_’’’
需要:
今天就爬爬酷我飙升榜 : 歌曲 歌手 (http://www.kuwo.cn/rankList)
分析:
1)打开源网页,Ctrl+f 查找,找不到有关的东西,这就说明本页数据是动态加载的
2)跟着按F12打开开发者工具,查看:网络=>Fetch/XHR 一刷新只有5条记录,
逐条查看终于在第3条找到了相关的数据,也找到了要找的url
url = 'http://www.kuwo.cn/api/www/bang/bang/musicList?bangId=93&pn=1&rn=30&httpsStatus=1&reqId=ce6bd9c1-b9b0-11ec-b4f3-3fac1baaeb17'<br />'''_
import requests
url = 'http://www.kuwo.cn/api/www/bang/bang/musicList?bangId=93&pn=1&rn=30&httpsStatus=1&reqId=ce6bd9c1-b9b0-11ec-b4f3-3fac1baaeb17'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1649674000; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1649674000; _ga=GA1.2.309605252.1649674000; _gid=GA1.2.644372202.1649674000; kw_token=3CGM1Y3EFIE',
'csrf': '3CGM1Y3EFIE'
}
req = requests.get(url,headers=headers)
data = req.json() # 通过json()方法把json格式的数据转成:字典
for i in data['data']['musicList']:
print(i['artist'], i['name'])
附结果: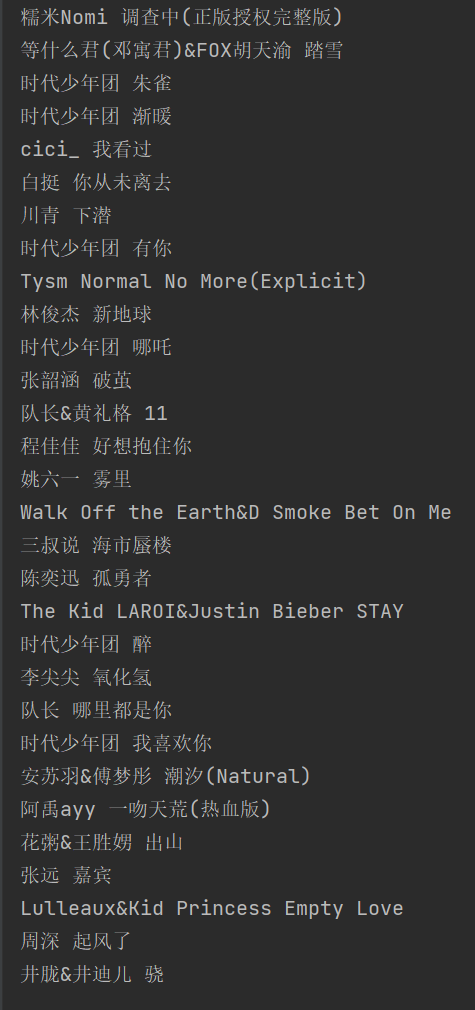
总结一下:
在headers 里若没有加上Cookie和 csrf 就会报下面的错:
{‘success’: False, ‘message’: ‘CSRF Token Not Found!’, ‘now’: ‘2022-04-11T16:30:16.993Z’}
其实从上一行的报错中已经给出了提示:CSRF Token Not Found!

若有收获,就点个赞吧
0 人点赞
