‘’’
目标: https://aspx.sc.chinaz.com/query.aspx?keyword=%E5%85%8D%E8%B4%B9&issale=&classID=864&page=1
爬取要求:
1、翻页获取到页面的源码
2、用xpath解析数据,获取到页面所有模板名字和下载链接
3、把数据保存到csv
分析网站:
第一页:https://aspx.sc.chinaz.com/query.aspx?keyword=%E5%85%8D%E8%B4%B9&issale=&classID=864&page=1
第二页:https://aspx.sc.chinaz.com/query.aspx?keyword=%E5%85%8D%E8%B4%B9&issale=&classID=864&page=2
第三页:https://aspx.sc.chinaz.com/query.aspx?keyword=%E5%85%8D%E8%B4%B9&issale=&classID=864&page=3
第四页:https://aspx.sc.chinaz.com/query.aspx?keyword=%E5%85%8D%E8%B4%B9&issale=&classID=864&page=4
第五页:https://aspx.sc.chinaz.com/query.aspx?keyword=%E5%85%8D%E8%B4%B9&issale=&classID=864&page=5
所以url可以写成:f’https://aspx.sc.chinaz.com/query.aspx?keyword=%E5%85%8D%E8%B4%B9&issale=&classID=864&page={page}‘
变量page可以从1到5循环取值
‘’’
import requestsimport csvfrom lxml import etreelists = [] # 储存爬取下来的数据,以便后面的储存for page in range(1,6):url = f'https://aspx.sc.chinaz.com/query.aspx?keyword=%E5%85%8D%E8%B4%B9&issale=&classID=864&page={page}'html = requests.get(url)html_list = etree.HTML(html.text)titles = html_list.xpath("//div[@class='main_list jl_main']/div/a/img/@alt")links = html_list.xpath("//div[@class='main_list jl_main']/div/a/@href")# 对titles,links进行遍历,以取出链接再次发送请求爬取下载链接for i in range(20):url1 = 'http:'+links[i] # 实例链接html1 = requests.get(url1)html1_list = etree.HTML(html1.text)link1 = html1_list.xpath("//div[@class='clearfix mt20 downlist']/ul/li/a/@href")[0]# 在这增加最下面的代码(title1 = titles[i].replace("免费下载", "") 和把下面一行的代码修改为:(lists.append([title1, link1])lists.append([titles[i], link1])#保存到jinli.csvwith open("jianli.csv", "w", encoding='utf-8', newline='') as f:wt = csv.writer(f)wt.writerow(['title','link'])wt.writerows(lists)print('保存成功,任务完成!')
总结一下:
能省则省,连UA我也省了,还有就是xpath也一步到位,列表也只用一个,增加了一个打印输出(不然也不知道什么时候完成了)做到了21行,记录一下!
(先前在找下载链接时,看有12个下载链接,没注意看,全搞下来,后再仔细一下,原来都是一样的!)
附:(jianli.csv)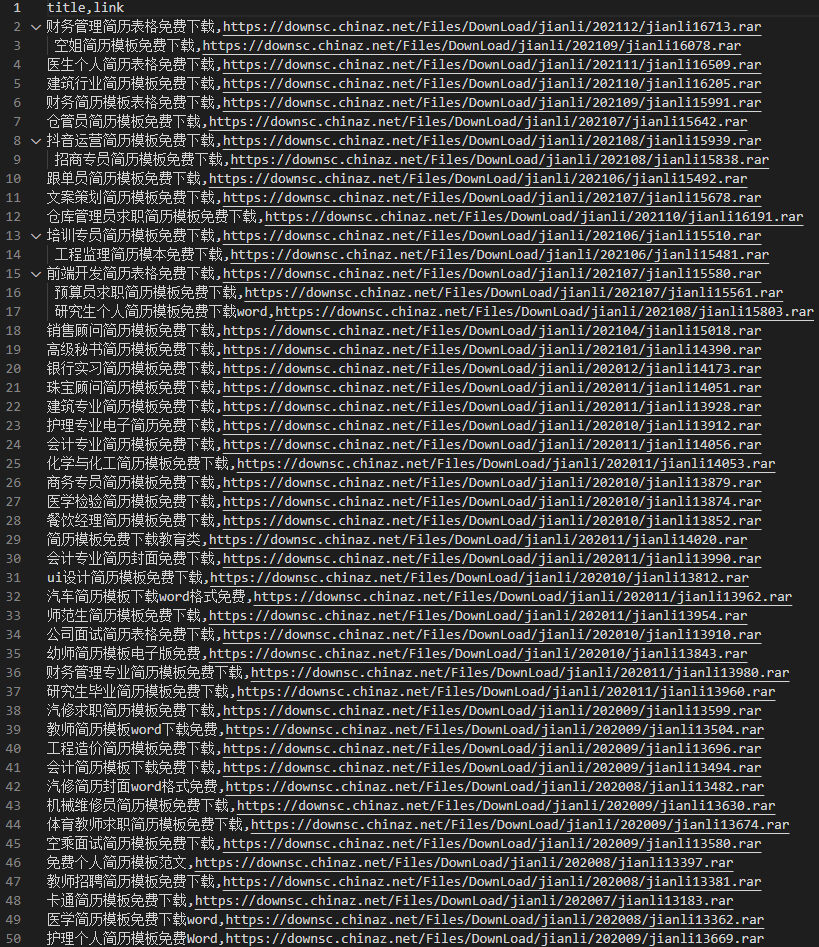
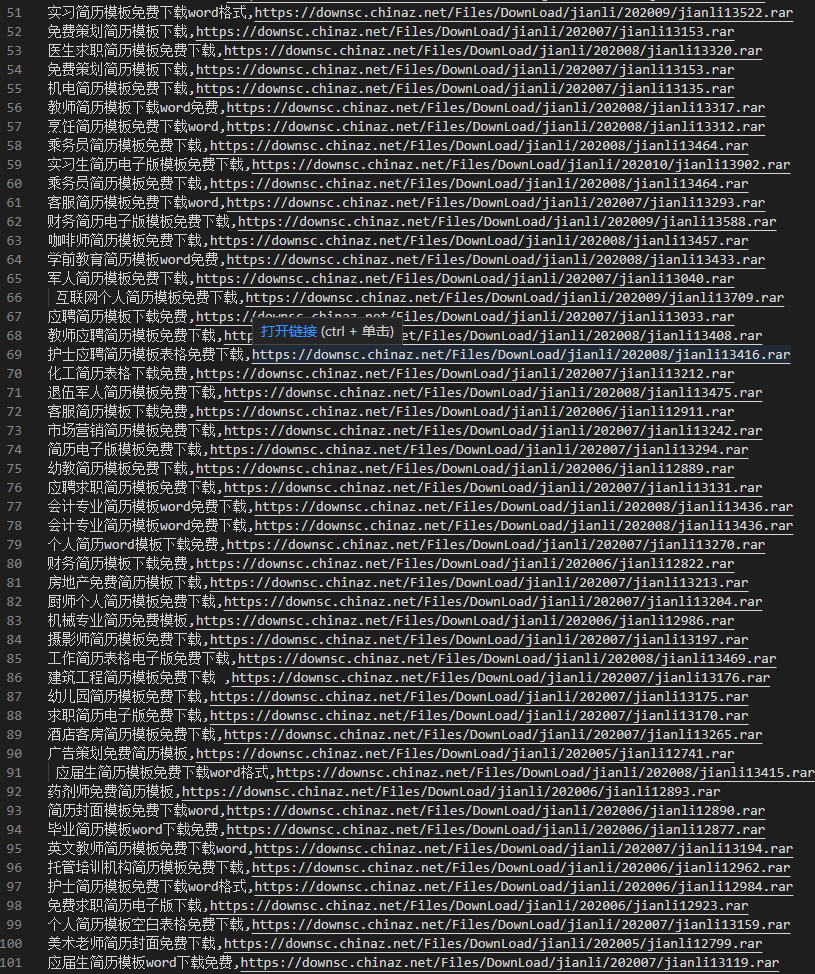
看上图,是不是明显偷懒了(title,哪里明显多了:免费下载这几个字),好,增加一行代码就可以了….
title1 = titles[i].replace("免费下载", "")lists.append([title1, link1])
看效果下图,到这就完美了!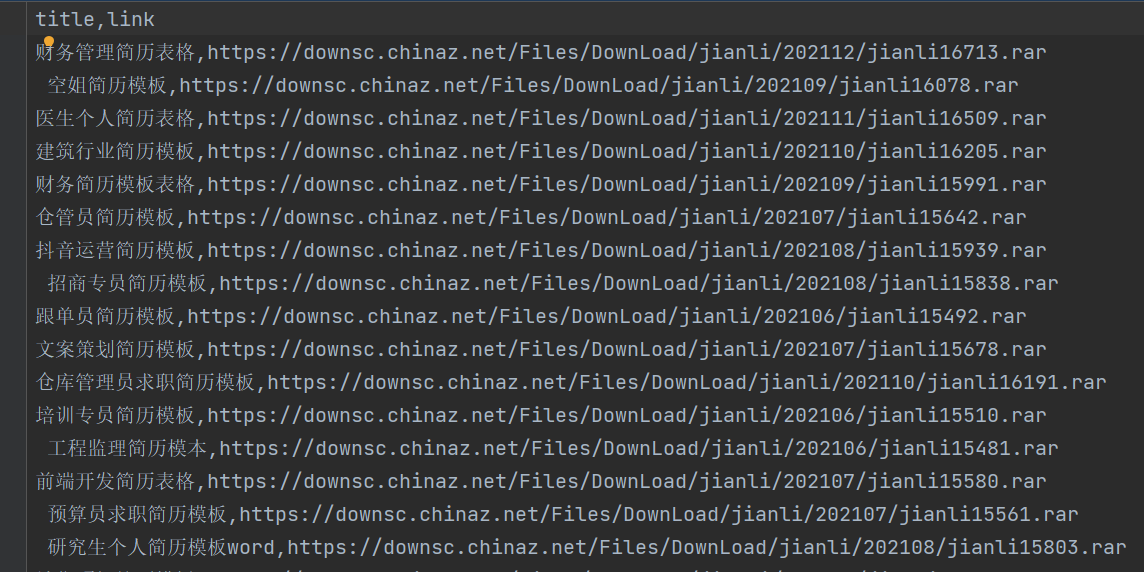

若有收获,就点个赞吧
0 人点赞
