一. 性能定位
性能定位口诀:
一压二查三指标,延迟吞吐是关键
时刻关注资源量,排查首先看GC
口诀分析
1. 看背压
通常最后一个背压高的subTask的下游就是job的明显瓶颈之一
2. 看checkoint时长
checkpoint的时长在一定程度上可以影响job的整体吞吐
3. 查看关键指标
通过延迟与吞吐指标可以对任务的性能进行精准的判断
4. 资源利用率
我们进行优化的最终目的是提供资源的利用率。
常见的性能问题如下
1. JSON序列化与反序列化
常出现在source和sink任务上,在指标上没有体现,容易被忽略
2. Map和set的Hash冲突
由于HashMap,HashSet等随着负载因子增高,引起的插入和查询性能下降。
3. 数据倾斜
数据倾斜会导致其中一个或者多个subtask处理的数据量远大于其他节点,造成局部数据延迟。
4. 和低速系统的交互
在实时系统进行高速数据处理时,当涉及到与外部低俗的系统(如Mysql,Hbase等)进行数据交互时。
5. 频繁的GC
因内存或者内存比例分配不合理导致频繁GC, 甚至是TaskManager失联
6. 大窗口
窗口size大,数据量大,或者是滑动窗口size和step的比值比较大,如size=10minmatch, step=1。

二. 经典调优场景
数据去重场景
基于用户的浏览数据流统计近90天的活跃用户数,并每隔10分钟输出一次当前结果,用户构建实时数据报表。
在上面这个经典场景中,存在如下几个特点:
1. 数据量大
日活量在6000万+, 平均每隔用户每天浏览次数为20次。
2. 增长速度快
每天新增用户1000万+,带来新增浏览量数亿。
3. 更新换代快
每年全量用户更新换代一次。
可以有如下方案:
方案一:通过Set,map等去重结构并结合flink的state来实现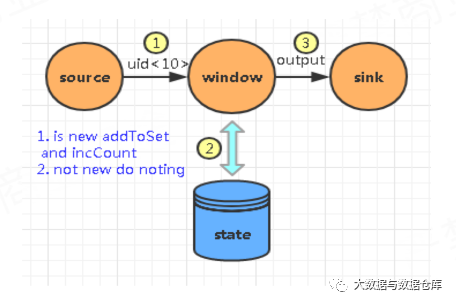
方案二:
精确去重:通过bitMap/raaring bitMap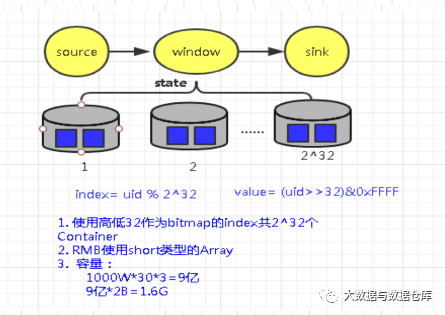
方案三:
近似去重:布隆过滤器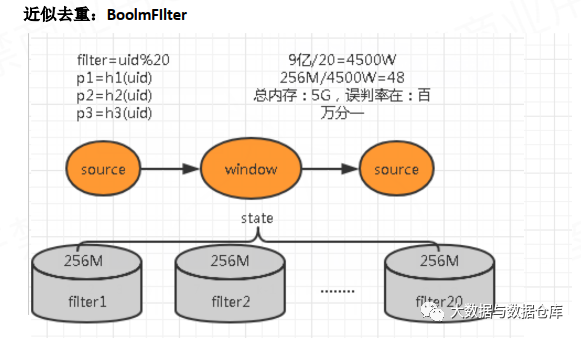

三. 内存调优
内存调优
Flink的内存主要分为三部分,对于network buffer和manager pool都是由Flink管理的,manager pool也已经走向堆外内存,因此flink 的内存调优主要分为两部分:
a. 非堆内存 network buffer 和 manager poll的调优
b. flink 系统中的heap内存的调优
非堆内存调优
对于非堆内存调优比较简单,主要是调整:network buffer 和manager pool buffer 的比例
1. Networkbuffer:
- taskmanager.network.memory.fraction (默认是0.1)
- taskmanager.network.memory.min
( 默认是64M) - taskmanager.network.memory.max
(默认是1G)
原则:默认是0.1或是小于0.1,可以根据使用情况进行调整。
2. ManagerBuffer:
- taskmanager.memory.off-heap:true
( 默认是false) - taskmanager.memory.fraction
(默认是0.7)
原则:在流计算中如果用户建议调整成小于0.3
堆内存调优
Flink是运行在jvm上的,故flink应用的堆内存调优和传统jvm调优无差别。
默认Flink使用的Parallel Scavenge的垃圾回收器可以改用G1 垃圾回收期。
启动参数如下:
env.java.opts=-server -XX:+UseG1GC -XX:MaxGCPauseMillis=300 —XX:+PrintGCDetails

若有收获,就点个赞吧
0 人点赞
