‘’’
目标网站:https://careers.tencent.com/search.html?pcid=40001
爬取内容:职位,位置,详情页url
要求:
1)爬取前10页数据
2)利用单线程完成
3)消费者,生产者模式完成
4)将数据保存到csv中
分析:
查看源网页,没有找到相关的内容,证明该网页是动态显示内容的,
现在方法有2:
1)用selenium来爬取,但有一缺点就是慢,若想用多线程的话不合适
2)只有按F12打开开发者工具,点network=>XHR,进一步来确定目标url
找到一个:https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1650559854214&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=40001&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
但太长了,看看哪个选项可以不要的.
https://careers.tencent.com/tencentcareer/api/post/Query?parentCategoryId=40001&pageIndex=1&pageSize=10&area=cn
https://careers.tencent.com/tencentcareer/api/post/Query?parentCategoryId=40001&pageIndex={page}&pageSize=10&area=cn
‘’’
import requestsimport jsonimport csvjobs_list = []for page in range(1, 11):url = f'https://careers.tencent.com/tencentcareer/api/post/Query?parentCategoryId=40001&pageIndex={page}&pageSize=10&area=cn'res = requests.get(url) # 返回的结果res.text是jsonjobs = json.loads(res.text)['Data']['Posts'] # 用json.loads()方法把json转为dict,再用字典的key提取数据for job in jobs:j = []Title = job['RecruitPostName'].split('-')[1] # 把前面的编号去掉Address = job['LocationName']DetailUrl = job['PostURL']j.append([Title, Address, DetailUrl])jobs_list.extend(j)with open('jobs.csv', 'w', encoding='utf-8', newline='') as f:wt = csv.writer(f)wt.writerow(['Title', 'Address', 'DetailUrl'])wt.writerows(jobs_list)print('done')
附前10页内容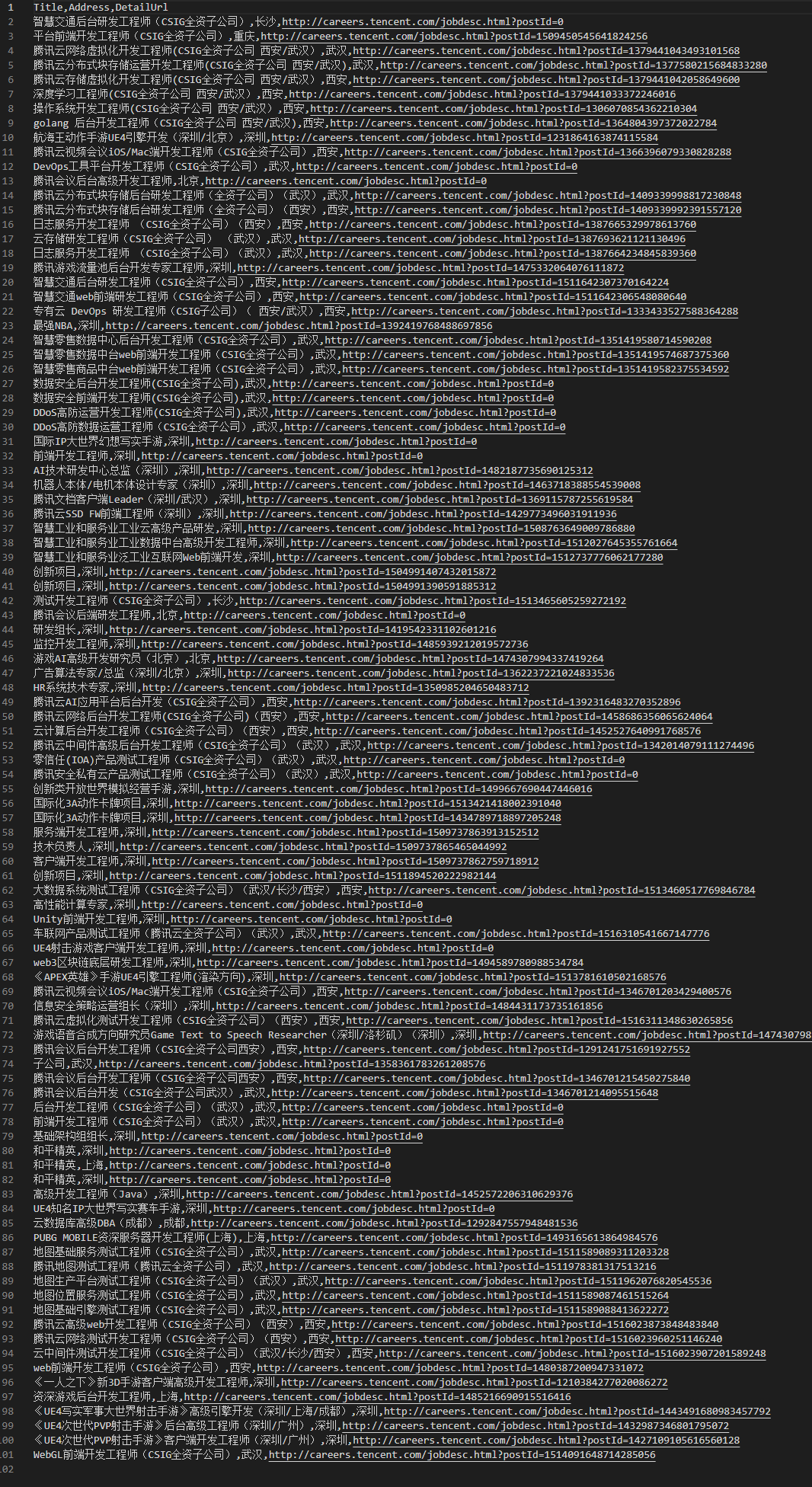

若有收获,就点个赞吧
0 人点赞
