二分搜索
二分查找场景:
- 寻找一个数
- 寻找左侧边界
- 寻找右侧边界
二分查找逻辑:
- 搜索一个元素时,搜索区间一般是左闭右闭区间。所以
while条件需要加上等号。if相等就返回。mid必须加减 1。while结束就返回。- 搜索左右边界时,一般左闭右开。
while要用小于号,不用加等号。if相等时,不要返回,利用mid锁定边界。while结束后要处理返回。
思路分析
0. 二分查找框架
int binarySearch(vector<int>& nums, int target) {int left = 0, right = ...;while (...) {int mid = left + (right - left) / 2;if (nums[mid] == target)...;else if (nums[mid] < target)...;else if (nums[mid] > target)...;}return ...;}
其中 ... 标记的部分,就是可能出现细节问题的地方,当检查一个二分查找代码时,要注意这几个地方。
1. 寻找一个数(基本的二分搜索)
即搜索一个数,如果存在,就返回其索引,否则返回 -1。常见的代码如下:
int binayrSearch(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1; // 注意 right 起始值
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
1. 为什么 while 循环条件中是 <= 而不是 <?
答:因为初始化 right 的赋值是 nums.sizez() - 1,即最后一个元素的索引,而不是 nums.size()。这两种都可能出现再不同功能的二分查找中,区别是:前者是两端都闭的区间 [left, right],后者左闭右开区间 [left, right)。因为索引 nums.size() 是越界的。上述代码使用的是两端都闭的区间。这个区间就是每次进行搜索的区间。
当找到目标值的时候可以终止搜索:
if (nums[mid] == target)
return mid;
如果没有找到,就需要 while 循环终止,然后返回 -1。
while 循环什么时候终止? ——> 搜索区间为空的时候应该终止,意味着没得找了。
while (left <= right)的终止条件是 left == right + 1,写成区间形式就是 [right + 1, right],此时区间为空。直接返回 -1 即可。
while (left < right) 的终止条件是 left == right,写成区间形式就是 [right, right],此时区间不为空,还有一个元素 nums[right],但此时的 while 循环终止,索引 right 没有被搜索到,如果此时返回 -1 就是错误的。此时可以打一个补丁:
while (left < right) {
...;
}
return nums[left] == target ? left : -1;
2. 为什么 left = mid + 1, right = mid - 1?有的代码没有加加减减,怎么判断?
答:需要再次明确⌈搜索区间⌋的概念,上述代码是左闭右闭区间。当发现索引 mid 不是要找的,下一步搜索区间应该是 [left, mid - 1] 或 [mid + 1, right],因为 mid 已经搜索过了,应该从搜索区间中去除。
2. 寻找左侧边界的二分搜索(非递减数组)
上述代码处理此类问题是有问题的。比如,一个有序数组 nums = [1, 2, 2, 2, 3]、target = 2。使用上述代码返回的是 2。如果想要得到 target 的左侧边界,即索引 1,或者 target 的右侧边界,即索引 3,上述代码是无法处理的。
常见的代码如下,注意细节:
int left_bound(vector<int>& nums, int target) {
if (nums.empty())
return -1;
int left = 0;
int right = nums.size(); // 注意
while (left < right) { // 注意
int mid = left + (right - left) / 2;
if (nums[mid] == target)
right = mid;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid; // 注意
}
return left;
}
1. 为什么 while 中是 < 而不是 <=?
答:right = nums.size(),因此每次⌈搜索区间⌋是 [left, right) 左闭右开。while (left < right) 的终止条件是 left == right,此时搜索区间 [left, left) 为空,所以可以正确终止。
2. 为什么没有返回-1 的操作?如果 nums 中不存在 target 这个值,怎么办?
答:先理解⌈左侧边界⌋有什么特殊含义:

对于这个数组,算法会返回 1。这个 1 可以这么解读:nums 中小于 2 的元素有 1 个。
比如对于有序数组 nums = [2, 3, 5, 7]、target = 1,算法会返回 0,含义是:nums 中小于 1 的元素有 0 个。再比如 nums = [2, 3, 5, 7]、target 8 ,算法会返回 4,含义是:nums中小于 8 的元素有 4 个。
综上,函数的返回值(即 left 变量的值)取值区间是闭区间 [0, nums.size()]。所以可以在添加两行代码就可以正确返回 -1。
while (left < right) {
...;
}
// target 比所有数都大
if (left == nums.size())
return -1;
return nums[left] == target ? left : -1;
3. 为什么 left = mid + 1, right = mid?和之前算法不同?
答:因为⌈搜索区间⌋是 [left, right)左闭右开,所以当 nums[mid] 被检查之后,下一步的搜索区间应该去掉 mid 分割成两个区间:[left, mid) 和 [mid + 1, right)。
4. 为什么该算法能够搜索左侧边界?
答:关键在于对于 nums[mid] == target 的处理:
if (nums[mid] == target)
right = mid;
可见,找到 target 时不要立刻返回,而是缩小⌈搜索区间⌋的上界 right,在区间 [left, mid) 中继续搜索,即不断向左收缩,达到锁定左侧边界的目的。
整体代码如下:
int left_bound(vector<int>& nums, int target) {
int left = 0;
int right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
right = mid;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
righ = mid;
}
// 比所有元素都大,具体返回值需要讨论,这里返回 -1 || 比所有元素都小,具体返回值需要讨论,这里返回 -1
if (left == nums.size() || nums[left] != target)
return -1;
return left;
}
或者:
int left_bound(vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
right = mid - 1;
else if (nums[mid] < target)
right = mid - 1;
else if (nums[mid] > target)
left = mid + 1
}
// 检查边界
if (left >= nums.size() || nums[left] != target)
return -1;
return left;
}
3. 寻找右侧边界的二分查找(非递减数组)
常见代码如下,左闭右开:
int right_bound(vector<int>& nums, int target) {
if (nums.empty())
return -1;
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
left = mid + 1; // 注意
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid;
}
return left - 1; // 注意
}
1. 为什么最后返回 left - 1?
关键在于这个条件判断:
if (nums[mid] == target)
left = mid + 1;
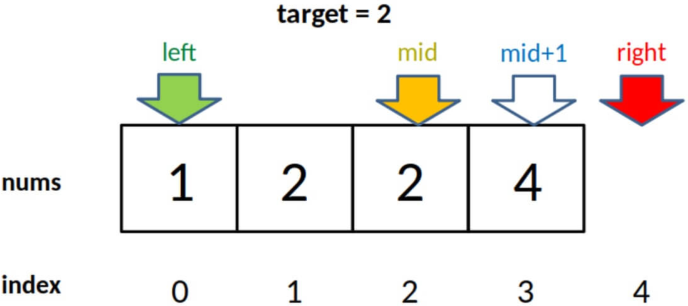
对 left 的更新必须是 left = mid + 1,也就是说 while 循环结束后,nums[left] 一定不等于 target 了,而 nums[left - 1] 是有可能使 target。
2. 如果 nums 不存在 target 这个值,怎么办?
类似之前的左侧边界搜索:
while (left < right) {
...;
}
if (left == 0)
return - 1;
return nums[left - 1] == target ? left - 1 : -1;
整体代码如下:
int right_bound(vector<int>& nums, int target) {
if (nums.empty())
return -1;
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
left = mid + 1;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid;
}
if (left == 0)
return -1;
return nums[left - 1] == target ? (left - 1) : -1;
}
或者:
int right_bound(vector<int>& nums, int target) {
if (nums.empty())
return -1;
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
left = mid + 1;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid - 1;
}
// 检查 right 下标
if (right < 0 || nums[right] != target)
return -1;
return right;
}
4. 将搜索区间统一为左闭右闭区间
1. 搜索元素
int binary_search(vector<int>& nums, int target) {
if (nums.empty())
return -1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid - 1;
}
return -1;
}
2. 搜索元素左侧边界
int left_bound(vector<int>& nums, int target) {
if (nums.empty())
return -1;
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
right = mid - 1;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid - 1;
}
// 检查 left 越界情况
if (left >= nums.size() || nums[left] != target)
return -1;
return left;
}
3. 搜索元素右侧边界
int right_bound(vector<int>& nums, int target) {
if (nums.empty())
return -1;
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
left = mid + 1;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid - 1;
}
// 检查 right 越界情况
if (right < 0 || nums[right] != target)
return -1;
return right;
}
二分搜索问题的泛化
什么问题可以运用二分搜索算法技巧?
首先,需要从题目中抽象出一个自变量 x,一个关于 x 的函数 f(x),以及一个目标值 target。
同时,三者需要满足以下条件:
f(x)必须是再x上的单调函数;- 计算满足约束条件
f(x) == target时的x的值。
例如,一个升序排列的有序数组 nums,以及一个目标元素 target,计算 target 在数组中的索引位置,如果有多个元素,返回最小索引。
可以将数组中的元素索引认为是自变量 x,函数关系 f(x) 就是访问数组:
int f(int x, vector<int>& nums)
return nums[x];
因为是升序数组,所以函数是递增函数。题目要求就是相当于问⌈满足 f(x) == target 的 x 最小值是多少⌋?如图所示:

如果一个算法问题,能够抽象成这幅图,就可以使用二分搜索算法。
// 函数 f 是关于自变量 x 的单调递增函数
int f(vector<int>& nums, int x)
return nums[x];
int leftBound(vector<int>& nums, int target) {
if (nums.empty())
return -1;
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (f(nums, mid) == target)
right = mid;
else if (f(nums, mid) < target)
left = mid + 1;
else if (f(nums, mid) > target)
right = mid;
}
return left;
}
代码框架总结如下:
// 函数 f 是关于自变量 x 的单调函数
int f(int x) {
//...
}
// 主函数,在 f(x) == target 的约束下求 x 的最值
int solution(vector<int>& nums, int target) {
if (nums.empty())
return -1;
// 自变量最小值?
int left = ...;
// 自变量最大值?
int right = ...;
while (left < right) {
int mid = left + (right - left) / 2;
if (f(mid) == target) {
// 求左侧边界还是右侧边界?
// ...
} else if (f(mid) < target) {
// 怎么让 f(x) 大一点?
// ...
} else if (f(mid) > target) {
// 怎么让 f(x) 小一点
// ...
}
}
return left
}
题目讨论
01 在排序数组中查找元素的第一个和最有一个位置
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
进阶:
你可以设计并实现时间复杂度为 O(log n) 的算法解决此问题吗?
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-first-and-last-position-of-element-in-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
直接利用左侧和右侧边界的二分搜索查找法即可。
// 左侧边界
int leftBound(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
right = mid - 1;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid - 1;
}
if (left >= nums.size())
return -1;
return nums[left] == target ? left : -1;
}
// 左侧边界
int leftBound(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
right = mid;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid;
}
if (left == nums.size())
return -1;
return nums[left] == target ? left : -1;
}
// 右侧边界
int rightBound(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
left = mid + 1;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid - 1;
}
if (rigth < 0)
return -1;
return nums[right] == target ? right : -1;
}
//右侧边界
int rightBound(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
left = mid + 1;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid;
}
if (left == 0)
return -1;
return nums[left - 1] == target ? left - 1 : -1;
}
vector<int> searchRange(vector<int>& nums, int target) {
if (nums.empty())
return {-1, -1};
return {leftBound(nums, target), rightBound(nums, target)};
}
02 二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/binary-search
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
直接使用二分搜索框架可。
int search(vector<int>& nums, int target) {
if (nums.empty())
return -1;
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid - 1;
}
return -1;
}
03 俄罗斯套娃信封问题
给你一个二维整数数组 envelopes ,其中 envelopes[i] = [wi, hi] ,表示第 i 个信封的宽度和高度。
当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算 最多能有多少个 信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
注意:不允许旋转信封。
示例 1:
输入:envelopes = [[5,4],[6,4],[6,7],[2,3]]
输出:3
解释:最多信封的个数为 3, 组合为: [2,3] => [5,4] => [6,7]。
示例 2:
输入:envelopes = [[1,1],[1,1],[1,1]]
输出:1
1 <= envelopes.length <= 5000
envelopes[i].length == 2
1 <= wi, hi <= 104
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/russian-doll-envelopes
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
本题相当于在二维平面里面求最长递增子序列。假设信封是由 (w, h) 这样的二维数对表示的,思路如下:
先对宽度 w 进行升序排序,如果遇到宽度相同的情况,则按照高度 h 降序排序。之后将所有的高度作为一个数组,在这个数组上计算最长递增子序列。
解法的关键在于,对于宽度相同的数对,要对其高度进行降序排序。因为两个宽度相同的信封不能相互包含,而逆序排序保证在宽度相同的数对中最多只选择一个计入最长递增子序列。
如何找出一个数组的最长递增子序列?
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。
示例 2:
输入:nums = [0,1,0,3,2,3]
输出:4
示例 3:
输入:nums = [7,7,7,7,7,7,7]
输出:1
提示:
1 <= nums.length <= 2500
-104 <= nums[i] <= 104
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-increasing-subsequence
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
注意:⌈子序列⌋和⌈字串⌋的区别,字串一定是连续的,子序列不一定是连续的。
使用动态规划思路:定义 dp[i] 表示以 nums[i] 结尾的最长递增子序列的长度。dp[0] = 1。所以,最终结果就是 dp 数组中的最大值。
假设已经知道 dp[0...4] 的所有结果,如何通过这些已知结果推出 dp[5]?
假设 nums[5] = val,既然是递增序列,只要找到前面哪些结尾比 val 小的子序列,然后将 val 接在后面,就可以形成一个新的递增序列,这个新的序列长度 + 1。可能会形成多个递增序列,选择最长的一个,把最长的长度最为 dp[5] 的值即可。
for (int i = 0; i < nums.size(); ++i) {
for (int j = 0; j < i; ++j) {
if (nums[j] > nums[i])
dp[i] = max(dp[i], dp[j] + 1);
}
}
结合 base case,代码如下:
int lengthOfLIS(vector<int>& nums) {
vector<int> dp(nums.size(), 1);
for (int i = 0; i < nums.size(); ++i) {
for (int j = 0; j < i; ++j) {
if (nums[j] > nums[i])
dp[i] = max(dp[i], dp[j] + 1);
}
}
int res = 0;
for (int num : dp)
res = max(res, num);
return res;
}
时间复杂度为 O(N^2)。
使用二分查找解法:通过一个简化的例子理解算法思想。
首先,给你一排扑克牌,我们像遍历数组那样从左到右一张一张处理这些扑克牌,最终要把这些牌分成若干堆。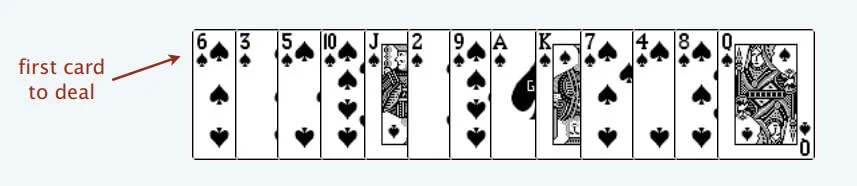
处理这些扑克牌要遵循以下规则:
只能把点数小的牌放在点数大的牌上;如果当前牌没有可以放置的堆,则新建一个堆,把这个牌放进去;如果有多个堆可选,则选择最左边的那一堆放置。比如说上述的扑克牌最终会被分成这样 5 堆(我们认为纸牌 A 的牌面是最大的,纸牌 2 的牌面是最小的)。
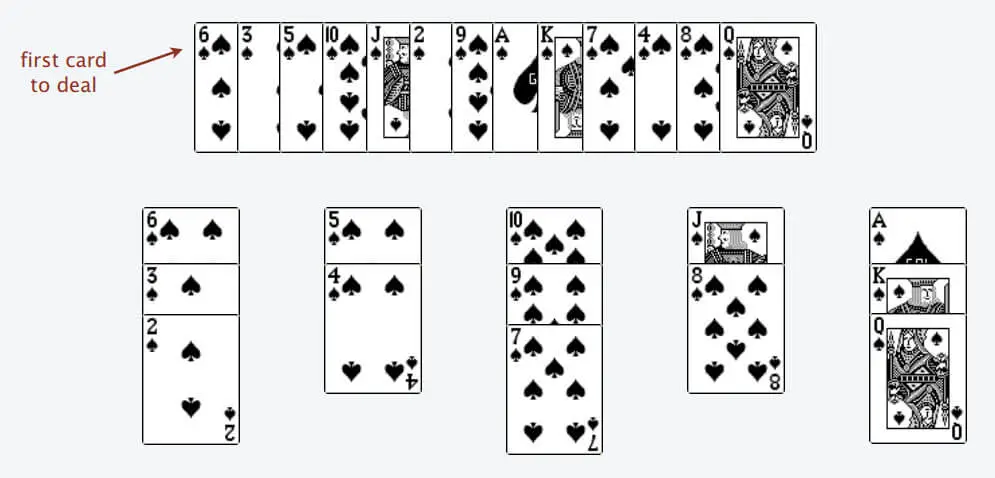
为什么遇到多个可选择堆的时候要放到最左边的堆上呢?稍加观察可以发现,这样可以保证牌堆顶的牌有序(2, 4, 7, 8, Q)。按照上述规则执行,可以算出最长递增子序列,牌的堆数就是最长递增子序列的长度。
每次处理一张扑克牌不是要找一个合适的牌堆顶来放吗,牌堆顶的牌是有序,这就能用到二分查找了:用二分查找来搜索当前牌应放置的位置。
int lengthOfLIS(vector<int>& nums) {
vector<int> top(nums.size(), 0);
int piles = 0;
for (int i = 0; i < nums.size(); ++i) {
int poker = nums[i];
int left = 0, right = piles;
while (left < right) {
int mid = left + (right - left) / 2;
if (top[mid] == poker)
right = mid;
else if (top[mid] < poker)
left = mid + 1;
else if (top[mid] > poker)
right = mid;
}
// 没有找到合适的
if (left == piles)
piles++;
// 把这张牌放在牌堆顶
top[left] = poker;
}
return piles;
}
所以,该题可以分为两步,先将信封按照规则排序,取出高度排序后的数组,在该数组上求得 LIS。
// 排序
static bool cmp(vector<int>& a, vector<int>& b) {
return a[0] == b[0] ? (a[1] > b[1]) : a[0] < b[0];
}
// 最长递增子序列长度
int lengthOfLIS(vector<int>& nums) {
vector<int> dp(nums.size(), 1);
for (int i = 0; i < nums.size(); ++i) {
for (int j = 0; j < i; ++j) {
if (nums[j] > nums[i])
dp[i] = max(dp[i], dp[j] + 1);
}
}
int res;
for (int n : dp)
res = max(res, n);
return res;
}
// 或
int lengthOfLIS(vector<int>& nums) {
vector<int>top(nums.size(), 0);
int piles = 0;
for (int i = 0; i < nums.size(), ++i) {
int poker = nums[i];
int left = 0, right = piles;
while (left < right) {
int mid = left + (right - left) / 2;
if (top[mid] == poker)
right = mid;
else if (top[mid] < poker)
left = mid + 1;
else if (top[mid] > poker)
right = mid;
}
if (left == piles)
piles++;
top[left] = poker;
}
return piles;
}
int maxEnvelopes(vector<vector<int>>&envelopes) {
int len = envelopes.size();
sort(envelopes.begin(), envelopes.end(), cmp);
vector<int> height(envelopes.size(), 0);
for (int i = 0; i < height.size(); ++i)
height[i] = envelopes[i][1];
return lenghtOfLIS(height);
}
04 判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,”ace”是”abcde”的一个子序列,而”aec”不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
示例 1:
输入:s = "abc", t = "ahbgdc"
输出:true
示例 2:
输入:s = "axc", t = "ahbgdc"
输出:false
提示:
0 <= s.length <= 100
0 <= t.length <= 10^4
两个字符串都只由小写字符组成。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/is-subsequence
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路一:双指针
定义两个指针指向两个字符串首尾,i 指向 s,j 指向 t。如果遇到 s[i] == t[j],++i, ++j,否则 ++j。最后如果 i == s.size(),则证明 s 是 t 的子序列。
bool isSubsequence(string s, string t) {
int i = 0, j = 0;
while (i < s.size() && j < t.size()) {
if (s[i] == t[j]) {
++i;
}
++j;
}
return i == s.size();
}
时间复杂度 O(N),N 为 t 的长度。
如果有大量输入的 S,称作 S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。按照刚才的逻辑,加个 for 循环也是可以的,但是处理每个 S 的时间复杂度还是 O(N),可以使用二分查找,时间复杂度可以将为 O(MlogN),M 是 S 的长度。因为 N 相对于 M 大很多,所以后者效率更高。
思路二:二分法
对于进阶问题,使用二分法处理,时间复杂度会降低很多。主要思路就是对 t 进行预处理,用一个字典 index 将每个字符出现的索引位置按顺序存储下来:
unordered_map<char, vector<int>> fun(string& t) {
auto lenT = t.size();
unordered_map<char, vector<int>> index;
for (int i = 0; i < lenT; ++i) {
index[t[i]].push_back(i);
}
// 打印,可以不要
for (auto & iter : index) {
cout << (iter.first) << ":" << "[";
vector<int> tmp = iter.second;
for (int num : tmp)
cout << num << " ";
cout << "]" <<endl;
}
return index;
}
比如,下图字符串 t 经过上述代码处理即可得到以下结果。

对于字符串 s 匹配 t 的过程如下图,图中已经匹配了 ab,接下来应该匹配 c 了:

按照之前的思路,需要 j 线性前进扫描字符 c。现在借助 index 中记录的信息,可以二分搜索 index[c] 中比 j 大的那个索引,在上图中,就是在 [0, 2, 6] 中搜索比 4 大的那个索引:

这样就可以快速得到下一个 c 的索引 6。现在问题就是如何使用二分搜索找到那个恰好比 4 大的索引?—寻找左侧边界的二分搜索。
二分查找返回目标
val的索引,对于搜索左侧边界的二分查找有一个性质:当val不存在时,得到的索引恰好就是比val大的最小元素索引。即,如果在数组中[0, 1, 3, 4]中搜索元素 2,算法会返回索引 2,就是元素 3 的位置,元素 3 就是数组中大于 3 的最小元素。
int leftBound(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
right = mid;
else if (nums[mid] < target)
left = mid + 1;
else if (nums[mid] > target)
right = mid;
}
return left;
}
综上,代码实现如下:
vector<bool> isSubsequence(vector<string>& strs, string t) {
vector<bool> flags(strs.size(), 0);
if (t.empty())
return flags;
// 预处理 t
unordered_map<char, vector<int>> index = fun(t);
int flag = 1;
for (int i = 0; i < strs.size(); ++i) {
string str = strs[i];
// t 上的指针
int j = 0;
for (char ch : str) {
// t 上没有这个字符
if (index.find(ch) == index.end()) {
flags[i] = false;
flag = 0;
break;
}
int pos = leftBound(index[ch], j);
// 搜索区间里没有找到
if (pos == index[ch].size()) {
flags[i] = false;
flag = 0;
break;
}
// 到这一步,说明 ch 在 t 中存在,相对顺序正确,找到它在 t 中的位置,向前移动指针 j,该字符匹配完成
j = index[ch][pos] + 1;
}
// 到这一步,s 字符串完全匹配了 t
if (flag)
flags[i] = true;
}
return flags;
}
关于该函数的返回值,可以根据题目要求进行处理。
05 阶乘函数后 K 个零
f(x) 是 x! 末尾是 0 的数量。(回想一下 x! = 1 2 3 … x,且 0! = 1 )
例如, f(3) = 0 ,因为 3! = 6 的末尾没有 0 ;而 f(11) = 2 ,因为 11!= 39916800 末端有 2 个 0 。给定 K,找出多少个非负整数 x ,能满足 f(x) = K 。
示例 1:
输入:K = 0
输出:5
解释:0!, 1!, 2!, 3!, and 4! 均符合 K = 0 的条件。
示例 2:
输入:K = 5
输出:0
解释:没有匹配到这样的 x!,符合 K = 5 的条件。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/preimage-size-of-factorial-zeroes-function
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
搜索有多少个 n 满足 f(n) == k,一个直观地解法就是穷举,因为随着 n 的增加,n! 肯定是递增的。伪代码如下:
int res = 0;
for (int n = 0; n < +inf; ++n) {
if (trailingZeroes(n) < k)
continue;
if (trailingZeroes(n) > k)
break;
if (trailingZeroes(n) == k)
res++;
}
return res;
代码中,函数 trailingZeroes(n) 表示 n! 末尾有多少个 0。
如何找到一个非负整数 n,它的阶乘 n! 的结果末尾有几个 0?
首先,两个数相乘的结果末尾有 0,一定是因为两个数中有因子 2 和 5,因为 10 = 2 * 5。
即,问题转换为:n! 最多可以分解出多少个因子 2 和 5?
比如,n = 25,那么 25! 最多可以分解出几个 2 和 5 相乘?这主要取决于能分解出几个因子 5,因为每个偶数都能分解出因子 2,因子 2 一定比因子 5 多。
即,问题转换为:n! 最多可以分解出多少个因子 5?
假设 n = 125,计算 125! 能分解出多少个因子 5?
首先,125 / 5 = 25,这一步就是计算有多少个像 5、15、20、25 这些 5 的倍数,它们一定可以提供一个因子 5。
再计算 125 / 25 = 5,这一步就是计算有多少个像 25, 50, 75 这些 25 的倍数。
代码如下:
int trailingZeroes(int n) {
int res = 0;
long divisor = 5;
while (divisor <= n) {
res += n / divisor;
divisor *= 5;
}
return res;
}
// 或
int trailingZeroes(int n) {
int res = 0;
for (int d = n; d / 5 > 0; d = d / 5)
res += d / 5;
return res;
}
时间复杂度为底数为 5 的对数,即 O(logN)。
另一种就是使用二分查找法。搜索有多少个 n 满足条件,就是在问,满足条件的 n 最大、最小是多少,最大值和最小值一减,就可以计算出有多少个 n 满足条件了。可以使用二分查找中⌈搜索左侧边界⌋和⌈搜索右侧边界⌋。
二分查找需要给定一个搜索区间,下界显然是 0,上界应该如何表示?题目给出的范围是 k = [0, 10^9] 区间内的整数,即需要计算当 trailingZeroes(n) == 10^9 时,n 为多少?trailingZeroes 函数是单调函数,先计算 trainingZeroes(INT_MAX) = 536870902 < LONG_MAX,在使用 LONG_MAX 计算,远超于 10^9。所以可以将 LONG_MAX 作为搜索的上界。
long trailingZeroes(long n) {
long res = 0;
for (long d = n; d / 5 > 0; d = d / 5)
res += d / 5;
return res;
}
现在就是要在区间 [0, LONG_MAX] 中寻找满足 trailingZeroes(n) == k 的左侧边界和右侧边界。
// 主函数
int preimageSizeFZF(int k) {
return (int)(rightBound(k) - leftBound(k) + 1);
}
// 搜索左侧边界
long leftBound(int target) {
long low = 0, high = LONG_MAX;
while (low < high) {
long mid = low + (high - low) / 2;
if (trailingZeroes(mid) == target)
high = mid;
else if (trailingZeroes(mid) < target)
low = mid + 1;
else if (trailingZeroes(mid) > target)
high = mid;
}
return low;
}
// 搜索右侧边界
long rightBound(int target) {
long low = 0, high = LONG_MAX;
while (low < high) {
long mid = low + (high - low) / 2;
if (trailingZeroes(mid) == target)
low = mid + 1;
else if (trailingZeroes(mid) < target)
low = mid + 1;
else if (trailingZeroes(mid) > target)
high = mid;
}
return low - 1;
}
06 珂珂吃香蕉
珂珂喜欢吃香蕉。这里有 N 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 H 小时后回来。
珂珂可以决定她吃香蕉的速度 K (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 K 根。如果这堆香蕉少于 K 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。
珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
返回她可以在 H 小时内吃掉所有香蕉的最小速度 K(K 为整数)。
示例 1:
输入: piles = [3,6,7,11], H = 8
输出: 4
示例 2:
输入: piles = [30,11,23,4,20], H = 5
输出: 30
示例 3:
输入: piles = [30,11,23,4,20], H = 6
输出: 23
1 <= piles.length <= 10^4
piles.length <= H <= 10^9
1 <= piles[i] <= 10^9
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/koko-eating-bananas
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
第一步:确定 x, f(x), target 分别是什么,并写出函数 f 的代码。
二分搜索的本质就是在搜索自变量。所以题目要求什么,就把什么设为自变量,所以吃香蕉的速度就是 x。显然,吃的速度越快,吃完的时间就越少,速度和时间是一个单调递减关系。函数 f(x) 就可以这么定义:如果吃香蕉的速度是 x 根/小时,则需要 f(x) 小时吃完所有香蕉。
代码实现如下:
// 定义:速度为 x,需要 f(x) 小时吃完所有香蕉
// f(x) 随着时间单调递减
int f(int x, vector<int>& piles) {
int hours = 0;
for (int pile : piles) {
hours += pile / x;
if (pile % x > 0)
hours++;
}
return hours;
}
target 就是吃香蕉的时间限制 H,是对 f(x) 返回值的约束。
第二步:找到 x 的取值范围作为二分搜索的搜索区间,初始化 left 和 right 变量。
吃香蕉的速度最小是多少?最大是多少?显然,最小速度是 1,最大速度是 piles 数组中元素的最大值,因为题目要求每小时最多吃一堆香蕉。你可以用一个 for 循环,计算最大值,要么看题目给的约束,piles 中的元素取值范围是多少,然后给 right 初始化一个取值范围之外的值。这样就可以确定二分搜索的区间边界。
第三步:根据题目要求,确定应该使用搜索左侧还是右侧的二分搜索算法。
题目要求计算最小速度,就是 x 要尽可能小:

就是搜索左侧边界的二分搜索,但是注意 f(x) 是单调递减,需要结合上图进行思考:
int minEatingSpeed(vector<int>& nums, int H) {
int left = 1;
int right = 1000000000 + 1; // right 是开区间,需要加 1
while (left < right) {
int mid = left + (right - left) / 2;
if (f(piles, mid) == H)
right = mid;
else if (f(piles, mid) < H)
right = mid;
else if (f(piles, mid) > H)
left = mid + 1;
}
}
07 在 D 天内送达包裹的能力
传送带上的包裹必须在 days 天内从一个港口运送到另一个港口。
传送带上的第 i 个包裹的重量为 weights[i]。每一天,我们都会按给出重量(weights)的顺序往传送带上装载包裹。我们装载的重量不会超过船的最大运载重量。
返回能在 days 天内将传送带上的所有包裹送达的船的最低运载能力。
示例 1:
输入:weights = [1,2,3,4,5,6,7,8,9,10], days = 5
输出:15
解释:
船舶最低载重 15 就能够在 5 天内送达所有包裹,如下所示:
第 1 天:1, 2, 3, 4, 5
第 2 天:6, 7
第 3 天:8
第 4 天:9
第 5 天:10
请注意,货物必须按照给定的顺序装运,因此使用载重能力为 14 的船舶并将包装分成 (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) 是不允许的。
示例 2:
输入:weights = [3,2,2,4,1,4], days = 3
输出:6
解释:
船舶最低载重 6 就能够在 3 天内送达所有包裹,如下所示:
第 1 天:3, 2
第 2 天:2, 4
第 3 天:1, 4
示例 3:
输入:weights = [1,2,3,1,1], D = 4
输出:3
解释:
第 1 天:1
第 2 天:2
第 3 天:3
第 4 天:1, 1
提示:
1 <= days <= weights.length <= 5 * 104
1 <= weights[i] <= 500
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/capacity-to-ship-packages-within-d-days
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
按照程序:
第一步:确定 x, f(x), target 分别是什么,并写出函数 f 的代码。
x:船的运载能力。f(x):当船的运载能力为 x 时,需要 f(x) 天运完货物。显然,f(x) 是单调递减函数。代码实现如下:
int f(vector<int>& weights, int x) {
int days = 0;
for (int i = 0; i < weights.size();) {
int cap = x;
while (i < weights.size()) {
if (cap < weights[i])
break;
else
cap -= weights[i];
i++;
}
days++;
}
return days;
}
target 就是运载货物的时间 days。
第二步:找到 x 的取值范围作为二分搜索的搜索区间,初始化 left 和 right 变量。
运载能力的最小值和最大值分别是多少。显然,最小值就是 weights 数组的最大值,因为需要保证每次都能将货物放在船上运输。最大值就是 weights 数组的累计和。这样一次就能将所有货物运输完毕。代码如下:
int left = 0, right = 1;
for (int weight : weights) {
left = max(left, weight);
right += weight;
}
第三步:根据题目要求,确定应该使用搜索左侧还是右侧的二分搜索算法。
题目要求计算最小运载量,就是让 x 尽可能地小,就是且二分搜索的左侧边界。结合上一题的图,代码如下:
int f(vector<int>& weights, int x) {
int days = 0;
for (int i = 0; i < weights.size();) {
int cap = x;
while (i < weights.size()) {
if (cap < weights[i]) {
break;
} else {
cap -= weights[i];
}
}
days++;
}
return days;
}
int shipWithinDays(vector<int>& weights, int days) {
int left = 0, right = 1;
for (int weight : weights) {
left = max(left, weight);
right += weight;
}
while (left < right) {
int mid = left + (right - left) / 2;
if (f(weights, mid) == days)
right = mid;
else if (f(weights, mid) < days)
right = mid;
else if (f(weights, mid) > days)
left = mid + 1;
}
}

若有收获,就点个赞吧
0 人点赞
