现,而不是使用空字符串。 详解: Negative prompt
| 原始 | 负面:紫色 | 负面:触手 |
|---|---|---|
 |
 |
 |
原文来自: https://github.com/pharmapsychotic/clip-interrogator
CLIP问询器 CLIP interrogator
CLIP问询器(CLIP interrogator)可以从图像中检索prompt 。prompt 可能无法重现相同的图像(有时甚至无法接近),但它可以是一个不错的开始。
第一次运行CLIP询问器时,它会下载几个GB的模型。
CLIP问询器有两个部分:一个是BLIP模型,它从图片中创建文本描述。另一个是CLIP模型,将从列表中挑选与图片相关的几行。默认情况下,只有一个列表-艺术家列表(来自artists.csv)可以通过以下操作添加更多列表:
● 在与webui相同的地方创建“问询(interrogate)”目录。
● 将文本文件放在其中,并在每行上写上相关的描述。 如要使用的文本文件,请参见[https://github.com/pharmapsychotic/clip-interrogator/tree/main/clip_interrogator/data]。 实际上,你可以直接使用那里的文件 - 只需跳过artists.txt,因为你已经拥有artists.csv中艺术家列表(或者也可以使用)。每个文件会向最终描述添加一行文本。例如,如果你在文件名中添加”.top3.”,比如flavors.top3.txt,则会将该文件中最相关的三行添加到prompt 中(其他数字也可以使用,比如.top7)。 这个功能相关的设置有:
●Interrogate: keep models in VRAM - 使用后不卸载内存里的模型。针对拥有大量VRAM的用户
●Interrogate: use artists from artists.csv - 在Interrogate时,从artists.csv中添加艺术家。当您在‘Interrogate’目录中拥有自己的艺术家列表时,禁用此选项可能会有用。
●Interrogate: num_beams for BLIP - 影响BLIP模型的详细描述的参数(生成提示的第一部分)
●Interrogate: minimum description length - BLIP模型文本的最小描述长度
●Interrogate: maximum descripton length - BLIP模型文本的最大描述长度
●Interrogate: maximum number of lines in text file - interrogator 只会考虑文件中的前 x 行。设置为0,则默认为1500行,这是一个4GB显卡可以处理的最大值。
编辑 Prompt

其中from和to是任意的文本,when是一个数字,它定义了在采样周期的什么时候应该进行切换。越晚,模型在替换from文本为to文本时的能力就越弱。如果when是介于0和1之间的数字,则它是在多少步之后进行切换的数。如果它是一个大于零的整数,则只是在哪一步之后进行切换。 编辑嵌套内的 prompt 在也会影响其它的。 此外:
●[to:when] - 在固定步骤(“when”)后,将“to”添加到prompt 中
●[from::when] - 从开始 [when] 步骤后移除 from示例: a [fantasy:cyberpunk:16] landscape
● 开始时,模型将绘制一个幻想景观 a fantasy landscape 。
● 在第16步之后,它将切换到绘制“赛博朋克风景”a cyberpunk landscape,继续从幻想停止的地方开始。 Here’s a more complex example with multiple edits: fantasy landscape with a [mountain:lake:0.25] and [an oak:a christmas tree:0.75][ in foreground::0.6][ in background:0.25] [shoddy:masterful:0.5] (sampler has 100 steps) 这是一个更复杂的例子,包括多次编辑:fantasy landscape with a [mountain:lake:0.25] and [an oak:a christmas tree:0.75][ in foreground::0.6][ in background:0.25] [shoddy:masterful:0.5](该样本有100个步骤)。
● 开始,前景是一座山和一棵橡树的幻想景观,质量较差, fantasy landscape with a mountain and an oak in foreground shoddy。
● 步骤25后, fantasy landscape with a lake and an oak in foreground in background shoddy“幻想风景画面,有一片湖泊和一棵橡树在前景和后景中显得很粗糙。
● 50步之后, fantasy landscape with a lake and an oak in foreground in background masterful以湖和橡树为前景,背景为梦幻景色的画面十分出色。
● 在第60步之后, fantasy landscape with a lake and an oak in background masterful带有湖和远景橡树的幻想景观非常出色。
● 步骤75后, fantasy landscape with a lake and a christmas tree in background masterful背景中的幻想湖和圣诞树非常精彩。
顶部的图片是根据prompt 制作的:
Official portrait of a smiling world war ii general, [male:female:0.99], cheerful, happy, detailed face, 20th century, highly detailed, cinematic lighting, digital art painting by Greg Rutkowski’s
二战时期的官方肖像画,一位微笑的将军,男性,愉快、开心,面部细节清晰,20世纪,高度详细,电影化的灯光效果,由格雷格·鲁特科夫斯基的数字艺术绘制
数字0.99将被替换为您在图像列标签中看到的内容。
图片中的最后一列是[male:female:0.0],这意味着您要求模型从头开始绘制一名女性,而不是从男性普通角色开始,这就是为什么它看起来与其他人如此不同的原因。
交替单词 Alternating Words
方便的语法来交换每两个步骤。
第1步,prompt 是“田野里有一头牛cow in a field”。第2步是“田野里有一匹马horse in a field”。第3步是“田野里有一头牛cow in a field”,以此类推。

请查看下面的高级示例。在第8步,链条会从“人”循环回到“牛”。
Doggettx在 this myspace.com post 首次实现了快速编辑。
Hires. fix
提供便捷选项,以较低的分辨率渲染您图像的一部分,然后以高分辨率添加细节。默认情况下,txt2img 在非常高的分辨率下制作奇奇怪怪的图像,这使得可以避免使用小图片的组合。启用方法是在txt2img页面上勾选Hires.fix复选框。
| 不使用 | 使用 Hires. fix |
|---|---|
 |
 |
 |
 |
小图由宽度/高度滑块设置分辨率进行渲染。大图的尺寸由三个滑块控制:“Scale by”倍数(高分辨率放大),“Resize width to”和/或“Resize height to”(高分辨率调整大小)。
●如果“Resize width to”和“Resize height to”的值为0,则使用“按比例缩放”。
●如果“Resize width to”为0,则从宽度和高度计算“Resize height to”。
●如果“Resize height to”为0,则从宽度和高度计算“Resize width to”。
●如果”Resize width to”和”Resize height to”都不为零,则图像将被放大至至少这些尺寸,并且部分内容将被裁剪。
升频器 Upscalers
下拉菜单允许您选择用于调整图像大小的升频器的类型。除了您在附加选项卡上可用的所有升频器之外,还有一个选项可将潜在空间图像升频,这就是Stable Diffusion 在内部使用的方式 - 对于一个3x512x512的RGB图像,它的潜在空间表示将是4x64x64。要查看每个潜在空间升频器的作用,您可以将降噪强度设置为0,将高分辨率步骤设置为1 - 您将得到一个非常好的近似,该 Stable Diffusion 将处理升频图像。
这里是不同的潜在升级模式的示例。
| 原件 |
|---|
 |
| 潜在 (无抗锯齿), 潜在 (抗锯齿) | 潜在 (双三次), 潜在 (双三次, 抗锯齿) | 潜在 (最近邻) |
|---|---|---|
 |
 |
 |
在贡献者引入抗锯齿变体之后,它们似乎与非抗锯齿变体相同。
Composable Diffusion
一种允许组合多个prompt 的方法。使用大写字母AND组合prompt 。
支持prompt 权重:a cat :1.2 AND a dog AND a penguin :2.2。默认权重值为1。将多个嵌入组合到您的结果中非常有用:creature_embedding in the woods:0.7 AND arcane_embedding:0.5 AND glitch_embedding:0.2
使用低于0.1的值将几乎没有影响。a cat AND a dog:0.03与a cat输出基本相同。
这可以用于生成精细调整的递归变体,通过继续附加更多 prompt 到您的总体中。creature_embedding on log AND frog:0.13 AND yellow eyes:0.08。
中断 Interrupt
按下中断按钮来停止当前处理。
4GB 显卡支持
化适用于 VRAM 较低的 GPU,使得在4GB内存的显卡上能生成 512x512 的图像。 —lowvram 是basujindal提出的优化思路的重新实现。模型被分成多个模块,只有一个模块保留在GPU内存中;当需要运行另一个模块时,前一个模块将从GPU内存中删除。这种优化的性质使得处理速度变慢——与我使用 RTX 3090 的正常操作相比,慢大约10倍。
-medvram是另一种优化,可以显著减少VRAM的使用量,不会在同一批次中同时处理有条件和无条件的降噪。
此优化实现不需要修改原始的 Stable Diffusion 代码。
面部修复 Face restoration
使用 GFPGAN 或 CodeFormer 可以改善照片中的面部。每个选项卡都有一个复选框可以使用面部修复,还有一个单独的选项卡可以让您在任何图片上使用面部修复,滑块可以控制效果的程度。您可以在设置中选择这两种方法。
| 原图 | GFPGAN | CodeFormer |
|---|---|---|
 |
 |
 |
Checkpoint Merger
一位匿名的慷慨捐赠者提供的指南
完整指南及其他信息,请查看此处:https://imgur.com/a/VjFi5uM。
保存 Saving
点击输出部分下面的保存按钮,生成的图片将保存到在设置中指定的目录中;生成参数将附加到同一目录中的csv文件中。
加载 Loading
Gradio 的加载图像对神经网络处理速度有非常负面的影响。当不活动的标签中没有Gradio时,我的RTX 3090可将图像制作得快大约10%。默认情况下,UI现在隐藏了加载进度动画,并用静态的 “加载中…” 替换,可以达到相同的效果。可以使用 —no-progressbar-hiding 命令行选项来恢复此设置并显示加载动画。
Prompt 验证
Stable Diffusion 有输入文本长度限制。如果您的prompt 太长,将在文本输出字段中会出出现警告,显示模型截断并忽略的文本部分。
png 信息
有关生成参数的信息会作为文本块添加到PNG文件中。您可以使用支持查看PNG块信息的软件查看图片信息,例如:https://www.nayuki.io/page/png-file-chunk-inspector。
设置
设置选项卡的界面,可以让你编辑先前只能通过命令行编辑的参数(超过一半)。设置会被保存到config.js文件中。作为命令行选项的保留设置,必须在启动时使用。
设置选项卡中的Images filename pattern字段允许定制生成的txt2img和img2img图片文件名。该模式定义了要包含在文件名中的生成参数及其顺序。支持的标签包括: [steps], [cfg], [prompt], [promptno_styles], [prompt_spaces], [width], [height], [styles], [sampler], [seed], [model_hash], [prompt_words], [date], [datetime], [job_timestamp].
这个列表会不断增加,会有新的标签加入。你可以将鼠标悬停在UI界面中Images filename pattern标签上,以获取最新的支持标签列表。
一种模式的例子:[seed]-[steps]-[cfg]-[sampler]-[prompt_spaces]
关于“prompt”标签的说明:[prompt]会在 prompt 词之间添加下划线,而[prompt_spaces]则会保留prompt 词的原样(更容易复制/粘贴)。[prompt_words]是您的 prompts 的简化和清理版本,已用于生成子目录名称,仅包含您的 prompt 单词(没有标点符号)。
如果您不填写此字段,则会应用默认模式([seed]-[prompt_spaces])。 请注意,标签实际上是在 pattern 内替换的。这意味着您也可以将非标签的单词添加到此 pattern 中,让文件名更好用。例如:s=[seed],p=[prompt_spaces]。
用户脚本 User scripts
如果以 —allow-code 选项启动程序,则在页面底部的 Scripts -> Custom code下提供额外的文本输入字段以输入脚本代码,以便您可以输入 Python 代码处理图像。 在代码中,使用p变量从Web UI访问参数,并使用display(images,seed,info)函数为Web UI提供输出。脚本中的所有全局变量也是可访问的。 一个简单的脚本,只需处理图像并正常输出。
UI配置 UI config
你可以在程序首次启动时自动创建的ui-config.json文件中更改UI元素的参数。 一些选项:
●单选组:默认选择
●滑动条:默认值,最小值,最大值,步长。
●复选框:选中状态
●文本和数字输入:默认值
当复选框被设置为UI配置条目时,通常会展开隐藏的部分,但初始不会。
ESRGAN 模型
可以在Extras选项卡和 SD upscale 中使用 ESRGAN 模型。 将 ESRGAN 模型放入 ESRGAN 目录中,与 webui.py 文件位于同一位置。只要文件具有.pth扩展名,就会将其加载为模型。从Model Database.中获取模型。 数据库中不是所有的型号都被支持。所有 2x 型号很可能都不被支持。 使用 Euler diffuser 的反向来分解输入图像,以创建用于构建输入 prompt 的噪声模式。 例如,您可以使用这张图片。从scripts_部分选择img2img替代测试。

请调整你的设置以进行重建过程:
●使用一个简短的场景描述:“A smiling woman with brown hair.” 描述您想更改的特征会有所帮助。将此设置为您的起始 prompt ,“脚本设置”中的“原始输入 prompt ”。
●你必须使用 Euler 采样方法,因为这个脚本是基于它构建的。
●采样步骤:50-60。在脚本中,这个值必须匹配解码步骤值,否则你会遇到麻烦。此示例使用50。
●CFG scale:2或以下。对于此演示,请使用1.8。(prompt :您可以编辑ui-config.json将“img2img/CFG Scale/step”更改为0.1而非0.5。
●去噪强度(Denoising strength)-这确实很重要,与旧文档所说相反。将其设置为1。
●请使用输入图像的宽度/高度。
●种子…你可以忽略它。现在反Euler正在为图像生成噪音。
●解码 cfg 比例(Decode cfg scale) - 在 1 以下的是完美的点。为了演示,使用 1。
●解码步骤(Decode steps)-如上所述,这应该与您的采样步骤匹配。演示用50,考虑增加到60以获得更详细的图像。
一旦上述所有内容都调好了,你就可以点击“生成”并获得一个非常接近原始的结果。 在验证脚本以高度准确性重新生成源照片后,您可以尝试更改 prompt 的细节。原始图像的较大变化可能会导致图像与源完全不同。 使用上述设置和以下 prompts 的示例输出(未显示红色头发/马尾)

user.css
创建一个名为user.css的文件并放置在webui.py同目录,将自定义CSS代码放入其中。例如,这样可以使画廊变高:
Plain Text 1 2 3 #txt2img_gallery, #img2img_gallery{ min-height: 768px; }
一个有用的提示是,您可以在您的网页界面链接后加入/?theme=dark来启用内置的深色主题。 例如(http://127.0.0.1:7860/?theme=dark) 或者,您可以在webui-user.bat中的set COMMANDLINE_ARGS=中添加—theme = dark例如. set COMMANDLINE_ARGS=—theme=dark
notification.mp3
如果网页用户界面的根目录中存在名为notification.mp3的音频文件,则在生成完成会播放该文件。
灵感的来源:
●https://pixabay.com/sound-effects/search/ding/?duration=0-30
●https://pixabay.com/sound-effects/search/notification/?duration=0-30
Tweaks
剪辑跳过 Clip Skip
这是设置中的滑块,它控制着 CLIP 网络处理 prompt 停止的时间。
详解:
CLIP是一种非常先进的神经网络,它可以将您的 prompts 文本转换为数字表示形式。神经网络可以很好地处理这种数字,这就是为什么SD的开发人员选择CLIP作为生产图像的Stable Diffusion 方法中涉及的三个模型之一。由于CLIP是神经网络,所以它有很多层。您的prompt s 以简单的方式数字化,然后通过各层层层传递。在第一层后,您可以获得prompt 的数字表示,然后将其馈送到第二层,将结果馈送到第三层等等,直到达到最后一层,这就是用于Stable Diffusion 的CLIP输出。这时滑块值为1。但是,您可以提前停止并使用倒数第二层的输出-这时滑块值为2。您越提前停止,神经网络所使用的层数就越少。
一些模型是用这种微调训练的,因此设置这个值有助于在这些模型的训练程度。

若有收获,就点个赞吧
0 人点赞
