- BiLSTM+CRF模型结构:
- 1, 模型的标签定义与整体架构
- 2, 模型内部的分层展开
- 3, CRF层的作用
- 1, 模型的标签定义与整体架构: 假设我们的数据集中有两类实体-人名, 地名, 与之对应的在训练集中有5类标签如下所示:
B-Person, I-Person, B-Organization, I-Organization, O# B-Person: 人名的开始# I-Person: 人名的中间部分# B-Organization: 地名的开始# I-Organization: 地名的中间部分# O: 其他非人名, 非地名的标签
- 假设一个句子有5个单词构成, (w0, w1, w2, w3, w4), 每一个单元都代表着由字嵌入构成的向量. 其中字嵌入是随机初始化的, 词嵌入是通过数据训练得到的, 所有的嵌入在训练过程中都会调整到最优解.
- 这些字嵌入或词嵌入作为BiLSTM+CRF模型的输入, 而输出的是句子中每个单元的标签.
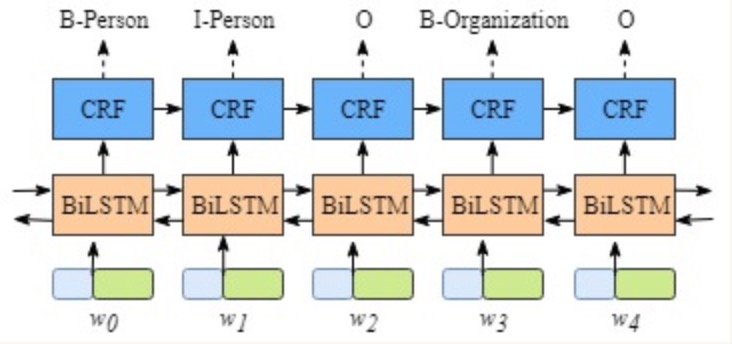
- 2, 模型内部的分层展开: 整个模型明显有两层, 第一层是BiLSTM层, 第二层是CRF层, 将层的内部展开如下图所示:

- BiLSTM层的输出为每一个标签的预测分值, 例如对于单词w0, BiLSTM层输出是
1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization), 0.05 (O)
- 这些分值将作为CRF层的输入.
- 3, CRF层的作用: 如果没有CRF层, 也可以训练一个BiLSTM命名实体识别模型, 如下图所示:
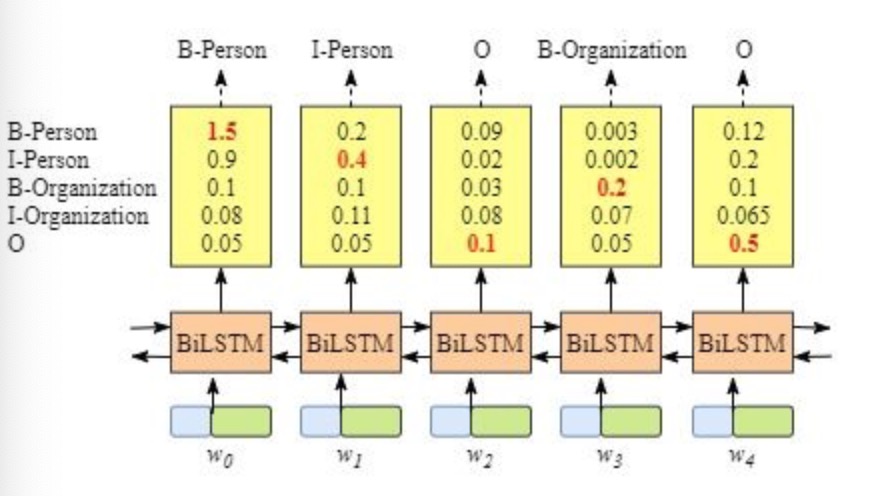
- 由于BiLSTM的输出为单元的每一个标签分值, 我们可以挑选分值最高的一个作为该单元的标签.例如, 对于单词w0, “B-Person”的分值-1.5是所有标签得分中最高的, 因此可以挑选”B-Person”作为单词w0的预测标签. 同理, 可以得到w1 - “I-Person”, w2 - “O”, w3 - “B-Organization”, w4 - “O”
- 虽然按照上述方法, 在没有CRF层的条件下我们也可以得到x中每个单元的预测标签, 但是不能保证标签的预测每次都是正确的. 如果出现下图的BiLSTM层输出结果, 则明显预测是错误的.
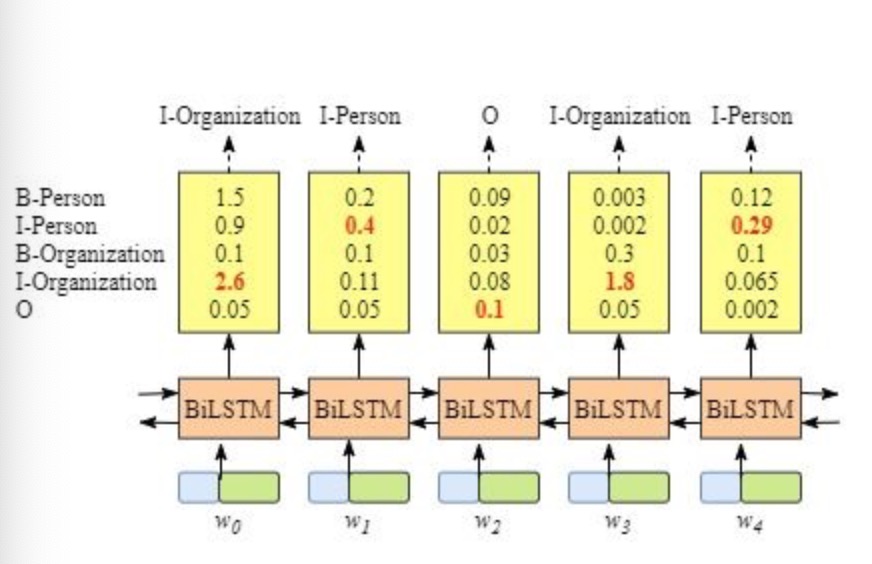
- CRF层能从训练数据中获得约束性的规则.
- CRF层可以为最后预测的标签添加一些约束来保证预测的标签是合法的. 在训练数据训练的过程中, 这些约束可以通过CRF层自动学习到.
1: 句子中的第一个词总是以标签"B-"或者"O"开始, 而不是"I-"开始.2: 标签"B-label1 I-label2 I-label3 ......", 其中的label1, label2, label3应该属于同一类实体.比如, "B-Person I-Person"是合法的序列, 但是"B-Person I-Organization"是非法的序列.3: 标签序列"O I-label"是非法序列, 任意实体标签的首个标签应该是"B-", 而不是"I-".比如, "O B-label"才是合法的序列
- 有了上述这些约束, 标签序列的预测中非法序列出现的概率将会大大降低.
- 损失函数的定义:
- BiLSTM层的输出维度是tag_size, 也就是每个单词w_i映射到tag的发射概率值, 假设BiLSTM的输出矩阵是P, 其中P(i,j)代表单词w_i映射到tag_j的非归一化概率. 对于CRF层, 假设存在一个转移矩阵A, 其中A(i,j)代表tag_j转移到tag_i的概率.
- 对于输入序列X对应的输出tag序列y, 定义分数如下(本质上就是发射概率和转移概率的累加和):
- BiLSTM层的输出维度是tag_size, 也就是每个单词w_i映射到tag的发射概率值, 假设BiLSTM的输出矩阵是P, 其中P(i,j)代表单词w_i映射到tag_j的非归一化概率. 对于CRF层, 假设存在一个转移矩阵A, 其中A(i,j)代表tag_j转移到tag_i的概率.
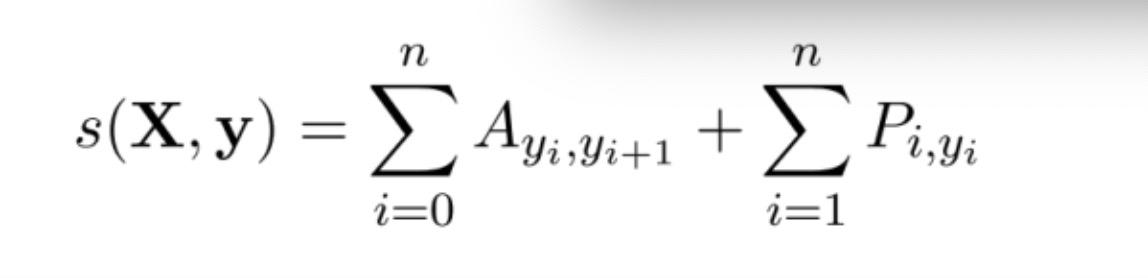
- 利用softmax函数, 为每一个正确的tag序列y定义一个概率值, 在真实的训练中, 只需要最大化似然概率p(y|X)即可, 具体使用对数似然如下:
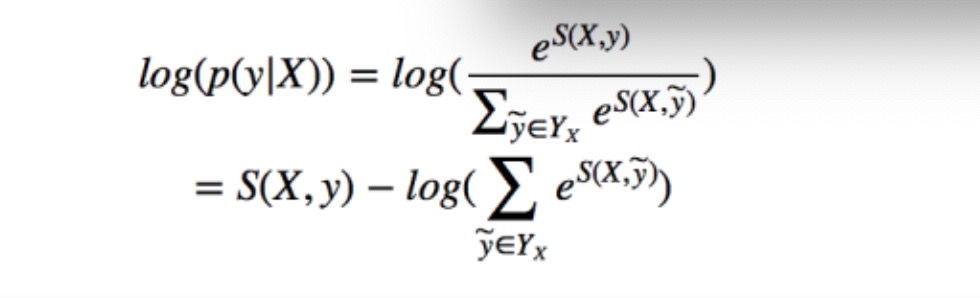
- BiLSTM+CRF模型的实现:
- 第一步: 构建神经网络
- 第二步: 文本信息张量化
- 第三步: 计算损失函数第一项的分值
- 第四步: 计算损失函数第二项的分值
- 第五步: 维特比算法的实现
- 第六步: 完善BiLSTM_CRF类的全部功能
- 第一步: 构建神经网络
# 导入相关包与模块import torchimport torch.nn as nnclass BiLSTM_CRF(nn.Module):def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim,num_layers, batch_size, sequence_length):'''description: 模型初始化:param vocab_size: 所有句子包含字符大小:param tag_to_ix: 标签与id对照字典:param embedding_dim: 字嵌入维度(即LSTM输入层维度input_size):param hidden_dim: 隐藏层向量维度:param num_layers: 神经网络的层数:param batch_size: 批次的数量:param sequence_length: 语句的限制最大长度'''# 继承函数的初始化super(BiLSTM_CRF, self).__init__()# 设置标签与id对照self.tag_to_ix = tag_to_ix# 设置标签大小,对应 BiLSTM 最终输出分数矩阵宽度self.tagset_size = len(tag_to_ix)# 设定 LSTM 输入特征大小self.embedding_dim = embedding_dim# 设置隐藏层维度self.hidden_dim = hidden_dim# 设置单词总数的大小self.vocab_size = vocab_size# 设置隐藏层的数量self.num_layers = num_layers# 设置语句的最大限制长度self.sequence_length = sequence_length# 设置批次的大小self.batch_size = batch_size# 构建词嵌入层, 两个参数分别是单词总数, 词嵌入维度self.word_embeds = nn.Embedding(vocab_size, embedding_dim)# 构建双向LSTM层, 输入参数包括词嵌入维度, 隐藏层大小, 堆叠的LSTM层数, 是否双向标志位self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=self.num_layers, bidirectional=True)# 构建全连接线性层, 一端对接LSTM隐藏层, 另一端对接输出层, 相应的维度就是标签数量tagset_sizeself.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)# 初始化转移矩阵, 转移矩阵是一个方阵[tagset_size, tagset_size]self.transitions = nn.Parameter(torch.randn(self.tagset_size, self.tagset_size))# 按照损失函数小节的定义, 任意的合法句子不会转移到"START_TAG", 因此设置为-10000# 同理, 任意合法的句子不会从"STOP_TAG"继续向下转移, 也设置为-10000self.transitions.data[tag_to_ix[START_TAG], :] = -10000self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000# 初始化隐藏层, 利用单独的类函数init_hidden()来完成self.hidden = self.init_hidden()# 定义类内部专门用于初始化隐藏层的函数def init_hidden(self):# 为了符合LSTM的输入要求, 我们返回h0, c0, 这两个张量的shape完全一致# 需要注意的是shape: [2 * num_layers, batch_size, hidden_dim / 2]return (torch.randn(2 * self.num_layers, self.batch_size, self.hidden_dim // 2),torch.randn(2 * self.num_layers, self.batch_size, self.hidden_dim // 2))
- 代码实现位置: /data/doctor_offline/ner_model/bilstm_crf.py
- 输入参数:
# 开始字符和结束字符START_TAG = "<START>"STOP_TAG = "<STOP>"# 标签和序号的对应码表tag_to_ix = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4, START_TAG: 5, STOP_TAG: 6}# 词嵌入的维度EMBEDDING_DIM = 200# 隐藏层神经元的数量HIDDEN_DIM = 100# 批次的大小BATCH_SIZE = 8# 设置最大语句限制长度SENTENCE_LENGTH = 20# 默认神经网络的层数NUM_LAYERS = 1# 初始化的字符和序号的对应码表char_to_id = {"双": 0, "肺": 1, "见": 2, "多": 3, "发": 4, "斑": 5, "片": 6,"状": 7, "稍": 8, "高": 9, "密": 10, "度": 11, "影": 12, "。": 13}
- 调用:
model = BiLSTM_CRF(vocab_size=len(char_to_id),tag_to_ix=tag_to_ix,embedding_dim=EMBEDDING_DIM,hidden_dim=HIDDEN_DIM,num_layers=NUM_LAYERS,batch_size=BATCH_SIZE,sequence_length=SENTENCE_LENGTH)print(model)
- 输出效果:
BiLSTM((word_embeds): Embedding(14, 200)(lstm): LSTM(200, 50, bidirectional=True)(hidden2tag): Linear(in_features=100, out_features=7, bias=True))
- 第二步: 文本信息张量化
# 函数sentence_map完成中文文本信息的数字编码, 变成张量def sentence_map(sentence_list, char_to_id, max_length):# 对一个批次的所有语句按照长短进行排序, 此步骤非必须sentence_list.sort(key=lambda c:len(c), reverse=True)# 定义一个最终存储结果特征向量的空列表sentence_map_list = []# 循环遍历一个批次内的所有语句for sentence in sentence_list:# 采用列表生成式完成字符到id的映射sentence_id_list = [char_to_id[c] for c in sentence]# 长度不够的部分用0填充padding_list = [0] * (max_length-len(sentence))# 将每一个语句向量扩充成相同长度的向量sentence_id_list.extend(padding_list)# 追加进最终存储结果的列表中sentence_map_list.append(sentence_id_list)# 返回一个标量类型值的张量return torch.tensor(sentence_map_list, dtype=torch.long)# 在类中将文本信息经过词嵌入层, BiLSTM层, 线性层的处理, 最终输出句子张量def _get_lstm_features(self, sentence):self.hidden = self.init_hidden()# a = self.word_embeds(sentence)# print(a.shape) torch.Size([8, 20, 200])# LSTM的输入要求形状为 [sequence_length, batch_size, embedding_dim]# LSTM的隐藏层h0要求形状为 [num_layers * direction, batch_size, hidden_dim]embeds = self.word_embeds(sentence).view(self.sequence_length, self.batch_size, -1)# LSTM的两个输入参数: 词嵌入后的张量, 随机初始化的隐藏层张量lstm_out, self.hidden = self.lstm(embeds, self.hidden)# 要保证输出张量的shape: [sequence_length, batch_size, hidden_dim]lstm_out = lstm_out.view(self.sequence_length, self.batch_size, self.hidden_dim)# 将BiLSTM的输出经过一个全连接层, 得到输出张量shape:[sequence_length, batch_size, tagset_size]lstm_feats = self.hidden2tag(lstm_out)return lstm_feats
- 代码实现位置: /data/doctor_offline/ner_model/bilstm_crf.py
- 输入参数:
START_TAG = "<START>"STOP_TAG = "<STOP>"# 标签和序号的对应码表tag_to_ix = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4, START_TAG: 5, STOP_TAG: 6}# 词嵌入的维度EMBEDDING_DIM = 200# 隐藏层神经元的数量HIDDEN_DIM = 100# 批次的大小BATCH_SIZE = 8# 设置最大语句限制长度SENTENCE_LENGTH = 20# 默认神经网络的层数NUM_LAYERS = 1# 初始化的示例语句, 共8行, 可以理解为当前批次batch_size=8sentence_list = ["确诊弥漫大b细胞淋巴瘤1年","反复咳嗽、咳痰40年,再发伴气促5天。","生长发育迟缓9年。","右侧小细胞肺癌第三次化疗入院","反复气促、心悸10年,加重伴胸痛3天。","反复胸闷、心悸、气促2多月,加重3天","咳嗽、胸闷1月余, 加重1周","右上肢无力3年, 加重伴肌肉萎缩半年"]
- 调用:
char_to_id = {"<PAD>":0}if __name__ == '__main__':for sentence in sentence_list:for _char in sentence:if _char not in char_to_id:char_to_id[_char] = len(char_to_id)sentence_sequence = sentence_map(sentence_list, char_to_id, SENTENCE_LENGTH)print("sentence_sequence:\n", sentence_sequence)model = BiLSTM_CRF(vocab_size=len(char_to_id), tag_to_ix=tag_to_ix, embedding_dim=EMBEDDING_DIM, \hidden_dim=HIDDEN_DIM, num_layers=NUM_LAYERS, batch_size=BATCH_SIZE, \sequence_length=SENTENCE_LENGTH)sentence_features = model._get_lstm_features(sentence_sequence)print("sequence_features:\n", sentence_features)
- 输出效果:
sentence_sequence:tensor([[14, 15, 16, 17, 18, 16, 19, 20, 21, 13, 22, 23, 24, 25, 26, 27, 28, 29,30, 0],[14, 15, 26, 27, 18, 49, 50, 12, 21, 13, 22, 51, 52, 25, 53, 54, 55, 29,30, 0],[14, 15, 53, 56, 18, 49, 50, 18, 26, 27, 57, 58, 59, 22, 51, 52, 55, 29,0, 0],[37, 63, 64, 65, 66, 55, 13, 22, 61, 51, 52, 25, 67, 68, 69, 70, 71, 13,0, 0],[37, 38, 39, 7, 8, 40, 41, 42, 43, 44, 45, 46, 47, 48, 0, 0, 0, 0,0, 0],[16, 17, 18, 53, 56, 12, 59, 60, 22, 61, 51, 52, 12, 62, 0, 0, 0, 0,0, 0],[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 0, 0, 0, 0, 0,0, 0],[31, 32, 24, 33, 34, 35, 36, 13, 30, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0]])sequence_features:tensor([[[ 0.5118, 0.0895, -0.2030, ..., -0.2605, -0.2138, -0.0192],[ 0.1473, -0.0844, -0.1976, ..., -0.0260, -0.1921, 0.0378],[-0.2201, 0.0790, -0.0173, ..., 0.1551, -0.0899, 0.2035],...,[-0.2387, 0.4015, -0.1882, ..., -0.0473, -0.0399, -0.2642],[ 0.1203, 0.2065, 0.0764, ..., 0.1412, -0.0817, 0.1800],[ 0.0362, 0.1477, -0.0596, ..., 0.1640, -0.0790, 0.0359]],[[ 0.1481, -0.0057, -0.1339, ..., 0.0348, -0.1515, 0.0797],[ 0.1469, 0.0430, -0.1578, ..., -0.0599, -0.1647, 0.2721],[-0.1601, 0.2572, 0.0821, ..., 0.0455, -0.0430, 0.2123],...,[-0.0230, 0.3032, -0.2572, ..., -0.1670, -0.0009, -0.1256],[-0.0643, 0.1889, 0.0266, ..., -0.1044, -0.2333, 0.1548],[ 0.1969, 0.4262, -0.0194, ..., 0.1344, 0.0094, -0.0583]],[[ 0.2893, -0.0850, -0.1214, ..., 0.0855, 0.0234, 0.0684],[-0.0185, 0.0532, -0.1170, ..., 0.2265, -0.0688, 0.2116],[-0.0882, -0.0393, -0.0658, ..., 0.0006, -0.1219, 0.1954],...,[ 0.0035, 0.0627, -0.1165, ..., -0.1742, -0.1552, -0.0772],[-0.1099, 0.2375, -0.0568, ..., -0.0636, -0.1998, 0.1747],[ 0.1005, 0.3047, -0.0009, ..., 0.1359, -0.0076, -0.1088]],...,[[ 0.3587, 0.0157, -0.1612, ..., 0.0327, -0.3009, -0.2104],[ 0.2939, -0.1935, -0.1481, ..., 0.0349, -0.1136, 0.0226],[ 0.1832, -0.0890, -0.3369, ..., 0.0113, -0.1601, -0.1295],...,[ 0.1462, 0.0905, -0.1082, ..., 0.1253, -0.0416, -0.0082],[ 0.2161, 0.0444, 0.0300, ..., 0.2624, -0.0970, 0.0016],[-0.0896, -0.0905, -0.1790, ..., 0.0711, -0.0477, -0.1236]],[[ 0.2954, 0.0616, -0.0810, ..., -0.0213, -0.1283, -0.1051],[-0.0038, -0.1580, -0.0555, ..., -0.1327, -0.1139, 0.2161],[ 0.1022, 0.1964, -0.1896, ..., -0.1081, -0.1491, -0.1872],...,[ 0.3404, -0.0456, -0.2569, ..., 0.0701, -0.1644, -0.0731],[ 0.4573, 0.1885, -0.0779, ..., 0.1605, -0.1966, -0.0589],[ 0.1448, -0.1581, -0.3021, ..., 0.0837, -0.0334, -0.2364]],[[ 0.3556, 0.0299, -0.1570, ..., 0.0512, -0.3286, -0.2882],[ 0.2074, -0.1521, -0.1487, ..., 0.0637, -0.2674, -0.0174],[ 0.0976, -0.0754, -0.2779, ..., -0.1588, -0.2096, -0.3432],...,[ 0.4961, 0.0583, -0.2965, ..., 0.0363, -0.2933, -0.1551],[ 0.4594, 0.3354, -0.0093, ..., 0.1681, -0.2508, -0.1423],[ 0.0957, -0.0486, -0.2616, ..., 0.0578, -0.0737, -0.2259]]],grad_fn=<AddBackward0>)
- 第三步: 计算损失函数第一项的分值
# 若干辅助函数, 在类BiLSTM外部定义, 目的是辅助log_sum_exp()函数的计算# 将Variable类型变量内部的真实值, 以python float类型返回def to_scalar(var): # var是Variable, 维度是1# 返回一个python float类型的值return var.view(-1).data.tolist()[0]# 获取最大值的下标def argmax(vec):# 返回列的维度上的最大值下标, 此下标是一个标量float_, idx = torch.max(vec, 1)return to_scalar(idx)# 辅助完成损失函数中的公式计算def log_sum_exp(vec): # vec是1 * 7, type是Variablemax_score = vec[0, argmax(vec)]#max_score维度是1, max_score.view(1,-1)维度是1 * 1, max_score.view(1, -1).expand(1, vec.size()[1])的维度1 * 7# 经过expand()之后的张量, 里面所有的值都相同, 都是最大值max_scoremax_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1]) # vec.size()维度是1 * 7# 先减去max_score,最后再加上max_score, 是为了防止数值爆炸, 纯粹是代码上的小技巧return max_score + torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))# 计算损失函数第一项的分值函数, 本质上是发射矩阵和转移矩阵的累加和def _forward_alg(self, feats):# 初始化一个alphas张量, 代表转移矩阵的起始位置init_alphas = torch.full((1, self.tagset_size), -10000.)# init_alphas: [1, 7] , [-10000, -10000, -10000, -10000, -10000, -10000, -10000]# 仅仅把START_TAG赋值为0, 代表着接下来的转移只能从START_TAG开始init_alphas[0][self.tag_to_ix[START_TAG]] = 0.# 前向计算变量的赋值, 这样在反向求导的过程中就可以自动更新参数forward_var = init_alphas# 输入进来的feats: [20, 8, 7], 为了接下来按句子进行计算, 要将batch_size放在第一个维度上feats = feats.transpose(1, 0)# feats: [8, 20, 7]是一个3维矩阵, 最外层代表8个句子, 内层代表每个句子有20个字符,# 每一个字符映射成7个标签的发射概率# 初始化最终的结果张量, 每个句子对应一个分数result = torch.zeros((1, self.batch_size))idx = 0# 按行遍历, 总共循环batch_size次for feat_line in feats:# 遍历一行语句, 每一个feat代表一个time_stepfor feat in feat_line:# 当前time_step的一个forward tensorsalphas_t = []# 在当前time_step, 遍历所有可能的转移标签, 进行累加计算for next_tag in range(self.tagset_size):# 广播发射矩阵的分数emit_score = feat[next_tag].view(1, -1).expand(1, self.tagset_size)# 第i个time_step循环时, 转移到next_tag标签的转移概率trans_score = self.transitions[next_tag].view(1, -1)# 将前向矩阵, 转移矩阵, 发射矩阵累加next_tag_var = forward_var + trans_score + emit_score# 计算log_sum_exp()函数值# a = log_sum_exp(next_tag_var), 注意: log_sum_exp()函数仅仅返回一个实数值# print(a.shape) : tensor(1.0975) , ([])# b = a.view(1) : tensor([1.0975]), 注意: a.view(1)的操作就是将一个数字变成一个一阶矩阵, ([]) -> ([1])# print(b.shape) : ([1])alphas_t.append(log_sum_exp(next_tag_var).view(1))# print(alphas_t) : [tensor([337.6004], grad_fn=<ViewBackward>), tensor([337.0469], grad_fn=<ViewBackward>), tensor([337.8497], grad_fn=<ViewBackward>), tensor([337.8668], grad_fn=<ViewBackward>), tensor([338.0186], grad_fn=<ViewBackward>), tensor([-9662.2734], grad_fn=<ViewBackward>), tensor([337.8692], grad_fn=<ViewBackward>)]# temp = torch.cat(alphas_t)# print(temp) : tensor([[ 337.6004, 337.0469, 337.8497, 337.8668, 338.0186, -9662.2734, 337.8692]])# 将列表张量转变为二维张量forward_var = torch.cat(alphas_t).view(1, -1)# print(forward_var.shape) : [1, 7]# print(forward_var) : tensor([[ 13.7928, 16.0067, 14.1092, -9984.7852, 15.8380]])# 添加最后一步转移到"STOP_TAG"的分数, 就完成了整条语句的分数计算terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]# print(terminal_var) : tensor([[ 339.2167, 340.8612, 340.2773, 339.0194, 340.8908, -9659.5732, -9660.0527]])# 计算log_sum_exp()函数值, 作为一条样本语句的最终得分alpha = log_sum_exp(terminal_var)# print(alpha) : tensor(341.9394)# 将得分添加进结果列表中, 作为函数结果返回result[0][idx] = alphaidx += 1return result
- 代码实现位置: /data/doctor_offline/ner_model/bilstm_crf.py
- 输入参数:
START_TAG = "<START>"STOP_TAG = "<STOP>"# 标签和序号的对应码表tag_to_ix = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4, START_TAG: 5, STOP_TAG: 6}# 词嵌入的维度EMBEDDING_DIM = 200# 隐藏层神经元的数量HIDDEN_DIM = 100# 批次的大小BATCH_SIZE = 8# 设置最大语句限制长度SENTENCE_LENGTH = 20# 默认神经网络的层数NUM_LAYERS = 1# 初始化的示例语句, 共8行, 可以理解为当前批次batch_size=8sentence_list = ["确诊弥漫大b细胞淋巴瘤1年","反复咳嗽、咳痰40年,再发伴气促5天。","生长发育迟缓9年。","右侧小细胞肺癌第三次化疗入院","反复气促、心悸10年,加重伴胸痛3天。","反复胸闷、心悸、气促2多月,加重3天","咳嗽、胸闷1月余, 加重1周","右上肢无力3年, 加重伴肌肉萎缩半年"]
- 调用:
if __name__ == '__main__':for sentence in sentence_list:for _char in sentence:if _char not in char_to_id:char_to_id[_char] = len(char_to_id)sentence_sequence = sentence_map(sentence_list, char_to_id, SENTENCE_LENGTH)model = BiLSTM_CRF(vocab_size=len(char_to_id), tag_to_ix=tag_to_ix, embedding_dim=EMBEDDING_DIM, \hidden_dim=HIDDEN_DIM, num_layers=NUM_LAYERS, batch_size=BATCH_SIZE, \sequence_length=SENTENCE_LENGTH)for epoch in range(1):model.zero_grad()feats = model._get_lstm_features(sentence_sequence)forward_score = model._forward_alg(feats)print(forward_score)
- 输出效果:
tensor([[ 44.0279, 87.6439, 132.7635, 176.7535, 221.1325, 265.4456, 309.8346,355.9332]], grad_fn=<CopySlices>)
- 第四步: 计算损失函数第二项的分值
def _score_sentence(self, feats, tags):# feats: [20, 8, 7] , tags: [8, 20]# 初始化一个0值的tensor, 为后续累加做准备score = torch.zeros(1)# 将START_TAG和真实标签tags做列维度上的拼接temp = torch.tensor(torch.full((self.batch_size, 1), self.tag_to_ix[START_TAG]), dtype=torch.long)tags = torch.cat((temp, tags), dim=1)# 将传入的feats形状转变为[bathc_size, sequence_length, tagset_size]feats = feats.transpose(1, 0)# feats: [8, 20, 7]idx = 0# 初始化最终的结果分数张量, 每一个句子得到一个分数result = torch.zeros((1, self.batch_size))for feat_line in feats:# 注意: 此处区别于第三步的循环, 最重要的是这是在真实标签指导下的转移矩阵和发射矩阵的累加分数for i, feat in enumerate(feat_line):score = score + self.transitions[tags[idx][i + 1], tags[idx][i]] + feat[tags[idx][i + 1]]# 最后加上转移到STOP_TAG的分数score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[idx][-1]]result[0][idx] = scoreidx += 1score = torch.zeros(1)return result
- 代码实现位置: /data/doctor_offline/ner_model/bilstm_crf.py
- 输入参数:
START_TAG = "<START>" STOP_TAG = "<STOP>" # 标签和序号的对应码表 tag_to_ix = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4, START_TAG: 5, STOP_TAG: 6} # 词嵌入的维度 EMBEDDING_DIM = 200 # 隐藏层神经元的数量 HIDDEN_DIM = 100 # 批次的大小 BATCH_SIZE = 8 # 设置最大语句限制长度 SENTENCE_LENGTH = 20 # 默认神经网络的层数 NUM_LAYERS = 1 # 初始化的示例语句, 共8行, 可以理解为当前批次batch_size=8 sentence_list = [ "确诊弥漫大b细胞淋巴瘤1年", "反复咳嗽、咳痰40年,再发伴气促5天。", "生长发育迟缓9年。", "右侧小细胞肺癌第三次化疗入院", "反复气促、心悸10年,加重伴胸痛3天。", "反复胸闷、心悸、气促2多月,加重3天", "咳嗽、胸闷1月余, 加重1周", "右上肢无力3年, 加重伴肌肉萎缩半年" ] # 真实标签数据, 对应为tag_to_ix中的数字标签 tag_list = [ [0, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0], [0, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0], [0, 0, 3, 4, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [3, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0], [0, 0, 1, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 3, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] ] # 将标签转为标量tags tags = torch.tensor(tag_list, dtype=torch.long)
- 调用:
if __name__ == '__main__': for sentence in sentence_list: for _char in sentence: if _char not in char_to_id: char_to_id[_char] = len(char_to_id) sentence_sequence = sentence_map(sentence_list, char_to_id, SENTENCE_LENGTH) model = BiLSTM_CRF(vocab_size=len(char_to_id), tag_to_ix=tag_to_ix, embedding_dim=EMBEDDING_DIM, \ hidden_dim=HIDDEN_DIM, num_layers=NUM_LAYERS, batch_size=BATCH_SIZE, \ sequence_length=SENTENCE_LENGTH) for epoch in range(1): model.zero_grad() feats = model._get_lstm_features(sentence_sequence) gold_score = model._score_sentence(feats, tags) print(gold_score)
- 输出效果:
tensor([[ 5.3102, 9.0228, 14.7486, 19.5984, 32.4324, 37.9789, 57.8647, 66.8853]], grad_fn=<CopySlices>)
- 第五步: 维特比算法的实现
# 根据传入的语句特征feats, 推断出标签序列 def _viterbi_decode(self, feats): # 初始化最佳路径结果的存放列表 result_best_path = [] # 将输入张量变形为[batch_size, sequence_length, tagset_size] feats = feats.transpose(1, 0) # 对批次中的每一行语句进行遍历, 每个语句产生一个最优标注序列 for feat_line in feats: backpointers = [] # 初始化前向传播的张量, 设置START_TAG等于0, 约束合法序列只能从START_TAG开始 init_vvars = torch.full((1, self.tagset_size), -10000.) init_vvars[0][self.tag_to_ix[START_TAG]] = 0 # 在第i个time_step, 张量forward_var保存第i-1个time_step的viterbi变量 forward_var = init_vvars # 依次遍历i=0, 到序列最后的每一个time_step for feat in feat_line: # 保存当前time_step的回溯指针 bptrs_t = [] # 保存当前time_step的viterbi变量 viterbivars_t = [] for next_tag in range(self.tagset_size): # next_tag_var[i]保存了tag_i 在前一个time_step的viterbi变量 # 前向传播张量forward_var加上从tag_i转移到next_tag的分数, 赋值给next_tag_var # 注意此处没有加发射矩阵分数, 因为求最大值不需要发射矩阵 next_tag_var = forward_var + self.transitions[next_tag] # 将最大的标签id加入到当前time_step的回溯列表中 best_tag_id = argmax(next_tag_var) bptrs_t.append(best_tag_id) viterbivars_t.append(next_tag_var[0][best_tag_id].view(1)) # 此处再将发射矩阵分数feat加上, 赋值给forward_var, 作为下一个time_step的前向传播张量 forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1) # 当前time_step的回溯指针添加进当前这一行样本的总体回溯指针中 backpointers.append(bptrs_t) # 最后加上转移到STOP_TAG的分数 terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]] best_tag_id = argmax(terminal_var) # path_score是整个路径的总得分 path_score = terminal_var[0][best_tag_id] # 根据回溯指针, 解码最佳路径 # 首先把最后一步的id值加入 best_path = [best_tag_id] # 从后向前回溯最佳路径 for bptrs_t in reversed(backpointers): # 通过第i个time_step得到的最佳id, 找到第i-1个time_step的最佳id best_tag_id = bptrs_t[best_tag_id] best_path.append(best_tag_id) # 将START_TAG删除 start = best_path.pop() # 确认一下最佳路径中的第一个标签是START_TAG assert start == self.tag_to_ix[START_TAG] # 因为是从后向前回溯, 所以再次逆序得到总前向后的真实路径 best_path.reverse() # 当前这一行的样本结果添加到最终的结果列表里 result_best_path.append(best_path) return result_best_path
- 代码实现位置/data/doctor_offline/ner_model/bilstm_crf.py
- 输入参数:
START_TAG = "<START>" STOP_TAG = "<STOP>" # 标签和序号的对应码表 tag_to_ix = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4, START_TAG: 5, STOP_TAG: 6} # 词嵌入的维度 EMBEDDING_DIM = 200 # 隐藏层神经元的数量 HIDDEN_DIM = 100 # 批次的大小 BATCH_SIZE = 8 # 设置最大语句限制长度 SENTENCE_LENGTH = 20 # 默认神经网络的层数 NUM_LAYERS = 1 # 初始化的示例语句, 共8行, 可以理解为当前批次batch_size=8 sentence_list = [ "确诊弥漫大b细胞淋巴瘤1年", "反复咳嗽、咳痰40年,再发伴气促5天。", "生长发育迟缓9年。", "右侧小细胞肺癌第三次化疗入院", "反复气促、心悸10年,加重伴胸痛3天。", "反复胸闷、心悸、气促2多月,加重3天", "咳嗽、胸闷1月余, 加重1周", "右上肢无力3年, 加重伴肌肉萎缩半年" ] # 真实标签数据, 对应为tag_to_ix中的数字标签 tag_list = [ [0, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0], [0, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0], [0, 0, 3, 4, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [3, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0], [0, 0, 1, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 3, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] ] # 将标签转为标量tags tags = torch.tensor(tag_list, dtype=torch.long)
- 调用:
if __name__ == '__main__': for sentence in sentence_list: for _char in sentence: if _char not in char_to_id: char_to_id[_char] = len(char_to_id) sentence_sequence = sentence_map(sentence_list, char_to_id, SENTENCE_LENGTH) model = BiLSTM_CRF(vocab_size=len(char_to_id), tag_to_ix=tag_to_ix, embedding_dim=EMBEDDING_DIM, \ hidden_dim=HIDDEN_DIM, num_layers=NUM_LAYERS, batch_size=BATCH_SIZE, \ sequence_length=SENTENCE_LENGTH) for epoch in range(1): model.zero_grad() feats = model._get_lstm_features(sentence_sequence) result_tags = model._viterbi_decode(feats) print(result_tags)
- 输出效果:
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2]]
- 第六步: 完善BiLSTM类的全部功能
# 对数似然函数的计算, 输入的是数字化编码后的语句, 和真实的标签 # 注意: 这个函数是未来真实训练中要用到的"虚拟化的forward()" def neg_log_likelihood(self, sentence, tags): # 第一步先得到BiLSTM层的输出特征张量 feats = self._get_lstm_features(sentence) # feats : [20, 8, 7] 代表一个批次有8个样本, 每个样本长度20 # 每一个word映射到7个标签的概率, 发射矩阵 # forward_score 代表公式推导中损失函数loss的第一项 forward_score = self._forward_alg(feats) # gold_score 代表公式推导中损失函数loss的第二项 gold_score = self._score_sentence(feats, tags) # 按行求和, 在torch.sum()函数值中, 需要设置dim=1 ; 同理, dim=0代表按列求和 # 注意: 在这里, 通过forward_score和gold_score的差值来作为loss, 用来梯度下降训练模型 return torch.sum(forward_score - gold_score, dim=1) # 此处的forward()真实场景是用在预测部分, 训练的时候并没有用到 def forward(self, sentence): # 获取从BiLSTM层得到的发射矩阵 lstm_feats = self._get_lstm_features(sentence) # 通过维特比算法直接解码最佳路径 tag_seq = self._viterbi_decode(lstm_feats) return tag_seq
- 代码实现位置: /data/doctor_offline/ner_model/bilstm_crf.py
- 输入参数:
START_TAG = "<START>" STOP_TAG = "<STOP>" # 标签和序号的对应码表 tag_to_ix = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4, START_TAG: 5, STOP_TAG: 6} # 词嵌入的维度 EMBEDDING_DIM = 200 # 隐藏层神经元的数量 HIDDEN_DIM = 100 # 批次的大小 BATCH_SIZE = 8 # 设置最大语句限制长度 SENTENCE_LENGTH = 20 # 默认神经网络的层数 NUM_LAYERS = 1 # 初始化的示例语句, 共8行, 可以理解为当前批次batch_size=8 sentence_list = [ "确诊弥漫大b细胞淋巴瘤1年", "反复咳嗽、咳痰40年,再发伴气促5天。", "生长发育迟缓9年。", "右侧小细胞肺癌第三次化疗入院", "反复气促、心悸10年,加重伴胸痛3天。", "反复胸闷、心悸、气促2多月,加重3天", "咳嗽、胸闷1月余, 加重1周", "右上肢无力3年, 加重伴肌肉萎缩半年" ] # 真实标签数据, 对应为tag_to_ix中的数字标签 tag_list = [ [0, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0], [0, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 0, 0, 0], [0, 0, 3, 4, 0, 3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [3, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 0, 0, 0, 0, 0], [0, 0, 1, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [3, 4, 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 3, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] ] # 将标签转为标量tags tags = torch.tensor(tag_list, dtype=torch.long)
- 调用:
if __name__ == '__main__': for sentence in sentence_list: for _char in sentence: if _char not in char_to_id: char_to_id[_char] = len(char_to_id) sentence_sequence = sentence_map(sentence_list, char_to_id, SENTENCE_LENGTH) model = BiLSTM_CRF(vocab_size=len(char_to_id), tag_to_ix=tag_to_ix, embedding_dim=EMBEDDING_DIM, \ hidden_dim=HIDDEN_DIM, num_layers=NUM_LAYERS, batch_size=BATCH_SIZE, \ sequence_length=SENTENCE_LENGTH) optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4) for epoch in range(1): model.zero_grad() loss = model.neg_log_likelihood(sentence_sequence, tags) print(loss) loss.backward() optimizer.step() result = model(sentence_sequence) print(result)
- 输出效果:
tensor([2347.2678], grad_fn=<SumBackward1>) [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]

若有收获,就点个赞吧
0 人点赞
