二叉树的序列化
题目描述
「二叉树的序列化和反序列化」就是给你输入一棵二叉树的根节点 root,要求你实现如下一个类:
class Codec {// 把一棵二叉树序列化成字符串string serialize(TreeNode* root) {}// 把字符串反序列化成二叉树TreeNode* deserialize(string data) {}};
可以用 serialize 方法将二叉树序列化成字符串,用 deserialize 方法将序列化的字符串反序列化成二叉树。
比如,输入如下这样一棵二叉树:

serialize 方法也许会将它序列化为 2, 1, #, 6, 3, #, #,其中 # 表示 nullptr 指针,将这个字符串再输入 deserialize 方法,依然可以还原出这颗二叉树。
前序遍历解法
前序遍历框架如下:
void traverse(TreeNode* root) {
if (root == nullptr)
return;
// 前序遍历代码
traverse(root->left);
traverse(root->right);
}
伪代码如下:
vector<int> res;
void traverse(TreeNode* root) {
if (root == nullptr) {
res.push_back(-1);
return;
}
// 前序遍历位置
res.push_back(root->val);
traverse(root->left);
traverse(root->right);
}
调用 traverse 函数之后,如下图,可以直观看出前序遍历做的事:
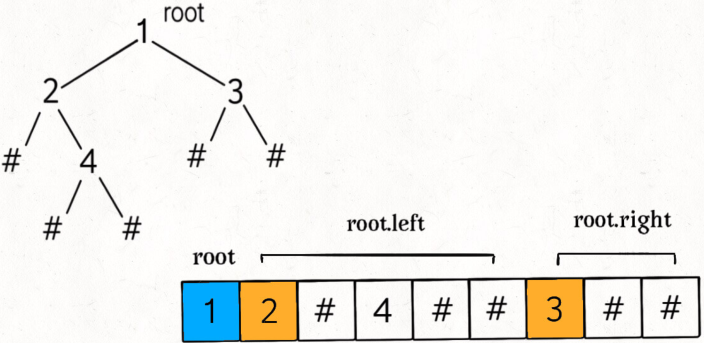
res = [1, 2, -1, 4, -1, -1, 3, -1, -1],这就是将二叉树「打平」到了一个列表中,其中 -1 表示 nullptr。
那么将二叉树打平到一个字符串中也是一样的:
// 代表分割符的字串
string sep = ",";
// 代表 nullptr 空指针的字符
string null_ = "#";
string str = "";
// 将二叉树打平为字符串
void traverse(TreeNode* root, string& str) {
if (root == nullptr) {
str += null_;
str += sep;
return;
}
// 前序遍历的位置
str += root->val;
str += sep;
traverse(root->left, str);
traverse(root->right, str);
}
至此,序列化函数 serialize 代码如下:
string sep = ",";
string null_ = "#";
// 辅助函数
void serialize(TreeNode* root, string& str) {
if (root == nullptr) {
str += null_;
str += sep;
return;
}
str += to_string(root->val);
str += sep;
serialize(root->left, str);
serialize(root->right, str);
}
// 主函数
string serialize(TreeNode* root) {
string str = "";
serialize(root, str);
return str;
}
现在,思考如何写 deserialize 函数,将字符串反过来构造二叉树。
首先可以把字符串转换为列表:
string data = "1, 2, #, 4, #, #, 3, #, #,";
list<string> split(const string& str, const string& ch) {
regex re(ch);
sregex_token_iterator first {str.begin(), str.end(), re, -1}, last;
return {first, last};
}
list<string> nodes = split(data, ",");
这样,nodes 列表就是二叉树的前序遍历结果,问题转换为:如何通过二叉树的前序遍历结果还原一棵二叉树?
PS:一般情况下,单单前序遍历结果是不能还原二叉树结构的,因为缺少空指针信息。
根据刚才分析,nodes 列表就是一棵打平的二叉树:

那么,反序列化过程也是一样的,先确定根节点 root,然后遵循前序遍历的规则,递归生成左右子树即可。
// 字符切割函数
list<string> split(const string& str, const string& ch) {
regex re(ch);
sregex_token_iterator first {str.begin(), str.end(), re, -1}, last;
return {first, last};
}
// 辅助函数
TreeNode* deserialize(list<string>& nodes) {
if (nodes.empty()) {
return nullptr;
}
// 前序遍历位置
// 列表最左侧是根节点
string first = nodes.front();
nodes.pop_front();
if (null == first) {
return nullptr;
}
TreeNode* root = new TreeNode(stoi(first));
root->left = deserialize(nodes);
root->right = deserialize(nodes);
return root;
}
// 主函数
TreeNode* deserialize(string data) {
// 将字符串转化为链表
list<string> nodes = split(data, sep);
return deserialize(nodes);
}
所以整体代码如下:
class Codec {
private:
string sep = ",";
string null = "#";
public:
/*序列化*/
// 辅助函数
void serialize(TreeNode* root, string& str) {
if (root == nullptr) {
str.append(null).append(sep);
return;
}
str.append(to_string(root->val)).append(sep);
serialize(root->left, str);
serialize(root->right, str);
}
// 主函数
string serialize(TreeNode* root) {
string str = "";
serialize(root, str);
return str;
}
/*反序列化*/
// 字符切割函数
list<string> split(const string& str, const string& ch) {
regex re(ch);
sregex_token_iterator first {str.begin(), str.end(), re, -1}, last;
return {first, last};
}
// 辅助函数
TreeNode* deserialize(list<string>& nodes) {
if (nodes.empty()) {
return nullptr;
}
// 前序遍历位置
// 列表最左侧是根节点
string first = nodes.front();
nodes.pop_front();
if (null == first) {
return nullptr;
}
TreeNode* root = new TreeNode(stoi(first));
root->left = deserialize(nodes);
root->right = deserialize(nodes);
return root;
}
// 主函数
TreeNode* deserialize(string data) {
// 将字符串转化为链表
list<string> nodes = split(data, sep);
return deserialize(nodes);
}
};
后续遍历解法
二叉树的后续遍历框架
void traverse(TreeNode* root) {
if (root == nullptr)
return;
traverse(root->left);
traverse(root->right);
// 后续遍历的代码
// todo
}
先实现序列化 serialize 函数
// 辅助函数
void serialize(TreeNode* root, string& str) {
if (root == nullptr) {
str.append(null).append(sep);
return;
}
str.append(to_string(root->val)).append(sep);
serialize(root->left, str);
serialize(root->right, str);
}
// 主函数
string serialize(TreeNode* root) {
string str = "";
serialize(root, str);
return str;
}
关键难点在于,如何实现后续遍历的 deserialize 函数。以下代码是错误的:
TreeNode* deserialize(list<string>& nodes) {
if (nodes.empty())
return nullptr;
root->left = deserialize(nodes);
root->right = deserialize(nodes);
// 后续遍历位置
string first = nodes.front();
nodes.pop_front();
if (null == first) {
return nullptr;
}
TreeNode* root = new TreeNode(stoi(first));
return root;
}
变量没有声明,不能提前使用。deserialize 函数,第一件事就是要寻找 root 节点的值,然后递归构造左右节点。在后续遍历中,root 的值是列表的最后一个元素。我们应该从后向前取出列表元素,先用最后一个元素构造 root,然后递归调用生成左右子树。
注意:从后往前在 nodes 列表中取元素,一定要先构造 root->right 子树,后构造 root->left 子树。
整体代码如下:
class Codec_ {
private:
string sep = ",";
string null = "#";
public:
/*序列化*/
// 辅助函数
void serialize(TreeNode* root, string& str) {
if (root == nullptr) {
str.append(null).append(sep);
return;
}
serialize(root->left, str);
serialize(root->right, str);
// 后序遍历位置
str.append(to_string(root->val)).append(sep);
}
// 主函数
string serialize(TreeNode* root) {
string str = "";
serialize(root, str);
return str;
}
/*反序列化*/
// 字符串切割函数
list<string> split(const string& str, const string& ch) {
regex re(ch);
sregex_token_iterator first {str.begin(), str.end(), re, -1}, last;
return {first, last};
}
// 辅助函数
TreeNode* deserialize(list<string>& nodes) {
if (nodes.empty()) {
return nullptr;
}
// 从后往前取出元素
string last = nodes.back();
nodes.pop_back();
if (null == last) {
return nullptr;
}
TreeNode* root = new TreeNode(stoi(last));
// 先构造右子树,再构造左子树
root->right = deserialize(nodes);
root->left = deserialize(nodes);
return root;
}
// 主函数
TreeNode* deserialize(string data) {
if (data.empty()) {
return nullptr;
}
list<string> nodes = split(data, sep);
return deserialize(nodes);
}
};
中序遍历解法
中序遍历无法实现反序列化函数 deserialize,因为无法找到 root 节点的值。
层序遍历解法
层序遍历二叉树的框架:
void traverse(TreeNode* root) {
if (root == nullptr)
return;
queue<TreeNode*> que;
vector<vector<int>> res;
que.push(root);
while (!que.empty()) {
vector<int> vec;
int len = que.size();
for (int i = 0; i < len; ++i) {
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if (node->left)
que.push(node->left);
if (node->right)
que.push(node->right);
}
res.push_back(vec);
}
}
上述代码是标准的二叉树层次遍历框架,队列中不会存在 nullptr 指针。但是在反序列的过程中是需要记录空指针的,所以需要略作修改:
void traverse(TreeNode* root) {
if (root == nullptr)
return;
queue<TreeNode*> que;
que.push(root);
while (!que.empty()) {
TreeNode* node = que.front();
que.pop();
if (node == nullptr)
continue;
cout << root->val << endl;
que.push(que->left);
que.push(que->right);
}
}
对空指针的检验从「将元素加入队列」的时候改为「从队列中取出元素」的时候。
string sep = ",";
string null = "#";
string serialize(TreeNode* root) {
if (root == nullptr) {
return "";
}
string str = "";
queue<TreeNode*> que;
que.push(root);
while (!que.empty()) {
TreeNode* node = que.front();
que.pop();
if (node == nullptr) {
str.append(null).append(sep);
continue;
}
str.append(node->val).append(sep);
que.push(root->left);
que.push(root->right);
}
return str;
}
层次遍历序列化得出的结果如下图:
可以看到,每个非空节点都会对应两个子节点,那么反序列化的思路也是用队列进行层次遍历,同时使用索引 i 记录对应子节点的位置。
代码如下:
class _Codec {
private:
string sep = ",";
string null = "#";
public:
string serialize(TreeNode* root) {
if (root == nullptr) {
return "";
}
string str = "";
queue<TreeNode*> que;
que.push(root);
while (!que.empty()) {
TreeNode* node = que.front();
que.pop();
if (node == nullptr) {
str.append(null).append(sep);
continue;
}
str.append(to_string(node->val)).append(sep);
que.push(node->left);
que.push(node->right);
}
return str;
}
vector<string> split(const string& str, const string& ch) {
regex re(ch);
sregex_token_iterator first {str.begin(), str.end(), re, -1}, last;
return {first, last};
}
TreeNode* deserialize(string data) {
if (data.empty()) {
return nullptr;
}
vector<string> nodes = split(data, sep);
// 第一个就是 root 的值
TreeNode* root = new TreeNode(stoi(nodes[0]));
// 队列记录父节点,将 root 加入队列
queue<TreeNode*> que;
que.push(root);
for (int i = 1; i < nodes.size(); ) {
// 队列中存的都是父节点
TreeNode* parent = que.front();
que.pop();
// 父节点对应的左侧子节点的值
string left = nodes[i++];
if (left != null) {
parent->left = new TreeNode(stoi(left));
que.push(parent->left);
} else {
parent->left = nullptr;
}
// 父节点对应的右侧子节点的值
string right = nodes[i++];
if (right != null) {
parent->right = new TreeNode(stoi(right));
que.push(parent->right);
} else {
parent->right = nullptr;
}
}
return root;
}
};
总结
三种解法总结如下:
/*使用前序遍历来实现*/
class Codec {
private:
string sep = ",";
string null = "#";
public:
/***
* @description: 辅助函数,序列化
* @param {TreeNode*} root
* @param {string&} str
* @return {*}
*/
void serialize(TreeNode* root, string& str) {
if (root == nullptr) {
str.append(null).append(sep);
return;
}
str.append(to_string(root->val)).append(sep);
serialize(root->left, str);
serialize(root->right, str);
}
/***
* @description: 主函数,序列化
* @param {TreeNode*} root
* @return {*}
*/
string serialize(TreeNode* root) {
string str = "";
serialize(root, str);
return str;
}
/***
* @description: 根据 ch 分割字符串 str
* @param {string&} str
* @param {string&} ch
* @return {*}
*/
list<string> split(const string& str, const string& ch) {
regex re(ch);
sregex_token_iterator first {str.begin(), str.end(), re, -1}, last;
return {first, last};
}
/***
* @description: 辅助函数,反序列化
* @param {*}
* @return {*}
*/
TreeNode* deserialize(list<string>& nodes) {
if (nodes.empty()) {
return nullptr;
}
// 前序遍历的第一个值为 root 节点的值
string first = nodes.front();
nodes.pop_front();
if (null == first) {
return nullptr;
}
TreeNode* root = new TreeNode(stoi(first));
root->left = deserialize(nodes);
root->right = deserialize(nodes);
return root;
}
/***
* @description: 主函数,反序列化
* @param {string} data
* @return {*}
*/
TreeNode* deserialize(string data) {
if (data.empty()) {
return nullptr;
}
list<string> nodes = split(data, sep);
return deserialize(nodes);
}
};
/*使用后序遍历来实现*/
class Codec_ {
private:
string sep = ",";
string null = "#";
public:
/***
* @description: 辅助函数,序列化
* @param {TreeNode*} root
* @param {string&} str
* @return {*}
*/
void serialize(TreeNode* root, string& str) {
if (root == nullptr) {
str.append(null).append(sep);
return;
}
serialize(root->left, str);
serialize(root->right, str);
str.append(to_string(root->val)).append(sep);
}
/***
* @description: 主函数,序列化
* @param {TreeNode*} root
* @return {*}
*/
string serialize(TreeNode* root) {
string str = "";
serialize(root, str);
return str;
}
/***
* @description: 字符串切割函数
* @param {string&} str
* @param {string&} ch
* @return {*}
*/
list<string> split(const string& str, const string& ch) {
regex re(ch);
sregex_token_iterator first {str.begin(), str.end(), re, -1}, last;
return {first, last};
}
/***
* @description: 辅助函数,反序列化
* @param {*}
* @return {*}
*/
TreeNode* deserialize(list<string>& nodes) {
if (nodes.empty()) {
return nullptr;
}
// 后序遍历最后一个元素的值是 root 节点的值
string last = nodes.back();
nodes.pop_back();
if (null == last) {
return nullptr;
}
TreeNode* root = new TreeNode(stoi(last));
root->right = deserialize(nodes);
root->left = deserialize(nodes);
return root;
}
/***
* @description: 主函数,反序列化
* @param {string} data
* @return {*}
*/
TreeNode* deserialize(string data) {
if (data.empty()) {
return nullptr;
}
list<string> nodes = split(data, sep);
return deserialize(nodes);
}
};
/*使用层次遍历来实现*/
class _Codec_ {
private:
string sep = ",";
string null = "#";
public:
/***
* @description: 序列化
* @param {TreeNode*} root
* @return {*}
*/
string serialize(TreeNode* root) {
if (root == nullptr) {
return "";
}
string str = "";
queue<TreeNode*> que;
que.push(root);
while (!que.empty()) {
TreeNode* node = que.front();
que.pop();
if (node == nullptr) {
str.append(null).append(sep);
continue;
}
str.append(to_string(root->val)).append(sep);
que.push(node->left);
que.push(node->right);
}
return str;
}
/***
* @description: 字符串切割函数
* @param {string&} str
* @param {string&} ch
* @return {*}
*/
vector<string> split(const string& str, const string& ch) {
regex re(ch);
sregex_token_iterator first {str.begin(), str.end(), re, -1}, last;
return {first, last};
}
/***
* @description: 反序列化
* @param {string} data
* @return {*}
*/
TreeNode* deserialize(string data) {
if (data.empty()) {
return nullptr;
}
vector<string> nodes = split(data, sep);
// 第一个元素就是 root 的值
string first = nodes[0];
if (null == first) {
return nullptr;
}
TreeNode* root = new TreeNode(stoi(first));
// 队列记录父节点
queue<TreeNode*> que;
que.push(root);
for (int i = 1; i < nodes.size();) {
// 从队列中取出一个父节点
TreeNode* parent = que.front();
que.pop();
// 父节点对应的左侧子节点的值
string left = nodes[i++];
if (null != left) {
parent->left = new TreeNode(stoi(left));
que.push(parent->left);
} else {
parent->left = nullptr;
}
// 父节点对应的右侧节点的值
string right = nodes[i++];
if (null != right) {
parent->right = new TreeNode(stoi(right));
que.push(parent->right);
} else {
parent->right = nullptr;
}
}
return root;
}
};

若有收获,就点个赞吧
0 人点赞
