问题导读:
1、StreamTask的层级结构如何理解?
2、StreamTask生命周期的抽象方法如何实现?
3、Java泛型类型擦除如何实现?
4、Flink类型暗示如何理解?
StreamTask**
在Flink源码之StreamOperator中已经说到StreamOperator上层是由StreamTask调用的,在Flink中将StreamTask称之为Invokable,它是一个抽象类。
StreamTask的层级结构如下图: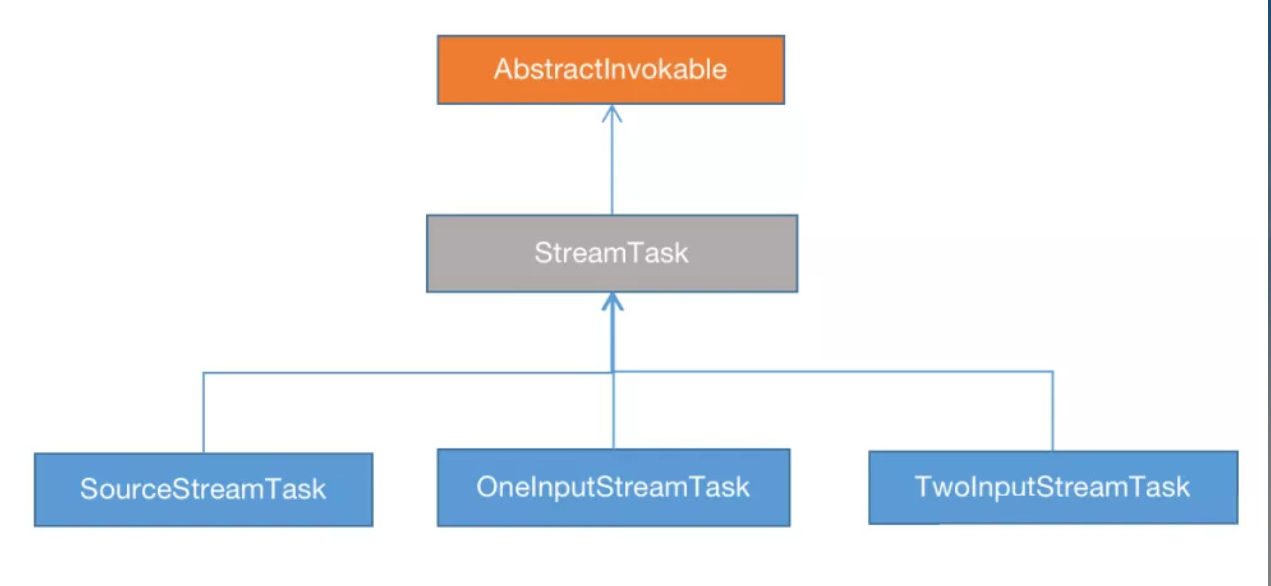
AbstractInvokable是一个抽象类,代表最顶层的Invokable,它是所有能够被TaskManager执行的task的抽象基类,流式任务和批处理任务都实现了该类,在这个抽象类里面声明了最重要的方法invoke,可以认为其是task执行的起点,当执行一个task时,TaskManager会调用invoke方法,并且task所有的操作包括启动输入输出的读写流等都发生在这个方法;此外还声明了与checkpoint相关的triggerCheckpointAsync/triggerCheckpointOnBarrier/abortCheckpointOnBarrier/notifyCheckpointCompleteAsync方法;
StreamTask是AbstractInvokable的基本抽象实现类,实现了invoke、triggerCheckpoint等方法,另外声明了init、run等StreamTask生命周期的抽象方法,其具体实现类有:
- SourceStreamTask代表源(StreamSource)的Invokable;
- OneInputStreamTask代表有一个输入流的Invokable;
- TwoInputStreamTask代表有两个输入流的Invokable;
当然,还有其它关于批处理(BatchTask)、迭代流(StreamIterationHead/StreamIterationTail)等相关的Invokable。
StreamTask是一个基础的Invokable,它会去调用一个或是多个StreamOperators,前提是这些StreamOperators组成了一个operator chain,被chain在一起的operator在一个线程内被同步的执行并且因此运行在同一个数据分区。在invoke方法内会调用这个operator的生命周期方法,invoke方法的执行可以分成以下步骤:
- 基本的初始化工作:创建基础工具(如配置等)并且加载operators chain;
- StreamTask的初始化,包括与checkpoint相关的例如Statebackend的创建,并最终调用operator的setup方法。调用task特定的init方法,当然具体实现是在其实现类里,主要完成StreamTwoInputProcessor的初始化来进行读取数据相关的处理;
- StreamOperator的初始化:进行operator的状态的初始化,包括调用initializeState、openAllOperators方法,initializeState会调用到StreamOperator的initializeState方法,完成状态的初始化过程,openAllOperators方法会调用StreamOperator的open方法,调用与用户相关的初始化过程;
- 执行过程:主要就是调用run()方法,具体的实现也是在对应的实现类里面,对于SourceStreamTask就是生产数据,对于OneInputStreamTask/TwoInputStreamTask主要就是执行读取数据与之后的数据处理流程,这个在正常情况下会一直执行下去
- 资源释放:任务正常结束或是异常停止都会执行的操作,包括closeAllOperators、disposeAllOperators、cleanup等,我们在userFunction里面涉及到的资源链接一定要在close里面执行资源的释放
在StreamTask里面除了invoke方法的实现,还有checkpoint的相关实现方法triggerCheckpointAsync/triggerCheckpoint/triggerCheckpointOnBarrier/abortCheckpointOnBarrier/notifyCheckpointCompleteAsync等。
另外,StreamTask实现了AsyncExceptionHandler接口,这个接口内包含了一个handleAsyncException方法,该方法在StreamTask的实现是使当前的StreamTask失败,在Flink里面,窗口定时触发或者是ProcessFunction的onTimer方法等相对于上面提到的run方法是一个异步过程,也就是说是由其它线程来执行的,如果这个异步执行的线程抛出的异常我们希望主线程也能捕获到并进行相应的处理,那么AsyncExceptionHandler就是完成这个功能的。
StreamTask中通过getCheckpointLock获取锁对象,定时调用与checkpoint执行都会使用这个lock对象完成同步功能,保证数据的一致性。比如在定时调用onTimer方法内可能会涉及到对状态的操作,但是处理方法processElement里面也会对状态进行操作,状态对于这两个线程是共享资源,如果不使用锁进行同步可能会导致状态数据的不一致。
Java泛型类型擦除和Flink类型暗示
我们知道,泛型在实现中一般有两种方式:
- 代码共享:也就是对同一个原始类型下的泛型类型只生成同一份目标代码,此时就会出现类型擦除。比如Java中就采取了这种方式,它对List类型,不管是List,还是List都只生成List.class这一份字节码;
- 代码特化:也就是对每一个泛型类型都生成不同的目标代码,如果是这种实现就不会出现类型擦除的问题,但是很明显的会出现代码膨胀的问题,C++就是采取的这种方式;
Java泛型所使用的类型擦除虽然避免了代码膨胀的问题,节约了JVM的资源,但是却加重了编译器的工作量,使它不得不在运行期之前就进行类型检查,禁止模糊的或是不合法的泛型使用方式。当然了,在使用extends和super来对将来指向容器的参数类型做限制时,Java的类型擦除也会根据限制的最左侧的界限来进行擦除和替换。
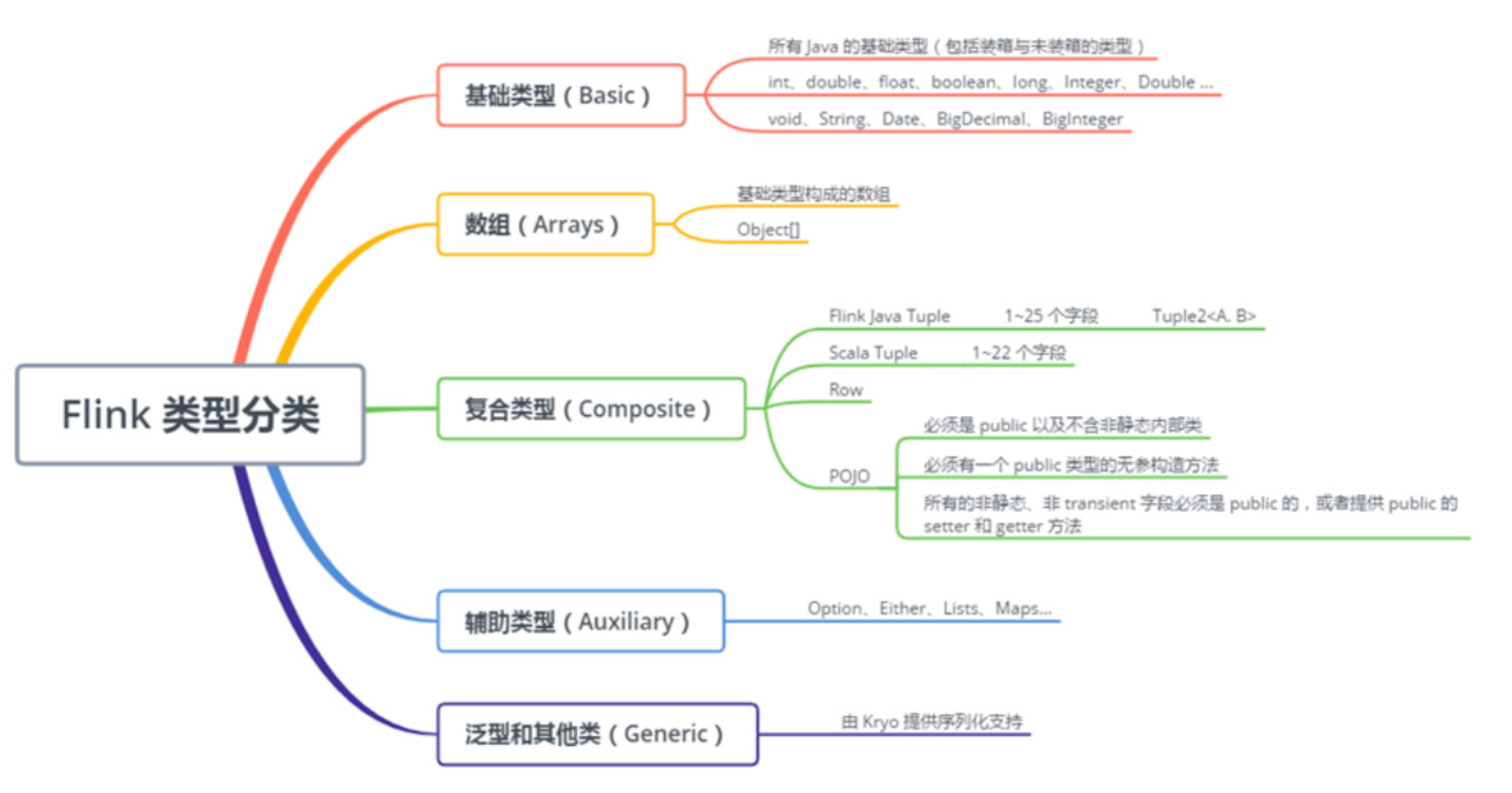
在简介完Java中的泛型类型擦除后,再来分析Flink中的类型及类型暗示。如下图所示时Flink支持的各种类型:
上图的各种类型的继承关系如下,它们是一一对应的关系: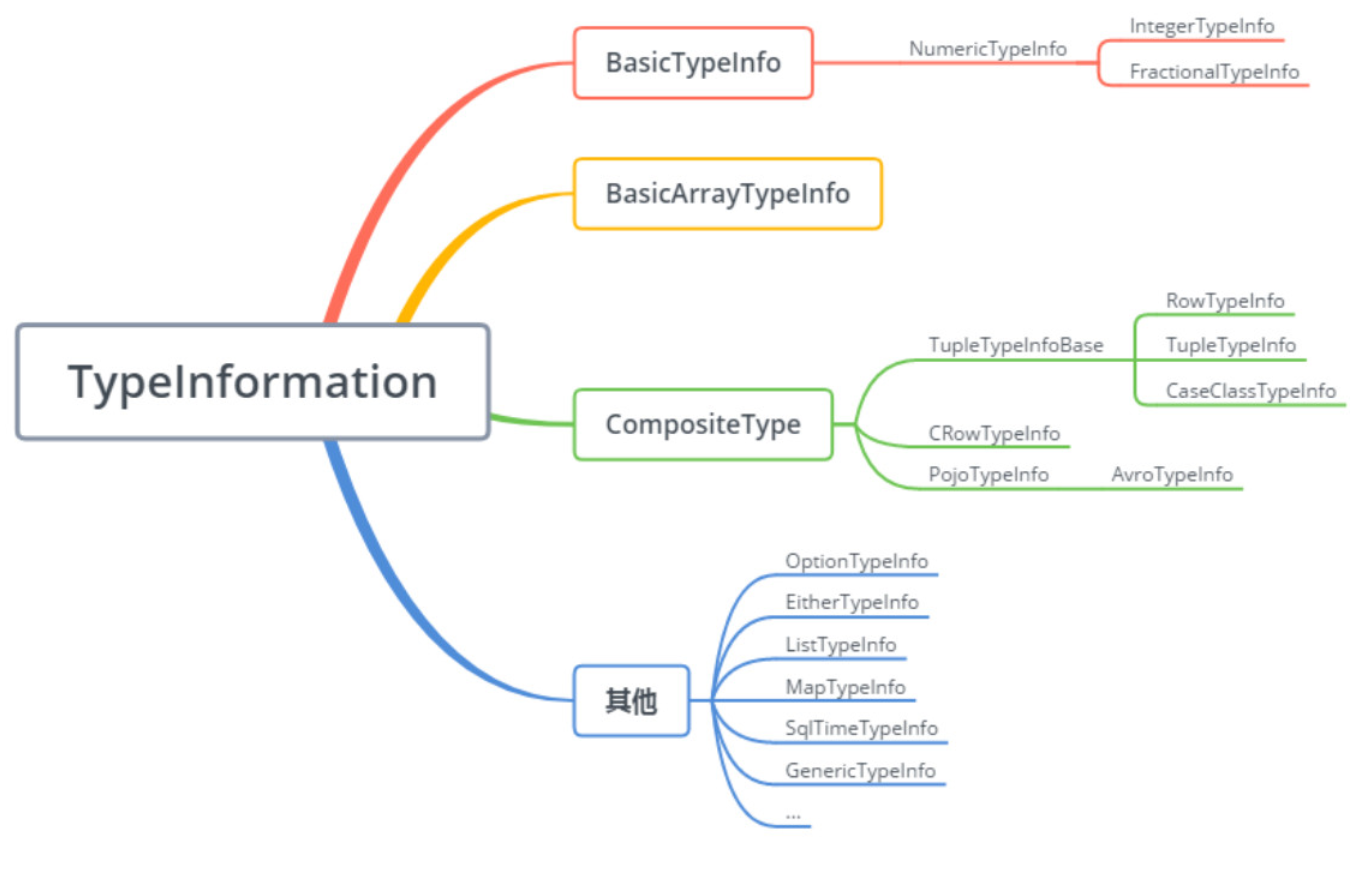
TypeInformation类是Flink类型系统的公共基类,由于Flink中的类型信息会随着作业的提交而被传递到各个执行节点,所以它及它的所有子类都必须是可序列化的。在处理数据类型和序列化时,Flink会按照自带的类型描述,一般类型提取和类型序列化框架的顺序进行处理。它会尝试推断出在分布式计算过程中被交换和存储的数据类型的信息,实现方式是通过TypeExtractor类利用方法签名、子类继承信息等方式,自动提取和恢复类型信息,其提供了对map、flatmap、fold、mapPartition、AggregateFunction等多个方法获取其返回类型或累加类型的函数。
如果Flink成功推断出了类型信息,就能够非常便捷的完成很多事情,如:
- 使用POJO类型时,通过引用它们的字段名称对数据进行分组、连接、聚合等操作(如我们常用到的dataStream.keyBy(“id”)就用到了类型推断),并提前对类型进行检测,以判断拼写错误或类型是否兼容等;
- 由于Flink所需要处理的数据需要进行网络传输和存储在内存中,数据类型信息越多,序列化和内存存储就越紧凑,压缩效率就越高;
- 使得用户可以尽量少的关心序列化框架和类型的注册;
最常见的需要用户进行数据类型处理的场景有以下几个:
- 注册子类型:如果函数只描述了父类型,但是执行时实际上却是子类型,此时一方面Flink需要识别这些子类型可能会造成性能下降,另一方面子类型的某些独特的特性可能无法识别,此时就需要通过StreamExecutionEnvironment或者ExecutionEnvironment调用其registerType(clazz)方法来注册子类型;
- 注册自定义序列化器:Flink会将自己不能处理的类型转交给Kryo序列化器,但是也并不是所有的类型都会被Kryo完美的处理,也就是说Flink并不能处理所有的类型,此时就需要为出问题的数据类型注册额外的序列化类,具体做法是在StreamExecutionEnvironment或者ExecutionEnvironment调用getConfig().addDefaultKryoSerializer(clazz, serializer)来实现。当然啦,也可以强制使用Avro序列化器来代替Kryo,实现办法是通过StreamExecutionEnvironment或者ExecutionEnvironment调用其getConfig().enableForceAvro();
- 类型提示:尽管FLink提供的推断方法已经很多,但是由于上面介绍的的Java泛型类型擦除,自动提取类型的方式仍然并不总是有效,如果Flink尝试了前述的各种办法仍然无法推断出泛型,用户就必须通过TypeHint来辅助进行推断,通过调用returns()方法声明返回类型。returns()方法接受三种类型的参数:字符串描述的类名(如”String”)、用于泛型类型的参数TypeHint、Java原生Class(例如String.class)等;
- 手动创建TypeInformation:Flink提供的TypeInformation及其子类已经包含了很多常用类型的信息,但有时可能还是不够,所以手动创建有时是必须的,如果是非泛型数据类型,直接通过传递Class对象到TypeInformation.of()即可,否则可能需要TypeHint匿名内部类来捕获泛型类型的信息然后通过TypeInformation.of(new TypeHint(){})来保存该信息,在运行时TypeExtractor即可通过getGenericSuperclass().getActualTypeArguments()方法来获取保存的实际类型;
从类型信息到内存块,需要经历以下步骤,这样数据才能被内存进行有效的管理,这也是Flink类型信息产生作用的过程:

若有收获,就点个赞吧
0 人点赞
