二叉树第一期
二叉树的重要性
比如经典算法快速排序和归并排序,其中快速排序就是个二叉树的谦虚遍历,归并排序就是二叉树的后序遍历。分析如下。
快速排序的逻辑是,想要对 nums[lo…hi] 进行排序,需要先找一个分界点 p,通过交换元素使得 nums[lo…p-1] 都小于等于 nums[p],且 nums[p+1…hi] 都大于 nums[p],然后递归地去 nums[lo…p-1] 和 nums[p+1…hi] 中寻找新的分界点,最后整个数组就被排序了。
快速排序的代码框架如下:
void sort(vector<int>& nums, int low, int high) {// 前序遍历位置-始// 通过交换元素构建分界点 pint p = partition(nums, low, high);// 前序遍历位置-终sort(nums, low, p - 1);sort(nums, p + 1, high);}
先构建分界点,然后去左右子数组构建分界点,就是一个二叉树的前序遍历。
归并排序的逻辑,想要堆 nums[lo…hi] 进行排序,先对 nums[lo…mid] 排序,在dui nums[mid+1…hi] 排序,最后把这两个有序子数组合并,整个数组就排序好了。
归并排序的代码框架如下:
void sort(vector<int>& nums, int low, int high) {int mid = (low + high) / 2;sort(num, low, mid);sort(num, mid + 1, high);// 后序遍历位置-始// 合并两个有序子数组merge(nums, low, mid, hi);// 后续遍历位置-终}
先对左右子数组排序,然后合并,就是一个二叉树后序遍历。
写递归算法的秘诀
写递归算法的关键在于要明确函数的「定义」是什么,然后相信这个定义,利用这个定义推导最终结果,不要跳入递归地细节。
比如,计算一颗二叉树共有几个节点:
// 定义:count(root) 返回以 root 为根的树有多少个结点int count(TreeNode* root) {// base caseif (root == nullptr)return 0;// 自己加上子树的节点数就是整棵树的节点数return 1 + count(root->left) + count(root->right);}
root 本身就是一个节点,加上左右子树的节点数就是以 root 为根的树的节点总数。
左右子树的节点数如何计算。其实就是计算根为 root->left 和 root->right 两棵树的节点数,按照定义,递归调用 count 函数即可。
写树相关的算法,简单来说,先搞清楚当前 root 节点「该做什么」以及「什么时候做」,然后根据函数定义递归调用子节点,递归调用会让孩子节点做相同的事情。
所谓「该做什么」即使让你想清楚些什么代码能够实现题目想要的效果,所谓「什么时候做」,就是让你思考这段代码应该写在前序、中序还是后续遍历的代码位置上。
算法实践
01 反转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:输入:root = [4,2,7,1,3,6,9]输出:[4,7,2,9,6,3,1]示例 2:输入:root = [2,1,3]输出:[2,3,1]示例 3:输入:root = []输出:[]提示:树中节点数目范围在 [0, 100] 内-100 <= Node.val <= 100来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/invert-binary-tree著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
关键思路在于发现反转整棵树就是交换每个节点的左右子节点,可以将交换左右子节点的代码放在前序遍历的位置,当然,放在后序遍历的位置上也是可以的。
TreeNode invertTree(TreeNode* root) {
// base case
if (root == nullptr)
return nullptr;
/**** 前序遍历位置 ****/
// root 节点需要交换它的左右子节点
TreeNode* tmp = root->left;
root->left = root->right;
root-right = tmp;
// 让左右子节点继续反转它们的子节点
invertTree(root->left);
invertTree(root->right);
return root;
}
02 填充二叉树节点的右侧指针
题目的意思就是把二叉树的每一层节点都用 next 指针连接起来:
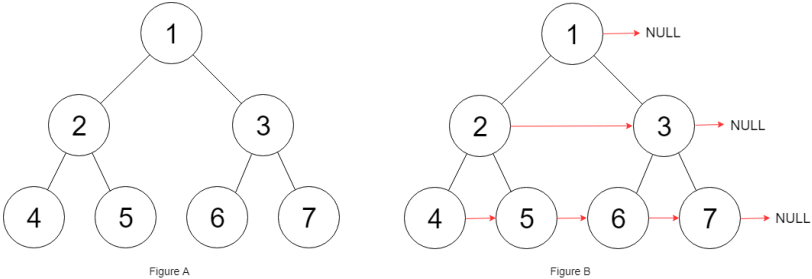
模仿上一道题,写出如下代码:
Node* connect(Node* root) {
if (root == nullptr || root->left == nullptr)
return root;
root->left->next = root->right;
connect(root->left);
connect(root->right);
return root;
}
上述代码有很大问题。节点 5 和 节点 6不属于同一个父节点,按照这段代码逻辑,它俩就无法串联起来。
二叉树的问题难点在于,如何把题目的要求细化成每个节点需要做的事情,如果只是依赖一个节点的话,肯定没有办法连接「跨父节点」的两个相邻节点的。
做法就是增加函数参数,一个节点做不到,就给安排两个节点。「将每一层二叉树节点连接起来」可以细化成「将每两个相邻节点都连接起来」:
class Solution {
public:
void connectTwoNode(Node* node1, Node* node2) {
if (node1 == NULL || node2 == NULL)
return;
// 前序遍历的位置
node1->next = node2;
// 连接相同父节点的两个子节点
connectTwoNode(node1->left, node1->right);
connectTwoNode(node2->left, node2->right);
// 连接跨越父节点的两个子节点
connectTwoNode(node1->right, node2->left);
}
Node* connect(Node* root) {
if (root == NULL)
return NULL;
connectTwoNode(root->left, root->right);
return root;
}
};
connectTwoNode 函数不断递归,可以覆盖整颗二叉树,将所有相邻的节点都连接起来,也就避免了之前出现的问题。
03 将二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历 顺序相同。
函数签名如下:
void flatten(TreeNode* root);
给 flatten 函数输入一个节点 root,那么以 root 为根的二叉树就会被拉平为一条链表:
- 将 root 的左子树和右子树拉平;
- 将 root 的右子树接到左子树下方,然后将整个左子树作为右子树

上面看起来最难的应该是第一步,如何把 root 的左右子树拉平?按照 flatten 函数的定义,对 root 的左右子树递归调用 flatten 函数即可。
class Solution {
public:
void flatten(TreeNode* root) {
// base case
if (root == nullptr)
return nullptr;
flatten(root->left);
flatten(root->right);
// 后序遍历的位置
//1. 左右子树都被拉成一条链表
TreeNode* left = root->left;
TreeNode* right = root->right;
// 2. 将左子树作为右子树
root->left = nullptr;
root->right = left;
// 3. 将原先的右子树 right 接到当前右子树的末端
TreeNode* p = root;
while (p->right) {
p = p->right;
}
p-right = right;
}
};
因为需要先拉平左右子树才能进行后续操作,所以是后续遍历框架。

若有收获,就点个赞吧
0 人点赞
