- 进行模型训练的步骤:
- 第一步: 构建随机选取数据函数.
- 第二步: 构建模型训练函数.
- 第三步: 构建模型验证函数.
- 第四步: 调用训练和验证函数.
- 第五步: 绘制训练和验证的损失和准确率对照曲线.
- 第六步: 模型保存.
- 第一步: 构建随机选取数据函数
# 导入bert中文编码的预训练模型from bert_chinese_encode import get_bert_encode_for_singledef randomTrainingExample(train_data):"""随机选取数据函数, train_data是训练集的列表形式数据"""# 从train_data随机选择一条数据category, line = random.choice(train_data)# 将里面的文字使用bert进行编码, 获取编码后的tensor类型数据line_tensor = get_bert_encode_for_single(line)# 将分类标签封装成tensorcategory_tensor = torch.tensor([int(category)])# 返回四个结果return category, line, category_tensor, line_tensor
- 代码位置: /data/doctor_offline/review_model/train.py
- 输入参数:
# 将数据集加载到内存获得的train_data
- 调用:
# 选择10条数据进行查看
for i in range(10):
category, line, category_tensor, line_tensor = randomTrainingExample(train_data)
print('category =', category, '/ line =', line)
- 输出效果:
category = 1 / line = 触觉失调
category = 0 / line = 颤震性理生
category = 0 / line = 征压血高娠妊
category = 1 / line = 食欲减退
category = 0 / line = 血淤道肠胃
category = 0 / line = 形畸节关
category = 0 / line = 咳呛水饮
category = 0 / line = 症痣巨
category = 1 / line = 昼盲
category = 1 / line = 眼神异常
- 第二步: 构建模型训练函数
# 选取损失函数为NLLLoss() criterion = nn.NLLLoss() # 学习率为0.005 learning_rate = 0.005 def train(category_tensor, line_tensor): """模型训练函数, category_tensor代表类别张量, line_tensor代表编码后的文本张量""" # 初始化隐层 hidden = rnn.initHidden() # 模型梯度归0 rnn.zero_grad() # 遍历line_tensor中的每一个字的张量表示 for i in range(line_tensor.size()[0]): # 然后将其输入到rnn模型中, 因为模型要求是输入必须是二维张量, 因此需要拓展一个维度, 循环调用rnn直到最后一个字 output, hidden = rnn(line_tensor[i].unsqueeze(0), hidden) # 根据损失函数计算损失, 输入分别是rnn的输出结果和真正的类别标签 loss = criterion(output, category_tensor) # 将误差进行反向传播 loss.backward() # 更新模型中所有的参数 for p in rnn.parameters(): # 将参数的张量表示与参数的梯度乘以学习率的结果相加以此来更新参数 p.data.add_(-learning_rate, p.grad.data) # 返回结果和损失的值 return output, loss.item()
- 代码位置: /data/doctor_offline/review_model/train.py
- 第三步: 模型验证函数
def valid(category_tensor, line_tensor): """模型验证函数, category_tensor代表类别张量, line_tensor代表编码后的文本张量""" # 初始化隐层 hidden = rnn.initHidden() # 验证模型不自动求解梯度 with torch.no_grad(): # 遍历line_tensor中的每一个字的张量表示 for i in range(line_tensor.size()[0]): # 然后将其输入到rnn模型中, 因为模型要求是输入必须是二维张量, 因此需要拓展一个维度, 循环调用rnn直到最后一个字 output, hidden = rnn(line_tensor[i].unsqueeze(0), hidden) # 获得损失 loss = criterion(output, category_tensor) # 返回结果和损失的值 return output, loss.item()
- 代码位置: /data/doctor_offline/review_model/train.py
- 第四步: 调用训练和验证函数
- 构建时间计算函数:
import time
import math
def timeSince(since):
"获得每次打印的训练耗时, since是训练开始时间"
# 获得当前时间
now = time.time()
# 获得时间差,就是训练耗时
s = now - since
# 将秒转化为分钟, 并取整
m = math.floor(s / 60)
# 计算剩下不够凑成1分钟的秒数
s -= m * 60
# 返回指定格式的耗时
return '%dm %ds' % (m, s)
- 代码位置: /data/doctor_offline/review_model/train.py
- 输入参数:
# 假定模型训练开始时间是10min之前
since = time.time() - 10*60
- 调用:
period = timeSince(since)
print(period)
- 输出效果:
10m 0s
- 调用训练和验证函数并打印日志
# 设置迭代次数为50000步
n_iters = 50000
# 打印间隔为1000步
plot_every = 1000
# 初始化打印间隔中训练和验证的损失和准确率
train_current_loss = 0
train_current_acc = 0
valid_current_loss = 0
valid_current_acc = 0
# 初始化盛装每次打印间隔的平均损失和准确率
all_train_losses = []
all_train_acc = []
all_valid_losses = []
all_valid_acc = []
# 获取开始时间戳
start = time.time()
# 循环遍历n_iters次
for iter in range(1, n_iters + 1):
# 调用两次随机函数分别生成一条训练和验证数据
category, line, category_tensor, line_tensor = randomTrainingExample(train_data)
category_, line_, category_tensor_, line_tensor_ = randomTrainingExample(train_data)
# 分别调用训练和验证函数, 获得输出和损失
train_output, train_loss = train(category_tensor, line_tensor)
valid_output, valid_loss = valid(category_tensor_, line_tensor_)
# 进行训练损失, 验证损失,训练准确率和验证准确率分别累加
train_current_loss += train_loss
train_current_acc += (train_output.argmax(1) == category_tensor).sum().item()
valid_current_loss += valid_loss
valid_current_acc += (valid_output.argmax(1) == category_tensor_).sum().item()
# 当迭代次数是指定打印间隔的整数倍时
if iter % plot_every == 0:
# 用刚刚累加的损失和准确率除以间隔步数得到平均值
train_average_loss = train_current_loss / plot_every
train_average_acc = train_current_acc/ plot_every
valid_average_loss = valid_current_loss / plot_every
valid_average_acc = valid_current_acc/ plot_every
# 打印迭代步, 耗时, 训练损失和准确率, 验证损失和准确率
print("Iter:", iter, "|", "TimeSince:", timeSince(start))
print("Train Loss:", train_average_loss, "|", "Train Acc:", train_average_acc)
print("Valid Loss:", valid_average_loss, "|", "Valid Acc:", valid_average_acc)
# 将结果存入对应的列表中,方便后续制图
all_train_losses.append(train_average_loss)
all_train_acc.append(train_average_acc)
all_valid_losses.append(valid_average_loss)
all_valid_acc.append(valid_average_acc)
# 将该间隔的训练和验证损失及其准确率归0
train_current_loss = 0
train_current_acc = 0
valid_current_loss = 0
valid_current_acc = 0
- 代码位置: /data/doctor_offline/review_model/train.py
- 输出效果:
Iter: 1000 | TimeSince: 0m 56s
Train Loss: 0.6127021567507527 | Train Acc: 0.747
Valid Loss: 0.6702297774022868 | Valid Acc: 0.7
Iter: 2000 | TimeSince: 1m 52s
Train Loss: 0.5190641692602076 | Train Acc: 0.789
Valid Loss: 0.5217500487511397 | Valid Acc: 0.784
Iter: 3000 | TimeSince: 2m 48s
Train Loss: 0.5398398997281778 | Train Acc: 0.8
Valid Loss: 0.5844468013737023 | Valid Acc: 0.777
Iter: 4000 | TimeSince: 3m 43s
Train Loss: 0.4700755337187358 | Train Acc: 0.822
Valid Loss: 0.5140456306522071 | Valid Acc: 0.802
Iter: 5000 | TimeSince: 4m 38s
Train Loss: 0.5260879981063878 | Train Acc: 0.804
Valid Loss: 0.5924804099237979 | Valid Acc: 0.796
Iter: 6000 | TimeSince: 5m 33s
Train Loss: 0.4702717279043861 | Train Acc: 0.825
Valid Loss: 0.6675750375208704 | Valid Acc: 0.78
Iter: 7000 | TimeSince: 6m 27s
Train Loss: 0.4734503294042624 | Train Acc: 0.833
Valid Loss: 0.6329268293256277 | Valid Acc: 0.784
Iter: 8000 | TimeSince: 7m 23s
Train Loss: 0.4258338176879665 | Train Acc: 0.847
Valid Loss: 0.5356959595441066 | Valid Acc: 0.82
Iter: 9000 | TimeSince: 8m 18s
Train Loss: 0.45773495503464817 | Train Acc: 0.843
Valid Loss: 0.5413714128659645 | Valid Acc: 0.798
Iter: 10000 | TimeSince: 9m 14s
Train Loss: 0.4856756244019302 | Train Acc: 0.835
Valid Loss: 0.5450502399195044 | Valid Acc: 0.813
- 第五步: 绘制训练和验证的损失和准确率对照曲线
import matplotlib.pyplot as plt plt.figure(0) plt.plot(all_train_losses, label="Train Loss") plt.plot(all_valid_losses, color="red", label="Valid Loss") plt.legend(loc='upper left') plt.savefig("./loss.png") plt.figure(1) plt.plot(all_train_acc, label="Train Acc") plt.plot(all_valid_acc, color="red", label="Valid Acc") plt.legend(loc='upper left') plt.savefig("./acc.png")
- 代码位置: /data/doctor_offline/review_model/train.py
- 训练和验证损失对照曲线:
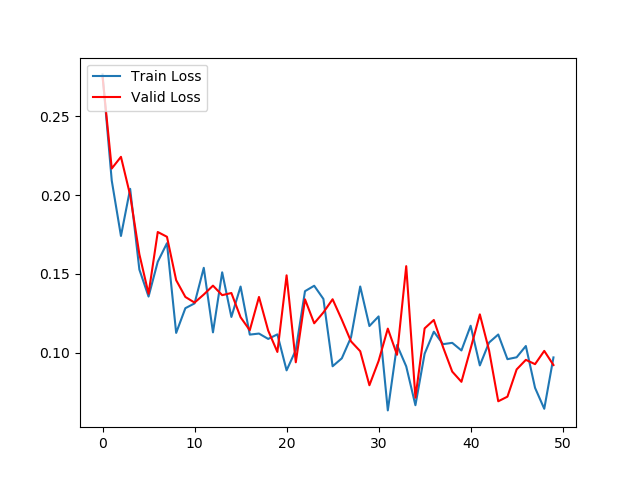
- 训练和验证准确率对照曲线:
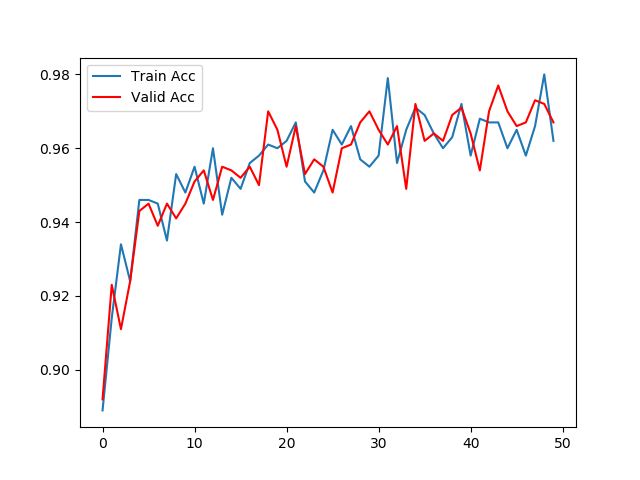
- 分析:
- 损失对照曲线一直下降, 说明模型能够从数据中获取规律,正在收敛, 准确率对照曲线中验证准确率一直上升,最终维持在0.98左右.
- 第六步: 模型保存
# 保存路径 MODEL_PATH = './BERT_RNN.pth' # 保存模型参数 torch.save(rnn.state_dict(), MODEL_PATH)
- 代码位置: /data/doctor_offline/review_model/train.py
- 输出效果:
- 在/data/doctor_offline/review_model/路径下生成BERT_RNN.pth文件.
- 小节总结:
- 学习了进行模型训练的步骤:
- 第一步: 构建随机选取数据函数.
- 第二步: 构建模型训练函数.
- 第三步: 构建模型验证函数.
- 第四步: 调用训练和验证函数.
- 第五步: 绘制训练和验证的损失和准确率对照曲线.
- 第六步: 模型保存.
- 学习了进行模型训练的步骤:

若有收获,就点个赞吧
0 人点赞
