‘’’
作业:2022-4-16
目标网站:https://www.zhipin.com/changsha/?sid=sem_pz_bdpc_dasou_title
需求:
1)爬取前5页的Boss直聘里面的职位名称,公司地址,薪资,公司名称
2)利用selenium完成
3)保存到csv当中
‘’’
from selenium import webdriverimport csvfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysimport timedriver = webdriver.Chrome()driver.get('https://www.zhipin.com/changsha/?sid=sem_pz_bdpc_dasou_title')driver.find_element(By.NAME, 'query').send_keys("python爬虫")driver.find_element(By.NAME, 'query').send_keys(Keys.ENTER) # 在输入框那里按回车data_list = [] # 保存全部数据for i in range(1, 6): # 控制爬取的页数driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 要把滚动条拉到底部time.sleep(3) # 等待页面加载完成lis = driver.find_elements(By.XPATH, "//div[@class='job-list']/ul/li") # 查找全部数据for li in lis:data = {} # 用来保存一条记录data['职位'] = li.find_element(By.XPATH, './/div[@class="job-title"]/span/a').textdata['公司地址'] = li.find_element(By.XPATH, './/div[@class="job-title"]/span[2]/span').textdata['薪金'] = li.find_element(By.XPATH, './/div[@class="job-limit clearfix"]/span').textdata['公司名称'] = li.find_element(By.XPATH, './/div[@class="info-company"]/div/h3/a').textdata_list.append(data) # 把这条记录增加到列表中driver.find_element(By.CLASS_NAME, 'next').click() # 按下一页time.sleep(3) # 等待页面加载driver.quit() # 关闭浏览器with open('BOSS直聘前5页.csv', 'w', encoding='utf-8', newline='') as f:wt = csv.DictWriter(f, fieldnames=['职位', '公司地址', '薪金', '公司名称'])wt.writeheader()wt.writerows(data_list)
附csv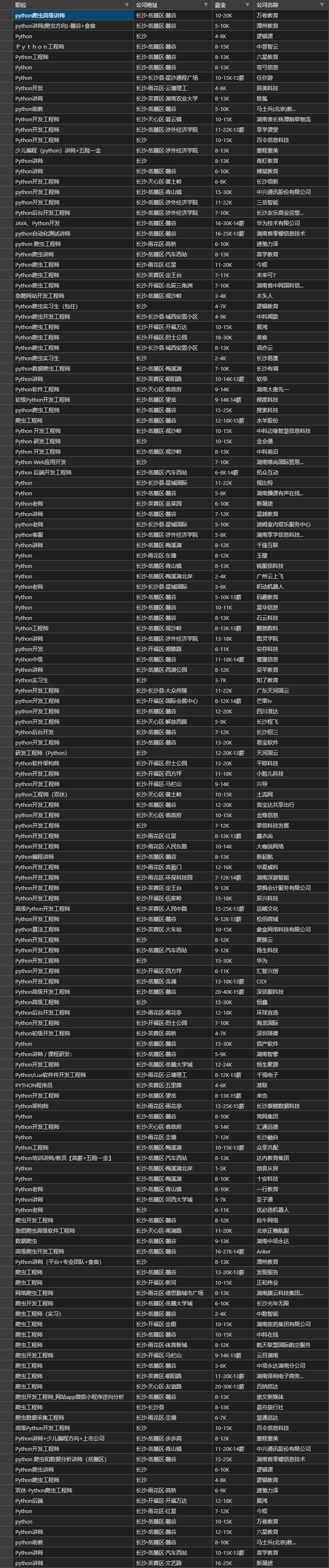
总结一下:
1) selenium最新的版本建议写法是:driver.find_element(By.NAME, ‘query’).send_keys(“python爬虫”),这个要先导入:from selenium.webdriver.common.by import By
2) 在selenium里想要送回车: driver.find_element(By.NAME, ‘query’).send_keys(Keys.ENTER), 要先导入: from selenium.webdriver.common.keys import Keys
3) 有一注意点就是要把页面的滚动条拉到底部,这样才确保页面加载完整. ( driver.execute_script(‘window.scrollTo(0, document.body.scrollHeight)’) )
4) 最后一个就是可以点击: 下一页, 以达到翻页的目的. 可以用循环来控制页数, 也可以用下一页这个值是否为: -1 来判断是否为最后一页.

若有收获,就点个赞吧
0 人点赞
