元素定位是做UI自动化最基础也是最重要的部分之一了,搞定了元素定位,算是推开了web自动化的大门,即可走进web自动化的世界;
首先,我们需要认识元素。元素是可识别区分的属性。 Selenium 的 WebDriver 一共提供了九种定位方法,其中最常用的是前八种;
| 定位器 Locator | 描述 |
|---|---|
| class | 定位class属性与搜索值匹配的元素(不允许使用复合类名) |
| css selector | 定位 CSS 选择器匹配的元素 |
| id | 定位 id 属性与搜索值匹配的元素 |
| name | 定位 name 属性与搜索值匹配的元素 |
| link text | 定位link text可视文本与搜索值完全匹配的锚元素 |
| partial link text | 定位link text可视文本部分与搜索值部分匹配的锚点元素。如果匹配多个元素,则只选择第一个元素。 |
| tag name | 定位标签名称与搜索值匹配的元素 |
| xpath | 定位与 XPath 表达式匹配的元素 |
元素定位选择原则:
- 一般来说,如果 HTML 的 id 是可用的、唯一的,那么它就是在页面上定位元素的首选方法。它们的工作速度非常快,可以避免复杂的 DOM 遍历带来的大量处理。
- 如果没有唯一的 id,那么最好使用写得好的 CSS 选择器来查找元素。XPath 和 CSS 选择器一样好用,但是它语法很复杂,并且经常很难调试。尽管 XPath 选择器非常灵活,但是他们通常未经过浏览器厂商的性能测试,并且运行速度很慢。(xpath会遍历dom树,然后层层匹配,所以性能会偏慢)
- 基于链接文本和部分链接文本的选择策略有其缺点,即只能对链接元素起作用。此外,它们在 WebDriver 内部调用 XPath 选择器。
- 标签名可能是一种危险的定位元素的方法。页面上经常出现同一标签的多个元素。这在调用 findElements(By) 方法返回元素集合的时候非常有用。
建议尽可能保持定位器的紧凑性和可读性。使用 WebDriver 遍历 DOM 结构是一项性能花销很大的操作,搜索范围越小越好。
1、ID定位
from selenium import webdriverimport timefrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome()try:driver.get(url='https://www.baidu.com/')time.sleep(3)ele = driver.find_element(By.ID,"su")print(ele)except Exception as e:raise efinally:driver.quit()
输出结果:
"D:\Program Files (x86)\Python39\python.exe" D:/Buyer_test_code/webuitest_jcmall/unit.py<selenium.webdriver.remote.webelement.WebElement (session="8c9e8948493a5e9c8d40d90796652d13", element="ad1c838b-f7d5-4d50-af59-575518a86dbc")>Process finished with exit code 0
输出结果是一个WebElement对象,对象中包含此次会话的session以及页面元素的element
- NAME定位
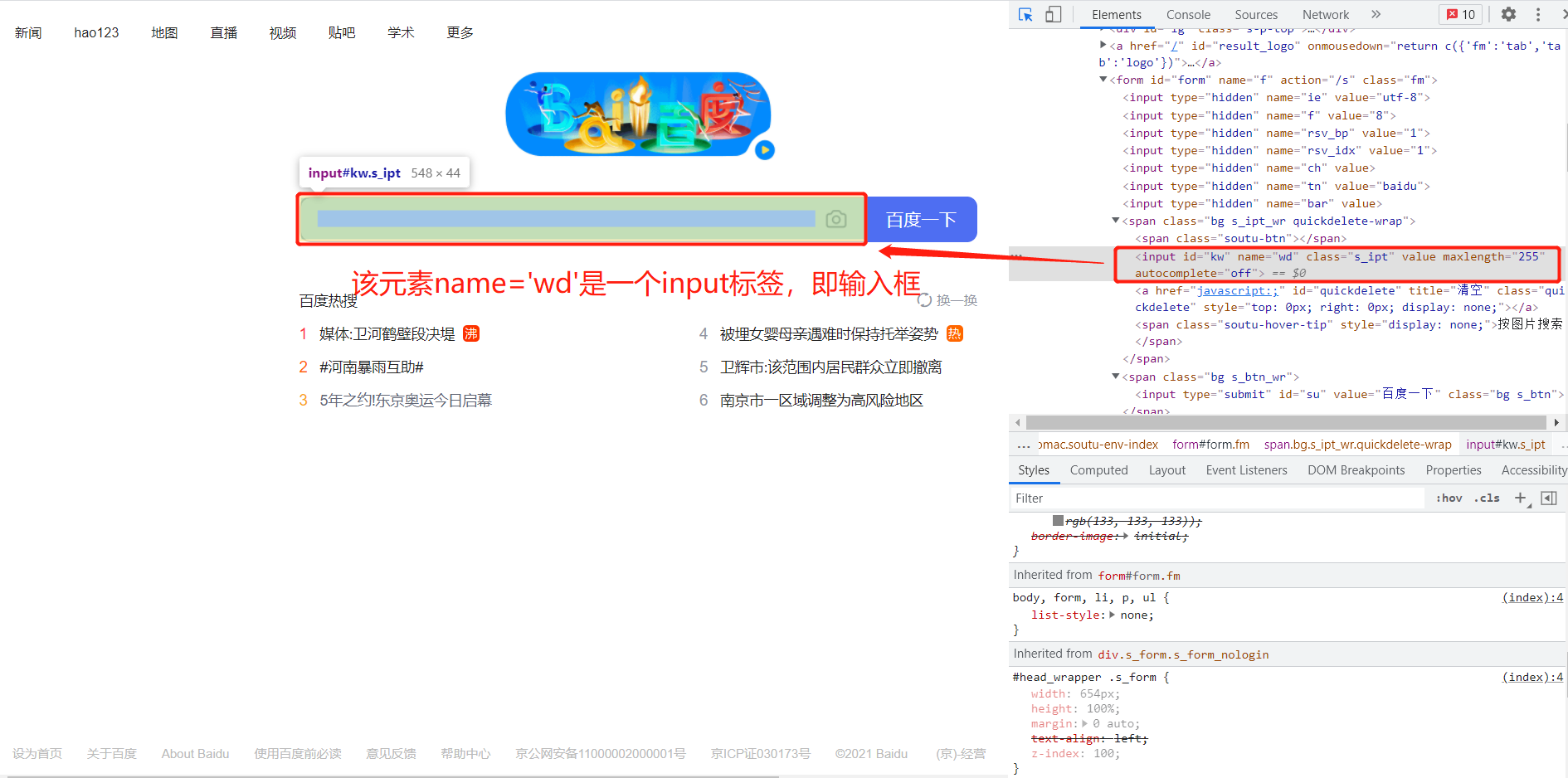
from selenium import webdriverimport timefrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome()try:driver.get(url='https://www.baidu.com/')time.sleep(3)ele = driver.find_element(By.NAME,"wd")print(ele)except Exception as e:raise efinally:driver.quit()
"D:\Program Files (x86)\Python39\python.exe" D:/Buyer_test_code/webuitest_jcmall/unit.py<selenium.webdriver.remote.webelement.WebElement (session="36ee840cad5e4d18dcdbf8bee7903c04", element="1ce2702e-7777-4ea4-ac97-fa05dc3a82f2")>Process finished with exit code 0
- CLASS_NAME定位 ```python from selenium import webdriver import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() try: driver.get(url=’https://www.baidu.com/‘) time.sleep(3) ele = driver.find_element(By.CLASS_NAME,”s_ipt”) print(ele) except Exception as e: raise e finally: driver.quit()
```python"D:\Program Files (x86)\Python39\python.exe" D:/Buyer_test_code/webuitest_jcmall/unit.py<selenium.webdriver.remote.webelement.WebElement (session="cf989d286cd3519eec64b2615033909e", element="26743821-2bdb-4189-8573-aae6cb82dc49")>Process finished with exit code 0
CSS_SELECTOR定位
在Web自动化中最推荐使用的一种方式,原因又如下几种:
- 例如
id这种元素在一个页面中可能并不唯一,并且很有可能是前端的框架自动生成的,研发人员并未对其进行维护,随时可能变;而CSS是前端开发最常用的一种维护方式,对于我们开发和维护自动化用例也更为清晰和方便 - 大部分定位都可以用
CSS来解决 CSS的写法相较于Xpath要更为简洁
常用的CSS选择器语法: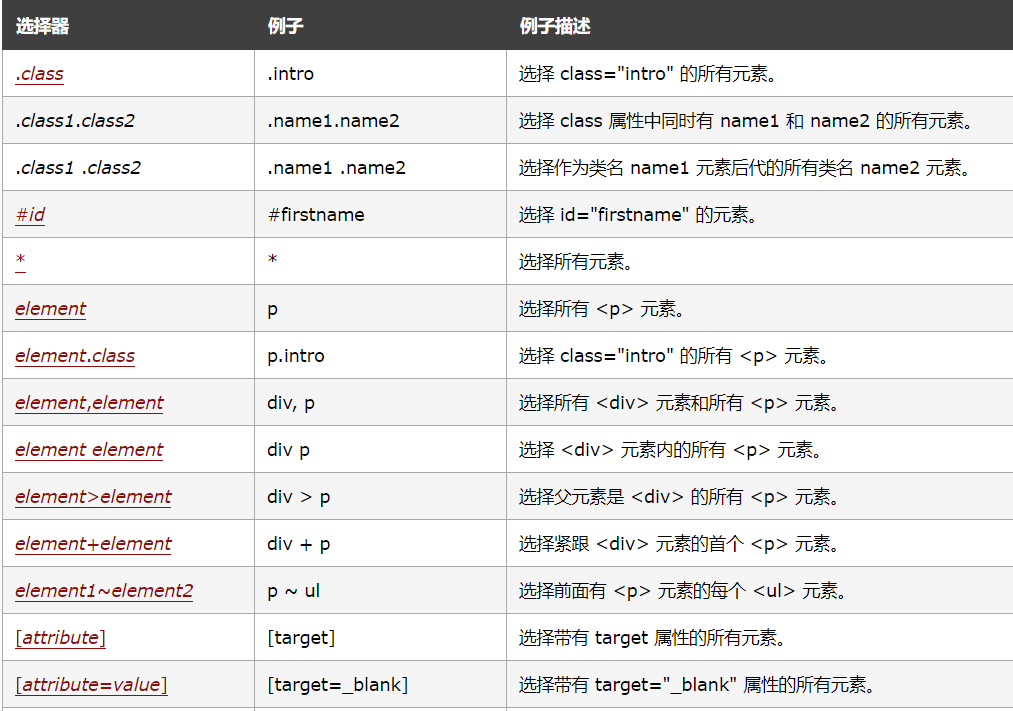
使用CSS_SELECTOR 结合ID定位
ele = driver.find_element(By.CSS_SELECTOR,"#kw")
使用CSS_SELECTOR 结合CLASS_NAME定位
ele = driver.find_element(By.CSS_SELECTOR,".s_ipt")
使用CSS_SELECTOR 结点定位
ele = driver.find_element(By.CSS_SELECTOR,"#s-top-left > a:nth-child(3)") # 父元素id='s-top-left'下第3个a标签元素
使用LINK_TEXT定位
可以点击的链接跳转上面的文字,就是link text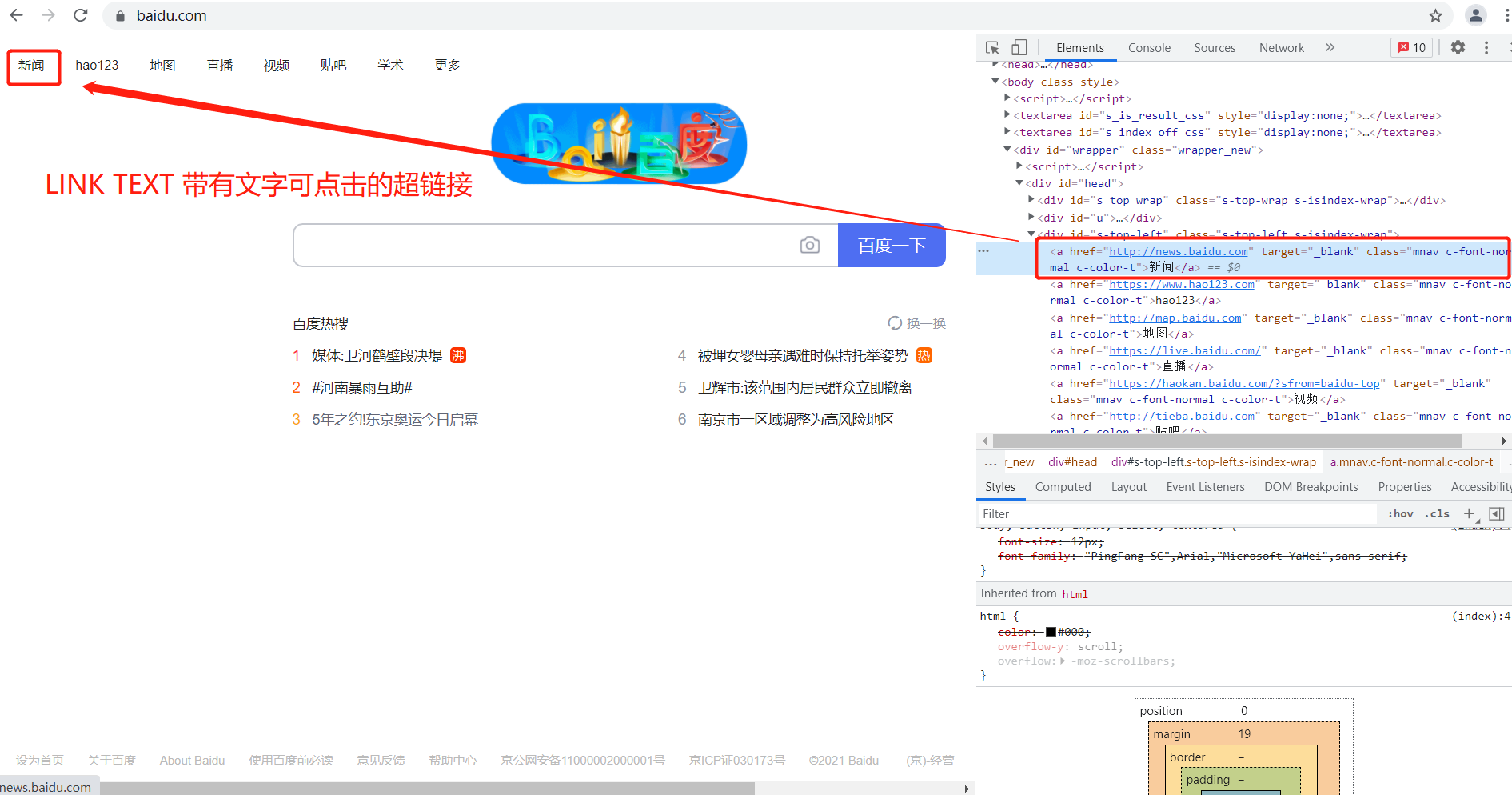
ele = driver.find_element(By.LINK_TEXT,"新闻")
使用XPATH定位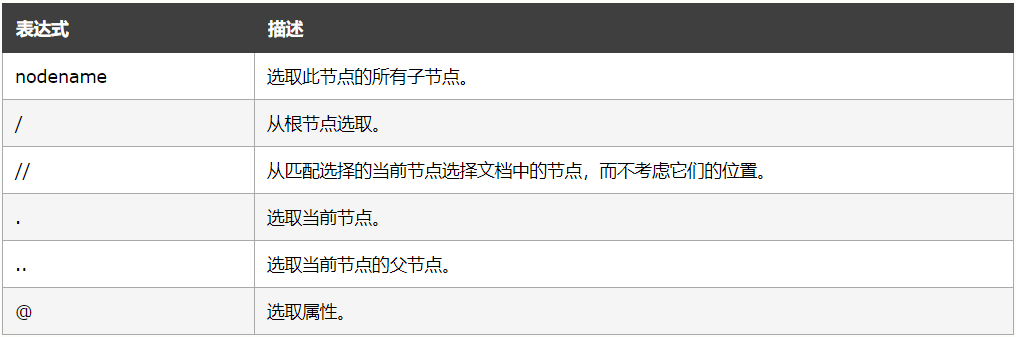

使用XPATH根据id定位
ele = driver.find_element(By.XPATH,"//*[@id='kw']")
使用XPATH根据class定位
ele = driver.find_element(By.XPATH,"//*[@class='s_ipt']")
使用XPATH根据name定位
ele = driver.find_element(By.XPATH,"//*[@name='wd']")
使用XPATH根据节点关系定位
ele = driver.find_element(By.XPATH,"//*[@id='s-top-left']/a[3]") # id='s-top-left'父节点下的第3个a标签元素
使用XPATH逻辑运算组合定位
ele = driver.find_element(By.XPATH,"//*[@id='kw' and @name='wd']")
selenium 中Js元素常用操作
在selenium中通过driver.execute_script(‘js语句’)来执行javaScript脚本
1、js常用定位
document.getElementById("id") # 通过id定位document.getElementsByName("name") # 通过name定位(获取list)document.getElementsByClassName("class") # 通过class定位(获取list)document.querySelector('css selector') # css selector定位document.querySelectorAll("css selector") # css selector定位(获取list)
2、js元素常用操作
document.getElementById("su").value='百度两下' # 修改元素属性document.getElementsByClassName("el-input__inner")[2].removeAttribute("readonly") # 去除元素属性document.getElementsByClassName("el-input__inner")[2].scrollIntoView() # 滚动页面,真到元素可见document.getElementById('kw').value='百度' #input输入框输入字符document.getElementById("su").click() # 对元素的点击操作

若有收获,就点个赞吧
0 人点赞
