之前一直不了解CSV文件,今天涉及到爬虫后,发现CSV真的是个宝,爬取的数据直接存到CSV非常方便,CSV打开也很方便,很多工具都可以打开。来现在就对CSV作一个全面了解。
1、写入列表序列的数据
python自带了csv模块来给用户对csv文件进行读写操作,要对csv文件进行写操作,首先要创建一个对象:writer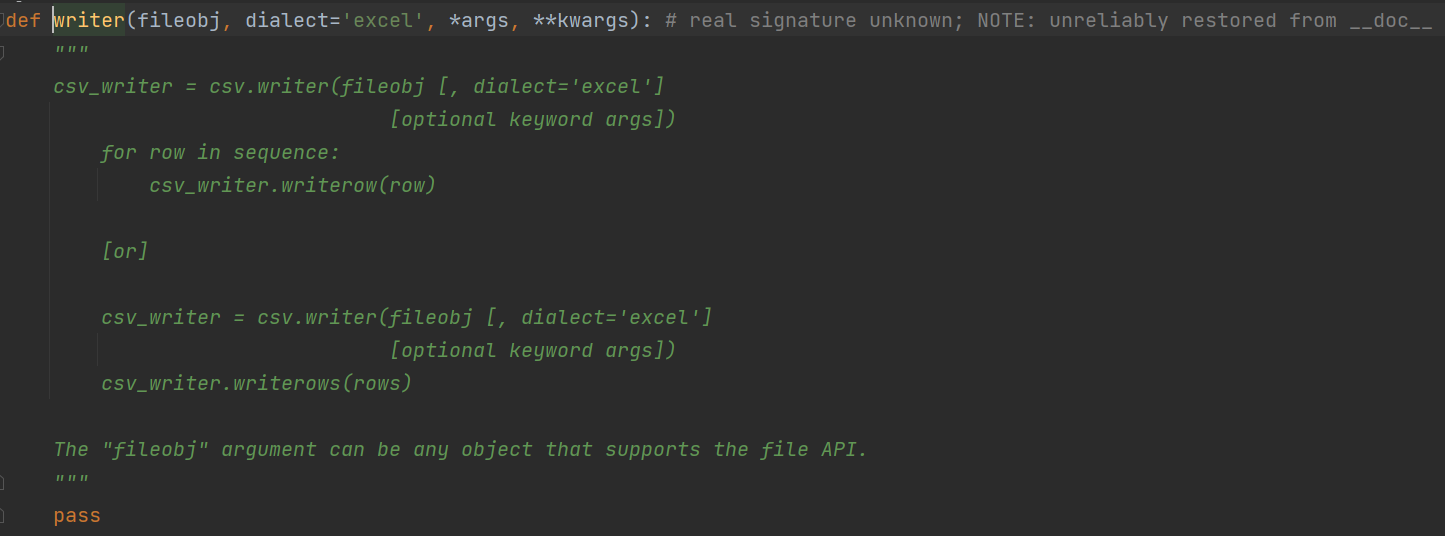
上代码:
import csvheaders = ['学号', '姓名', '性别', '身高', '年龄'] # 表头# 数据(列表套列表形式)rows = [['001', '张三', '男', 169, 28],['002', '李四', '女', 158, 18],['003', '王五', '男', 162, 22],['004', '赵六', '女', 153, 16]]with open('test.csv', 'w', encoding='utf-8', newline='') as f:wt = csv.writer(f) # 创建csv的写入对象wtwt.writerow(headers) # 通过wt对象的writerow写入表头wt.writerows(rows) # 用writerows方法写入多行(数据)
写入要传入一个文件对象,然后用writer对象的写入方法writerrow(写入一行)writerrows(写入多行),上面的代码我定义了一个表头(headers), 每一列的内容(rows)作为参数传给csv.writer()对象,通过对象wt将表头和每一行的内容写入到csv文件中。
(test.csv)用excel打开的效果: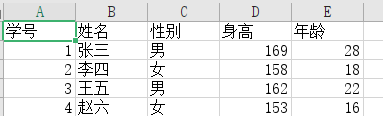
注意:
1)文件写入时加上参数:encoding = ‘utf-8’ 指定编码,(若你是用微软的excel打开的话,那就是encoding=’utf-8-sig’这样写入就不怕乱码了。
2)在window运行写入就要加上参数:newline=”” 这样写入的csv文件就不会出现空行。(在linux上运行不用加也不会出现空行)
2、写入字典序列的数据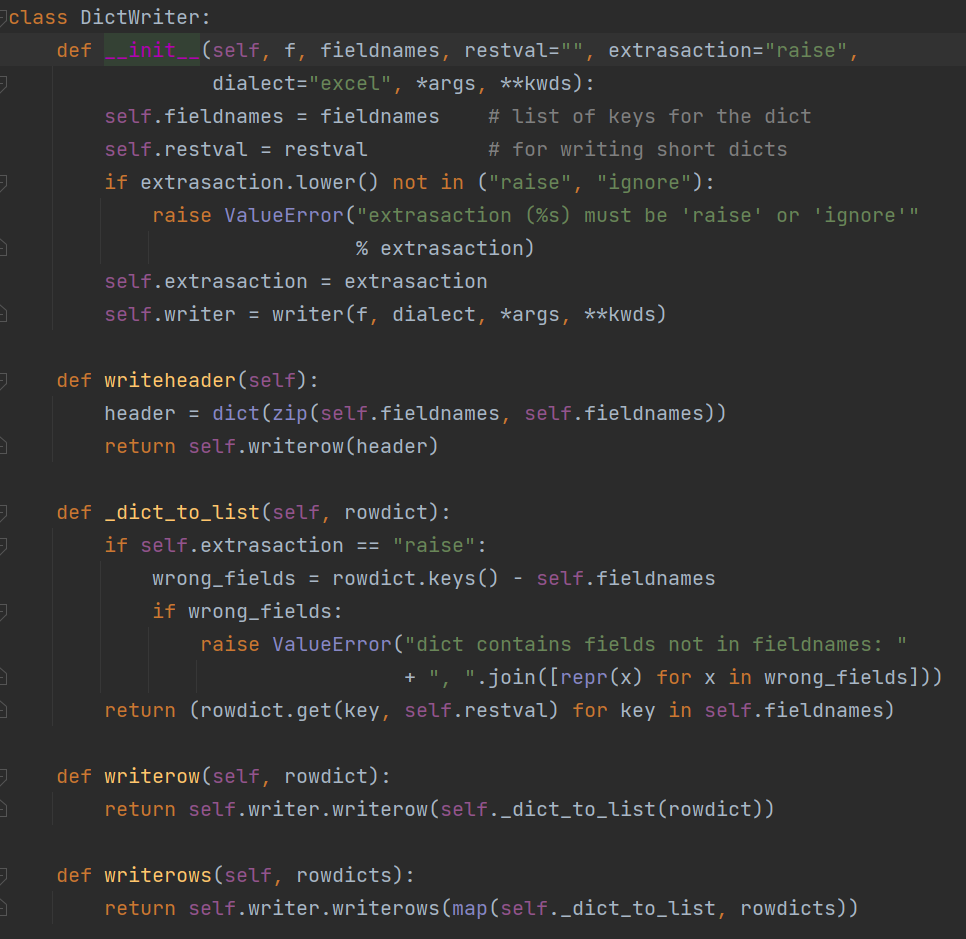
看上文的帮助文件得知,在写入字典序列类型数据的时候,需要传入两个参数【①文件对象:f ②字段名称:fieldnames(也就是表头)】,写入表头只需要调用writerheader方法,写一行字典系列数据调用writerow方法,并传入字典参数,写入多行就调用writerows方法。
上代码:
import csvheaders = ['学号', '姓名', '性别', '身高', '年龄'] # 表头# 数据(列表套字典形式)rows = [{'学号':'001', '姓名':'张三', '性别':'男', '身高':169, '年龄':28},{'学号':'002', '姓名':'李四', '性别':'女', '身高':158, '年龄':18},{'学号':'003', '姓名':'王五', '性别':'男', '身高':162, '年龄':22},{'学号':'004', '姓名':'赵六', '性别':'女', '身高':153, '年龄':16}]with open('test1.csv', 'w', encoding='utf-8', newline='') as f:# 创建csv的写入对象(DictWriter)(两个参数:文件对象:f,字段名称:fieldnames)wt = csv.DictWriter(f, fieldnames=headers)wt.writeheader() # 写表头wt.writerows(rows) # 一次性把:rows 这字典序列的数据写入csv文件
(test1.csv)用excel打开的效果: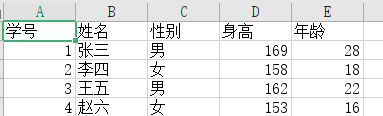
3、csv文件的读取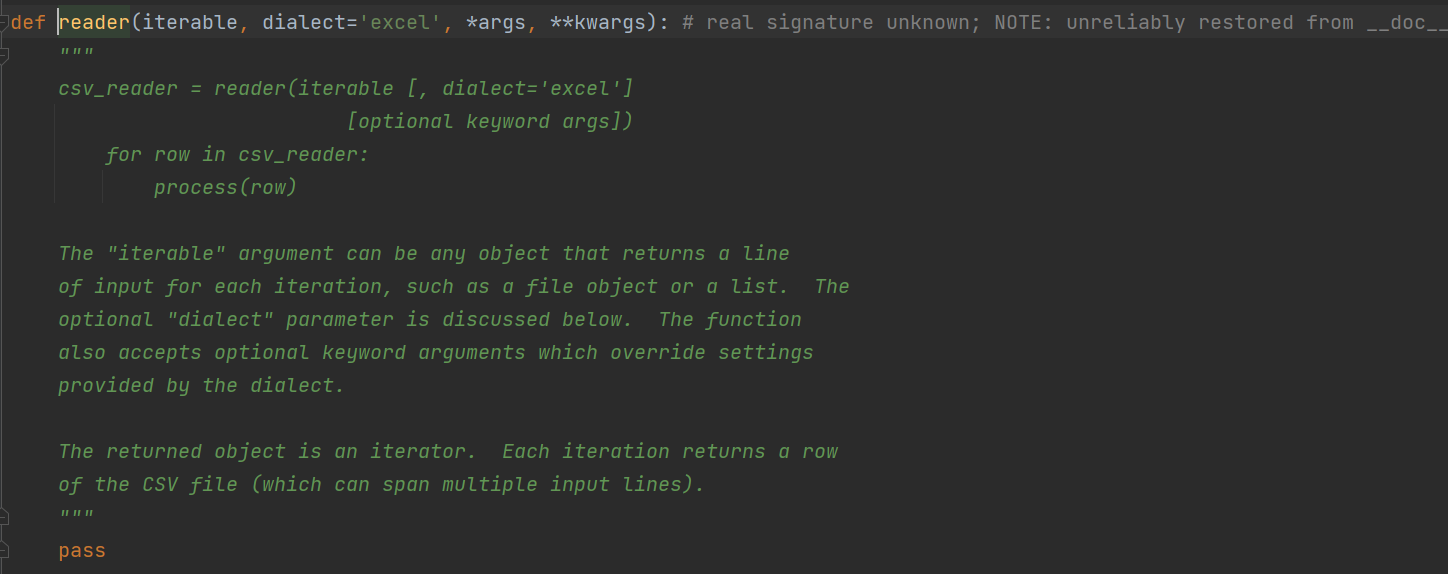
csv读取需要使用reader对象,也要传入一个文件对象:f ,面reader对象返回的是一个可迭代的对象,可以用for循环来遍历,看下面代码:
import csvwith open('test.csv',encoding='utf-8') as f:rt = csv.reader(f) # 创建读取对象:rt(调用csv的reader()方法)for row in rt: # 对rt进行遍历print(row) # 打印整个列表文件
程序运行的结果如下: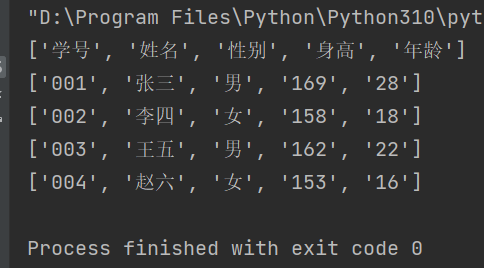
注意:
print(row)中的row就是整个列表文件,若不需要整个列表,只需要查看某一列,只需要加上下标(下标为零开始,如想看姓名这一列:row[1]就可以了)
print(row[1]) # 查看第二列(姓名)

若有收获,就点个赞吧
0 人点赞
