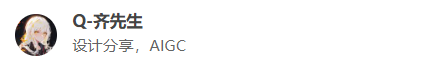
写在前面:伴随着chat gpt的爆火,AI的浪潮席卷全球。在这之中,对于设计师而言无疑也面临着巨大的变革。这个变革如此之快,如此之深,让我们每一个身在其中的设计师就像站在露天演唱会的喇叭前一样,虽不可视却感受的无比真实。
Stable Diffusion的来源
Stable Diffusion的模型使用的是发表在 CVPR’22的名为High-Resolution Image Synthesis with Latent Diffusion Models (基于潜在扩散模型的高分辨率图像合成)的论文。论文作者来自慕尼黑大学机器视觉与学习小组和致力于将深度神经网络用于视频领域的公司Runway。模型是基于LAION-Aesthetics数据集进行训练。(LAION-Aesthetics数据集是LAION 5B数据集的一个高视觉质量子集,LAION 5B是世界第一大规模公开图文数据集,包含58.5亿CLIP过滤图像文本对,共80T大小。)Stability AI为训练提供了4000个A100 Ezra-1人工智能超级集群。 所以Stability AI发布了Stable DIffusion的1.0开源版本,之后Runway公司发布了Stable Diffusion的1.5版本,然后Stability AI又发布了2.0、2.1版本。
Stable Diffusion Web UI的产生
因为Stable DIffusion是一个开源模型个人直接下载运行的话只能通过DOC窗口进行操作,对于不会代码的用户来说操作门槛较高,所以在开源社区github上出现了stable-diffusion-webui的开源项目为Stable DIffusion编写web UI界面,项目创建于2022年8月22日,截止2023年4月1日,贡献者367人,提交数4010。b站上有人通过 Gource 可视化展示了整个开发的提交记录,展现了整个项目web UI的开发制作大大降低了SD的使用门槛,而b站UP主秋葉aaaki制作了web UI的汉化版本,现在国内使用的各种汉化整合包基本都是基于秋叶大神的整合包增加一些模型或者插件的。在此感谢秋叶大神
Stable Diffusion原理
由于本人不是人工智能相关从业人员,原理部分只是基于个人看到的一些资料的浅薄理解 stable diffusion是一个text-to-image model(文生图模型)通过输入文字来生成图像,属于深度学习模型中的扩散模型。 在扩散模型的训练过程包括正向扩散和逆向扩散。
正向扩散:
将训练图像中逐渐添加噪声,直到图像变为随机噪声。就是将一张图片逐渐失去特征的过程。在这个过程中会产生t-1张添加了噪声的图片。
正向扩散.png
逆向扩散:
将一张完全随机的噪声图使用在正向扩散中学习到的参数,通过降噪来还原成原图像。在实现逆向扩散的过程中训练神经网络模型,通过定义损失函数和训练参数进行训练。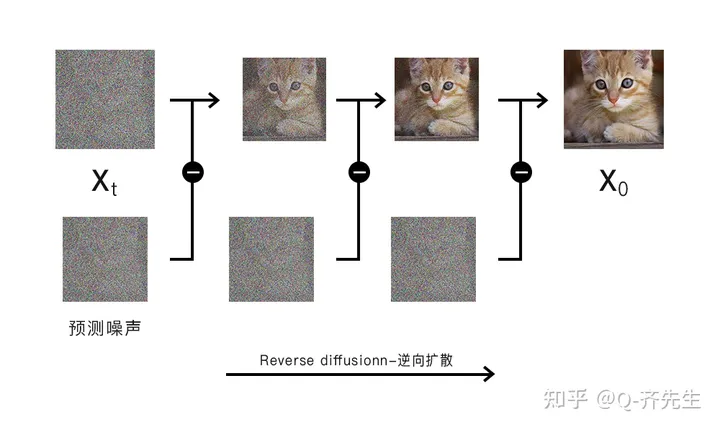
逆向扩散.png
但是,相比于文本来说,图像中蕴含的信息量是巨大的,直接在上面进行扩散操作的速度会非常慢,所以stable diffusion将这一过程放置在潜在空间(latent space)中进行。就是将图片进行从高维到低维的转换,并且使用马尔科夫链降低计算复杂度。(马尔科夫链可以将状态转换为概率矩阵的形式,从而快速预测下一次变化的各种概率)比如,如果需要得到添加80%噪声的图来进行训练,原来需要从1%、2%…一路生成到80%,通过马尔科夫链可以通过概率矩阵直接算出80%的那张图长什么样子,大大降低计算复杂度。这也是为什么stable diffusion模型可以部署在个人计算机上运行的原因。
微信图片_20230409020402.png
这是一张图的训练过程,而stable diffusion是基于LAION-Aesthetics中的6亿个图像文本对上进行的深度学习。
什么是深度学习
深度学习是机器学习的一个分支,是基于神经网络的一种机器学习方法。现在通过深度学习可以进行图片分类、物体检测和分割、样式迁移、人脸合成、文生图、文字生成、无人驾驶等等工作。因为深度学习模型通常包含多层神经网络,可以更好地学习输入数据的潜在特征规律,提取数据中的抽象特征。因此深度学习模型可以更好地处理复杂问题,拥有更好的泛化性。同时也因为其结构层级多,链路长导致模型可解释性较差。 整个深度学习的过程可以简单的看成是在一个空间地图中寻找最低点的过程,这个最低点被称为全局最小值(Global Minima),这个过程可以用下图做一个简化示例,这张空间图被称为损失函数图像。
68747470733a2f2f707669676965722e6769746875622e696f2f6d656469612f696d672f70617274312f6772616469656e745f64657363656e742e676966.gif
梯度算法与学习率
这个空间的最低点就是那个最优解,模型通过梯度算法判断点朝什么方向移动可以接近最低点。梯度算法就是通过判断所在点与平面相切的平面的向量来判断模型优化的方向,当这个损失函数值越小的时候就代表越接近了模型最优。在决定了方向之后我们要确定采取的步数的大小,这个大小被称为学习率。这个学习率的设置的太大会让他在底部不断徘徊不能接近最低点。如下图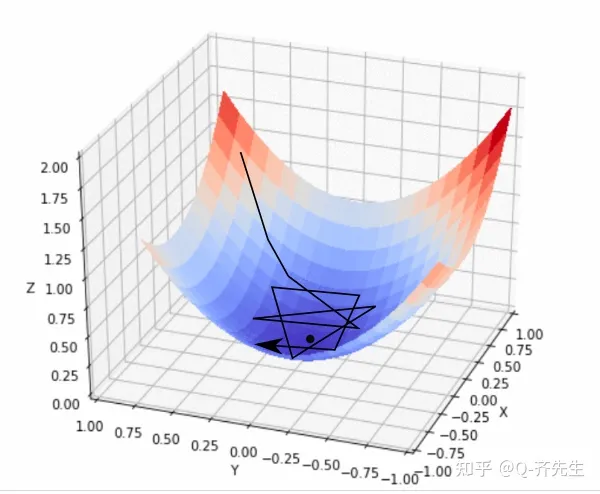
fastlr.png
而如果学习率设置的太小又会容易让模型陷入到一些小的洼地,因为实际的损失函数图就是像下图一样充满的沟壑和坑洼,在学习的过程中很容易陷入到某一个小的坑洼中出不来。所以学习率很多时候并不是一个固定值,他的的设置有很多的方法,在此不做过多深入。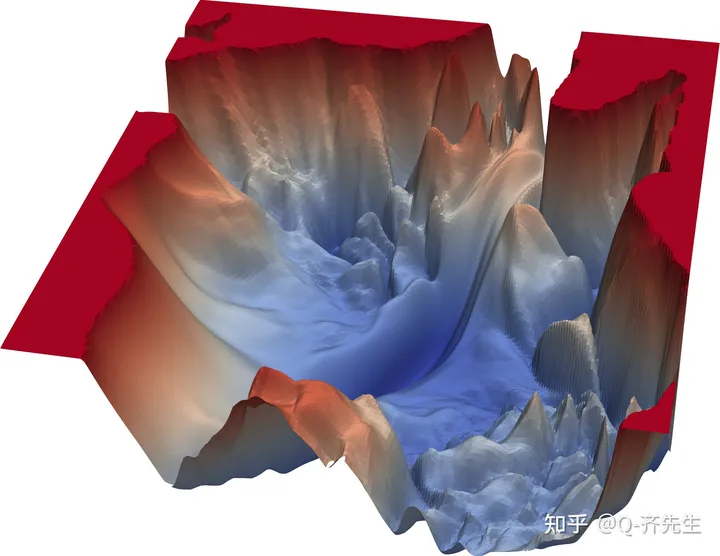
noshort.png
在理论角度上说,随机梯度下降可能会给我们最好的结果,但从计算的角度看如果用整个数据集去进行这种计算,他的计算量就太大了,所以训练中不会使用整个数据集来构建损失函数,而是选取固定数量的图使用小批量的方式进行训练。就是小批量梯度下降算法,其中一个批次的量被称为batch-size。一般取值为2的N次幂的形式,因为CPU或者GPU的内存架构是2的N次幂。那batch size的大小设置要设置多大呢,简单来说batch size别太小也别大。
模型训练中的过拟合与欠拟合
简单的来说过拟合就是学过头的了,欠拟合就是学习的不够。可以通过下图来理解。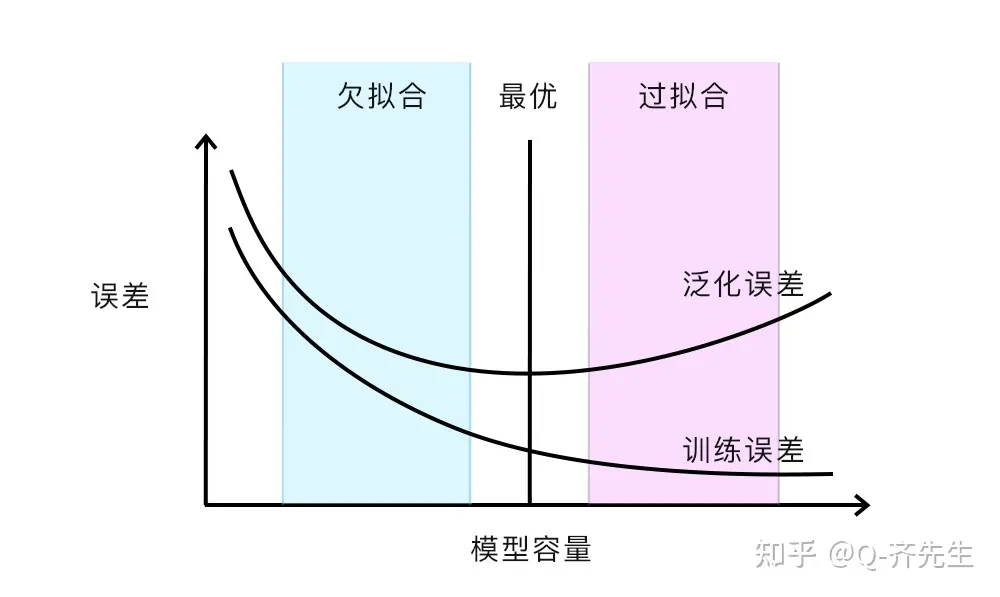
过拟合与欠拟合.png
过拟合
模型在训练中学习数据集中的特征过细,导致在训练数据集内表现很好,但是导致模型泛化性不够。
过拟合.png
欠拟合
模型在训练中学习特征不足,导致使用中误差过大。
欠拟合.png
最近很获得Lora模型的训练中也用到XYZ图标的方式检验Lora模型的过拟合与欠拟合,从中挑选出最合适的Lora模型。 以上就是我对stable diffusion的大致了解,本文尽量避免提及数学公式,希望能让没有相关知识的设计师也能容易理解,了解原里才能更快的学习。文中如有错误欢迎在评论区指正。
参考:
Intro to optimization in deep learning: Gradient Descent
How does Stable Diffusion work? - Stable Diffusion Art
High-Resolution Image Synthesis with Latent Diffusion Models

若有收获,就点个赞吧
0 人点赞
