- 3.1 姓名问题识别模型的整体训练流程
- 字粒度存储路径
char_train_data_path = “./name_question.train.1”
char_valid_data_path = “./name_question.valid.1” - 读取训练数据,分隔符为空格
df1 = pd.read_csv(train_data_path, header=None, sep=” “)
df2 = pd.read_csv(valid_data_path, header=None, sep=” “) - 使用字的形式进行训练
# 首先对文本内容进行处理,
# 将”请问您贵姓?”变成 “请 问 您 贵 姓 ?”,以空格分割
df1[1] = pd.DataFrame(map(lambda x: “ “.join(list(x)), df1[1]))
df2[1] = pd.DataFrame(map(lambda x: “ “.join(list(x)), df2[1])) - 生成训练数据
df1.to_csv(char_train_data_path, header=False, index=False, sep=”\t”)
# 生成验证数据
df2.to_csv(char_valid_data_path, header=False, index=False, sep=”\t”) - 进行模型训练,这里我们将n-gram特征设置为2
# 其他参数都是用默认,如:embed_size为100,训练轮数epoch为5
model = fasttext.train_supervised(input=char_train_data_path, wordNgrams=2) - 之后我们在验证集上进行验证
valid_result = model.test(char_valid_data_path)
print(valid_result) - 设置背景风格
plt.switch_backend(“Agg”) - 小节总结
- 3.2 模型训练对比试验与优化措施
- 训练数据路径
train_data_path = “./name_question.train”
# 验证数据路径
valid_data_path = “./name_question.valid” - 词粒度存储路径
word_train_data_path = “./name_question.train.2”
word_valid_data_path = “./name_question.valid.2” - 读取训练数据,分隔符为空格
df1 = pd.read_csv(train_data_path, header=None, sep=” “)
df2 = pd.read_csv(valid_data_path, header=None, sep=” “) - 使用词的形式进行训练
df1[1] = pd.DataFrame(map(lambda x: “ “.join(jieba.cut(x)), df1[1]))
df2[1] = pd.DataFrame(map(lambda x: “ “.join(jieba.cut(x)), df2[1])) - 生成训练数据
df1.to_csv(word_train_data_path, header=False, index=False, sep=”\t”)
# 生成验证数据
df2.to_csv(word_valid_data_path, header=False, index=False, sep=”\t”) - 进行模型训练,这里我们将n-gram特征设置为2
# 其他参数都是用默认,如:embed_size为100,训练轮数epoch为5
# model = fasttext.train_supervised(input=word_train_data_path, wordNgrams=2) - 之后我们在验证集上进行验证
valid_result = model.test(word_valid_data_path)
print(valid_result) - 原始数据和增强后数据的存储路径
train_data_path = “./name_question.train”
augm_train_data_path = “./name_question_augm.train” - 实例化翻译对象
translator = Translator() - 读取原始训练数据
df = pd.read_csv(train_data_path, header=None, sep=” “) - 转成列表并提取标签和文本内容
input = df.values.tolist()
label = list(map(lambda x: x[0], input))
content = list(map(lambda x: x[1], input_)) - 以标签和内容列表为输入进行数据增强,以相同格式进行输出
# 进行批量翻译, 翻译目标是英语
translations = translator.translate(content, dest=”en”)
# 获得翻译后的结果
en_res = list(map(lambda x: x.text, translations)) - 最后在翻译回中文, 完成回译全部流程
translations = translator.translate(en_res, dest=”zh-cn”)
cn_res = list(map(lambda x: x.text, translations))
res = list(zip(label, cn_res)) - 将原始数据与增强数据进行堆叠(concat)
df1 = pd.DataFrame(res)
df2 = pd.DataFrame(input_)
df = pd.concat([df1, df2], axis=0, join=”outer”)
# 写入文件
df.to_csv(augm_train_data_path, index=False, header=None, sep=” “) - 请 您好们根据上述的过程,自己将name_question_augm.train转化成基于词粒度的word_name_question_augm.train
word_augm_train_data_path = “./word_name_question_augm.train” - 之后在验证集上进行验证
valid_result = model.test(word_valid_data_path)
print(valid_result) - 迁移词向量路径
word_vec_path = “./cc.zh.300.vec” - 默认使用词粒度
# 这里注意:fasttext模型默认的词向量维度为100
# 而这里迁移的词向量维度是300,因此必须令参数dim=300
model = fasttext.train_supervised(
input=word_train_data_path,
autotuneValidationFile=word_valid_data_path,
autotuneDuration=600,
wordNgrams=2,
dim=300,
pretrainedVectors=word_vec_path,
) - 之后在验证集上进行验证
valid_result = model.test(word_valid_data_path)
print(valid_result) - 获得一个bin格式模型
model.save_model(“unsupervised_data.bin”) - 之后在验证集上进行验证
valid_result = model.test(word_valid_data_path)
… - 3.3 模型服务的部署
- 使用route()装饰器来告诉Flask触发函数的URL
@app.route(‘/‘)
def hello_world():
“””请求指定的url后,执行的主要逻辑函数”””
# 在用户浏览器中显示信息:’Hello, World!’
return ‘Hello, World!’ - 导入fasttext
import fasttext
import jieba - 最新的模型,大家根据自己之前训练的模型名字进行修改
model_name = “name_question_1591259822.bin” - 最新模型的全路径
model_path = “/data/ItcastBrain/Info/fasttext_model/“ + model_name - 加载已训练的模型,注意: 这段加载语句不能写入下方的函数中,
# 否则将会每次请求都会重新加载
model = fasttext.load_model(model_path) - 定义服务请求路径和方式, 这里使用POST请求
@app.route(“/v1/is_name_question/“, methods=[“POST”])
def recogniition():
“””
姓名问题识别函数
它的输入咨询师所有的对话和索引列表,[[content, index], [content, index], …]
它的输出是姓名问题文本对应的index,如果没有则为-1
“””
# 首先接受传过来的数据体,即咨询师所有的对话和索引列表
text = request.get_json()[“text”]
# 设置默认result为-1
result = -1
# 遍历对话内容和索引
for te, index in text:
# 使用模型进行预测
predicted = model.predict(“ “.join(jieba.cut(te)))
if predicted[0][0] == “labelname”:
# 如果预测出的标签为”labelname”, 则证明出现姓名询问语句
# 记录索引
result = index
# 停止循环,因为在对话中客服往往只询问一次客户姓名
break
# 返回字符串类型的结果(返回json或str形式都是可以的)
return str(result) - http://0.0.0.0:5001/v1/is_name_question/“
# key为text,内容为咨询师所有对话内容和索引的列表
data = {
“text”: [
[“你好,你是想了解哪个课程呢?”, 0],
[“还在么 您好?”, 0],
[“你好”, 1],
[“您想了解哪个专业的学费呢”, 1],
[“专业不同,学时学费也不一样”, 1],
[“好的,方便QQ或者微信,邮箱接收吗?我这边发您”, 3],
[“您贵姓”, 5],
]
}
# 多层嵌套必须使用json=data
# 超时时间为200
start = time.time()
res = requests.post(url, json=data, timeout=200)
end = time.time()
print(end - start)
print(res.text)">根据gunicorn开启的5001端口,app.py中的url路径
url = “http://0.0.0.0:5001/v1/is_name_question/“
# key为text,内容为咨询师所有对话内容和索引的列表
data = {
“text”: [
[“你好,你是想了解哪个课程呢?”, 0],
[“还在么 您好?”, 0],
[“你好”, 1],
[“您想了解哪个专业的学费呢”, 1],
[“专业不同,学时学费也不一样”, 1],
[“好的,方便QQ或者微信,邮箱接收吗?我这边发您”, 3],
[“您贵姓”, 5],
]
}
# 多层嵌套必须使用json=data
# 超时时间为200
start = time.time()
res = requests.post(url, json=data, timeout=200)
end = time.time()
print(end - start)
print(res.text) - 返回对应的索引
5 - http://后的名称相同
upstream prod {
server 0.0.0.0:5001;
server 0.0.0.0:5002 backup;
}">以下是与热更新有关的配置
# 这里代理两个端口的服务
# 其中5002为backup,即当5001服务停止时被启用
# 这里的prod要与下面proxy_pass中http://后的名称相同
upstream prod {
server 0.0.0.0:5001;
server 0.0.0.0:5002 backup;
} - nginx的外层服务使用8086端口
server {
listen 8086;
server_name 0.0.0.0;
location /static/ {
alias /data/ItcastBrain/static/;
} - 3.4 延展知识:层次softmax
- 3.5 延展知识:KerasTuner进行自动超参数调优
- 导入keras tuner中的超参数调优方法
# 随机搜索
from kerastuner.tuners import RandomSearch
# 贝叶斯优化
from kerastuner.tuners import BayesianOptimization - 加载手写字识别的标准数据集
(x, y), (val_x, val_y) = keras.datasets.mnist.load_data()
# 像素值缩放
x = x.astype(‘float32’) / 255.
val_x = val_x.astype(‘float32’) / 255. - 获取指定数量的数据作为样本
x = x[:10000]
y = y[:10000] - 使用随机搜索获得超参数调节器
tuner = RandomSearch(
# 构建模型函数名,默认传入hp
build_model,
# 优化指标
objective=’val_accuracy’,
# 最大尝试次数
max_trials=10,
# 每种方式的尝试次数
executions_per_trial=3,
# 结果保存路径
directory=’test_dir’) - 使用调节器在指定数据上进行搜索
tuner.search(x=x,
y=y,
epochs=3,
validation_data=(val_x, val_y)) - 将结果作为摘要打印
tuner.results_summary() - 日志保存路径
log_dir = “./log_dir”
# batch_size是每次进行参数更新的样本数量
batch_size = 32 - epochs将全部数据遍历训练的次数
epochs = 10
3.1 姓名问题识别模型的整体训练流程
接下来,我们将训练一个模型来判断咨询师的每一次对话是否为询问”姓名”的语句,首先,我们明确这是一个文本二分类任务,且是一个在线二分类任务,也就是对推断速度有一定要求。这种类型的任务在NLP领域都是首选fasttext模型作为baseline(基本解决方案),这里也不例外。我们使用Facebook发布的fasttext工具来完成.
- 所以选择fasttext的原因:
- 模型结构简单,参数量相比大型模型(如BERT)较少,即提高训练效率又提高推断效率。
姓名问题识别模型的整体训练流程
- 第一步: 正负样本定义与验证集划分
- 第二步: 了解fasttext模型结构
- 第三步: 使用fasttext模型工具进行训练和验证
- 第四步: 使用自动超参数调优方法进行模型调优
- 第五步: 模型保存与实例预测
第一步: 正负样本定义与验证集划分
我们首先定义正负样本,以方便数据标注和采集。
正负样本的定义:
正样本定义:
- 在历史语料中,所有咨询师进行姓名提问的文本。
负样本定义:
- 在历史语料中,所有咨询师非姓名提问的文本。
注意:
- 这样的定义方式使得负样本数量远远多于正样本,因为我们之后的评估指标是精度和召回率,因此,我们需要控制采集的负样本数量与正样本数量相当,比例约为1:1.
最终我们通过人工标注采集正样本数量约2500条,负样本数量约2500条。
- 部分数据展示:
__label__name 方便留下你的名字吗?
labelnone 您好,现在这个学科正在搞活动
labelname 怎么称呼您呢
labelname 您好你叫什么名字
labelnone 好的
labelname 你的名字?
labelnone 你的微信是什么?
labelname 你贵姓???
labelname 您可以留下您的名字吗
labelnone 方便留下QQ号吗?
labelnone 刘芳跟进 设计,请知道。
labelname 您好,你叫什么名
labelname 你叫什么名字呢,是对Java感兴趣吗?
labelnone 这里的 工作氛围很好
labelname 嗯嗯,不错,名字是?
labelnone 和前端移动开发研究
labelname 可否留下您的姓名?
labelnone 好吧,我不知道你这里有你之前接触这个领域?
labelnone 这个是你的名字吗?
labelnone 您是从 设计,还是提高 工作考虑的呢?
labelname 叫什么名字呢,想 选什么 设计
labelnone 北京有开设AI班,要 选名吗
- 数据说明:
- 一共分为两列,第一列代表标签共两种类型,labelname: 代表该文本为询问姓名的文本。labelnone: 代表该文本不是询问姓名的文本。第二列就是对应文本信息,这里都是来自咨询师的对话内容。label是fasttext工具表示标签的默认形式。
- 鉴于数据中可能含有大量隐私数据,因此只会交给学生部分数据来了解数据形式,同时考虑让学生真正看到模型的应用效果,会使用原有数据做模型训练和预测。
- 数据存储地址:
- /data/ItcastBrain/Info/fasttext_model/name_question.train
- 划分验证集:
- 这里我们使用linux命令在文件层面划分验证集, 使用文件划分一定要保证你的正负样本是均匀的,不要划分完使验证集都是某一类标签。划分比例为0.2,也就是5000数据中有1000条数据作为验证集。在name_question.train路径下执行以下代码将生成name_question.valid文件。
# 使用head进行重定向,并使用sed命令将选定的数据从name_question.train删除
# 注意:不要重复执行这个命令,这里的范围是第1行到第100行
# 您好们根据自己的数据量进行配置, 假如你只有500条数据,那么选定”1,100d”练习一下即可。
head -100 name_question.train > name_question.valid | sed -i ‘1,100d’ name_question.train
第二步: 了解fasttext模型结构
- fasttext模型结构:
- 从大的尺度上来看,fastext由两个层组成,分别是EmbeddingBag和Linear(全连接层);而这个所谓的EmbeddingBag层实质是Embedding层和GAP(全局平均池化层)的结合层。从下面的图中可以看到,文本在做完数值映射后,即刻进入EmbeddingBag层然后进入Linear层,Linear层完成分类任务输出类别结果。
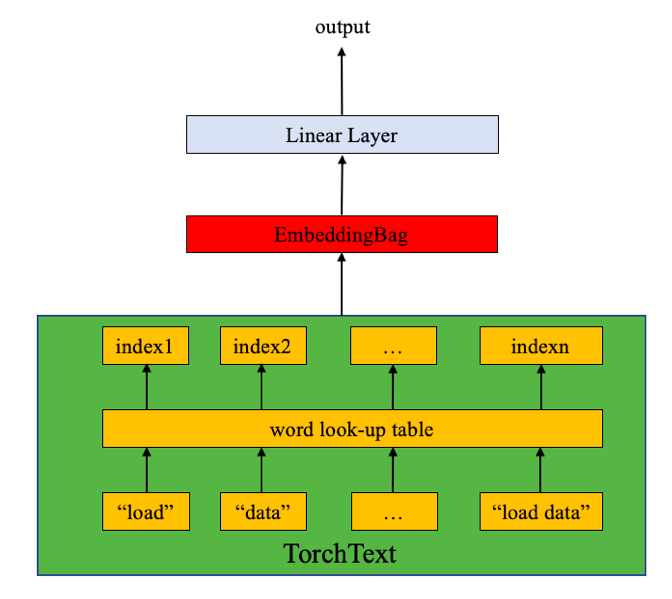
- 下面用一段代码帮助我们来更好理解EmbeddingBag层:
>>> import torch
>>> import torch.nn as nn
# 这里初始化EmbeddingBag有三个参数:
# vocab_size代表语料中不重复的词汇总数
>>> vocab_size = 10
# embed_dim代表词嵌入的维度
>>> embed_dim = 3
# 其中mode参数代表Embedding后Bag中的计算方式,默认为mean
# 因为fasttext要求是平均池化,这里也一定要使用mean
>>> embedding = nn.EmbeddingBag(vocab, 3, mode=’mean’)
# 假设我们有这样一个输入,每个数值是文本映射后的数值
>>> input = torch.LongTensor([1,2,4,5,4,3,2,9])
# 这里我们还需要定义不同Bag起始位置(输入可以分为不同的Bag)
# 这里的[0, 4]代表将输入[1,2,4,5,4,3,2,9]分成了[1,2,4,5]和[4,3,2,9]
# 这样第一个Bag[1,2,4,5]将通过Embedding层得到4个1x3的张量,
# 因为他们属于一个Bag,要做’mean’运算,即张量相加再除4得到一个1x3的张量
# 同理,第二个Bag也得到一个1x3的张量
>>> offsets = torch.LongTensor([0, 4])
# 最终结果就是两个1x3的张量
>>> embedding(input, offsets)
tensor([[ 0.4865, 0.4120, -0.5756],
[ 0.4941, 0.8481, -0.0126]], grad_fn=
- 下面我们使用pytorch将fasttext进行实现:
import torch.nn as nn
import torch.nn.functional as F
class FastText(nn.Module):
“””创建fasttext模型的类”””
def init(self, vocabsize, embeddim, num_class):
“””
:param vocab_size: 语料中不重复的词汇总数
:param embed_dim: 词嵌入维度
:param num_class: 目标的类别数
“””
super().__init()
# 初始化EmbeddingBag层
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
# 初始化全连接层
self.fc = nn.Linear(embed_dim, num_class)
# 初始化权重
self.init_weights()
def init_weights(self):<br /> """初始化权重函数"""<br /> # 均匀分布参数<br /> initrange = 0.5<br /> # embedding层使用均匀分布,如果是采用迁移词向量,这里则初始化迁移词向量<br /> self.embedding.weight.data.uniform_(-initrange, initrange)<br /> # 全连接层也是均匀分布<br /> self.fc.weight.data.uniform_(-initrange, initrange)<br /> # 偏置初始化为0<br /> self.fc.bias.data.zero_()def forward(self, text, offsets):<br /> """<br /> 正向传播逻辑<br /> :param text: 输入的文本的数值映射<br /> :param offsets: Bag的起始位置<br /> """<br /> # 先通过EmbeddingBag层<br /> embedded = self.embedding(text, offsets)<br /> # 再通过全连接层<br /> return self.fc(embedded)
- 说明:
- 因为我们之后会直接使用fasttext工具,因此这个实现在之后不会用到。
第三步: 使用fasttext模型工具进行训练和验证
- 训练和验证部分代码实现:
# 导入fastext工具包
# 关于安装:
# wget https://github.com/facebookresearch/fastText/archive/v0.9.1.zip
# unzip v0.9.1.zip
# cd fastText-0.9.1
# make
# pip install .
# 使fasttext命令成为全局命令
# cp fasttext /usr/bin/fasttext
import fasttext
import pandas as pd
# 训练数据路径
train_data_path = “./name_question.train”
# 验证数据路径
valid_data_path = “./name_question.valid”
字粒度存储路径
char_train_data_path = “./name_question.train.1”
char_valid_data_path = “./name_question.valid.1”
读取训练数据,分隔符为空格
df1 = pd.read_csv(train_data_path, header=None, sep=” “)
df2 = pd.read_csv(valid_data_path, header=None, sep=” “)
使用字的形式进行训练
# 首先对文本内容进行处理,
# 将”请问您贵姓?”变成 “请 问 您 贵 姓 ?”,以空格分割
df1[1] = pd.DataFrame(map(lambda x: “ “.join(list(x)), df1[1]))
df2[1] = pd.DataFrame(map(lambda x: “ “.join(list(x)), df2[1]))
生成训练数据
df1.to_csv(char_train_data_path, header=False, index=False, sep=”\t”)
# 生成验证数据
df2.to_csv(char_valid_data_path, header=False, index=False, sep=”\t”)
进行模型训练,这里我们将n-gram特征设置为2
# 其他参数都是用默认,如:embed_size为100,训练轮数epoch为5
model = fasttext.train_supervised(input=char_train_data_path, wordNgrams=2)
之后我们在验证集上进行验证
valid_result = model.test(char_valid_data_path)
print(valid_result)
- 代码位置:
- /data/ItcastBrain/Info/fasttext_model/model_train.py
- 输出效果:
# 在4000条训练集中,我们一共出现5762个不同汉字和符号,共两个标签
Read 0M words
Number of words: 5762
Number of labels: 2
Progress: 100.0% words/sec/thread: 3098300 lr: 0.000000 avg.loss: 0.057372 ETA: 0h 0m 0s
# 在1000条数据的验证集上,我们的精度为0.882,召回率为0.871
(1000, 0.882, 0.871)
第四步: 使用自动超参数调优方法进行模型调优
- 虽然我们在baseline已经取得了不错的效果,但在实际生产中,我们是一定要做超参数调优的,下面是自动超参数调优的实现:
# 前后的代码不变,只是在训练时配置超参数调优
# autotuneValidationFile参数需要指定验证数据集所在路径,
# 它将在验证集上使用随机搜索方法寻找可能最优的超参数.
# 使用autotuneDuration参数可以控制随机搜索的时间, 默认是300s,
# 根据不同的需求, 我们可以延长或缩短时间.
model = fasttext.train_supervised(
input=char_train_data_path,
autotuneValidationFile=char_valid_data_path,
autotuneDuration=600,
wordNgrams=2,
verbose=3, # 该参数决定日志打印级别, 当设置为3,可以将当前正在尝试的超参数打印出来
)
- 代码位置:
- /data/ItcastBrain/Info/fasttext_model/model_train.py
- 输出效果:
Warning : wordNgrams is manually set to a specific value. It will not be automatically optimized.
# 尝试了309次调优,最佳F1为值为:0.906593
Progress: 100.0% Trials: 309 Best score: 0.906593 ETA: 0h 0m 0s
Training again with best arguments
Trial = 1
epoch = 5
lr = 0.1
dim = 100
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 2000000
dsub = 2
loss = softmax
ead 0M words
Number of words: 5762
Number of labels: 2
Progress: 100.0% words/sec/thread: 3098135 lr: 0.000000 avg.loss: 0.050116 ETA: 0h 0m 0s
(1000, 0.922, 0.898)
- 绘制使用自动超参数调优前后的效果对比图:
# 制图代码
# 导入matplotlib
import matplotlib.pyplot as plt
设置背景风格
plt.switch_backend(“Agg”)
def plot(metric, metric_name, labels, fig_name):
“””
绘制函数
:param metric: 需要对比的评估指标列表
:param metric_name: 需要对比的评估指标名称
:param labels: 对比实验的名称列表,列表长度与metric相同
:param: fig_nam: 对比图保存名称
“””
# 初始化画布和轴
fig, ax = plt.subplots()
# 使用数据绘制柱状图
ax.bar([0, 1], metric)
# 设置纵坐标名称
ax.set_ylabel(metric_name)
# 设置横轴刻度
ax.set_xticks([0, 1])
# 设置横轴名称
ax.set_xticklabels(labels)
# 加入表格线
ax.yaxis.grid(True)
# 设置布局
plt.tight_layout()
# 保存图像并关闭画布
plt.savefig(fig_name)
plt.close(fig)
- 输入两次实验结果:
# 两次的精度结果
precision = [0.882, 0.922]
# 两次的召回率结果
recall = [0.871, 0.898]
plot(precision, “精度”, [‘使用自动超参数调优前’, ‘使用自动超参数调优后’], “at_pre.png”)
plot(recall, “召回率”, [‘使用自动超参数调优前’, ‘使用自动超参数调优后’], “at_recall.png”)
- 精度对比图:
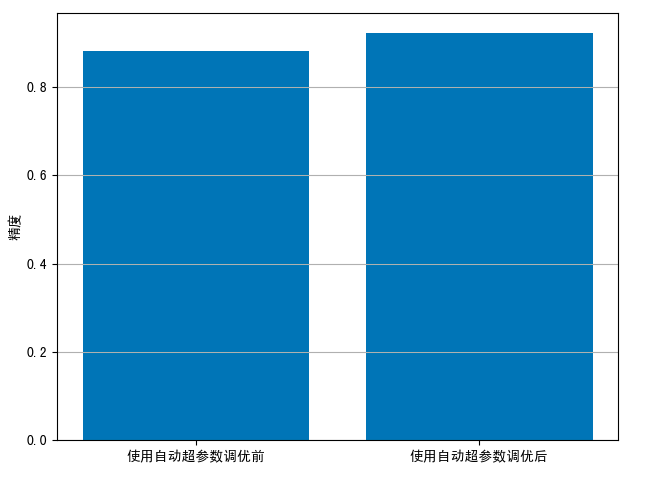
- 召回率对比图:
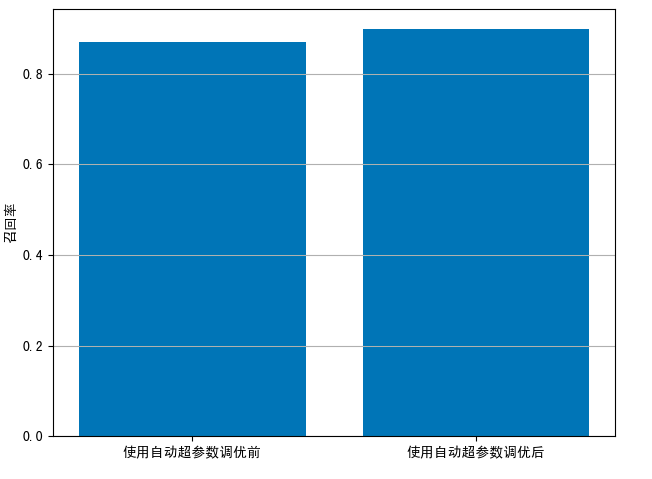
第五步: 模型保存与实例预测
- 保存模型
import time
time = int(time.time())
model_save_path = “./name_question{}.bin”.format(time_)
model.save_model(model_save_path)
- 代码位置:
- /data/ItcastBrain/Info/fasttext_model/model_train.py
- 输出效果:
- 在当前文件目录下生成namequestion时间戳.bin的模型文件。
- 查看当前保存模型的最佳参数组合:
fasttext dump name_question_{xxxxxx}.bin args
- 输出效果:
dim 100
ws 5
epoch 5
minCount 1
neg 5
wordNgrams 2
loss softmax
model sup
bucket 2000000
minn 0
maxn 0
lrUpdateRate 100
t 0.000
- 实例预测:
# 使用fasttext的load_model进行模型的重加载
model = fasttext.load_model(model_save_path)
# 对样本进行预测
result = model.predict(“ “.join(list(“还在么 您好?”)))
print(result)
result = model.predict(“ “.join(list(“贵姓?”)))
print(result)
- 代码位置:
- /data/ItcastBrain/Info/fasttext_model/model_train.py
- 输出效果:
# 第一个不是询问姓名的
((‘labelnone’,), array([0.93931992]))
# 第二个是询问姓名的
((‘labelname’,), array([0.96400203]))
小节总结
这一小节我们 工作了使用fasttext工具训练一个模型来判断咨询师的每一次对话是否为询问”姓名”的语句。 可分为以下步骤:
- 第一步: 正负样本定义与验证集划分
- 第二步: 了解fasttext模型结构
- 第三步: 使用fasttext模型工具进行训练和验证
- 第四步: 使用自动超参数调优方法进行模型调优
- 第五步: 模型保存与实例预测
3.2 模型训练对比试验与优化措施
工作目标
- 掌握模型字词粒度对比试验的实现过程。
- 掌握数据增强试验的实现过程。
- 掌握词向量迁移试验的实现过程。
这一小节我们将在当前的模型训练过程中进行若干对比试验,来判断是否能够提升评估指标,之后将把试验结果表现不错的方法作为模型最终的优化措施。
模型字词粒度对比试验
- 什么是字词粒度对比:
- 细心的 您好可能会发现,我们之前模型训练时是将输入的文本转换成字粒度,eg:”请问您贵姓?”变成 “请 问 您 贵 姓 ?”,每个字以空格分割。现在我们将改变这种分割方式,使用中文分词工具jieba来对文本分词,eg:”请问您贵姓?”变成 “请问 您 贵姓 ?”,以此作为输入来和之前的模型训练结果进行对比。
- 词粒度模型训练实现:
import fasttext
import pandas as pd
import jieba
训练数据路径
train_data_path = “./name_question.train”
# 验证数据路径
valid_data_path = “./name_question.valid”
词粒度存储路径
word_train_data_path = “./name_question.train.2”
word_valid_data_path = “./name_question.valid.2”
读取训练数据,分隔符为空格
df1 = pd.read_csv(train_data_path, header=None, sep=” “)
df2 = pd.read_csv(valid_data_path, header=None, sep=” “)
使用词的形式进行训练
df1[1] = pd.DataFrame(map(lambda x: “ “.join(jieba.cut(x)), df1[1]))
df2[1] = pd.DataFrame(map(lambda x: “ “.join(jieba.cut(x)), df2[1]))
生成训练数据
df1.to_csv(word_train_data_path, header=False, index=False, sep=”\t”)
# 生成验证数据
df2.to_csv(word_valid_data_path, header=False, index=False, sep=”\t”)
进行模型训练,这里我们将n-gram特征设置为2
# 其他参数都是用默认,如:embed_size为100,训练轮数epoch为5
# model = fasttext.train_supervised(input=word_train_data_path, wordNgrams=2)
model = fasttext.train_supervised(
input=word_train_data_path,
autotuneValidationFile=word_valid_data_path,
autotuneDuration=600,
wordNgrams=2,
)
之后我们在验证集上进行验证
valid_result = model.test(word_valid_data_path)
print(valid_result)
- 文件位置:
- /data/ItcastBrain/Info/fasttext_model/model_train_gran_test.py
- 输出效果:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.627 seconds.
Prefix dict has been built successfully.
Warning : wordNgrams is manually set to a specific value. It will not be automatically optimized.
Progress: 100.0% Trials: 326 Best score: 0.912568 ETA: 0h 0m 0s
Training again with best arguments
Read 0M words
Number of words: 2477
Number of labels: 2
Progress: 100.0% words/sec/thread: 337 lr: 0.000000 avg.loss: 0.045739 ETA: 0h 0m 0s
(1000, 0.938, 0.892)
- 精度与召回对比数据:
| 精度 | 召回率 | |
|---|---|---|
| 词粒度 | 0.938 | 0.892 |
| 字粒度 | 0.922 | 0.898 |
- 分析:
- 由表可见,当以词为粒度进行训练时,训练样本中的Number of words数量锐减,从某种程度上减轻了模型的拟合难度,在精度表现上比之前的”字粒度”提升约1.6%,召回率表现与之前相当。因此在当前语料上从使用”词粒度”是一项可以提升评估指标的优化措施。接下来的试验也是以词粒度为基础进行的。
数据增强对比试验
- 什么是数据增强对比:
- 当前我们的训练数据仅有4000条,这对于深度 工作任务来讲是比较少的(即使是模型结构简单的fasttext),我们希望模型能够有更强的泛化能力,因此,我们将使用”回译”数据增强方法来扩展数据量,将扩展训练后的效果与之前的模型效果进行对比。
- 数据增强与模型训练的实现:
- 首先,对原始数据中的文本进行回译,得到增强数据
- 再将原始数据与增强数据堆叠,写入新的文件
import pandas as pd
# 导入google翻译接口工具
# 安装: pip install googletrans
from googletrans import Translator
原始数据和增强后数据的存储路径
train_data_path = “./name_question.train”
augm_train_data_path = “./name_question_augm.train”
实例化翻译对象
translator = Translator()
读取原始训练数据
df = pd.read_csv(train_data_path, header=None, sep=” “)
转成列表并提取标签和文本内容
input = df.values.tolist()
label = list(map(lambda x: x[0], input))
content = list(map(lambda x: x[1], input_))
以标签和内容列表为输入进行数据增强,以相同格式进行输出
# 进行批量翻译, 翻译目标是英语
translations = translator.translate(content, dest=”en”)
# 获得翻译后的结果
en_res = list(map(lambda x: x.text, translations))
最后在翻译回中文, 完成回译全部流程
translations = translator.translate(en_res, dest=”zh-cn”)
cn_res = list(map(lambda x: x.text, translations))
res = list(zip(label, cn_res))
将原始数据与增强数据进行堆叠(concat)
df1 = pd.DataFrame(res)
df2 = pd.DataFrame(input_)
df = pd.concat([df1, df2], axis=0, join=”outer”)
# 写入文件
df.to_csv(augm_train_data_path, index=False, header=None, sep=” “)
- 文件位置:
- /data/ItcastBrain/Info/fasttext_model/model_train_augm_test.py
- 输出效果:
- 在/data/ItcastBrain/Info/fasttext_model/路径下出现name_question_augm.train文件。内容如下:
# 只展示增强后的部分数据
labelname 你叫什么名字?
labelnone 嗯嗯。哦,你也可以从头开始
labelname 是你的名字?
labelnone 你的QQ是
labelname 您可以留下您的姓名
labelnone 现在方便吗?
labelnone 刘芳跟着 设计,请知道。
labelname 您好们,你叫什么名字
labelname 电话+叫什么名字?
labelname 是你的名字吗?我应该怎么称呼您?
- 使用增强后的数据进行训练:
# 这段代码与词粒度模型训练实现的代码逻辑相同,只不过读取的训练数据不同
import jieba
import fasttext
请 您好们根据上述的过程,自己将name_question_augm.train转化成基于词粒度的word_name_question_augm.train
word_augm_train_data_path = “./word_name_question_augm.train”
model = fasttext.train_supervised(
input=word_aumg_train_data_path,
autotuneValidationFile=word_valid_data_path,
autotuneDuration=600,
wordNgrams=2,
)
之后在验证集上进行验证
valid_result = model.test(word_valid_data_path)
print(valid_result)
- 文件位置:
- /data/ItcastBrain/Info/fasttext_model/model_train_augm_test.py
- 输出效果:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.627 seconds.
Prefix dict has been built successfully.
Warning : wordNgrams is manually set to a specific value. It will not be automatically optimized.
Progress: 100.0% Trials: 305 Best score: 0.914067 ETA: 0h 0m 0s
Training again with best arguments
Read 0M words
Number of words: 4157
Number of labels: 2
Progress: 100.0% words/sec/thread: 337 lr: 0.000000 avg.loss: 0.044921 ETA: 0h 0m 0s
(1000, 0.932, 0.895)
- 精度与召回对比数据:
| 精度 | 召回率 | |
|---|---|---|
| 非数据增强 | 0.938 | 0.892 |
| 数据增强 | 0.932 | 0.895 |
- 分析:
- 由表可见,数据增强在该语料下并没有为模型指标带来太多的改善,说明增强的文本内容与验证集中badcase(那些没有被识别正确的样本)的关联并不大。一方面,该文本的回译效果并不是很好。另一方面,可能因为当前我们的模型指标已经处在一个比较高的水平(F1已经在91%左右),一般数据增强技术对于初始阶段的模型泛化提升帮助较大,而对于高水平模型提升能力有限,因此我们需要寻找更具有针对性的方法。
词向量迁移对比试验
- 什么是词向量迁移:
- 原始的fasttext在初始化Embedding参数时,都是使用随机的均匀分布。但是fasttext其实也提供了众多语言的预训练参数(包括中文),这些预训练参数能够帮助模型选择更好的训练初始点,也让文本语义更加丰富。下面我们将使用这些预训练参数来训练模型,并和之前的结果进行对比。
- 词向量迁移与模型训练实现:
- 首先通过以下地址:https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.zh.300.vec.gz,下载cc.zh.300.vec.gz文件。
- .gz文件使用
gunzip cc.zh.300.vec.gz进行解压,请确保文件在/data/ItcastBrain/Info/fasttext_model/路径下。
import jieba
import fasttext
import pandas as pd
迁移词向量路径
word_vec_path = “./cc.zh.300.vec”
默认使用词粒度
# 这里注意:fasttext模型默认的词向量维度为100
# 而这里迁移的词向量维度是300,因此必须令参数dim=300
model = fasttext.train_supervised(
input=word_train_data_path,
autotuneValidationFile=word_valid_data_path,
autotuneDuration=600,
wordNgrams=2,
dim=300,
pretrainedVectors=word_vec_path,
)
之后在验证集上进行验证
valid_result = model.test(word_valid_data_path)
print(valid_result)
- 代码位置:
- /data/ItcastBrain/Info/fasttext_model/model_train_vec_test.py
- 输出效果:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.627 seconds.
Prefix dict has been built successfully.
Warning : wordNgrams is manually set to a specific value. It will not be automatically optimized.
Warning : dim is manually set to a specific value. It will not be automatically optimized.
Progress: 100.0% Trials: 305 Best score: 0.937167 ETA: 0h 0m 0s
Training again with best arguments
Read 0M words
Number of words: 2477
Number of labels: 2
Progress: 100.0% words/sec/thread: 337 lr: 0.000000 avg.loss: 0.029621 ETA: 0h 0m 0s
(1000, 0.951, 0.927)
- 精度与召回对比数据:
| 精度 | 召回率 | |
|---|---|---|
| 非词向量迁移 | 0.938 | 0.892 |
| 词向量迁移 | 0.951 | 0.927 |
- 分析:
- 由表可知,通过迁移词向量使得精度和召回率得到明显提升,精度提升约1.3%,召回率提升约3.5%,说明在迁移的词向量能够对当前语料起到很好的表述作用,进而更多的覆盖验证集中的样本,提升模型泛化能力。这只是我们在未知领域(使用大型综合语料)使用迁移词向量的效果,接下来我们使用领域内词向量进行迁移。
- 领域内词向量进行迁移
- 我们知道,在我们当前的问题背景下,无标签的语料(客户与咨询师的对话)基本是无限提供的,而且,fasttext工具也具备将无标签语料训练成词向量的能力,因此,我们就可以结合该工具两个重要功能完成领域内词向量进行迁移(这其实正是fasttext工具的正确打开方式,也是作者最初创立该工具两个功能的用意)。
- 使用无监督语料训练词向量:
- 实际上我们在80000个对话块上进行词向量训练。
- 使用无监督语料训练词向量:
- 我们知道,在我们当前的问题背景下,无标签的语料(客户与咨询师的对话)基本是无限提供的,而且,fasttext工具也具备将无标签语料训练成词向量的能力,因此,我们就可以结合该工具两个重要功能完成领域内词向量进行迁移(这其实正是fasttext工具的正确打开方式,也是作者最初创立该工具两个功能的用意)。
import fasttext
# 在训练词向量过程中, 我们可以设定很多常用超参数来调节我们的模型效果, 如:
# 无监督训练模式: ‘skipgram’ 或者 ‘cbow’, 默认为’skipgram’, 在实践中,skipgram模式在利用子词方面比cbow更好.
# 词嵌入维度dim: 默认为100, 但随着语料库的增大, 词嵌入的维度往往也要更大,我们选择是150
# 数据循环次数epoch: 默认为5,
# 工作率lr: 默认为0.05, 根据经验, 建议选择[0.01,1]范围内.
# 使用的线程数thread: 默认为12个线程, 一般建议和你的cpu核数相同.
model = fasttext.train_unsupervised(‘unsupervised_data.txt’, “skipgram”, dim=150, epoch=5, lr=0.1, thread=8)
获得一个bin格式模型
model.save_model(“unsupervised_data.bin”)
- 代码位置:
- /data/ItcastBrain/Info/fasttext_model/unsupervised_train.py
- 输出效果:
Read 124M words
Number of words: 218316
Number of labels: 0
Progress: 100.0% words/sec/thread: 49523 lr: 0.000000 avg.loss: 1.777205 ETA: 0h 0m 0s
- 对模型格式进行转换:
- 之前我们加载的预训练词向量都是vec格式的,但无监督训练后却是bin格式,因此需要进行转换。
# 以下代码为fasttext官方推荐:
# 请将以下代码保存在bintovec.py文件中
from future import absoluteimport
from future import division
from future import printfunction
from __future import unicode_literals
from __future import division, absolute_import, print_function
from fasttext import load_model
import argparse
import errno
if name == “main“:
# 整个代码逻辑非常简单
# 以bin格式的模型为输入参数
# 按照vec格式进行文本写入
# 可通过head -5 xxx.vec进行文件查看
parser = argparse.ArgumentParser(
description=(“Print fasttext .vec file to stdout from .bin file”)
)
parser.add_argument(
“model”,
help=”Model to use”,
)
args = parser.parse_args()
f = load_model(args.model)<br /> words = f.get_words()<br /> print(str(len(words)) + " " + str(f.get_dimension()))<br /> for w in words:<br /> v = f.get_word_vector(w)<br /> vstr = ""<br /> for vi in v:<br /> vstr += " " + str(vi)<br /> try:<br /> print(w + vstr)<br /> except IOError as e:<br /> if e.errno == errno.EPIPE:<br /> pass
- 代码位置:
- /data/ItcastBrain/Info/fasttext_model/bin_to_vec.py
- bin_to_vec.py脚本使用:
# 在bin_to_vec.py路径下执行该命令,生成unsupervised_data.vec
python bin_to_vec.py unsupervised_data.bin > unsupervised_data.vec
- 同样的方式进行训练和验证:
...
model = fasttext.train_supervised(
input=word_train_data_path,
autotuneValidationFile=word_valid_data_path,
autotuneDuration=600,
wordNgrams=2,
dim=150,
pretrainedVectors=”unsupervised_data.vec”,
)
之后在验证集上进行验证
valid_result = model.test(word_valid_data_path)
…
- 精度与召回对比数据:
| 精度 | 召回率 | |
|---|---|---|
| 非词向量迁移 | 0.938 | 0.892 |
| 领域内词向量迁移 | 0.968 | 0.949 |
- 分析:
- 由表可知,通过领域内的迁移词向量使得精度和召回率得到更明显的提升,精度提升约3%,召回率提升约5.7%,说明在领域内的迁移词向量能够对当前语料起到更好的表述作用,进而更多的覆盖验证集中的样本,提升模型泛化能力。
领域内一致性训练-UDAT(拓展)
UDAT思想受到Google Research的论文《UNSUPERVISED DATA AUGMENTATION FOR CONSISTENCY TRAINING》启发,目的是更充分的利用领域内的无监督语料,同时将其与数据增强方式进行结合。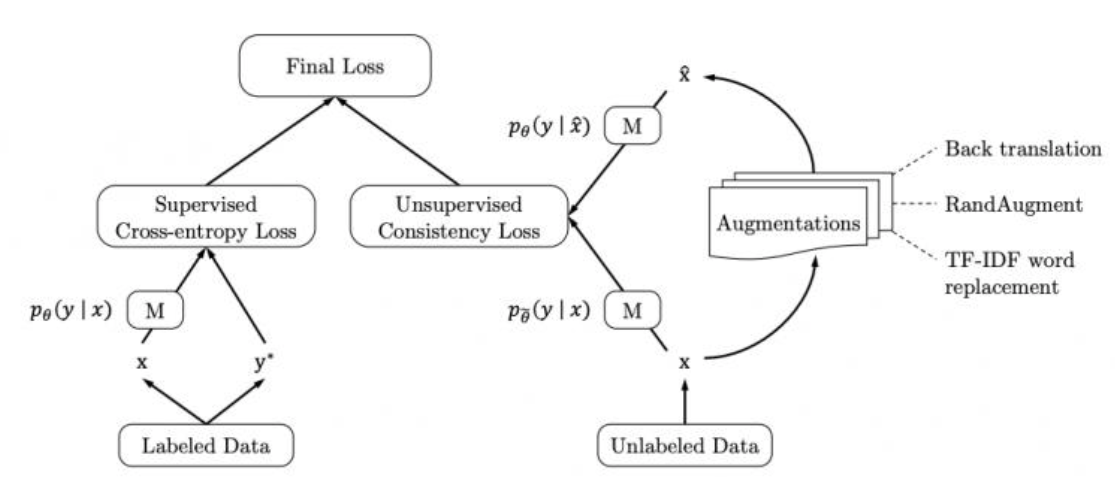
- UDAT的实现步骤:
- 第一步:对无监督数据(无标注的咨询对话)进行数据增强(回译),这和我们之前 工作的对有监督数据增强不同,这样我们就可以得到每条无监督数据及其对应的变体。
- 第二步:定义返回logits分布的fasttext模型,该模型仍由Embedding + GAP + Dense组成,不过Dense最后输出维度较高,如128,256,512等,将第一步得到的无监督数据及其变体分别输入该模型,获得两个张量表示。
- 第三步:我们损失函数使用KL散度,它能够很好的比较两个分布之间差异,优化目的就是使无监督数据及其变体的高阶特征表示差距更小,因为他们本来就是属于同一标签(1或者0)。
- 第四步:通过第三步的预训练,我们可以得到fasttext模型的embedding参数,接着,我们重新基于该参数微调后面的Dense层(换成输出为指定标签数的全连接),这时的微调使用的是少量的有监督数据。
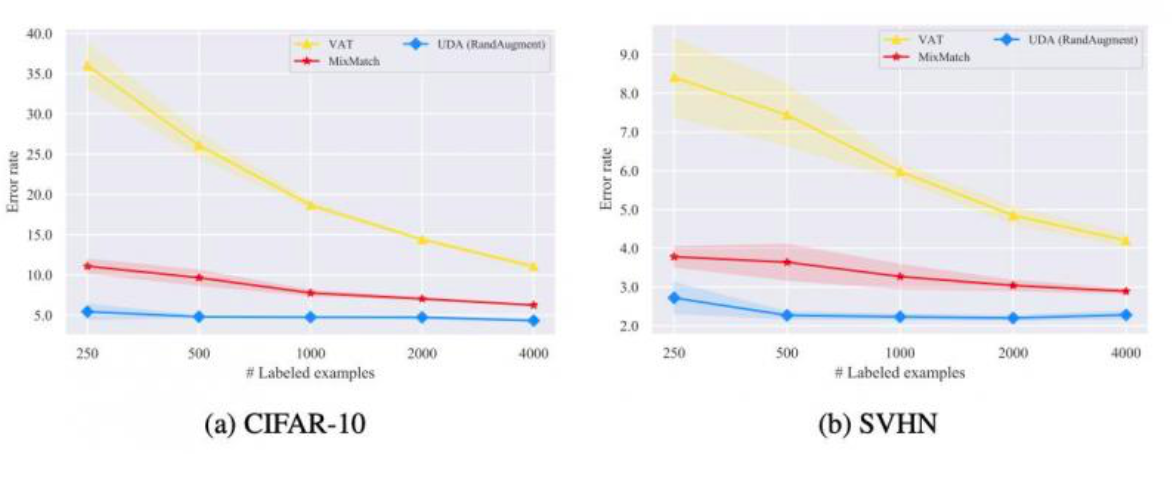
- UDAT的原理:
- 我们知道,单纯的领域内词向量迁移获得的embedding只是保存了文本语料中的词义,这些张量表示中并不会包含句子与句子差异,而我们最终模型需要进行的任务是判断句子类别(差异)。
- 因此,UDAT是从句子与句子的差异角度出发进行embedding的预训练(这种方式也是会获得词义),在整个预训练过程中,模型将获得区分类别差异的能力(虽然不能明确具体的类别),这就好像聚类,最后,再通过有监督的微调,就能够通过很少的标签数据将聚类后的数据明确划分,其泛化效果远远超过单纯的有监督以及增强+有监督的方式。
- 图中,VAT代表单纯的有监督方式,Mix-Batch代表增强+有监督的混合方式,UDA即一致性训练方式。
- 实际精度与召回对比数据:
| 精度 | 召回率 | |
|---|---|---|
| 非词向量迁移 | 0.938 | 0.892 |
| 领域内一致性训练 | 0.976 | 0.951 |
- 注意:
- 领域内一致性训练,需要自主构建fasttext模型,并适当调整网络结构,还需要使用一些自动超参数调优工具,如使用KerasTuner对fasttext模型进行超参数调优。
小节总结
这一小节,我们做了若干对比试验,来寻找模型训练过程中的优化措施,包括:
- 模型字词粒度对比试验
- 数据增强对比试验
- 词向量迁移对比试验
- 领域内一致性训练对比实验
通过试验结果,我们认为在当前语料下,模型使用词粒度和词向量的迁移能够有效优化评估指标。当然,这些优化措施的作用也会随着数据集的变化而变化,实际生产中,这样的试验需要在每次数据集发生大的改动后进行。
3.3 模型服务的部署
工作目标
- 了解什么是模型热更新以及如何做到热更新。
- 了解Flask框架及其相关的服务组件。
- 掌握使用Flask框架将模型封装成服务的流程。
什么是模型热更新
- 因为训练AI模型往往是较大的文件,在每次IO时往往比较耗时,因此会选择在服务开启时读入内存,避免IO操作。而这样的话,就意味着当我们更新模型时需要暂停服务, 这对于在线任务是非常不可取的行为;因此我们需要一种既能避免IO又能使用户无感知的方式,这种的要求就是模型热更新要求。
如何做到热更新
- 最常见的满足热更新要求的方法就是一同开启两个模型服务,一个作为正式使用,一个作为backup(备用),当我们有更新需求时,将正式服务暂停进行模型更换,而此时备用服务将继续为用户服务,直到正式服务重新上线。在正式服务运转正常后,再为备用服务更换模型。
Flask服务组件
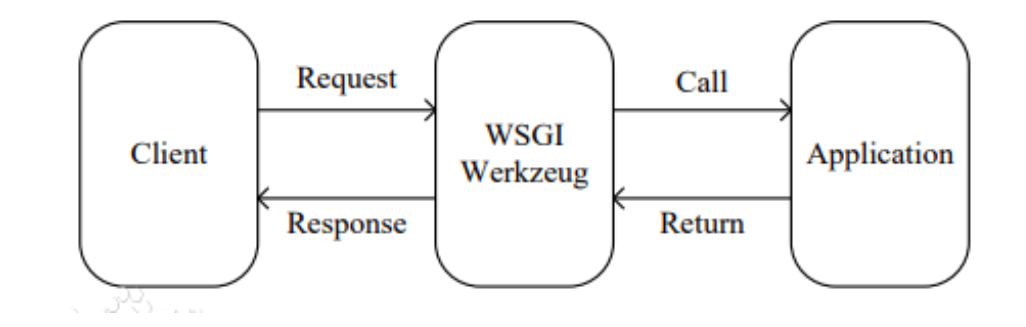
- web框架FLask:
- Flask框架是当下最受欢迎的python轻量级框架, 也是pytorch官网指定的部署框架. Flask的基本模式为在程序里将一个视图函数分配给一个URL,每当用户访问这个URL时,系统就会执行给该URL分配好的视图函数,获取函数的返回值.
- 作用:
- 在项目中, Flask框架是主逻辑服务和句子相关模型服务使用的服务框架.
- 安装:
# 使用pip安装Flask
pip install Flask==1.1.1
- 基本使用方法:
# 导入Flask类
from flask import Flask
# 创建一个该类的实例app, 参数为name, 这个参数是必需的,
# 这样Flask才能知道在哪里可找到模板和静态文件等东西.
app = Flask(name)
使用route()装饰器来告诉Flask触发函数的URL
@app.route(‘/‘)
def hello_world():
“””请求指定的url后,执行的主要逻辑函数”””
# 在用户浏览器中显示信息:’Hello, World!’
return ‘Hello, World!’
if name == ‘main‘:
app.run(host=”0.0.0.0”, port=5001)
- 代码位置:
- /data/ItcastBrain/Info/fasttext_server/app.py
- 启动服务:
python app.py
- 查看效果:
- 通过浏览器打开地址http://0.0.0.0:5001可看见打印了’Hello, World’.
- web组件Gunicorn:
- Gunicorn是一个被广泛使用的高性能的Python WSGI UNIX HTTP服务组件(WSGI: Web Server Gateway Interface),移植自Ruby的独角兽(Unicorn )项目,具有使用非常简单,轻量级的资源消耗,以及高性能等特点。
- 作用:
- 在项目中, Gunicorn和Flask框架一同使用, 处理请求, 因其高性能的特点能够有效减少服务丢包率.
- 安装:
# 使用pip安装gunicorn
pip install gunicorn==20.0.4
- 基本使用方法:
# 注意:kill掉之前的5001端口服务,不再使用原生的启动方式
# 而是使用gunicorn启动Flask服务:
gunicorn -w 1 -b 0.0.0.0:5001 app:app
# -w 代表开启的进程数, 我们只开启一个进程
# -b 服务的IP地址和端口
# app:app 是指执行的主要对象位置, 在app.py中的app对象
使用Flask框架将模型封装成服务
我们可以将模型封装成服务的流程分为三步:
- 第一步: 编写app.py文件
- 第二步: 使用gunicorn启动服务
- 第三步: 编写test.py进行接口测试
- 第四步: 使用Nginx代理两个服务满足热更新
第一步: 编写app.py文件,代码实现如下:
# Flask框架固定工具
from flask import Flask
from flask import request
app = Flask(name)
导入fasttext
import fasttext
import jieba
最新的模型,大家根据自己之前训练的模型名字进行修改
model_name = “name_question_1591259822.bin”
最新模型的全路径
model_path = “/data/ItcastBrain/Info/fasttext_model/“ + model_name
加载已训练的模型,注意: 这段加载语句不能写入下方的函数中,
# 否则将会每次请求都会重新加载
model = fasttext.load_model(model_path)
定义服务请求路径和方式, 这里使用POST请求
@app.route(“/v1/is_name_question/“, methods=[“POST”])
def recogniition():
“””
姓名问题识别函数
它的输入咨询师所有的对话和索引列表,[[content, index], [content, index], …]
它的输出是姓名问题文本对应的index,如果没有则为-1
“””
# 首先接受传过来的数据体,即咨询师所有的对话和索引列表
text = request.get_json()[“text”]
# 设置默认result为-1
result = -1
# 遍历对话内容和索引
for te, index in text:
# 使用模型进行预测
predicted = model.predict(“ “.join(jieba.cut(te)))
if predicted[0][0] == “labelname”:
# 如果预测出的标签为”labelname”, 则证明出现姓名询问语句
# 记录索引
result = index
# 停止循环,因为在对话中客服往往只询问一次客户姓名
break
# 返回字符串类型的结果(返回json或str形式都是可以的)
return str(result)
- 代码位置:
- /data/ItcastBrain/Info/fasttext_server/app.py
第二步: 使用gunicorn来启动服务
# 假如我们不再/data/ItcastBrain/Info/fasttext_server/路径下启动
# 则可以添加—chdir参数来指明app路径
gunicorn -w 1 -b 0.0.0.0:5001 —chdir /data/ItcastBrain/Info/fasttext_server/ app:app
- 输出效果:
[2020-06-04 17:04:11 +0800] [28276] [INFO] Starting gunicorn 20.0.4
[2020-06-04 17:04:11 +0800] [28276] [INFO] Listening at: http://0.0.0.0:5001 (28276)
[2020-06-04 17:04:11 +0800] [28276] [INFO] Using worker: sync
[2020-06-04 17:04:11 +0800] [28279] [INFO] Booting worker with pid: 28279
Warning : load_model does not return WordVectorModel or SupervisedModel any more, but a FastText object which is very similar.
第三步: 编写test.py进行接口测试
import requests
import time
根据gunicorn开启的5001端口,app.py中的url路径
url = “http://0.0.0.0:5001/v1/is_name_question/“
# key为text,内容为咨询师所有对话内容和索引的列表
data = {
“text”: [
[“你好,你是想了解哪个课程呢?”, 0],
[“还在么 您好?”, 0],
[“你好”, 1],
[“您想了解哪个专业的学费呢”, 1],
[“专业不同,学时学费也不一样”, 1],
[“好的,方便QQ或者微信,邮箱接收吗?我这边发您”, 3],
[“您贵姓”, 5],
]
}
# 多层嵌套必须使用json=data
# 超时时间为200
start = time.time()
res = requests.post(url, json=data, timeout=200)
end = time.time()
print(end - start)
print(res.text)
- 代码位置:
- data/ItcastBrain/Info/fasttext_server/test.py
- 输出效果:
# 平均处理一个请求只需要3.5ms
0.003493785858154297
返回对应的索引
5
第四步: 使用Nginx代理两个服务满足热更新
到这里说明我们模型服务能够正常工作,之后我们将启动两个同样的服务,分别使用5001和5002端口, 并将两个服务使用Nginx代理宜满足热更新。下面对nginx进行一些简单介绍,并对其中的配置进行说明。
- Nginx:
- Nginx是一个高性能的HTTP和反向代理web服务器,也是工业界web服务最常使用的外层代理。
- 安装:
yum install nginx
- Nginx热更新部分配置说明:
- 这些配置已经为大家写好,可以在/data/ItcastBrain/conf/nginx/nginx.conf中进行查看。
...
以下是与热更新有关的配置
# 这里代理两个端口的服务
# 其中5002为backup,即当5001服务停止时被启用
# 这里的prod要与下面proxy_pass中http://后的名称相同
upstream prod {
server 0.0.0.0:5001;
server 0.0.0.0:5002 backup;
}
nginx的外层服务使用8086端口
server {
listen 8086;
server_name 0.0.0.0;
location /static/ {
alias /data/ItcastBrain/static/;
}
# 这里注意prod要与上面upstream后的名称相同<br /> location / {<br /> proxy_pass http://prod;<br /> include /data/ItcastBrain/conf/nginx/uwsgi_params;<br /> proxy_set_header X-Real-IP $remote_addr;}<br /> }
…
- Nginx的启动:
# 实际中我们并不会直接启动Nginx,而是在整体服务部署时使用supervisor进行启动和关闭
# 因此这里大家了解以下启动命令即可
# -c是指向配置文件
# -g “daemon off;”代表非后台运行
nginx -c /data/ItcastBrain/conf/nginx/nginx.conf -g “daemon off;”
小节总结
- 工作了什么是热更新与如何做到热更新
- 工作了Flask服务组件的使用
- 工作了将模型封装成服务的流程
- 第一步: 编写app.py文件
- 第二步: 使用gunicorn启动服务
- 第三步: 编写test.py进行接口测试
- 第四步: 使用Nginx代理两个服务满足热更新
3.4 延展知识:层次softmax
工作目标
- 了解fasttext模型中层次softmax的应用场景和原理。
- 掌握层次softmax的使用方法。
- 首先明确:我们在该项目中并没有使用层次softmax!
层次softmax的应用场景
- 当业务场景中存在大量目标类别时(一般指超过500个类别以上的分类任务),fasttext的输出层会使用层次softmax来提升训练效率。而我们的项目是二分类,因此不需要使用。
层次softmax原理
1,明确到底什么是层次softmax:
- 是一种使用最优二叉树结构替代网络原有输出层(全连接层)的方式。
2,提升训练效率的内在原理:
- 在训练阶段,由于二叉树是根据预先统计的每个标签数量的占比构造的霍夫曼树(最优二叉树),根据霍夫曼树的性质,使得占比最大的标签节点路径最短,又因为路径中的节点计算等同于神经网络的节点,也就是代表参数量,意味着这种方式需要更新和计算的参数最少,因此提升训练速度。
3,是否存在一定弊端:
- 因为最优二叉树的节点中存储参数,而样本数量最多的标签对应的参数又最少,可能出现在某些类别上欠拟合,影响模型准确率。因此,若非存在大量目标类别产生的训练低效,首选具有全连接层的输出层。
- 详解视频(官方):
- 重点说明:
- 根据我们之前的 工作,fasttext不仅能够分类,也能够训练词向量,而词向量的训练输出是超多类别的(词汇总数),因此使用了层次softmax,这也是上一代word2vec工具和fastext中实现的word2vec的重要区别,面试中经常问到word2vec和fasttext的区别是什么,回答就要以层次softmax为重点,另外一个是n-gram特征的hash bucket(考察较少)。
层次softmax的使用方法
# 实现非常简单,loss='hs'即可
model = fasttext.train_supervised(input=”cooking.train”, lr=1.0, dim=50, loss=’hs’)
Number of words: 9012
Number of labels: 734
Progress: 100.0% words/sec/thread: 2199406 lr: 0.000000 loss: 1.718807 eta: 0h0m
Read 0M words
小节总结
- 工作了层次softmax的应用场景。
- 工作了层次softmax原理。
- 工作了层次softmax的使用方法。
3.5 延展知识:KerasTuner进行自动超参数调优
工作目标
- 掌握如何使用Keras Tuner进行自动超参数调优。
- 掌握使用Keras Tuner对fasttext模型进行超参数调优以提升评估指标。
- 掌握当某些类别中数据量达到一定程度时如何提升数据指标。
如何使用Keras Tuner进行自动超参数调优
- Keras Tuner介绍:
- Keras Tuner 是一个易于使用的分布式超参数优化框架,能够解决执行超参数搜索时的一些痛点。Keras Tuner 可让您轻松定义搜索空间,并利用内置算法找到最佳超参数的值,内置有贝叶斯优化、Hyperband和随机搜索算法,其设计亦便于研究人员进行新的搜索算法的扩展。
- Keras Tuner的安装:
pip install keras-tuner==1.0.1
- Keras Tuner使用代码说明:
# 导入tensorflow中的keras
from tensorflow import keras
from tensorflow.keras import layers
导入keras tuner中的超参数调优方法
# 随机搜索
from kerastuner.tuners import RandomSearch
# 贝叶斯优化
from kerastuner.tuners import BayesianOptimization
加载手写字识别的标准数据集
(x, y), (val_x, val_y) = keras.datasets.mnist.load_data()
# 像素值缩放
x = x.astype(‘float32’) / 255.
val_x = val_x.astype(‘float32’) / 255.
获取指定数量的数据作为样本
x = x[:10000]
y = y[:10000]
def buildmodel(hp):
“””
构建模型
:param hp: 超参数选择器
“””
# 创建keras序列模型
model = keras.Sequential()
# 添加指定的层
model.add(layers.Flatten(input_shape=(28, 28)))
# 将层数作为超参数进行调节
for i in range(hp.Int(‘num_layers’, 2, 20)):
# 将每层的节点数作为超参数进行调节
model.add(layers.Dense(units=hp.Int(‘units‘ + str(i), 32, 512),
activation=’relu’))
# 增加输出层
model.add(layers.Dense(10, activation=’softmax’))
# 模型相关配置,并将Adam中的 工作率作为超参数进行调节
model.compile(
optimizer=keras.optimizers.Adam(
hp.Choice(‘learning_rate’, [1e-2, 1e-3, 1e-4])),
loss=’sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
# 返回模型
return model
使用随机搜索获得超参数调节器
tuner = RandomSearch(
# 构建模型函数名,默认传入hp
build_model,
# 优化指标
objective=’val_accuracy’,
# 最大尝试次数
max_trials=10,
# 每种方式的尝试次数
executions_per_trial=3,
# 结果保存路径
directory=’test_dir’)
使用调节器在指定数据上进行搜索
tuner.search(x=x,
y=y,
epochs=3,
validation_data=(val_x, val_y))
将结果作为摘要打印
tuner.results_summary()
- 输出效果:
## 随机搜索的结果
[Results summary]
|-Results in test_dir/untitled_project
|-Showing 10 best trials
|-Objective(name=’val_acc’, direction=’max’)
[Trial summary]
|-Trial ID: ca9e21ebe997028e6515320630bcc045
|-Score: 0.9430332779884338
|-Best step: 0
> Hyperparameters:
|-learning_rate: 0.001
|-num_layers: 7
|-units_0: 480
|-units_1: 288
|-units_10: 416
|-units_11: 416
|-units_12: 224
|-units_13: 64
|-units_14: 192
|-units_15: 480
|-units_16: 64
|-units_17: 416
|-units_18: 160
|-units_19: 480
|-units_2: 288
|-units_3: 384
|-units_4: 480
|-units_5: 384
|-units_6: 160
|-units_7: 416
|-units_8: 448
|-units_9: 416
贝叶斯优化的结果
[Results summary]
|-Results in test_dir/untitled_project
|-Showing 10 best trials
|-Objective(name=’val_acc’, direction=’max’)
[Trial summary]
|-Trial ID: 5acfd9cf670cfa3dde05c1b144e48c56
|-Score: 0.9283999800682068
|-Best step: 0
> Hyperparameters:
|-learning_rate: 0.0001
|-num_layers: 2
|-units_0: 512
|-units_1: 512
|-units_10: 512
|-units_11: 512
|-units_12: 512
|-units_13: 512
|-units_14: 512
|-units_15: 512
|-units_16: 512
|-units_17: 512
|-units_18: 512
|-units_2: 32
|-units_3: 512
|-units_4: 32
|-units_5: 32
|-units_6: 32
|-units_7: 32
|-units_8: 512
|-units_9: 512
使用Keras Tuner对fasttext模型进行超参数调优
- 对模型结构构建以及训练部分的代码进行修改:
### 使用了tf中的keras,和keras tuner的tensorflow版本依然是1.14.0
from kerastuner.tuners import RandomSearch
from kerastuner.tuners import BayesianOptimization
from kerastuner import HyperModel
class FasttextModel(HyperModel):
def __init__(self, maxlen, new_max_features):<br /> self.maxlen = maxlen<br /> self.new_max_features = new_max_featuresdef _model_build(self, hp):<br /> """该函数用于模型结构构建"""# 在函数中,首先初始化一个序列模型对象<br /> model = keras.models.Sequential()# 然后首层使用Embedding层进行词向量映射<br /> # 在这里将词嵌入维度作为超参数进行调节<br /> model.add(keras.layers.Embedding(self.new_max_features,<br /> hp.Choice('embedding_dims', values=[50, 100]),<br /> input_length=self.maxlen))# 然后用构建全局平均池化层,减少模型参数,防止过拟合<br /> model.add(keras.layers.GlobalAveragePooling1D())# 最后构建全连接层 + sigmoid层来进行分类.<br /> model.add(keras.layers.Dense(1, activation='sigmoid'))# 整合编译过程<br /> # 在这里将优化器和指定优化器中的 工作率作为超参数进行调节<br /> model.compile(loss='binary_crossentropy',<br /> optimizer=hp.Choice('optimizer', values=['Adam', 'Adagrad']),<br /> metrics=['accuracy'])return model
日志保存路径
log_dir = “./log_dir”
# batch_size是每次进行参数更新的样本数量
batch_size = 32
epochs将全部数据遍历训练的次数
epochs = 10
def model_fit(x_train, y_train, maxlen, new_max_features):
“””用于模型训练”””
_model_build = FasttextModel(maxlen, new_max_features)._model_build
tuner = RandomSearch(
_model_build,
# 调参器度量指标
objective=’val_acc’,
# 全局最多尝试的次数
max_trials=8,
# 每个调优参数的尝试次数
executions_per_trial=2,
directory=’log_dir’,
project_name=’RStune’)
tuner.search(x_train, y_train,<br /> batch_size=batch_size,<br /> epochs=epochs,<br /> validation_split=0.2)print("******************************")<br /> tuner.results_summary()<br /> # 得到调优后最好的1个模型<br /> model = tuner.get_best_models(num_models=1)[0]<br /> return model
- 代码位置:
- /data/django-uwsgi/text_labeled/model_train/tf_movie_model_train_with_tuner.py
- 调用:
model = model_fit(x_train, y_train, maxlen, new_max_features)
- 输出效果:
# 调优过程日志过长,只显示部分
# 显示10次最佳调优结果和对应的超参数, 根据调优结果的优劣依次显示
[Results summary]
|-Results in log_dir/BOtune
|-Showing 10 best trials
|-Objective(name=’val_acc’, direction=’max’)
[Trial summary]
|-Trial ID: 02c1d9133afa2424a906e2e31b756215
|-Score: 0.89716099076271057
|-Best step: 0
> Hyperparameters:
|-embedding_dims: 50
|-optimizer: Adam
[Trial summary]
|-Trial ID: cdcd861a9016099d619b47e6ff1d2f3f
|-Score: 0.842568966031074524
|-Best step: 0
> Hyperparameters:
|-embedding_dims: 100
|-optimizer: Adagrad
…
- 练一练:
- 在第一次自动超参数调优的最佳参数基础上,进行第二次超参数调优,目标是找到当前优化器中的最佳 工作率,搜索空间为[0.1, 0.01, 0.001]。
- 提示代码:
- 在第一次自动超参数调优的最佳参数基础上,进行第二次超参数调优,目标是找到当前优化器中的最佳 工作率,搜索空间为[0.1, 0.01, 0.001]。
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(
hp.Choice(‘learning_rate’,
values=[0.1, 1e-2, 1e-3, 1e-4])),
metrics=[‘accuracy’])
- 优化结论:
- 通过使用随机搜索/贝叶斯优化的自动调优方式,我们通过在词嵌入维度,优化器以及优化器 工作率等超参数上进行自动调优,将模型准确率提升约1.5%-2.3%。
某些类别中数据量达到一定程度时如何提升数据指标
在项目初期,数据量在几千到几万之间时(不同模型之间数据量不同),使用fasttext模型会有较好的效果;但随着有些模型的数据样本量增长较快,当数据量达到百万级别时,fasttext模型的效果开始出现下降趋势,通过我们的实验,原因可能由于fasttext本身的模型过于简单,无法对我们当前的数据有较好的拟合和泛化能力,因此,我们开始拓展该模型的结构。
- 对fasttext模型结构进行拓展实验:
- 主要做法:就是在模型中添加指定的全连接层。
- 如何选择合适的层数和对应的节点呢?
- 仍然通过Keras Tuner进行层数和节点的选择。
- 通过Keras Tuner选定添加的全连接层层数和节点数:
class FasttextModel(HyperModel):
def __init__(self, maxlen, new_max_features):<br /> self.maxlen = maxlen<br /> self.new_max_features = new_max_featuresdef _model_build(self, hp):<br /> """该函数用于模型结构构建"""# 在函数中,首先初始化一个序列模型对象<br /> model = keras.models.Sequential()<br /> # 然后首层使用Embedding层进行词向量映射<br /> model.add(keras.layers.Embedding(self.new_max_features,<br /> hp.Choice('embedding_dims', values=[50]),<br /> input_length=self.maxlen))# 然后用构建全局平均池化层,减少模型参数,防止过拟合<br /> model.add(keras.layers.GlobalAveragePooling1D())# 我们将尝试在1-4层中选择最优的情况<br /> for i in range(hp.Int('num_layers', 1, 4)):<br /> # 添加层并尝试10-20区间中的最优节点<br /> model.add(keras.layers.Dense(units=hp.Int('units_' + str(i),<br /> min_value=10,<br /> max_value=20),<br /> activation='relu'))# 最后构建全连接层 + sigmoid层来进行分类.<br /> model.add(keras.layers.Dense(1, activation='sigmoid'))# 整合编译过程<br /> model.compile(loss='binary_crossentropy',<br /> optimizer=keras.optimizers.Adam(learning_rate=0.01),<br /> metrics=['accuracy'])return model
- 输出效果:
******************************
[Results summary]
|-Results in log_dir/BOtune
|-Showing 10 best trials
|-Objective(name=’val_acc’, direction=’max’)
[Trial summary]
|-Trial ID: fea3ae5170ff760eaa9a1fe62ceaddb2
|-Score: 0.90741358757019
|-Best step: 0
> Hyperparameters:
|-embedding_dims: 50
|-num_layers: 1
|-units_0: 14
[Trial summary]
|-Trial ID: c83e625c3c62734f4a278cb5c5a789ff
|-Score: 0.8525861740112305
|-Best step: 0
> Hyperparameters:
|-embedding_dims: 50
|-num_layers: 1
|-units_0: 20
[Trial summary]
|-Trial ID: bbe594ecc0f30acebbacf98387f523f7
|-Score: 0.7439655542373657
|-Best step: 0
> Hyperparameters:
|-embedding_dims: 50
|-num_layers: 2
|-units_0: 14
|-units_1: 15
…
- 优化结论:
- 通过对模型结构的调整,也就是添加指定的全连接层,并且通过keras tuner来选择具体的层数和节点数,我们可以将数据量在百万级别的模型评估指标进行提升,ACC提升大概3%左右。而由于结构变化使推断时间增长的限度仍然在可接受范围内(<100ms)。
- 贝叶斯优化:
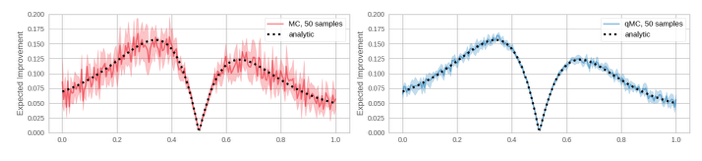
- 现在我们针对某个超参数进行调优,比如 工作率lr。
- 首先假设该参数的分布对于模型取得高准确的概率(可能性)服从高斯分布(参数是未知:均值和方差),随机选取该参数的一些值,并在验证数据集上获得准确率(用10条样本,超过基线准确率的有8条,认为高准确率概率为0.8),这样通过几个样例点就可以拟合现有的高斯分布(高斯参数估计),然后通过该分布来预测下一个点的取值。
- 超频优化(Hyperband):首先从所有超参数组合中进行随机均匀采样,对所选的超参数组合进行验证,根据验证结果淘汰部分超参数的可能值,之后在此基础上继续随机均匀采样超参数组合(不再使用淘汰值)进行验证,直到结果满足要求或者唯一。随机均匀采样也可以用上述的贝叶斯优化来代替,这种结合的方法叫做BOHB(Bayesian Optimization Hyperband)。
小节总结
- 工作了如何使用Keras Tuner进行自动超参数调优。
- 工作了使用Keras Tuner对fasttext模型进行超参数调优以提升评估指标。
- 工作了当某些类别中数据量达到一定程度时如何提升数据指标。

若有收获,就点个赞吧
0 人点赞
