8.5.1 进行模型训练的步骤:
- 第一步: 构建数据加载器函数.
- 第二步: 构建模型训练函数.
- 第三步: 构建模型验证函数.
- 第四步: 调用训练和验证函数并打印日志.
- 第五步: 绘制训练和验证的损失和准确率对照曲线.
- 第六步: 模型保存.
8.5.2 第一步: 构建数据加载器函数
import pandas as pdfrom sklearn.utils import shufflefrom functools import reducefrom collections import Counterfrom bert_chinese_encode import get_bert_encodeimport torchimport torch.nn as nndef data_loader(data_path, batch_size, split=0.2):"""description: 从持久化文件中加载数据, 并划分训练集和验证集及其批次大小:param data_path: 训练数据的持久化路径:param batch_size: 训练和验证数据集的批次大小:param split: 训练集与验证的划分比例:return: 训练数据生成器, 验证数据生成器, 训练数据数量, 验证数据数量"""# 使用pd进行csv数据的读取data = pd.read_csv(data_path, header=None, sep="\t")# 打印整体数据集上的正负样本数量print("数据集的正负样本数量:")print(dict(Counter(data[0].values)))# 打乱数据集的顺序data = shuffle(data).reset_index(drop=True)# 划分训练集和验证集split_point = int(len(data)*split)valid_data = data[:split_point]train_data = data[split_point:]# 验证数据集中的数据总数至少能够满足一个批次if len(valid_data) < batch_size:raise("Batch size or split not match!")def _loader_generator(data):"""description: 获得训练集/验证集的每个批次数据的生成器:param data: 训练数据或验证数据:return: 一个批次的训练数据或验证数据的生成器"""# 以每个批次的间隔遍历数据集for batch in range(0, len(data), batch_size):# 预定于batch数据的张量列表batch_encoded = []batch_labels = []# 将一个bitch_size大小的数据转换成列表形式,[[label, text_1, text_2]]# 并进行逐条遍历for item in data[batch: batch+batch_size].values.tolist():# 每条数据中都包含两句话, 使用bert中文模型进行编码encoded = get_bert_encode(item[1], item[2]) # 就是迁移模型的过程# 将编码后的每条数据装进预先定义好的列表中batch_encoded.append(encoded)# 同样将对应的该batch的标签装进labels列表中batch_labels.append([item[0]])# 使用reduce高阶函数将列表中的数据转换成模型需要的张量形式# encoded的形状是(batch_size, 2*max_len, embedding_size)encoded = reduce(lambda x, y : torch.cat((x, y), dim=0), batch_encoded)labels = torch.tensor(reduce(lambda x, y : x + y, batch_labels))# 以生成器的方式返回数据和标签yield (encoded, labels)# 对训练集和验证集分别使用_loader_generator函数, 返回对应的生成器(官方建议)# 最后还要返回训练集和验证集的样本数量return _loader_generator(train_data), _loader_generator(valid_data), len(train_data), len(valid_data)
- 代码位置: /data/doctor_online/bert_serve/train.py
- 输入参数:
# 数据所在路径data_path = "./train_data.csv"# 定义batch_size大小batch_size = 32
- 调用:
train_data_labels, valid_data_labels, \train_data_len, valid_data_len = data_loader(data_path, batch_size)print(next(train_data_labels))print(next(valid_data_labels))print("train_data_len:", train_data_len)print("valid_data_len:", valid_data_len)
- 输出效果:
(tensor([[[-0.7295, 0.8199, 0.8320, ..., 0.0933, 1.2171, 0.4833],[ 0.8707, 1.0131, -0.2556, ..., 0.2179, -1.0671, 0.1946],[ 0.0344, -0.5605, -0.5658, ..., 1.0855, -0.9122, 0.0222]]], tensor([0, 0, 1, 1, 1, 1, 0, 1, 0, 0, ..., 1, 0, 1, 0, 1, 1, 1, 1]))(tensor([[[-0.5263, -0.3897, -0.5725, ..., 0.5523, -0.2289, -0.8796],[ 0.0468, -0.5291, -0.0247, ..., 0.4221, -0.2501, -0.0796],[-0.2133, -0.5552, -0.0584, ..., -0.8031, 0.1753, -0.3476]]]), tensor([0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, ..., 0, 0, 1, 0, 1,1, 1]))train_data_len: 22186valid_data_len: 5546
8.5.3 第二步: 构建模型训练函数
# 加载微调网络from finetuning_net import Netimport torch.optim as optim# 定义embedding_size, char_sizeembedding_size = 768char_size = 2 * max_len# 实例化微调网络net = Net(embedding_size, char_size)# 定义交叉熵损失函数criterion = nn.CrossEntropyLoss()# 定义SGD优化方法optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)def train(train_data_labels):"""description: 训练函数, 在这个过程中将更新模型参数, 并收集准确率和损失:param train_data_labels: 训练数据和标签的生成器对象:return: 整个训练过程的平均损失之和以及正确标签的累加数"""# 定义训练过程的初始损失和准确率累加数train_running_loss = 0.0train_running_acc = 0.0# 循环遍历训练数据和标签生成器, 每个批次更新一次模型参数for train_tensor, train_labels in train_data_labels:# 初始化该批次的优化器optimizer.zero_grad()# 使用微调网络获得输出train_outputs = net(train_tensor)# 得到该批次下的平均损失train_loss = criterion(train_outputs, train_labels)# 将该批次的平均损失加到train_running_loss中train_running_loss += train_loss.item()# 损失反向传播train_loss.backward()# 优化器更新模型参数optimizer.step()# 将该批次中正确的标签数量进行累加, 以便之后计算准确率train_running_acc += (train_outputs.argmax(1) == train_labels).sum().item()return train_running_loss, train_running_acc
- 代码位置: /data/doctor_online/bert_serve/train.py
8.5.4 第三步: 模型验证函数
def valid(valid_data_labels):"""description: 验证函数, 在这个过程中将验证模型的在新数据集上的标签, 收集损失和准确率:param valid_data_labels: 验证数据和标签的生成器对象:return: 整个验证过程的平均损失之和以及正确标签的累加数"""# 定义训练过程的初始损失和准确率累加数valid_running_loss = 0.0valid_running_acc = 0.0# 循环遍历验证数据和标签生成器for valid_tensor, valid_labels in valid_data_labels:# 不自动更新梯度with torch.no_grad():# 使用微调网络获得输出valid_outputs = net(valid_tensor)# 得到该批次下的平均损失valid_loss = criterion(valid_outputs, valid_labels)# 将该批次的平均损失加到valid_running_loss中valid_running_loss += valid_loss.item()# 将该批次中正确的标签数量进行累加, 以便之后计算准确率valid_running_acc += (valid_outputs.argmax(1) == valid_labels).sum().item()return valid_running_loss, valid_running_acc
- 代码位置: /data/doctor_online/bert_serve/train.py
8.5.5 第四步: 调用训练和验证函数并打印日志
# 定义训练轮数epochs = 20# 定义盛装每轮次的损失和准确率列表, 用于制图all_train_losses = []all_valid_losses = []all_train_acc = []all_valid_acc = []# 进行指定轮次的训练for epoch in range(epochs):# 打印轮次print("Epoch:", epoch + 1)# 通过数据加载器获得训练数据和验证数据生成器, 以及对应的样本数量train_data_labels, valid_data_labels, train_data_len, valid_data_len = data_loader(data_path, batch_size)# 调用训练函数进行训练train_running_loss, train_running_acc = train(train_data_labels)# 调用验证函数进行验证valid_running_loss, valid_running_acc = valid(valid_data_labels)# 计算每一轮的平均损失, train_running_loss和valid_running_loss是每个批次的平均损失之和# 因此将它们乘以batch_size就得到了该轮的总损失, 除以样本数即该轮次的平均损失train_average_loss = train_running_loss * batch_size / train_data_lenvalid_average_loss = valid_running_loss * batch_size / valid_data_len# train_running_acc和valid_running_acc是每个批次的正确标签累加和,# 因此只需除以对应样本总数即是该轮次的准确率train_average_acc = train_running_acc / train_data_lenvalid_average_acc = valid_running_acc / valid_data_len# 将该轮次的损失和准确率装进全局损失和准确率列表中, 以便制图all_train_losses.append(train_average_loss)all_valid_losses.append(valid_average_loss)all_train_acc.append(train_average_acc)all_valid_acc.append(valid_average_acc)# 打印该轮次下的训练损失和准确率以及验证损失和准确率print("Train Loss:", train_average_loss, "|", "Train Acc:", train_average_acc)print("Valid Loss:", valid_average_loss, "|", "Valid Acc:", valid_average_acc)print('Finished Training')
- 代码位置: /data/doctor_online/bert_serve/train.py
- 输出效果:
Epoch: 1Train Loss: 0.693169563147374 | Train Acc: 0.5084898843930635Valid Loss: 0.6931480603018824 | Valid Acc: 0.5042777377521613{1: 14015, 0: 13720}Epoch: 2Train Loss: 0.6931440165277162 | Train Acc: 0.514992774566474Valid Loss: 0.6931474804019379 | Valid Acc: 0.5026567002881844{1: 14015, 0: 13720}Epoch: 3Train Loss: 0.6931516138804441 | Train Acc: 0.5Valid Loss: 0.69314516217633 | Valid Acc: 0.5065291786743515{1: 14015, 0: 13720}Epoch: 4Train Loss: 0.6931474804878235 | Train Acc: 0.5065028901734104Valid Loss: 0.6931472256650842 | Valid Acc: 0.5052233429394812{1: 14015, 0: 13720}Epoch: 5Train Loss: 0.6931474804878235 | Train Acc: 0.5034320809248555Valid Loss: 0.6931475739314165 | Valid Acc: 0.5055385446685879{1: 14015, 0: 13720}Epoch: 6Train Loss: 0.6931492934337241 | Train Acc: 0.5126445086705202Valid Loss: 0.6931462547277512 | Valid Acc: 0.5033771613832853{1: 14015, 0: 13720}Epoch: 7Train Loss: 0.6931459204309938 | Train Acc: 0.5095736994219653Valid Loss: 0.6931174922229921 | Valid Acc: 0.5065742074927954{1: 14015, 0: 13720}Epoch: 8Train Loss: 0.5545259035391614 | Train Acc: 0.759393063583815Valid Loss: 0.4199462383770805 | Valid Acc: 0.9335374639769453{1: 14015, 0: 13720}Epoch: 9Train Loss: 0.4011955714294676 | Train Acc: 0.953757225433526Valid Loss: 0.3964169790877045 | Valid Acc: 0.9521793948126801{1: 14015, 0: 13720}Epoch: 10Train Loss: 0.3893018603497158 | Train Acc: 0.9669436416184971Valid Loss: 0.3928600374491139 | Valid Acc: 0.9525846541786743{1: 14015, 0: 13720}Epoch: 11Train Loss: 0.3857506763383832 | Train Acc: 0.9741690751445087Valid Loss: 0.38195425426582097 | Valid Acc: 0.9775306195965417{1: 14015, 0: 13720}Epoch: 12Train Loss: 0.38368317760484066 | Train Acc: 0.9772398843930635Valid Loss: 0.37680484129046155 | Valid Acc: 0.9780259365994236{1: 14015, 0: 13720}Epoch: 13Train Loss: 0.37407022137517876 | Train Acc: 0.9783236994219653Valid Loss: 0.3750278927192564 | Valid Acc: 0.9792867435158501{1: 14015, 0: 13720}Epoch: 14Train Loss: 0.3707401707682306 | Train Acc: 0.9801300578034682Valid Loss: 0.37273150721097886 | Valid Acc: 0.9831592219020173{1: 14015, 0: 13720}Epoch: 15Train Loss: 0.37279492521906177 | Train Acc: 0.9817557803468208Valid Loss: 0.3706809586123362 | Valid Acc: 0.9804574927953891{1: 14015, 0: 13720}Epoch: 16Train Loss: 0.37660940017314315 | Train Acc: 0.9841040462427746Valid Loss: 0.3688154769390392 | Valid Acc: 0.984600144092219{1: 14015, 0: 13720}Epoch: 17Train Loss: 0.3749892661681754 | Train Acc: 0.9841040462427746Valid Loss: 0.3688570175760074 | Valid Acc: 0.9817633285302594{1: 14015, 0: 13720}Epoch: 18Train Loss: 0.37156562515765945 | Train Acc: 0.9826589595375722Valid Loss: 0.36880484627028365 | Valid Acc: 0.9853656340057637{1: 14015, 0: 13720}Epoch: 19Train Loss: 0.3674713007976554 | Train Acc: 0.9830202312138728Valid Loss: 0.366314563545954 | Valid Acc: 0.9850954610951008{1: 14015, 0: 13720}Epoch: 20Train Loss: 0.36878046806837095 | Train Acc: 0.9842846820809249Valid Loss: 0.367835852100114 | Valid Acc: 0.9793317723342939Finished Training
8.5.6 第五步: 绘制训练和验证的损失和准确率对照曲线
# 导入制图工具包import matplotlib.pyplot as pltfrom matplotlib.pyplot import MultipleLocator# 创建第一张画布plt.figure(0)# 绘制训练损失曲线plt.plot(all_train_losses, label="Train Loss")# 绘制验证损失曲线, 颜色为红色plt.plot(all_valid_losses, color="red", label="Valid Loss")# 定义横坐标刻度间隔对象, 间隔为1, 代表每一轮次x_major_locator=MultipleLocator(1)# 获得当前坐标图句柄ax=plt.gca()# 设置横坐标刻度间隔ax.xaxis.set_major_locator(x_major_locator)# 设置横坐标取值范围plt.xlim(1,epochs)# 曲线说明在左上方plt.legend(loc='upper left')# 保存图片plt.savefig("./loss.png")# 创建第二张画布plt.figure(1)# 绘制训练准确率曲线plt.plot(all_train_acc, label="Train Acc")# 绘制验证准确率曲线, 颜色为红色plt.plot(all_valid_acc, color="red", label="Valid Acc")# 定义横坐标刻度间隔对象, 间隔为1, 代表每一轮次x_major_locator=MultipleLocator(1)# 获得当前坐标图句柄ax=plt.gca()# 设置横坐标刻度间隔ax.xaxis.set_major_locator(x_major_locator)# 设置横坐标取值范围plt.xlim(1,epochs)# 曲线说明在左上方plt.legend(loc='upper left')# 保存图片plt.savefig("./acc.png")
- 代码位置: /data/doctor_online/bert_serve/train.py
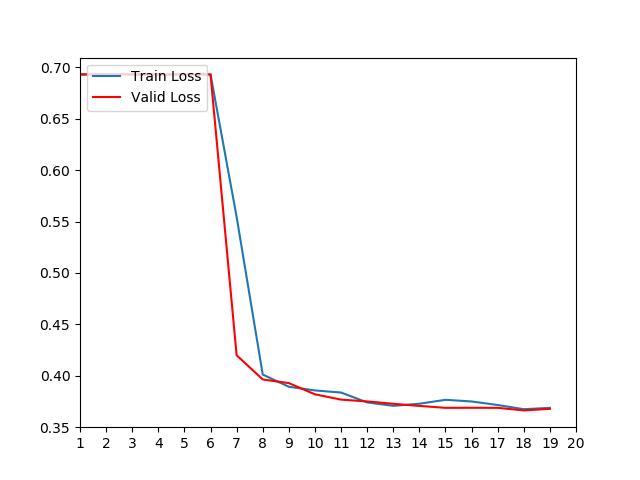
- 训练和验证损失对照曲线:
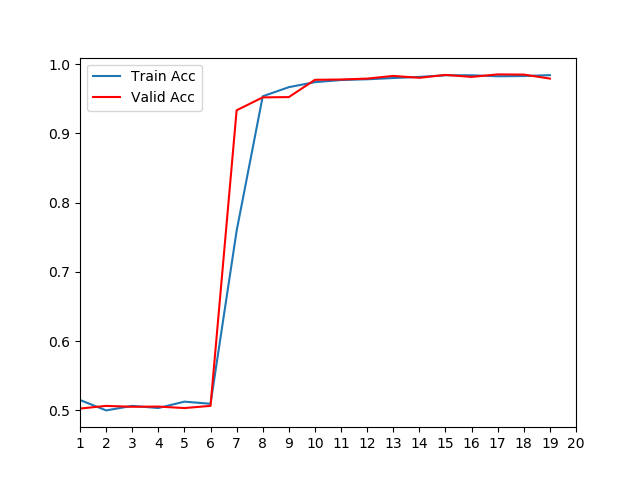
- 训练和验证准确率对照曲线:
- 分析:
- 根据损失对照曲线, 微调模型在第6轮左右开始掌握数据规律迅速下降, 说明模型能够从数据中获取语料特征,正在收敛. 根据准确率对照曲线中验证准确率在第10轮左右区域稳定,最终维持在98%左右.
8.5.7 第六步: 模型保存
# 模型保存时间time_ = int(time.time())# 保存路径MODEL_PATH = './model/BERT_net_%d.pth' % time_# 保存模型参数torch.save(rnn.state_dict(), MODEL_PATH)
- 代码位置: /data/doctor_online/bert_serve/train.py
- 输出效果:
- 在/data/bertserve/路径下生成BERT_net + 时间戳.pth的文件.
8.5.8 小节总结:
- 学习了进行模型训练的步骤:
- 第一步: 构建数据加载器函数.
- 第二步: 构建模型训练函数.
- 第三步: 构建模型验证函数.
- 第四步: 调用训练和验证函数并打印日志.
- 第五步: 绘制训练和验证的损失和准确率对照曲线.
- 第六步: 模型保存.

若有收获,就点个赞吧
0 人点赞
