1.1 初始flink
Flink 项目的理念是:“Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
1.2 Flink 的重要特点
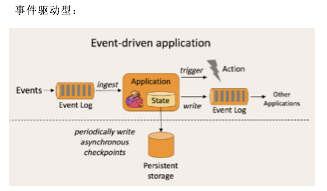
1.2.1 事件驱动型(Event-driven)
1.2.2 流与批的世界观
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统 传输的每个数据项执行操作,一般用于实时统计。
在 flink 的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并 提供数据,必须连续处理无界流,也就是说必须在获取后立即处理 event。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前 通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有 界数据集进行排序,有界流的处理也称为批处理。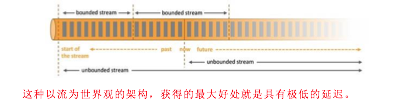
1.2.3 分层 api
<br />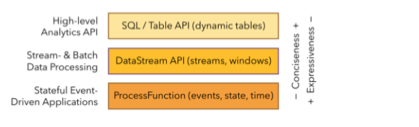
1.2.4 flink的其他特点

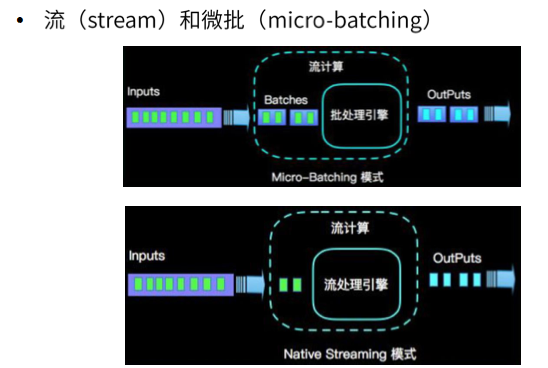
1.2.5 flink VS Spark Streaming



<br />

若有收获,就点个赞吧
0 人点赞
