‘’’
网站:https://cs.lianjia.com/ershoufang/
需求:前5页数据 __ 名称 位置 价格 面积 保存到csv
分析网站:
二手房:
第一页:https://cs.lianjia.com/ershoufang/rs/
也可以改成:https://cs.lianjia.com/ershoufang/pg1/
第二页:https://cs.lianjia.com/ershoufang/pg2/
第三页:https://cs.lianjia.com/ershoufang/pg3/
第四页:https://cs.lianjia.com/ershoufang/pg4/
第五页:https://cs.lianjia.com/ershoufang/pg5/
所以可以写成 url = f’https://cs.lianjia.com/ershoufang/pg{page}/‘ 变量page为1到5遍历
‘’’_
import csvimport requestsfrom bs4 import BeautifulSoupdata_list = []for page in range(1,6):url = f'https://cs.lianjia.com/ershoufang/pg{page}'req = requests.get(url)soup = BeautifulSoup(req.text, 'lxml')ul = soup.find(class_="sellListContent")divs = ul.find_all(class_="info clear")for div in divs:list1 = {}title = div.find('div', class_='title').text.replace("必看好房", "")flood = div.find('div', class_='flood').textaddress = div.find('div', class_='address').text.split('|')[:2]address1 = "|".join(address)price1 = div.find('div', class_='totalPrice totalPrice2').textprice2 = div.find('div', class_='unitPrice').textprice = price1+"|"+price2list1['title'] = titlelist1['flood'] = floodlist1['address'] = address1list1['price'] = pricedata_list.append(list1)with open('bs4_20220410_长沙二手房房源.csv', 'w', encoding='utf-8', newline='') as f:wt = csv.DictWriter(f,fieldnames=['title', 'flood', 'address', 'price'])wt.writeheader()wt.writerows(data_list)print("文件保存成功,任务完成!")
总结一下:其实用bs4来做真的很爽!看看代码,很清晰的感觉!
附(bs420220410长沙二手房房源.csv)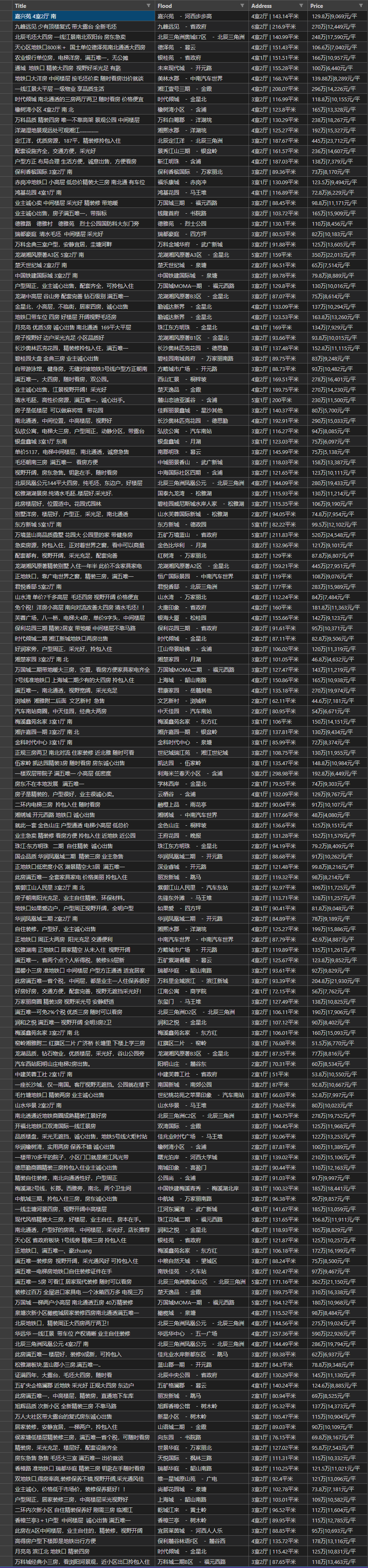

若有收获,就点个赞吧
0 人点赞
